


301
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享首先来看看问题的描述:给定一个输入的表达式,希望能够输出括号展开后的结果。如果正向思考不是很简单的话,不妨逆向考虑:输出的结果应该有怎样的形式呢?
输入的表达式中归根到底其实只有幂函数因子和数字因子(表达式因子也是由这两种因子构成的),并且他们参与的运算其实也只有加减乘以及乘方运算。直觉上来考虑,这样的输入表达式,其计算出来的结果一定是多项式,形式如下:
$$
P_n(x) = \sum_{i=1}^n a_ix^{q_i}
$$
首先要明确一点,即多项式满足以下的几点性质,这些性质都很容易证明,在此不做展开:
确定了这些性质以后,便可以着手去递归地证明输入的表达式可以被转化为上述的这种多项式形式:
首先,最基本的数字因子以及幂函数因子可以被表述为上述的形式
$$
P_1(x) = a_1x^0\
P_1(x) = 1x^{q_1}
$$
然后,这些因子相乘组合而成的项可以被表示为上述的形式
$$
P_m(x) = P_{n_1}(x)P_{n_2}(x)\cdots P_{n_k}(x)
$$
项进行加减组合而成的表达式也可以被表示为上述的形式
$$
P_e(x) = P_{m_1}(x) + P_{m_2}(x) + \cdots + P_{m_t}(x)
$$
表达式的乘方可以被表示为上述的形式
$$
P_s(x) = [P_e(x)]^u
$$
由此便证明了输入的表达式确实可以被转化为多项式的形式。在这样的形式下,整个表达式是不含有括号的,符合输出要求。因此只需要能够把输入的表达式转化为上述这种形式,就解决了问题。至于具体的转化方法,下文进行详细阐述,这里先不做展开。
在HW2中,引入了新的exp指数函数因子,很明显最终的结果不再是传统意义上由单项式 $ax^n$ 组合而成的的多项式了。其实没有关系,只需要把最终的形式稍作修改,设计出一种新的“多项式”出来,便可以符合要求。这种新的多项式形式如下:
$$
P_n(x) = \sum_{i=1}^n a_ix^{q_i}\exp(P_{m_i}(x)) \quad 或 \quad 0
$$
值得注意的是,由于嵌套结构的存在,这种新的“多项式”定义里面,不可避免地会出现递归的定义形式。同样的,与传统的多项式类似,该结构满足以下几点基本性质:
两个“多项式”相加减,仍为“多项式”
两个“多项式”相乘,仍为“多项式”
这里对第二条性质进行一小点说明:
$$
a_1x^{q_1}\exp(P_{m_1}(x))\times a_2x^{q_2}\exp(P_{m_2}(x)) = a_1a_2x^{q_1+q_2}\exp(P_{m_1}(x)+P_{m_2}(x))
$$
由于第一条性质成立,所以$P_{m_1}(x)+P_{m_2}(x) = P_{m_3}(x)$ ,等式右侧满足“多项式”的形式
某个“多项式”进行乘方操作,仍为“多项式”(多次使用第二条性质)
假设某一个表达式只含有幂函数、数字以及指数函数,那么便可以递归地证明其一定能够被表示为最终的“多项式”形式:
幂函数因子、数字因子、指数函数因子是“多项式”
$$
P_1(x) = 1\times x^{q}\times\exp(0)\
P_1(x) = A\times x^{0}\times\exp(0)\
P_1(x) = 1\times x^{0}\times\exp(P_n(x))
$$
由这些因子相乘而得到的项是“多项式”
$$
P_m(x) = P_{n_1}(x)P_{n_2}(x)\cdots P_{n_k}(x)
$$
由项相加得到的表达式是“多项式”
$$
P_e(x) = P_{m_1}(x) + P_{m_2}(x) + \cdots + P_{m_t}(x)
$$
表达式的乘方是“多项式”
$$
P_s(x) = [P_e(x)]^u
$$
由此便证明了任何只含有幂函数、数字、指数函数这些基础元素的表达式一定能被转化为“多项式”。
在HW2中,还引入了新的自定义函数相关的机制,我认为这个机制对于上述的“多项式”形式的定义和证明并不会产生任何的影响。可以这样来考虑:每一个函数调用都可以把实参带入进去从而得到新的表达式,如果这个表达式仍含有函数调用,就把这些函数调用也进行展开,直到最后不含有函数调用为止,此时得到的表达式就只含有幂函数、指数函数以及数字。得到了这样的表达式以后,根据上面的证明,也就可以得到最终的“多项式”
在HW3中,引入了求导算子,在HW2中定义的“多项式”形式并不用发生变化,因为“多项式”进行求导操作后仍为“多项式”,这里证明如下:
假设“多项式”为0,那么其导数为0,仍未多项式;
假设“多项式不为0”,那么其导数为:
$$
P'n(x)=\sum{i=1}^n a_iq_ix^{q_i-1}\exp(P_{m_i}(x))+\sum_{i=1}^na_ix^{q_i}\exp(P_{m_i}(x))P'{m_i}(x)
$$
根据上述的形式可以看出,若 $P'{m_i}(x)$ 为“多项式”,则 $P'_n(x)$ 为“多项式”,这里只需要进行递归地证明即可。
经过了上面的分析,现在程序需要做的事情其实已经非常清楚了:把输入的表达式进行转化,变为上述定义的“多项式”的形式,然后进行输出。这里我参考了一些学长学姐的思路,采取存算分离的策略:
在存的过程中,对于输入的表达式,应原封不动的保留其结构,不管是任何因子,项,表达式,还有他们之间的嵌套、调用关系,都不进行改变,直接用对应的数据结构进行保存。对于输入表达式的存储过程,以下分为两个部分进行说明:其一是输入表达式的解析,其二是具体的存储数据结构
表达式的解析
首先,经过分析可以发现,任何空白项其实对于最终的表达式语义并不会产生任何影响,因此在第一步就应该对该方面进行预处理,删除输入的表达式字符串种所有的空白项:
String inputStr = scanner.nextLine();
inputStr = inputStr.replaceAll("[ \t]", ""); //正则表达式 [ \t] 表示仅有空格和制表符所组成的任意长度的子串
在预处理过后,可以考虑对输入的字符串进行拆分,将其分为最小的具有一定语义的词。这样做的目的主要是因为考虑到直接分析字符会有较大困难,比如说对于表达式
1123123*x^+008
如果从词法角度进行分析,可以将其拆分为
1123123 某个数字
* 乘法符号
x 变量符号
^ 乘方符号
+ 正负符号
008 某个数字
而如果直接分析字符串中的每一个字符,则需要把所有的数字数位拆开:
1 某个数位
1 某个数位
2 某个数位
3 某个数位
1 某个数位
2 某个数位
3 某个数位
* 乘法符号
x 变量符号
^ 乘方符号
+ 正负符号
0 某个数位
0 某个数位
8 某个数位
在分析上就会显得很乱并且不能体现出原表达式的结构。
因此可以利用一个词法分析器 Lexer 对于输入的字符串进行这样的词分析,把整个表达式转化为一个个具有一定意义的 Token 然后再进行处理:
//Lexer.java
public class Lexer {
private final ArrayList<Token> tokenList = new ArrayList<>(); //词法分析的结果是存储一个token的列表
public Lexer(String inputExpression) { //构造函数将输入的字符串作为参数
int pos = 0; //用于表明当前扫描的字符的位置的临时变量
while (pos < inputExpression.length()) {
if (inputExpression.charAt(pos) == '+') { //存储单个加号
tokenList.add(new Token("+", Token.Type.ADD));
pos++;
}
... //其它类型的符号
else if (Character.isDigit(inputExpression.charAt(pos))) { //存储一串数字
StringBuilder sb = new StringBuilder();
while (Character.isDigit(inputExpression.charAt(pos))) {
sb.append(inputExpression.charAt(pos));
pos++;
if (pos >= inputExpression.length()) {
break;
}
}
tokenList.add(new Token(sb.toString(), Token.Type.NUM));
}
...
}
}
... // peek() 方法和 move() 方法,具体请看下文
}
//Token.java
public class Token {
public enum Type {
ADD, SUB, MUL, LB, RB, NUM, PWR, VAR, COM, EQ //分别代表了不同类的 “词”
}
//PWD means power sign ^
//VAR means variable (string consists entirely of alphabets)
//COM means comma ,
//EQ means equal =
private final Type type;
private final String content; //只存储种类不够,还需要该词的具体内容
...
}
词法分析器 Lexer 提供了 peek() 方法和 move() 方法,方便后续的解析器读取token进行解析
public boolean move() { //移动到下一个token,如果移动成功返回True,如果已经到达token列表的末尾,就返回False
if (index < tokenList.size() - 1) {
index++;
return true;
}
return false;
}
public Token peek() { //返回当前的 Token
return tokenList.get(index);
}
在分析出了这些原子的 Token 以后,便可以着手进行整个表达式的解析。在我的架构中,采用了递归下降的解法,而没有采用正则表达式解析的写法,主要考虑到的是
下面用一个例子来演示下递归下降法的工作流程,假设现在已经有一个被 Lexer 解析好的输入表达式,其为
+x^2*(x+2)*exp(x)-x^+7*9
^
|
|
Lexer目前指向的位置
当我调用 parseExpr 尝试去解析该表达式的时候,先不考虑其具体实现,我希望最终这个函数能够把这一整个表达式解析好然后一次性返回给我。
然后进入到 parseExpr 函数内部,根据形式化定义,表达式其实无非就是 +/- Term 的集合,读取到当前 Lexer 指向的第一项是一个正号,便知道接下来是一个正项,随后移动一位,变成
+x^2*(x+2)*exp(x)-x^+7*9
^
|
|
Lexer目前指向的位置
接下来 parseExpr 由于不知道项的构成方式,其只知道接下来的内容一定是某一项,他便把当前的 Lexer 交给 parseTerm 这个方法,希望 parseTerm 能够把这一项解析完毕然后返回给它。
在 parseTerm 方法拿到 Lexer 以后,它看了看,发现第一个字符是 x ,它也不认识,它只知道 Term 是由 +/- 还有一堆 Factor 乘起来所组成的,既然他没有检测到正负号,说明接下来的内容一定是一个Factor,然后又把当前的 Lexer 交给 parseFactor,希望这个函数能够解析接下来的Factor并把结果交给他。
这里省略 parseFactor的工作流程,因为 Factor 是一个比较原子的操作,其基本上不用继续进行递归调用(不考虑指数因子内部的因子或者表达式因子的话),假设 parseFactor 已经对第一个因子 x^2 完成了解析并且把 Lexer 也移动到了下一个待解析的地方:
+x^2*(x+2)*exp(x)-x^+7*9
^
|
|
Lexer目前指向的位置
现在又回到了 parseTerm的函数体内,它发现当前 Lexer 指向的是一个乘号,那么根据它对 Term 组成方式的了解,接下来也一定又是一个 Factor,于是他让 Lexer 向后挪动一位,等待 parseFactor 的结果:
+x^2*(x+2)*exp(x)-x^+7*9
^
|
|
Lexer目前指向的位置
parseFactor 发现一个左括号,它断定这是一个表达式因子,它只知道括号内部一定有一个表达式,但是其不知道该怎么解析表达式,于是他又把 Lexer 向右挪动一位,然后交给 parseExpr进行解析。parseExpr 解析完毕后他把自己返回给上层的 parseTerm进行处理。
如此不断递归地进行解析,便可以把整个表达式地内容全部解析并存储下来,然后等待后续的计算转化。
至于自定义函数的解析,我认为这一套方法仍然可用,首先是自定义函数定义的形式:
函数名(形参1,形参2(如果有的话),形参3(如果有的话)) = 表达式
对于前面的结构,可以专门新建一个 parseCustomFuncDefi 函数来进行解析,至于后面的表达式部分,直接调用 parseExpr 进行解析即可。
然后考虑自定义函数调用的解析,其也可以继续沿用递归下降,其形式为
函数名 (实参因子1, 实参因子2, 实参因子3)
只需要对这 $k \leq 3$ 个实参因子分别调用 parseFactor 方法就可以完成对自定义函数调用的解析
存储的数据结构
接下来举例说明一下存储上述解析结果的数据结构。
表达式类 Expr,其本质上就是项 Term 的集合,因此需要用一个 ArrayList<Term>来保存其中的项
private ArrayList<Term> termList;
对于项的类 Term,其是因子的集合,因此可以用一个 ArrayList<Factor>来保存其中的因子
private ArrayList<Factor> factorList;
同时由于项有正负的区分,还需要一个 flag 标志该项是否为正,采用一个 boolean 类型的变量来存储
private boolean isPosi = false;
然后便是对于因子的存储,虽然在形式化表达中存在各种因子,而且看起来其结构和功能都各异,但是仍然不应该割裂的去看待他们,而应该去提取他们的共性特征:例如,他们都可以成为项 Term 的子元素;又例如,这些因子都应该可以求导等等。考虑到上述这一点以后,可以新建一个 Factor 接口,其中设定一些希望每一种因子都能够实现的抽象方法,然后再去创建每一种因子具体的实现类,这些具体的实现类除了存储与自己有关的特别的数据以外,还应该实现接口所有的抽象方法。
public interface Factor {
public abstract Polynomial toPoly(); //转化为标准 “多项式” 形式
public abstract Factor computeDeriv(); //计算当前因子的导数并返回结果,返回值也是 Factor 类型,这样的话就可以对返回的结果进行进一步的操作
...
}
以指数因子为例,其实现类代码如下:
public class ExpoFactor implements Factor {
// exp(factor)^pow
private int pow; //存储的与指数函数因子有关的特殊数据:外部指数
private Factor factor; //存储的与指数函数因子有关的特殊数据:内部指数
...
@Override
public Factor computeDeriv() ... //重写了Factor接口的求导方法
@Override
public Polynomial toPoly() ... //重写了Factor接口的标准形式转化方法
...
}
对于自定义函数处理,这里分成定义和调用两部分来进行说明,首先是定义部分,由于自定义函数在全局都生效,因此需要有一个专门的类来存储定义好的函数,方便后面进行调用,这里采取单例模式,新建了一个只含有静态方法和变量的 CustomFunc 类用于存储和解析自定义函数:
public class CustomFunc {
private static HashMap<String, ArrayList<String>> argNameListMap = new HashMap<>(); //函数名到参数列表的映射
private static HashMap<String, Expr> exprMap = new HashMap<>(); //函数名到函数表达式的映射
//the key of both hashsets are the name of the custom function,
//e.g. h of h(x,y,z) = x^2+y^2+z^2
//the value of first hashset is the argument list of custom function,
//e.g. [x,y,z] of h(x,y,z) = x^2+y^2+z^2
//the value of second hashset is the function expression of the custom function,
//e.g. x^2+y^2+z^2 of h(x,y,z) = x^2+y^2+z^2
public static void parseFuncDefi(Lexer lexer) ... //解析自定义函数的定义式
public static boolean isDefined(String funcName) ... //检查是否定义了名叫funcName的函数
public static Expr getExpr(String funcName) ... //获取函数名对应的表达式
public static ArrayList<String> getArgList(String funcName) ... //获取函数名对应的形参列表
public static Set<String> getFuncList() ... //获取已定义的函数列表
}
对于调用部分,除了基础的函数名称以外,其实只需要存储实参的 $k \leq 3$ 个因子即可,代码如下:
import java.util.ArrayList;
public class CustomFuncCallFactor implements VarFactor {
private String funcName; //函数名称
private ArrayList<Factor> argFactorList; //实参因子列表,最多含有三个元素
public void addFactorArg(Factor factor) //添加实参因子
public String getFuncName() //获取函数名
public ArrayList<Factor> getArgFactorList() //获取实参因子列表
@Override
public Factor computeDeriv() //计算导数
@Override
public Polynomial toPoly() //转化标准形式
}
其他的因子类按照其应该含有的元素进行设计即可,这里就不重复贴出代码了。
经过上述存储的过程,整个表达式的结构已经完全被存入到了各个类中,并且形成了一个树形的数据结构,树的根节点是顶层的表达式,其叶节点是形成该顶层表达式的项,而这些项的叶节点又是各个因子等等。。。
在问题分析中提到,为了能够进行最终的化简和输出,需要将原始的表达式转化为标准 “多项式” 的形式。而与解析表达式的过程类似,对于构建标准“多项式”的过程,也需要构建相应的数据结构进行存储。为了实现该目标,我设计了两个类,一个是 Poly 类,作为最终的多项式整体而存在;而另一个类则叫做 ComplexTerm 类,以下称为复合项,其代表了形如
$$
ax^n\exp(P(x))
$$
的一个式子,作为 Poly 类中的一项。
在解析存储部分,采用了自顶向下的建树策略,在构建高层的结构时,只考虑其直接子元素,而不考虑底层的细节。在进行标准化转化时,也可以采用类似的策略:
假设某一个表达式 Expr 由几个 Term 所构成,而这些 Term 都已经被转化为了标准的 “多项式” 形式,此时只需要考虑如何将这些多项式进行合并(相加),合成一个新的多项式。
因此在用于存储最终的多项式的类里,需要引入加法函数:
//Polynomial.java
public static Polynomial polyAdd(Polynomial polyA, Polynomial polyB) {
... // 接受两个Poly对象作为参数,返回他们相加后的结果
return newAddedPoly;
}
由此便可以设计出表达式 Expr 类向“多项式” Poly 类转化的函数 Expr.toPoly():
//Expr.java
@Override
public Polynomial toPoly() {
newPoly = new Polynomial();
for (int i = 0;i < termList.size();i++) {
newPoly = Polynomial.polyAdd(newPoly, termList.get(i).toPoly());
}
return newPoly;
}
在 Expr 的转化函数内部,其调用了 Term 的转化方法,因此接下来转化的任务就落到了 Term 类上。还是利用递归的思想,先不去考虑更底层的细节,只考虑到 Term 类是由各种因子相乘得到的,那么假设 Term 的每一个因子都已经转化为了 Poly,就可以调用 Poly 的乘法方法将他们乘起来,从而得到最终的结果,即
//Term.java
public Polynomial toPoly() {
Polynomial newPoly = new Polynomial();
for (Factor factorItem : factorList) {
newPoly = Polynomial.polyMul(newPoly, factorItem.toPoly());
}
return newPoly;
}
这样的话,就又需要引入 Poly 类的乘法函数:
//Polynomial.java
public static Polynomial polyMul(Polynomial polyA, Polynomial polyB) {
ArrayList<ComplexTerm> newCTermList = new ArrayList<>();
for (ComplexTerm complexTermItemA : polyA.getCTermList()) {
for (ComplexTerm complexTermItemB : polyB.getCTermList()) {
newCTermList.add(ComplexTerm.cTermMul(complexTermItemB, complexTermItemA)); //复合项相乘然后放到列表里
}
}
return new Polynomial(newCTermList);
}
可以看到,由于 Poly 类其实是由复合项类所构成的,所以其实 Poly 类的乘法是复合项之间两两相乘最后再合并到一起,所以还需要实现复合项的乘法:
//ComplexTerm.java
public static ComplexTerm cTermMul(ComplexTerm complexTermA, ComplexTerm complexTermB) {
... //具体细节略去了,大体上就是对应的系数相乘得到新的系数
//对应的幂函数指数相加得到新指数
//exp中的指数“多项式”相加得到新的指数“多项式”
}
至此,就已经完成了 Term 向 Poly 转化的 toPoly 方法。
至于具体因子向 Poly 的转化,是较为简单的,比如说幂函数因子,只需要新建一个复合项如下:
$$
1 \times x^p\times \exp(0)
$$
然后新建一个 Poly 只含有这一个复合项即可。
求导因子和自定义函数调用因子的处理
看起来非常完美,原本的表达式通过解析器 Parser 构造出 Expr->Term->Factor 的树状结构,接下来被一级一级的转化为 Poly, 运算,最终实现了用一个 Poly 存储和原本表达式数学等价的结构。但是其实还隐藏着很大的问题,这便是求导因子和自定义函数调用因子的问题,例如
f(g(x),h(x),f(x,x,x)) 或 dx(exp(x) + x^6*exp(dx(x^5)))
请问这样的因子该如何转化为标准“多项式”的结构呢?这是无从下手的,因为函数调用和求导都是形式化的一种数学算符,在最终的输出中,不能含有这些算符,因此需要将具体的表达式带入、计算以后才能够继续进行转化。
对于求导算子 ,只要让每一个 Factor 都重写求导方法,然后在调用求导因子的 toPoly 方法时,可以先调用内部因子的求导方法,得到求导后的因子,再调用这个新的因子的 toPoly 方法,便可以完成转化。唯一要注意的点是在对 Expr 类或 Term 类等含有比较复杂的结构进行求导的时候,应注意正确使用链式法则和乘法、除法等求导公式。
对于自定义函数的调用因子,可以分成两步来转化:
将所有的实参因子转化为具体的、不含任何求导因子或自定义函数调用因子的因子。这么说可能有点绕,举个例子:
假设输入为
3
f(x,y,z) = x+y+z
g(z) = exp(z)
h(y) = y^6
f(g(x),h(x),dx(x^4))
这其中,
g(x) h(x) dx(x^4)
是函数调用因子的实参因子,将这些因子变为不带有求导因子和自定义函数调用因子的因子后:
exp(x) x^6 4x^3
整体的函数调用变为
f(exp(x),x^6,4x^3)
接下来的任务便是将这些实参因子带入到函数的定义表达式中去而得到具体的不含有自定义调用因子的表达式。
这里可以采取两种策略,一种是遍历原函数定义表达式的字符串,找到形参所在的位置,然后将实参因子带入进行字符串替换,但是这样得到的结果是一个字符串,要得到对应的数据结构的话,又需要由对应的 parser 解析器函数进行解析,该过程显得不够简洁。
我这里采用的是树移植法(这个名字是我从讨论区里看来的,一开始并不知道这个算法叫这个名字。),其核心思想是既然我想要进行带入,那就写一个带入函数呗:
public abstract Factor replaceWith(String varName, Factor factorReplace);
这个函数作为 Factor 类的抽象方法,所有的因子实现类都需要实现该函数,其作用就是把当前因子中所有的 varName 变量,全部替换为 factorReplace 因子,听起来可能有些抽象,举个例子:
现在有一个 expr,长这个样子:
$$
y^2+exp(y)^2+5yz
$$
此时我调用了这个 expr 的 replaceWith 方法,希望能把 y 替换为 exp(x)。这时,先看看 expr 做了什么:
Term 的 replaceWith 方法,并且把得到的因子 exp(x)^2 放到一个新的 Term 里,再把这个 Term 放到结果的 Expr 里Term 的 ReplaceWith 方法,还是把得到的因子 exp(exp(x))^2 放到一个新的 Term 里,然后再把这个 Term 放到结果的 Expr 里Term 的 ReplaceWith 方法,同样的把得到的因子 (5*exp(x)*z) 放到一个新的Term里,再把这个 Term 放到结果的 Expr 里Expr,完成了替换这里只说明了 Expr 的替换过程,对于 Term 以及某个 Factor 的替换过程也是类似的,调用自己的叶节点的替换方法,然后按照规则把他们拼凑成新的 Factor 以后返回结果
有了这样一个带入函数就好办了,对于已经输入的自定义函数的定义表达式,调用 $k \leq 3$ 次此函数,分别把不同的形参用实参因子进行代替,得到新的,不含有自定义函数调用算符的因子,然后再进行 toPoly 的转化,就可以了。
在解决了求导和自定义函数调用的问题后,便真正的可以进行转化和输出了
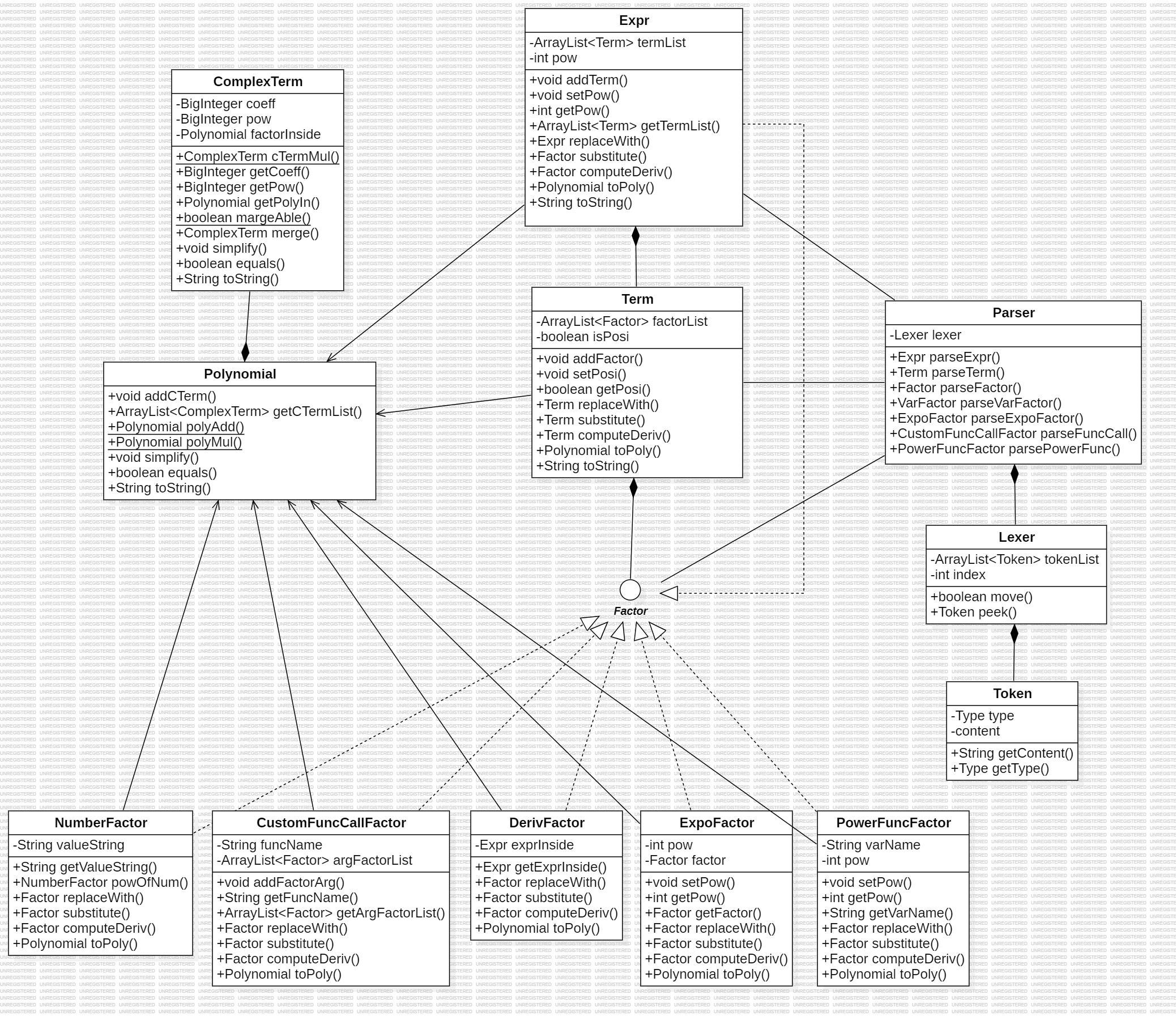
以下是我的第一单元架构的UML类图:
对于度量分析,这里采用了 IntelliJ Idea 的两款插件 Statistic 和 MatricesReload 来进行自动化分析:
首先是代码量的数据:
| 文件名称 | 总行数 | 代码行数 | 注释行数 | 空行数 |
|---|---|---|---|---|
| ComplexTerm.java | 146 | 122 | 9 | 15 |
| CustomFunc.java | 91 | 71 | 9 | 11 |
| CustomFuncCallFactor.java | 81 | 63 | 5 | 13 |
| DerivFactor.java | 44 | 35 | 0 | 9 |
| ExpoFactor.java | 88 | 68 | 8 | 12 |
| Expr.java | 122 | 101 | 7 | 14 |
| Factor.java | 9 | 6 | 0 | 3 |
| Lexer.java | 70 | 65 | 0 | 5 |
| MainClass.java | 75 | 24 | 35 | 16 |
| NumberFactor.java | 58 | 40 | 6 | 12 |
| Parser.java | 178 | 160 | 9 | 9 |
| Polynomial.java | 122 | 99 | 11 | 12 |
| PowerFuncFactor.java | 116 | 97 | 7 | 12 |
| Term.java | 91 | 80 | 0 | 11 |
| TestALL.java | 17 | 15 | 0 | 2 |
| Token.java | 26 | 17 | 4 | 5 |
| VarFactor.java | 3 | 2 | 0 | 1 |
可以看到每一个文件的码量都维持在200行以下,在码量上考虑的话,有较好的可读性。其中ComplexTerm.java 和 Parser.java 代码量最多。前者是因为要实现较为复杂的化简、运算逻辑,并且这些逻辑主要是其内部的逻辑,与其他类无关,所以无法进行拆分,其代码量相较而言较大;而后者则是因为所有类的解析函数都放在这一个类中,所以总码量较大,但由于不同的类的解析有不同的函数,所以其实该文件的每个函数代码量都可以处在可以接受的范围。
然后再来查看复杂度,这里选取了复杂度最高的6个方法进行分析:
| 方法名 | CogC | ev(G) | iv(G) | v(G) |
|---|---|---|---|---|
Lexer.Lexer(String) | 26.0 | 16.0 | 14.0 | 16.0 |
Polynomial.equals(Object) | 25.0 | 6.0 | 7.0 | 9.0 |
Parser.parseFactor() | 20.0 | 4.0 | 13.0 | 13.0 |
CustomFunc.parseFuncDefi(Lexer) | 14.0 | 2.0 | 11.0 | 12.0 |
ComplexTerm.equals(Object) | 12.0 | 5.0 | 8.0 | 11.0 |
Polynomial.simplify() | 11.0 | 1.0 | 7.0 | 7.0 |
首先是Lexer的构造方法,由于其需要对整个输入的表达式进行词法判断与分析,有非常多的判断语句,所以其圈复杂度较高。我觉得这里不太容易进行优化,因为构成表达式的这些基本单元并不依赖于其他的结构,只能由 Lexer 进行遍历、判断、然后生成 tokenList,这也是该方法的本质复杂度高的原因,如果该方法内部缺少了任何一个判断分支,都无法完成其工作。
对于 Polynomial 类的 Eqauals 方法,由于每一个类都含有很多复合项,因此要确定两个 “多项式” 是否相等,就需要去判断不同的复合项是否对应相等,而由于这些项的顺序有可能不同,所以需要用一个二重循环来构造一个一一映射。同时,我们还需要保证不同的复合项之间不能合并,否则就可能会出现 1+1+1+1 与 4 不相等的这种情况的出现。综上,该方法的圈复杂度较高,主要是因为“判断相等”这件事情的逻辑比起其他的事情,比如说计算相加,要来得更高。
然后是 Parser 类的 parseFactor 方法,其圈复杂度较高是因为不管解析任何类型的因子,都会先调用该方法判断接下来要解析的因子类型,由于因子种类较多,所以就造成了该方法的圈复杂度高。
对于复合项的equals方法,其实和Poly类的equals方法类似,也需要考虑到内部因子是否相等、系数是否同为0,等问题造成了圈复杂度高。
最后是Polynomial的化简方法,每次都需要拿出一项出来和其他所有项进行比较,查看内部因子是否相等、进而确定能否合并,如果能合并的话就进行合并操作,同时还需要进行删除。该方法的逻辑相对复杂,复杂度高。
在三次作业中,出现了两次比较致命的bug:
首先是在HW2的时候,没有考虑到嵌套括号有可能导致的指数膨胀的问题,仍然用int类型来存储指数,从而导致溢出,输出错误。后来将所有的指数类型全部改为BigInteger并且修改相关的计算方法后这个问题就解决了。以后再遇到迭代开发的时候,一定要看清楚迭代要求,先想清楚迭代前后问题的规模是否发生了改变。这个bug的出现就是我想当然的以为即使是嵌套括号也不会让指数超出int的类型范围,然后就炸了(悲
还有一个bug是出在计算由表达式计算Poly的时候:考虑以下这种情况:
(((x+1)^8)^8)^8
一开始我选择了全部计算完毕再进行化简合并,但是对于上述这种输入来说,如果不合并全部展开,就会导致最终的 poly 共有2^512项!这对于空间时间代价来说都是不能够忍受的,因此最终我在每次计算完毕之后都进行化简,避免了由于多项式乘法造成的项数快速膨胀。该bug我认为同样也是没有将问题的规模以及所有情况考虑周全所导致的。
此单元中,幸运的是,由于HW1就直接选择了递归下降法来解析表达式而非使用正则表达式进行解析,因此没有进行大规模的重构,基本上后两次作业都是在上一次的基础上进行增量开发。由此可见,一个好的架构对于解决问题是非常重要且关键的。以前我编程可能更加注重的是解决问题,而忽略了在解决问题的过程中也要注意的一些要点。
在第一单元的编程过程中,我逐渐体会到面向对象的思想以及特性(多态、继承、封装等)在保持代码的简洁性、可拓展性以及可维护性这些方面上起到了非常关键的作用。在编码的过程中,我能够将问题抽象出来分成一个个子问题,在考虑上层的过程中完全不需要思考下层具体的实现细节。这种上下层分离的思考方式能够减少很多思维量,也让后期调试的过程变得更加容易了(给面向对象的程序debug相当于在一个树上做查找,而给面向过程的程序debug则是在线性表上做查找,前者显然要简单得多)
总结一下就是不管在进行任何编码之前,先多想,想明白了,想清楚了再去做。
有一点小小的建议和期待

其实研讨课给出的议题是候选,不是要求每个都进行讨论。



