

896
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享4月8日,苹果发布了其最新的多模态大语言模型(MLLM )——Ferret-UI,能够更有效地理解和与屏幕信息进行交互,在所有基本UI任务上都超过了GPT-4V!
苹果开发的多模态模型Ferret-UI增强了对屏幕的理解和交互,在引用、基础和推理方面表现出了卓越的性能,这些增强功能的出现预示着巨大的进步。
一句话Siri就能帮忙打开美团外卖下订单的日子看来不远啦!

Ferret是一种MLLM,擅长在形状和细节各异的自然图像中进行空间参照和定位,以 ChatGPT 为代表的 AI 大语言模型(LLMs),其训练材料通常是文本内容。为了能够让 AI 模型能够理解图像、视频和音频等非文本内容,多模态大语言模型(MLLMs)因此孕育而生。
目前的多模态大模型(LMMs)主要是一种图像到文本的生成模型,它接受图像作为输入,并输出文本序列。如图1.1(a)左侧所示,所有模型变体都共享一个非常相似的模型架构和训练目标。
模型架构:如图1.1(a)右侧所示,模型通常由一个图像编码器组成,用于提取视觉特征,以及一个语言模型来解码文本序列。视觉和语言模态可以通过可训练的连接模块进行可选连接。图像编码器和语言模型可以从头开始训练,也可以从预训练模型初始化。
训练目标:如图1.1(b)所示,它通常采用自回归损失来优化输出文本的Token。对于Transformer中的注意力图(Vaswani等人,2017年),图像Token可以相互关注,当前的文本Token关注所有图像Token以及之前的文本Token。
这种架构使得多模态大模型能够处理和理解图像内容,并将其转化为自然语言描述。这些模型在图像描述、视觉问答(VQA)和图像字幕生成等任务中表现出色。随着技术的发展,多模态大模型的应用范围预计将进一步扩展,涵盖更多种类的模态和更复杂的交互任务。
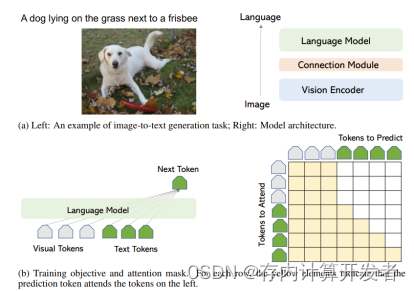
图1: 图像到文本的生成任务、架构和训练目标说明
在多模态大模型的发展中,算力是多模态大模型遇到的挑战之一。以 Meta 的 OPT-175B 为例,他们在训练过程中使用了 992 张显存为 80G 的 NVIDIA A100 GPUs。而谷歌的 PaLM-540B,甚至使用了 6144 张 TPUs。这都充分证明了训练一个大模型需要足够的算力支持。国内许多公司也在积极构建属于自己的云计算平台,例如阿里云、百度云、华为云、腾讯云等等。特别地,4 月 14 号,腾讯云发布了新一代 HCC 高性能计算集群,搭载了 NVIDIA H800 Tensor Core GPU。因此,构建一个高性能计算集群是进行大模型训练的必经之路。本文介绍两种基于类脑神经架构与芯片。
为了减少每个输入的计算负担,我们提出了能够同时处理多个输入的多输入-多输出神经网络(MIMONets)。MIMONets通过可变绑定机制扩充了各种深度神经网络架构,在一个组合数据结构中,以通过固定宽度的分布式来表示任意数量的输入。因此,MIMONets将非线性神经转换调整为整体处理数据结构,速度提升几乎与数据结构中叠加输入项的数量成正比。将MIMONets的概念应用于CNN和Transformer架构,分别得到了MIMOConv和MIMOFormer。经验评估显示,与WideResNet CNNs在CIFAR10和CIFAR100上相比,MIMOConv在准确率增量范围内实现了约2-4倍的加速。类似地,MIMOFormer可以同时处理2-4个输入,同时在长距离领域基准测试中保持高平均准确率,在[-1.07,-3.43]%的增量范围内。下文详细介绍MIMOConv架构和MIMOFormer架构。
MIMONets概念应用于CNN,针对卷积神经网络(CNNs)的扩展,构建一个多输入多输出的MIMOConv,能够同时处理多个图像的叠加。MIMOConv架构如图3所示。多个输入样本(N)通过第一个卷积层传递,并根据全息降维表示(HRR)绑定到唯一的高维键上,并通过逐一元素加法进行叠加。在通过网络的主要CNN层传递叠加张量之后,我们获得一个包含所有输入信息的组合特征向量。通过基于MBAT分别学习的键进行解绑(相当于矩阵乘法),我们提取出各个处理过的信息,然后将其通过最终的全连接层生成用于分类的logits。

图3:MIMOConv配置为N=3个通道。输入图像先分别通过第一个卷积层,然后将每个特征值与特定于通道的高维键绑定。键-值对进行叠加,产生保持维度的组合,并通过其余的CNN层。输出通过相应的键解绑,解绑的表示分别使用共享的全连接层进行分类。
MIMOConv增强模型的性能的三个关键要素如下:
1. 局部性的可变绑定(Variable Binding of Locality):
- MIMOConv通过可变绑定机制来保持输入数据的局部性。这意味着模型可以根据不同输入的特征动态调整其感受野,从而更好地捕捉局部特征和上下文信息。这种可变性使得CNN能够灵活地适应不同的输入和任务需求。
2. 高维嵌入(Embracing high dimensional embeddings):
- MIMOConv利用高维嵌入来表示输入数据,这允许模型在更高维度的空间中捕捉更复杂的特征。高维嵌入可以提供更丰富的信息表示,有助于模型学习到更抽象和通用的特征,从而提高对输入数据的理解能力。
3. 鼓励使用等距层(Encouraging isometric layers)
MIMOConv鼓励使用等距层,在卷积神经网络(CNN)的背景下,等距层有助于保留输入数据的空间信息,这对于图像识别、分割等任务至关重要,因为在这些任务中,特征之间的空间关系是关键。
MIMOConv的设计使得CNN能够更有效地处理多模态输入,提高了模型的表达能力和泛化性能。这种方法特别适用于需要同时处理图像、文本或其他类型数据的任务,如视觉问答(VQA)和图像字幕生成等。通过这些创新的机制,MIMOConv为CNNs提供了一种新的视角,以适应更广泛的应用场景和挑战。
MIMONets应用于Transformer架构中,形成MIMOFormer架构,它将叠加计算的原则应用于点积自注意力机制。图4展示了一个具有四个受保护通道的MIMOFormer层,包括一个单头注意力块、一个连接操作、一个线性层、一个多层感知机(MLP)以及一个跳跃连接。
仅仅将受保护的注意力键和查询进行叠加并不能得到期望的结果。对于token对之间的标量注意力分数,传统的点积注意力会不可逆地结合各个受保护通道的注意力分数,从而有效地模糊了注意力权重。通过基于线性Transformers构建,注意力分数不会塌陷为标量,从而使得叠加计算成为可能。
MIMOFormer的设计允许在自注意力机制中同时处理多个输入序列,而不会相互干扰,这在处理多模态数据或需要并行处理多个任务的场景中非常有用。通过保持每个输入序列的独立性,MIMOFormer可以更精确地捕捉和处理每个序列的特征,从而提高模型的整体性能和准确性。MIMOFormer可以同时处理2-4个输入,同时保持[-1.07%,-3.43%]的高平均精度。
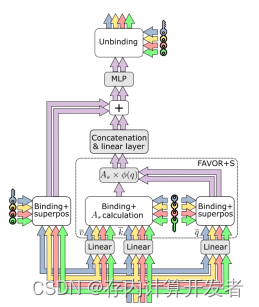
图4:MIMOFormer 层将叠加计算应用于单头 FAVOR+S和 MLP 的叠加计算
1. MIMOFormer应用实例:
在注意力机制期间专门进行叠加计算。通道(n, m)中的各个标记(tokens)通过使用密钥 \( \tilde{a}(n,m) = a(n,m), \) 与Si(n)解绑定(unbinding)直接检索。FAVOR+S内的剩余计算步骤是分别执行的。这种设计允许在注意力机制中利用叠加,同时保持其他计算步骤的独立性。
2. MIMOFormer加速应用实例:
除在注意力机制中使用叠加,还在拼接(concatenation)、线性层(linear layer)以及MLP中使用叠加。与第一个变体不同,围绕注意力块的跳跃连接(skip connection)必须考虑引入的叠加。为了允许潜在的嵌入维度不匹配,实例化了两组不同的随机生成的双极密钥(bipolar keys):一组用于跳跃连接和MLP后的解绑定,另一组用于FAVOR+S绑定。所有密钥在训练期间都是固定的;线性层中拼接后的可训练权重负责找到绑定和解绑定密钥之间的关系。
这种设计的优势在于它能够在保持数据流的连续性和一致性的同时,提高计算效率。通过在不同的层和操作中使用叠加,可以减少所需的计算资源,并可能加快模型的训练和推理速度。此外,通过使用固定的密钥和可训练的权重,模型可以在保持数据安全的同时,学习如何最有效地处理输入数据。
在第二个实例中,引入的双极密钥系统允许模型灵活地处理不同维度的数据,这对于处理复杂的多通道输入尤其有用。这种灵活性使得MIMOFormer架构能够适应各种不同的数据结构和任务需求。
总的来说,这两个MIMOFormer实例展示了如何通过在深度学习架构中巧妙地应用叠加和密钥绑定/解绑定机制来提高模型性能和计算效率。这种方法为处理大规模数据集和复杂任务提供了新的可能性,同时也为未来的研究和开发提供了有趣的方向。
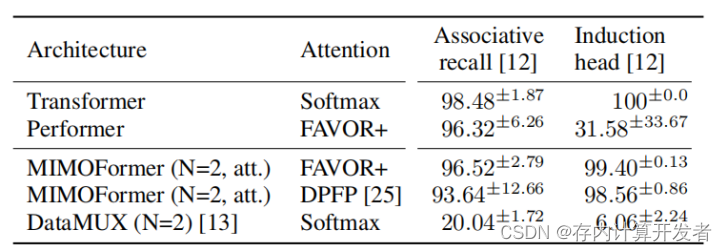
表1:合成序列建模任务的准确率
表1展示了两个合成序列建模任务的准确率结果,这些任务对于Transformer的替代模型,在这些更为微妙的自然语言处理(NLP)任务中,DataMUX 的准确率即使在大量训练努力下,当N=2时也下降到了20.04%和6.06%。相比之下,MIMOFormer在这两个任务上的得分分别为96.52%和99.40%,表现出了显著的成功。
与此相反,MIMOFormer的方法能够收敛到精确的注意力而不会产生模糊。这意味着MIMOFormer在处理序列数据时,能够更清晰、更准确地识别和强调重要的信息,从而提高了模型的整体性能。MIMOFormer的这种特性使其具有很高的灵活性,可以调整并应用于其他线性变换器模型,例如DPFP 。在DPFP模型中,MIMOFormer的得分分别为93.64%和98.56%,这进一步证明了其在不同模型中的适用性和有效性。
总的来说,MIMOFormer在处理复杂NLP任务时展现出了卓越的性能,特别是在需要精确注意力机制的应用中。通过避免注意力得分模糊,MIMOFormer能够更有效地学习和处理数据,这使得它在合成序列建模任务中取得了显著的准确率提升。此外,MIMOFormer的可调整性和适用于多种线性变换器模型的能力,使其成为了一个强大且多才多艺的工具,可以在多种不同的NLP任务中发挥作用。
MIMONets,即“Multiple Input Multiple Output Networks”,是一类旨在通过神经网络架构中的主导操作—卷积(convolution)和注意力(attention)来展示叠加计算(computation in superposition)有效性的模型。MIMONets实例,MIMOConv和MIMOFormer,分别针对这两种操作进行了优化和改进。
MIMOConv:这个实例专注于卷积操作,卷积是卷积神经网络(CNNs)中的核心组件。通过在卷积层中应用叠加计算,MIMOConv能够更高效地处理多个输入通道,并提取更丰富的特征表示。这种方法可以提高模型在图像识别、视频分析和其他需要空间特征提取的任务中的性能。
MIMOFormer:这个实例则专注于注意力机制,它是变换器模型(如Transformer)中的关键组成部分。注意力机制允许模型在序列数据中动态地关注不同部分,而叠加计算的引入使得MIMOFormer能够在处理复杂的序列任务时更加高效和准确。
MIMONets确实有潜力成为加速基础模型推理的有力候选者,特别是在需要动态和按需推理的场景中。基础模型(foundation models),如大型预训练语言模型或多模态模型,通常具有大量的参数和复杂的结构,它们在提供高精度和强大泛化能力的同时,也对计算资源提出了较高的要求。
总之,MIMONets的这些特性使其成为加速基础模型推理的有力工具,特别是在需要动态和按需推理的应用中。随着人工智能应用的不断扩展和深入,MIMONets可能会在未来的AI系统中扮演越来越重要的角色。下篇文章我们将继续介绍加速多模态大模型的推理的神经形态架构。
 每日一看大模型新闻(2023.12.15-12.17)3D、视频直接扔进对话框,大模型掌握跨模态推理;PaLM 2数学性能暴涨6%!DeepMind新作力证「合成数据」是通往AGI关键;OpenAI:
每日一看大模型新闻(2023.12.15-12.17)3D、视频直接扔进对话框,大模型掌握跨模态推理;PaLM 2数学性能暴涨6%!DeepMind新作力证「合成数据」是通往AGI关键;OpenAI:

