



4,212
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享多Agent模式是一种分布式计算范式,它通过将复杂任务分解为多个子任务,并由独立的智能体(Agents)并行处理,从而提高系统的处理能力和效率。这种模式在自然语言处理、机器学习和其他数据密集型应用中尤为有效。然而,多Agent系统的实施和运行需要显著的算力支持,尤其是在处理大型数据集和复杂模型时。为了满足这些需求,算力提供方正在探索新的供给模式,软硬件优化,存内计算等模式。
吴恩达教授在美国红杉 AI 活动上关于 Agent 的最新趋势与洞察,提出了目前有 4 种主要的 Agent 设计模式,分别是:
Reflection:让 Agent 审视和修正自己生成的输出;
Tool Use:LLM 生成代码、调用 API 等进行实际操作;
Planning:让 Agent 分解复杂任务并按计划执行;
Multiagent Collaboration:多个 Agent 扮演不同角色合作完成任务;
🤩 在 扣子(coze.cn)/Coze (coze.com)上,可以将上述四种模式快捷落地,本文重点介绍Reflection模式和多Agent模式。
含义:让 Agent 审视和修正自己生成的输出。
背景:大模型的生成有时候会犯懒,可能只会部分执行Prompt导致效果有限。Reflection模式适用于让LLM自行审视和修正自己生成的输出,对生成内容进行多次自我调优,进而生成更加优质的内容。
场景:让 AI 或 LLM 说,写一个行业短评。开始写第一稿,自己阅读生成第一稿,思考哪些部分需要修改,然后,LLM进一步优化生成,可以一遍又一遍地进行。因此,这个工作流程是可迭代的,你可能让模型进行一些思考,然后修改文章,再思考,并通过多次迭代来完成这个过程。
流程图:
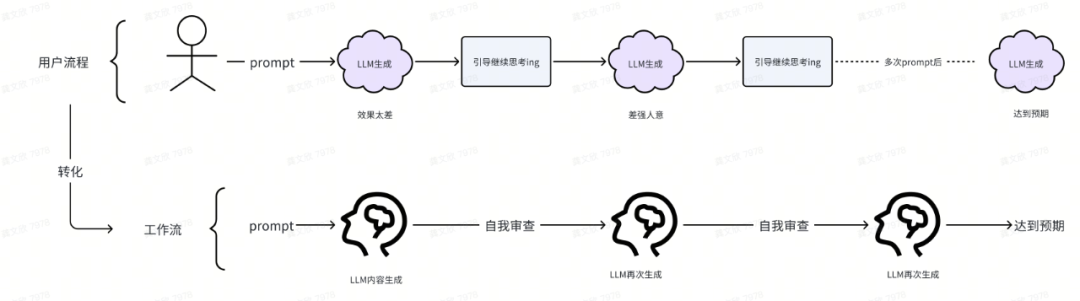
🔥 Workflow实现简单“行业短评”效果
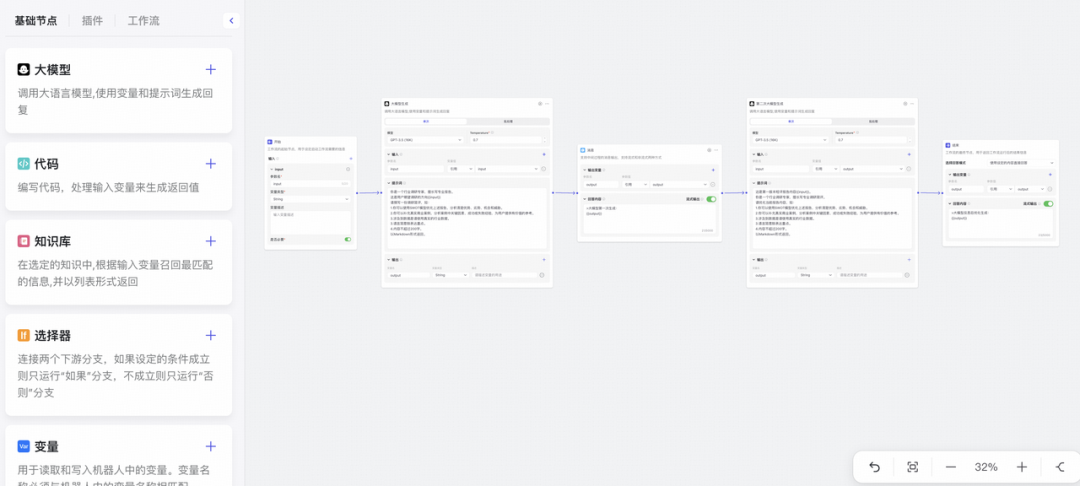
👉 工作流拆解:
第一步:Start节点,用于接收用户的输入。
第二步: 大模型节点,行业短评Prompt:使用真实数据、案例、SWOT模型,并言简意赅表达。
第三步:基于其生成结果第二步中的大模型的生成结果,复制其Prompt,并进一步提示生成短评,达到审视和修正自己生成输出的效果,提高短评生成质量。
第四步: 输出结果。
👉 示意图参考:
👀 效果:汽车行业调研短评

第一次:大模型对于提示,仅生成比较概括性的短评,使用了真实数据。
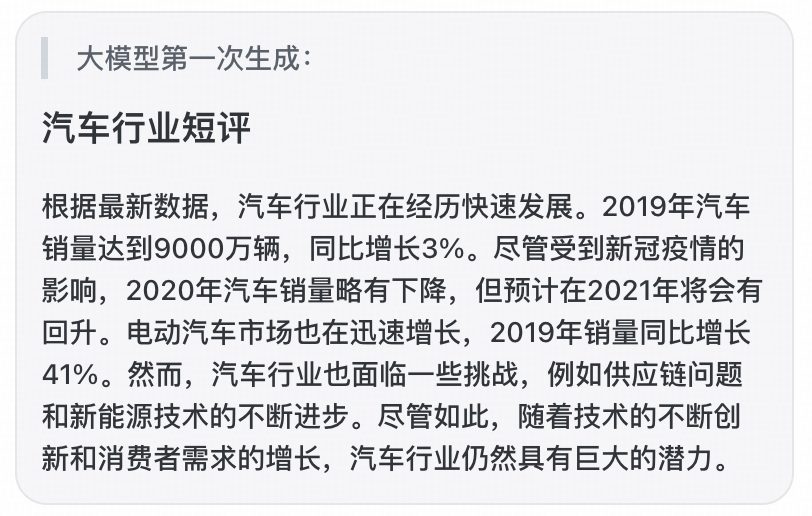
第二次:大模型对生成结果进行迭代,生成了详细短评,不仅优化了表达内容,还增加了SWOT分析和案例分析。

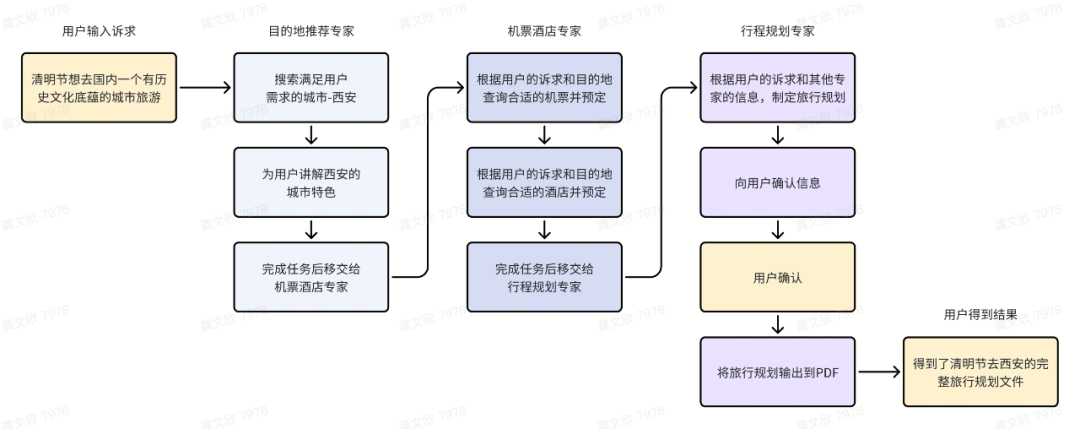
🔥 使用coze的Multi-agent功能实现高质量旅行规划
第一步:定义3个用于旅行规划场景的专家Agents
目的地推荐专家: 调用搜索等能力,基于用户的需求推荐目的地。
机票酒店专家: 调用机票、酒店的查询工具,根据用户的背景信息和诉求,推荐合适的机票酒店。
行程规划专家: 根据用户的信息和其他专家产出的结果,帮助用户制定完整的行程规划,并将内容输出到PDF中。
第二步:将3个专家Agents排列到画布中,并为他们设置任务交接的条件。
第三步:开始对话
直接登入Coze,创建属于你的Agent, 产品经理在线等你提需求,点击下方链接,开启测评:
https://bbs.csdn.net/topics/618354373![]() https://bbs.csdn.net/topics/618354373
https://bbs.csdn.net/topics/618354373


效果演示图
多Agent模式在构建AI系统时,需要处理来自不同代理的任务和数据,这通常会导致算力需求的增加。在多Agent模式下,每个代理可能负责特定的任务或工作流程的一部分,它们需要进行通信和协作以完成更复杂的任务。这种模式的算力需求取决于多个因素,包括代理的数量、每个代理处理的任务复杂度、代理间的交互频率以及整体系统的优化程度。
在多Agent模式中,如果每个代理都使用类似的大型模型,那么总体算力需求将是巨大的。此外,多模态大模型对算力的消耗呈指数级增长趋势,因为它们需要处理和整合来自不同模态(如文本、图像、音频等)的数据。这种类型的模型在多Agent模式下的应用将进一步推动对高性能计算资源的需求。
值得一提的是,在新一轮算力攻坚赛中,突破传统冯·诺依曼架构的范式探索成为主要方向之一。而“存算一体”架构打破了存算分离的壁垒,减少了数据的搬运,它就如同“在家办公”的新型工作模式,消除了数据“往返通勤“的能量消耗、时间延迟,并且节约了“办公场所”的运营成本,因而具备高能效比。加上“存算一体”架构对于工艺制程的“弱依赖”性(14nm展现4nm数字电路表现性能),使其成为了AI算力的重要发展方向。
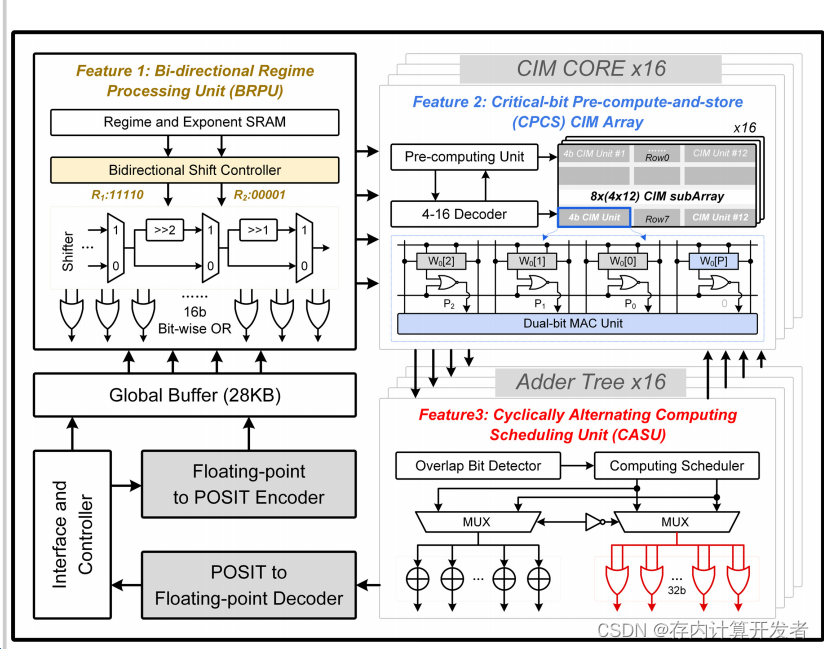
Posit数字计算内存(CIM)模型(简称PD-CIM)的整体架构
上图为最新融入Posit系统的存内计算架构,在加载数据到PD-CIM时,FP-to-POSIT编码器将浮点数据转换为Posit格式以便于存储。CPCS会检测权重尾数的位宽,并预存逻辑值到备用的CIM单元中。在计算过程中,BRPU执行基于位移位或的区间处理。CIM核心结合CPCS有三种工作模式,包括3位模式、2-4位集合关联模式和正常模式。前两种模式使用预存的逻辑值来实现CIM内部的双比特乘累加(MAC)操作。CASU通过将加法操作替换为位级或操作来节省加法树的能量,并改变CPCS的计算顺序以增加无重叠尾数的数量。
整体而言,PD-CIM架构的设计旨在通过在存储器内部直接进行计算来提高能效和计算性能,同时支持多种计算精度和工作模式,以适应不同的计算需求。这种架构特别适合于需要处理大量数据和复杂计算任务的应用,如人工智能和大数据分析。
多Agent模式背后的算力需求通常较高,因为需要同时处理来自多个智能体的任务和数据。存内计算(Computing in memory,CIM)作为一种新兴的计算架构,能够在存储器阵列内完成逻辑运算,避免存储器和处理器之间频繁的数据搬移操作,从而提升算力,降低功耗。


