


889
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享本文聚焦存内计算前沿论文ISSCC 2024 34.3,总结归纳其创新点,并对与之相似的创新点方案进行归纳拓展。
一、文章基本信息
ISSCC 2024 34.4:《A 22nm 64kb Lightning-Like Hybrid Computing-in-Memory Macro with a Compressed Adder Tree and Analog-Storage Quantizers for Transformer and CNNs》[1]介绍了一种形似“闪电”的数模混合存内计算宏结构,其具有压缩的加法树(也即近似加法树)与用于Transformer和CNNs的模拟存储量化器。文章作者团队来自东南大学与北京大学,第一作者为东南大学博士生郭安,其在近两年ISSCC、JSSC上共以第一作者身份发表论文3篇。
作者围绕现阶段数模混合存内计算芯片的现状提出了三点挑战:
(1)混合CIM在精度与面积/功耗开销之间的权衡;
(2)模拟CIM中读出电路的巨大能耗与误差;
(3)在大规模的加法器树下,数字CIM的能效有限。
作者同样提出了三种解决方案来应对挑战:
(1)类似闪电的模拟/数字混合结构,以保持能效和推理精度;
(2)基于数字4:2压缩器的加法器树以及双正则化训练方法,以减少面积/功率成本;
(3)用于可扩展累加器长度的模拟存储量化器(ASQC),输出比率为1。

图1 论文Challenge&Solution部分
二、论文内容解析
文章的创新点主要聚焦于三个方面:(1)闪电式数模混合结构;(2)压缩器的设计(采用近似方法);(3)引入ASQC,为ADC减负。
首先是闪电式数模混合结构。图2展示了闪电式混合SRAM CIM宏架构,支持累加器长度可扩展。图中蓝色为数字计算部分,黄色为模拟计算部分,通过将高位、低位数字单元(HDU与LDU)与高位、低位模拟单元(HAU、LAU),如图所示对其进行排列组合(两个子阵列与HDU和LDU对组合,四个子阵列与HDU和LAU对组合,其余两个子阵列与HAU和LAU对组合),以此来进行高效的INT 8的MAC操作。
其优势在于:(1)与传统的模拟累加器相比,由于采用了HAU、LAU和模拟存储量化器电路(ASQC),大大减少了所需的ADC转换次数和存储需求;(2)该结构支持更大的累加长度,而无需存储大量的部分和,这对于卷积神经网络(CNN)和Transformer网络更为合适。

图2 闪电式混合SRAM CIM宏架构
其次是压缩器的设计。图3展示了HDU/LDU的详细原理图和操作,以及作者提出的用于高效数字域处理的基于4:2压缩器的加法器树。每四个16×1b 6T-SRAM单元列共享一个HDU/LDU。每个HDU/LDU 由4个或非门和一个4:2压缩器组成。每4:2压缩器由一个或非门和一个28T全加器组成。由真值表可知,如果W4n=0,当n∈[0,31]时,则不会出现错误计算。采用闪电测绘法,当0⩽W4n⩽3时,不存在数字计算误差。因此,作者有意将在[0,3]范围内的W4n通过该压缩器计算,从而减少其计算误差,所以在文中作者提出“该压缩器影响不大”,但据笔者复现结果显示,误差最大达24.9%,与文中浅白色标注21.875%相近,该压缩器具有一定的局限性和显著的误差。除此之外,作者提出了双正则化的训练方法,如图所示,在每个训练时期,训练的权重被分为两组,不满意的权重组 Wa和理想的权重组Wb。Wa包含映射ID为4n且大于x或小于0的权重,而Wb包含其余权重。对于Wa,采用稀疏正则化(L1)来限制权重值范围。对于Wb,使用正常正则化(L2),这与普通训练过程相同。

图3 压缩器结构&双正则化训练
关于ASQC的设计,ASQC包含三种功能:一种比较器、一种计数器和一种SAR ADC,它具有三个阶段来量化模拟MAC值:(1)模拟存储(AS)阶段。AS阶段通常包含多个周期以延长累积长度并降低功率。AS阶段,Ceven和Codd之一将被HAU/LAU充电,而另一个将放电到地。一旦充电容量电压达到触发值,两者就会进行切换,计数器加一。当一个累积周期结束时,充电容量中的剩余电荷将被存储并成为下一周期的初始电压。引入虚拟电容以消除因开关引起的电荷损失。(2)SAR-ADC阶段。一旦所有累加周期结束,残余电压将由SAR-ADC量化以保留所有模拟值。最终的数字转换器值为k·Qc[5:0]+Qsar[5:0],可以实现输出比1。(3)复位阶段。量化后,所有容量、计数器和SAR-ADC将在下一个转换器周期设置为零。如图4所示,为其操作时序与结构简述图。
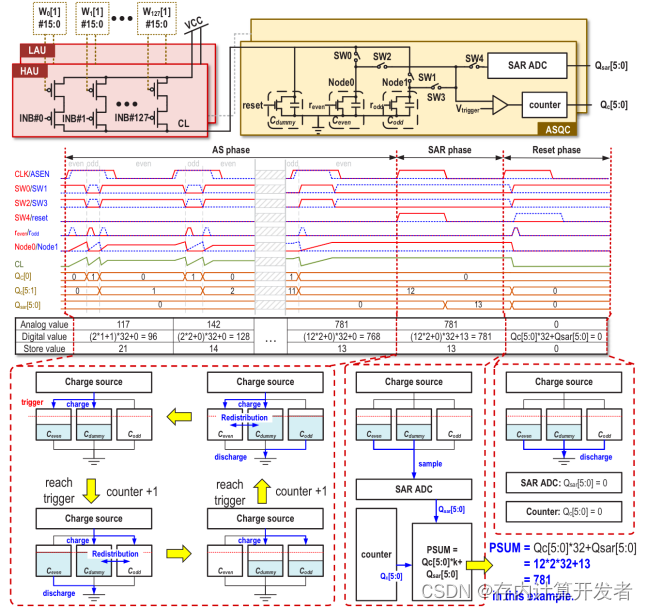
图4 ASQC模块的时序&结构
接下来我们将以创新点2:近似压缩器的设计为重点,从本论文的近似电路仿真出发,介绍近3年的近似计算技术相关的高水平论文,旨在为读者详细介绍近似计算技术的原理和特点等[1]。
如图1(a)所示,为本篇论文中基于或非门的4:2近似压缩器电路示意图,该近似压缩器由一个或非门和一个28T全加器组成,图1(c)为近似压缩器真值表,可以看出有25%的概率产生“-1”的误差,近似压缩器之后为传统精确加法器树。以256并行度的加法器树为例,传统精确加法器树大约需要10486个晶体管,该近似加法器树大约需要7186个晶体管,节省了31.47%的面积。如图1(b)所示,为256并行度的近似加法器树的仿真结果,采用的仿真指标为RMSE和真值表分析。平均RMSE(均方根误差,Root Mean Square Error)为7.72%,最大RMSE为24.90%。以上分析体现了近似计算技术以有限误差为代价,减小所需面积和功耗的原理。
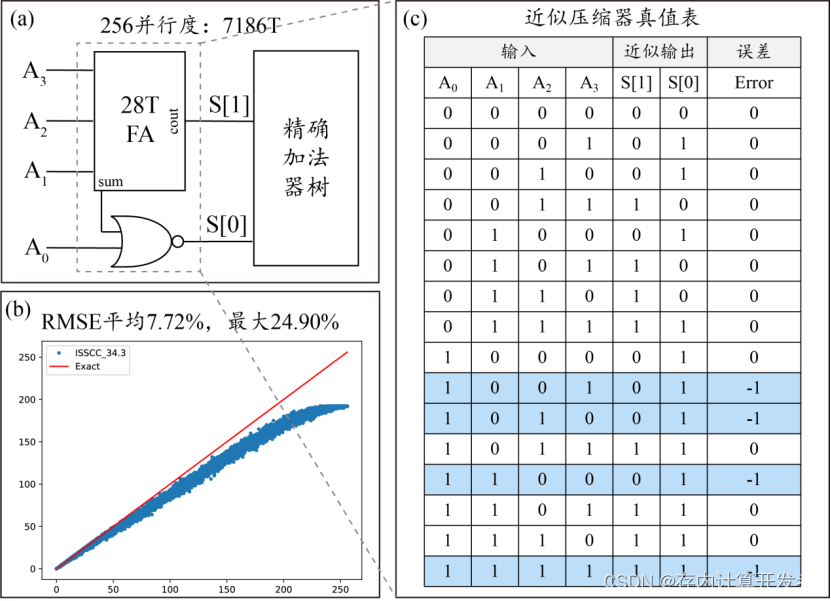
图 5 近似压缩器示意图:(a)基于或非门的4:2近似压缩器电路;(b)近似加法器树仿真结果;(c)近似压缩器真值表
近似计算是一种新兴的计算范式,其核心是在允许一定误差存在的前提下,通过可容忍的精度损失降低硬件开销,从而实现计算效率的提升。
近似计算的思想早在20世纪60年代就得到了应用。自2008年左右以来,随着AI模型训练所需算力的提升,近似加法器和乘法器受到了极大的关注,目前近似加法器主要有推测加法器、分段加法器、近似进位选择加法器和近似全加法器等设计方案;近似乘法器主要有保存进位乘法器、使用近似计数或压缩器、使用对数近似等设计方案[2]。近似加法器和乘法器已经集成在AI深度学习加速器中,用于减少延迟、面积、功耗等,取得了优异的成果,具有非常广阔的应用前景。
具体到近年发表的文献中,近似计算方案也有所体现:
(1)压缩器近似[3]
DIMCA方案发表于JSSC 2023,该文献采用和34.3类似的压缩器思路,具体设计和性能评估如下图所示。该设计使用压缩器结构设计替换掉加法树的低位部分,压缩器设计本身相较于同等输入尺寸加法树设计会节约部分晶体管,同时该设计会节约输出比特数,二者共同作用实现了晶体管的节省。本文先的压缩器方案参考自文献[4],同时该文献对后续的加法树部分设计进行改进,优化了加法计算的进位速度。笔者认为,随着加法树输入并行度的增大,压缩器近似设计必然会导致输出偏小,该设计对于网络的影响可能因网络的输入分布而异。不同于34.3,该文献通过较低的RMSE来降低近似设计对网络推理效果的影响。

图6 DIMCA设计
(2)乘法器近似[5]
在ISSCC2023中,清华大学报告了一种乘法器的近似设计。该设计参考自传统的绝对值差分计算,将其中L1距离替换为L2距离,用于乘法计算,称为绝对差分运算(ADO)。它将原本的乘累加计算拆解,可以替换掉传统设计中的乘法器,实现乘法功能所需的硬件成本。

图7 ADO乘法器设计
(3)加法树低位近似[6]
在稍早的严重中,常提到一种将加法树中较低位的全加器和半加器替换为与门、或门的近似方法。如文献[6]所提出的OLOCA设计。该设计结构图如下所示,高nh-1位采用精确计算,低nl位采用或门和全通设计,第l位使用与门和或非门代替半加器。通过配置nh和nl的比例,对加法树的计算误差进行控制。
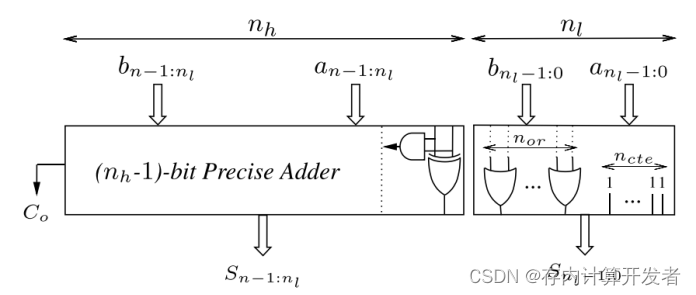
图8 低位近似加法树示意图
综上,近似计算的范式设计的出发点都是为了节省晶体管个数、降低计算电路面积、提高计算电路能效比。这类设计的重点在于,如何降低近似带来的影响,一方面,可以寻找神经网络、图像处理等容错性较高的应用场景;另一方面,可以考虑近似误差低的硬件结构;也可以如本篇论文所做的,进行人为限制,降低近似计算电路的参与度。
参考文献:


