



4,691
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享视频链接:入门篇【2】Transformer 架构界的变形金刚_哔哩哔哩_bilibili
本次课程深入探讨了深度学习模型中Transformers架构的革命性引入及其对传统RNN限制的突破。回顾了IN模型及其对序列处理的依赖后,转而研究了Google于2017年提出的"Attention is All You Need"论文,该论文提出了一个摒弃循环的全新架构,仅依靠自注意力机制,显著改善了并行处理能力,加快了训练速度。同时,通过全连接层(密集网络)的应用,有效解决了RNN的瓶颈问题之一—序列信息处理的效率低下。

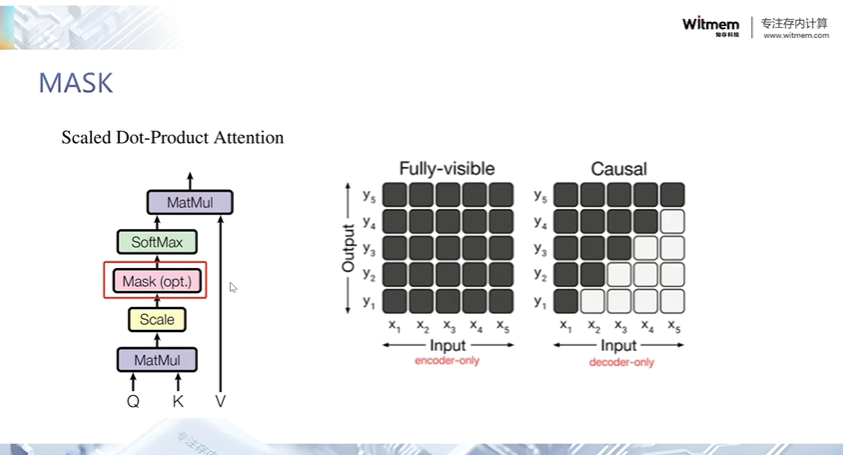
课程还讨论了加入位置嵌入的方法,这有助于保持对词序的关键信息理解,是理解语言的基础。通过对Transformer的介绍,不仅展现了其在自然语言处理任务中的卓越性能,也为未来深度学习架构的发展开辟了新纪元。随后,重点转向了注意力机制和掩码的详细解析,阐释了如何通过Softmax函数和掩码限制,精确控制模型的注意力集中区域,从而提升预测的准确性和可靠性。通过Transformer和注意力机制的深度分析,揭示了现代深度学习在处理自然语言任务方面的巨大潜力和广阔前景。
当谈到循环神经网络(RNN)的缺陷时,最明显的问题之一就是其无法进行有效的并行运算。这一点在处理长序列时尤为显著,因为每个时间步都依赖于前一个时间步的输出。这导致了计算的串行化,使得训练和推理过程变得相当耗时。
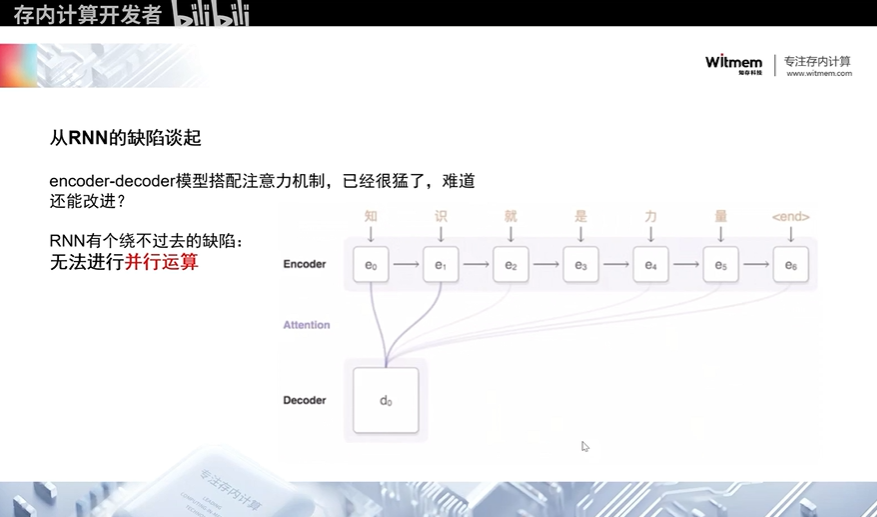
尽管RNN存在这些缺陷,但随着深度学习领域的不断发展,研究人员提出了许多改进的方法。其中一个突破性的进展是引入了注意力机制,尤其是在encoder-decoder模型中的应用。这种模型结构允许网络在处理长序列时聚焦于关键部分,从而提高了性能和效率。encoder-decoder模型搭配注意力机制已经相当强大,但仍然存在改进的空间。例如,可以进一步探索不同类型的注意力机制,以适应不同的任务和数据特征。此外,可以结合其他网络结构或引入更高级的架构来进一步提高模型的性能和泛化能力。
尽管RNN存在一些不可避免的缺陷,但通过不断创新和改进,我们可以不断提高模型的性能,并开发出更加高效和强大的神经网络模型。
完全舍弃CNN和RNN,只使用深度神经网络取决于任务和数据的特性。
对于某些特定类型的数据,例如结构化数据或具有固定长度输入的数据,DNN是一个很好的选择。在这种情况下,可以使用多个全连接层来构建一个深度的神经网络,通过这些层来提取特征并进行预测。可以使用不同的激活函数、正则化技术和优化算法来调整网络的性能。
但对于序列数据或图像数据等具有结构化特征的数据,完全舍弃CNN和RNN会限制模型的表达能力。因为CNN和RNN分别对于处理空间结构和时间结构的数据具有很强的能力。在这种情况下,需要仔细设计DNN的架构,以确保它能够有效地捕捉到数据中的相关特征。
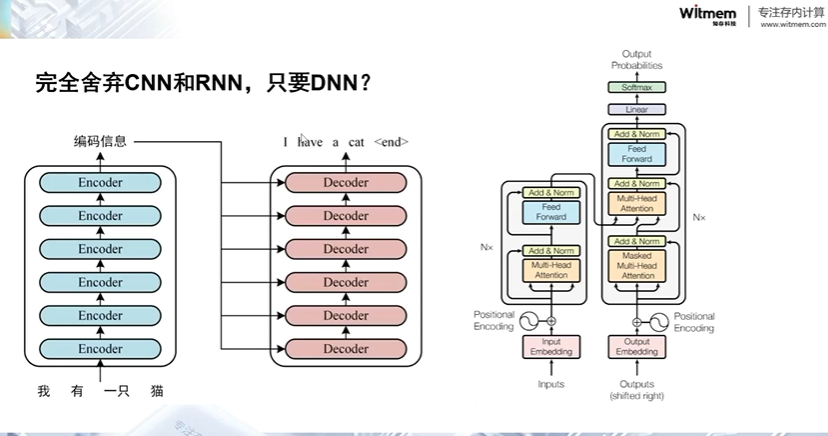
虽然完全舍弃CNN和RNN并仅使用DNN会增加一些挑战,但这并不意味着是不可能的。关键在于深入了解要处理的数据类型和任务,以确定最适合的模型结构。
DNN的核心运算是矩阵乘法,这使得它们能够在大规模并行计算环境中高效运行。如下图
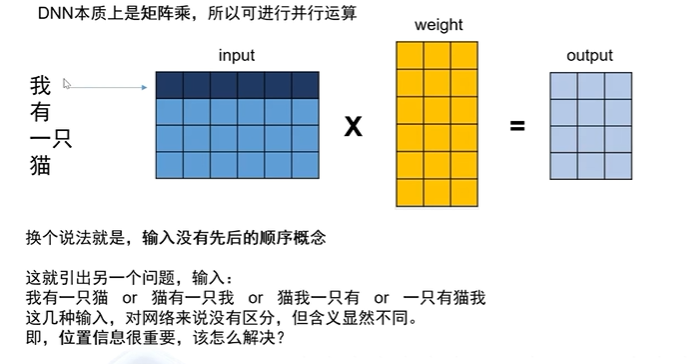
在处理自然语言处理(NLP)任务时,词语的顺序通常承载着重要的语义信息。这就引出了一个重要问题:在网络中如何处理位置信息?
一种解决方法是引入位置编码,这样网络就能够区分不同位置的单词或标记。常见的位置编码方法包括使用正弦和余弦函数的位置嵌入或可学习的位置编码(Learned Positional Encoding)。
另一个方法是使用序列模型(Sequence Models),例如循环神经网络(RNN)或长短期记忆网络(LSTM)。这些模型能够考虑到输入数据的顺序,并根据上下文调整其内部状态,从而更好地理解语义信息。
引入注意力机制(Attention Mechanism)也是一种有效的方法。注意力机制允许网络根据输入中不同位置的重要性来调整其关注度,使网络能够更好地处理位置信息。
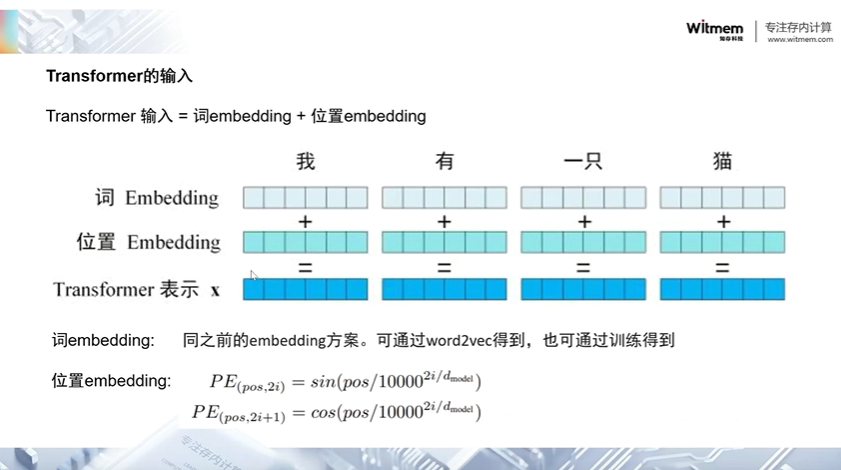
Transformer 模型的输入通常包括两部分:标记(tokens)序列和位置编码(positional encoding)。
标记序列(Tokens Sequence):标记序列是模型的主要输入,它表示了待处理的文本或序列数据。在自然语言处理任务中,标记通常是单词、子词或字符的序列,每个标记通常由一个唯一的整数索引表示。这些标记首先经过嵌入层(embedding layer)进行词嵌入(word embedding)或标记嵌入(token embedding),将每个标记转换为一个高维度的向量表示。
位置编码(Positional Encoding):由于 Transformer 模型没有像 RNN 或 CNN 那样的内部状态来捕捉序列中的顺序信息,因此需要通过位置编码来注入位置信息。位置编码是一个与标记序列具有相同维度的矩阵,它通过将位置信息编码成特定的向量添加到标记的嵌入向量中来表示每个标记的位置。通常使用正弦和余弦函数或学习得到的位置编码来实现这一目的。
Transformer 模型的输入由标记序列和位置编码组成。标记序列表示待处理的文本或序列数据,而位置编码则注入了每个标记的位置信息,使得模型能够更好地理解序列数据中的顺序信息。
Transformer 模型的核心是注意力机制,它允许模型在处理输入序列时动态地分配注意力权重。Transformer 模型由编码器(encoder)和解码器(decoder)两个部分组成。每个编码器和解码器都包含多层自注意力机制和前馈神经网络。
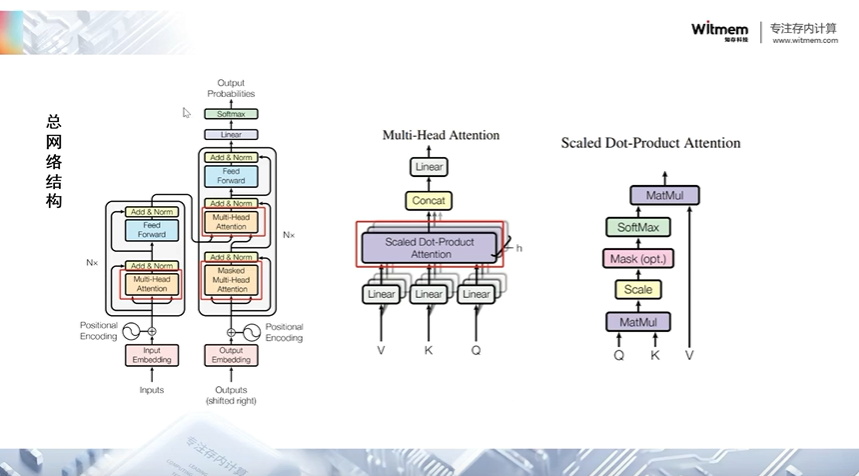
自注意力机制允许模型同时考虑输入序列中不同位置的信息,并据此计算每个位置的表示。这使得模型能够处理序列中的长距离依赖关系,并且不需要像循环神经网络(RNN)或卷积神经网络(CNN)那样的固定结构。
在自注意力机制中,输入序列被映射到查询(Query)、键(Key)和值(Value)空间。然后,通过计算查询和键之间的点积,并对其进行缩放,得到每个查询对所有键的注意力分布。最后,通过将这些注意力分布与值进行加权求和,得到最终的输出。
多头注意力机制则是通过在每个注意力机制操作中使用多组查询、键和值来提高模型的表达能力。每个注意力头都学习到不同的表示,然后这些表示被连接并输入到下一层网络中。
多头注意力(Multi-Head Attention)是 Transformer 模型中的一个关键组件,它允许模型在同一时间关注输入序列的不同部分,并从多个角度对输入进行编码。
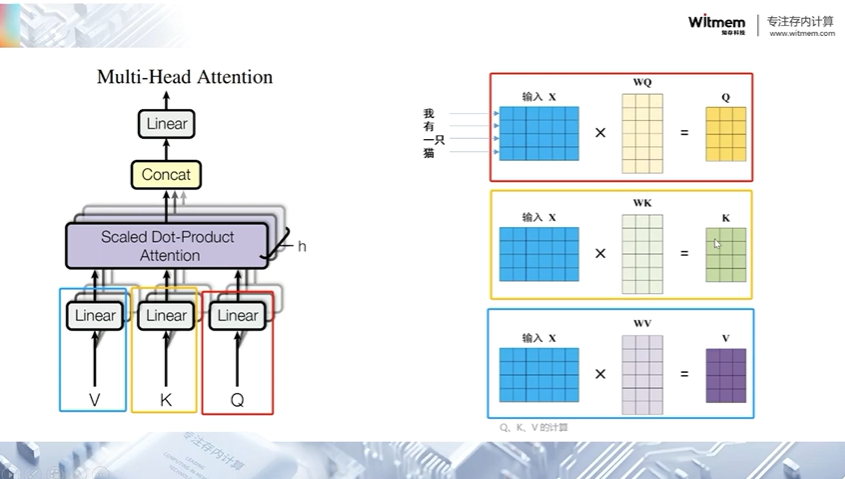
在多头注意力机制中,输入序列经过线性变换,然后被分割成多个头(heads)。每个头都有自己的查询(Query)、键(Key)和值(Value)的表示。然后,每个头都通过独立的注意力机制计算出注意力权重,这些权重用来加权求和对应头的值。最后,多个头的输出被拼接在一起,并经过另一个线性变换,生成最终的多头注意力输出。
通过引入多头机制,模型能够同时从不同的表示空间中学习到不同的特征,并允许模型在不同的方面进行关注。这种多头机制可以增加模型的表达能力,并允许模型在处理复杂的输入数据时更加灵活地捕获特征。
缩放点积注意力(Scaled Dot-Product Attention)是 Transformer 模型中的一种注意力机制,用于计算注意力权重并将其应用于值序列。
点积计算(Dot Product):将查询向量(Q)和键向量(K)进行点积运算,得到一个分数矩阵,表示了查询与键之间的相关性。具体而言,对于给定的查询向量 Q 和键向量 K,点积计算如下所示:

在缩放点积注意力中,给定一个查询向量 q 和一组键值对 (k, v),计算方法如下:
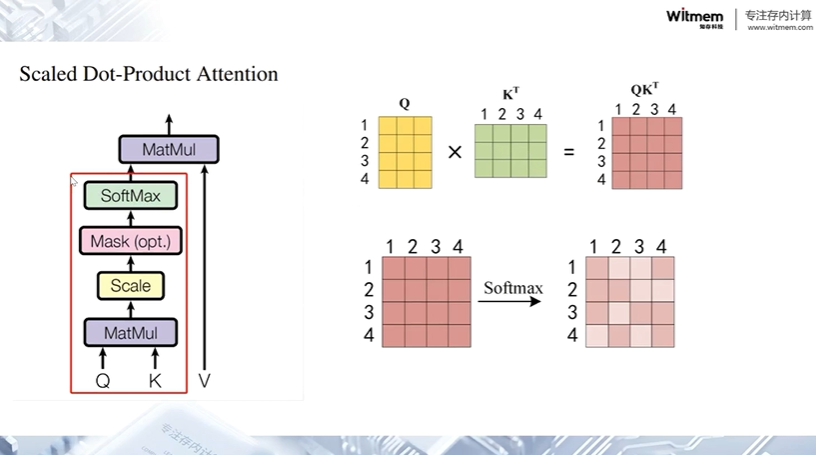
缩放点积注意力的优点在于它的计算效率高,复杂度为 O(n),其中 n 是查询的维度。这使得它在处理大规模数据时具有较好的性能。
缩放(Scaling):为了控制点积的大小,避免因维度较大导致的梯度消失问题,通常会将点积结果除以缩放因子 。
Softmax 归一化:对缩放后的点积结果应用 softmax 函数,将得分转换为注意力权重。这些权重表示了每个键在给定查询下的重要性。
加权求和:使用注意力权重对值向量(V)进行加权求和,得到最终的注意力输出。具体而言,对于每个查询向量 Q
在 Transformer 模型中,缩放点积注意力被应用于自注意力机制(self-attention),它允许模型在处理输入序列时动态地分配注意力权重,并学习输入序列中不同位置之间的关系。缩放点积注意力是 Transformer 模型中编码器和解码器的核心组件之一,为模型提供了建模序列依赖关系的能力,从而在各种自然语言处理任务中取得了优异的性能。
这篇文章深入探讨了Transformer架构在深度学习模型中的革命性引入以及对传统RNN限制的突破。它回顾了传统的RNN模型的缺陷,特别是在处理长序列时的串行计算限制,并介绍了Google于2017年提出的"Attention is All You Need"论文所引入的Transformer架构。
在视频中强调了Transformer架构的关键组成部分,包括自注意力机制和多头注意力机制。这些机制允许模型同时考虑输入序列中不同位置的信息,并在处理序列时动态地分配注意力权重,从而显著改善了模型的并行处理能力和训练速度。还介绍了Transformer模型的输入和总体结构,以及其中关键的缩放点积注意力机制。这一机制通过点积计算、缩放和Softmax归一化来计算注意力权重,并将其应用于值序列,从而实现了有效的注意力集中和信息提取。
视频还强调了Transformer模型在处理自然语言处理任务中的卓越性能和广阔前景,同时也指出了继续探索和改进的空间,以进一步提高模型的性能和泛化能力。

本篇文章总结视频链接:入门篇【2】Transformer 架构界的变形金刚_哔哩哔哩_bilibili



