


301
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享本单元UML图
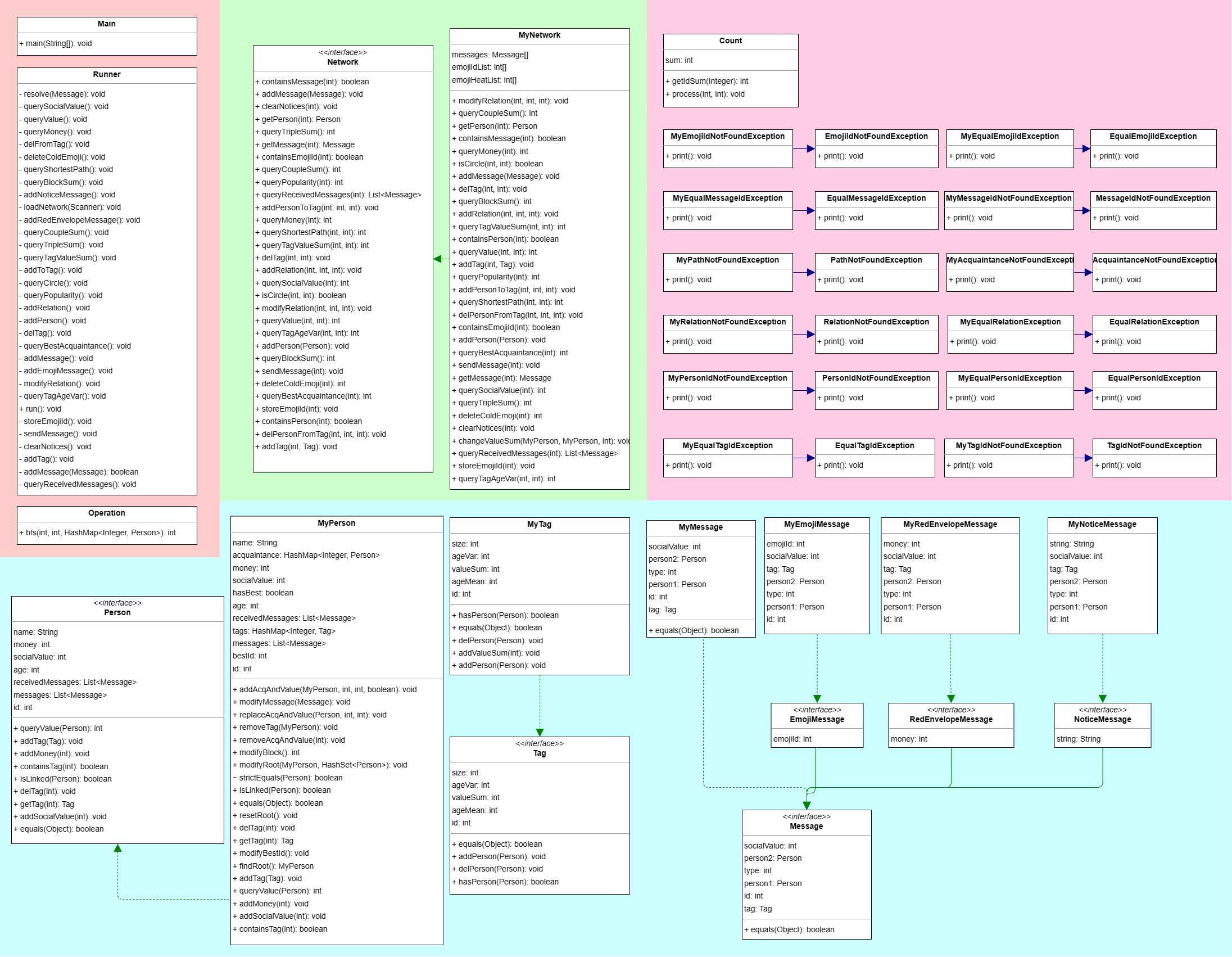
架构
设置Count类记录各种异常的发生情况。其他类和JML要求一致。
优化
容器选择
看到JML中的Person[] 、int[]很容易想到换个容器存放,查询时会更快一些。
查询时,遍历数组复杂度为𝑂(𝑛),而以id为key的HashMap复杂度为𝑂(1),并且本次作业中的容器中的元素不涉及顺序要求,因此选择HashMap作为容器。
MyNetwork类:
private final HashMap<Integer, Person> persons; // <person.getId(), person>
MyPerson类:
private final HashMap<Integer, Person> acquaintance; // <neighbor.getId(), neighbor>
private final HashMap<Integer, Integer> value; // <neighbor.getId(), neighbor.queryValue(this)>
算法选择
本次作业如果完全按照JML书写,会发现isCircle方法复杂度较高。该方法抽象出来其实是在判断无向图的两点是否连通。
起初我想用DFS实现,考虑到时间复杂度较高,如果不断问询两点是否连通,极易导致TLE,以及考虑到课程组应该就是想拿这个卡我们,于是我在同学的帮助下,使用并查集对此方法做优化。
并查集,实际上就是将一张图分为一个个连通块,同一块内任意两点可达,不同块中的两点不连通。我为每个块设置了一个根节点root,并对MyNetwork类中涉及根节点的方法做修改:
addPerson(Person person):孤立的点的根节点指向自身;addRelation(int id1, int id2, int value):如果两点的根节点相同(加边前,两点在同一个块中),根节点不做修改;否则,小块向大块合并(DFS,将块更小的一方中的所有点的根节点 设置为 块更大的一方中的所有点的根节点)(确保一个块只能有唯一的根节点);modifyRelation(int id1, int id2, int value):若modify后两点间value大于零,则根节点不做修改;否则(即两点间删边),重新找根节点(将 根节点指向旧根节点的所有点 的根节点指向自身,对id1进行DFS,将与id1连通的所有点的根节点设置为id1,此时,若id2的根节点为id1(意味着删边后,id1和id2依然连通),则停止操作,否则,对id2进行DFS,将与id2连通的所有点的根节点设置为id2)(通俗讲就是先将所有点变为孤立,然后依据原先的边重新寻根);isCircle(int id1, int id2):有了以上的并查集建立、更新基础,判断两点是否连通,即判断两点的根节点是否相同,相同则连通,不相同则不连通。动态维护
queryBlockSum():求块的个数,实际上也是在找连通。依据已经建立好的并查集,我设置了一个HashMap<Person, Integer> block,用以记录每个块的根节点和该块的大小,block.size()就是queryBlockSum()的返回值。同时,记录每个块的大小,方便了addPerson(Person person)中 “小块往大块上合并” 时块的大小判断——小块往大块上合并,能减少时间复杂度。
queryTripleSum():计算图中三角形的个数。我设置tripleSum记录当前三角形个数,tripleSum动态维护思路如下:
addRelation:
tripleSum = tripleSum + id1 与 id2 交集个数
deleteRelation:
tripleSum = tripleSum - id1 与 id2 交集个数
方法合并
上述提到,我设置了HashMap<Person, Integer> block,如果每次单独计算每个块的大小,无疑会增加耗时,而每次块的大小发生改变时,都会重新寻找根节点,借助这一特性,我将块大小的计算和寻根过程合并,减少DFS次数。
public int modifyBlock() {
HashSet<Person> visited = new HashSet<>();
this.modifyRoot(this, visited);
return visited.size(); // 块的大小
}
public void modifyRoot(MyPerson person, HashSet<Person> visited) { // DFS
if (visited.contains(this)) {
return;
}
this.root = person;
visited.add(this);
for (Person neighbor : this.acquaintance.values()) {
((MyPerson) neighbor).modifyRoot(person, visited);
}
}
复杂度(截取部分)
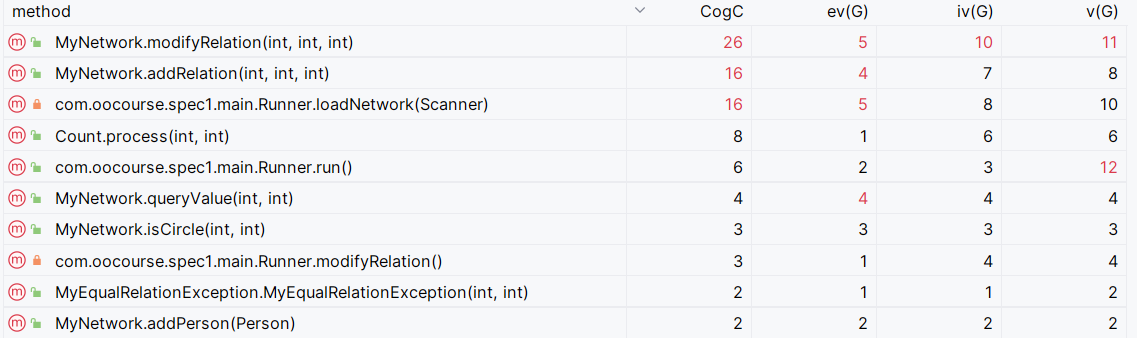
并查集的使用导致isCircle方法复杂度大大降低;
modifyRelation、addRelation方法中都涉及重新寻根的操作,复杂度较高。
架构
设置Count类记录各种异常的发生情况。其他类和JML要求一致。
优化
容器选择
沿用上次作业的思路,用HashMap作为容器。
MyPerson类:
private final HashMap<Integer, Tag> tags; // <tag.getId(), tag>
MyTag类:
private final HashMap<Integer, Person> persons; // <person.getId(), person>
算法选择
queryShortestPath(int id1, int id2)抽象后实际是在求两点间的路径长-1。我采用了广度优先算法计算(感觉是个常规做法(?,有考虑过记录两点间路径长,但两点之间加边删边因素太多,遂作罢)
还要注意自己到自己的最短路径查询,按照JML要求,应该为0,而不是BFS做出来的-1。
写的时候一直觉得queryShortestPath(int id1, int id2)是这次tle考察重点,结果又压错题啦
动态维护
MyPerson类中记录BestAcquaintanceId:queryBestAcquaintance(int id)和queryCoupleSum()方法中都涉及到寻找某个人的bestAcquaintance,因此,不妨将每个person的BestAcquaintance记录下来。在MyPerson类,我设置了
private boolean hasBest; // 用以记录该人是否有bestAcquaintance
private int bestId; // 该人bestAcquaintance的id
addAcqAndValue:
if (!hasBest) { // 原来没有 bestId
bestId = id;
hasBest = true;
} else if (value > this.value.get(bestId)) { // 原来有 bestId,现在的 value 更大
bestId = id;
} else if (value == this.value.get(bestId) && id < bestId) { //原来有bestId,现在的value一样大,现在的id更小
bestId = id;
}
replaceAcqAndValue:
if (value > oldBestValue) { // value 大于 bestValue,更新 bestId
bestId = id;
} else if (value == oldBestValue && id < bestId) { // value 等于 bestValue,且 id 更小
bestId = id;
} else if (id == bestId && value < oldValue) { // 修改bestId且value变小,要重新寻找
modifyBestId();
}
removeAcqAndValue:
if (id == bestId) { // 删去bestId对应的边,要重新寻找
modifyBestId();
}
MyTag类中动态维护 ageSum:addPerson时ageSum = ageSum + person.getAge();,delPerson时ageSum = ageSum - person.getAge();,较为简单,避免了每次查询总和的遍历导致的时间损耗。
(强测CPU_TLE,debug时维护)MyTag类中动态维护 valueSum:
addPerson与delPerson时维护较为简单:
addPerson:
for (Person p : persons.values()) {
valueSum = valueSum + p.queryValue(person) * 2;
}
delPerson:
for (Person p : persons.values()) {
valueSum = valueSum - person.queryValue(p) * 2;
}
难点在于,addRelation和modifyRelation时会改变两人间的value,哪些tag中包括两人、如何通知对应的tag,这需要我们对于JML的信息有深刻的理解(显然强测结果出来之前我并没有很理解)。
经同学提示,我明白了,只有两人的共同邻居,其tag中的persons可能会存放两人,故addRelation和modifyRelation中需要查找两人的共同邻居,遍历共同邻居的tags,若tag中的persons包含这两人,则维护该tag中的valueSum。
MyNetwork:
public void changeValueSum(MyPerson person1, MyPerson person2, int value) {
for (Person third : person1.getAcquaintance().values()) {
if (third != person2 && third.isLinked(person2)) {
for (Tag tag : ((MyPerson) third).getTags().values()) {
if (tag.hasPerson(person1) && tag.hasPerson(person2)) {
((MyTag) tag).addValueSum(value);
}
}
}
}
}
MyTag:
public void addValueSum(int num) {
valueSum = valueSum + num * 2;
}
复杂度(截取部分)
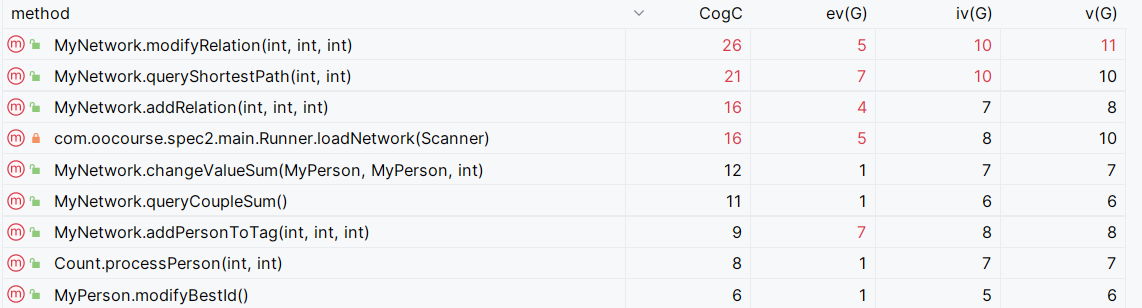
modifyRelation、addRelation方法不仅承担了并查集的更新,还与changeValueSum方法一起承担了tag中valueSum的维护,三者复杂度较高。
queryShortestPath方法采用BFS,复杂度较高。
queryCoupleSum()和modifyBest()方法分别需要遍历persons和acquaintances,复杂度较高。
架构
设置Count类记录各种异常的发生情况。
设置Operation类执行MyNetwork类中的部分操作(因为超行了)。
其他类和JML要求一致。
优化
容器选择
MyNetwork类:该类中的messages不涉及顺序要求,故用HashMap存放。
private HashMap<Integer, Message> messages; // <message.getId(), message>
将该类中的int[] emojiIdList和int[] emojiHeatList合并为HashMap<Integer, Integer> emojis。
private HashMap<Integer, Integer> emojis; // <id, heat>
MyPerson类:该类中的messages涉及顺序要求,插入删除操作较多,可用LinkedList存放。(其实我用了ArrayList,,好在强测过了)
private LinkedList<Message> messages;
算法选择
有点不知道这次作业想让我优化什么
方法合并
对于sendMessage(int id),第二种require中有多次判断、多次遍历persons,采取在一次遍历中多次判断来实现。
复杂度(截取部分)
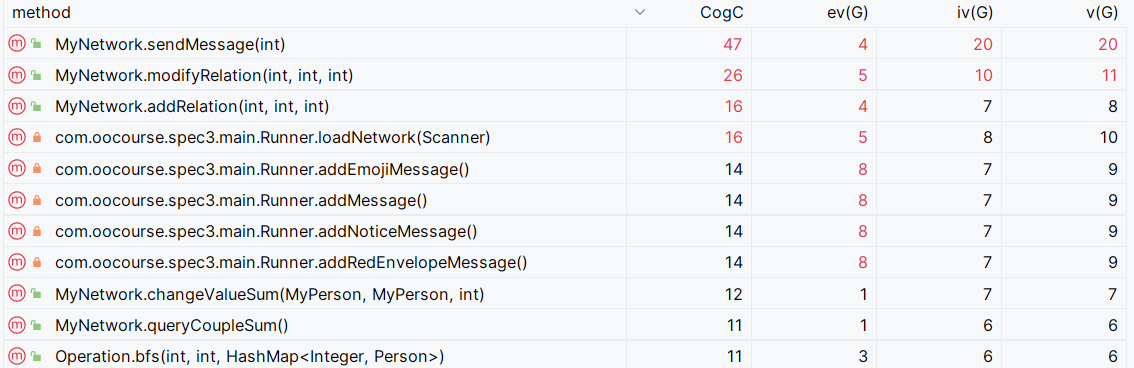
sendMessage(int id)涉及各种message的判断,并对不同类型的message做出响应:改变socialValue或者遍历对应的person、修改person属性。复杂度较高。
数据生成
这部分我仿照了实验的test,首先向图中添加足够多的person,接着随机生成指令,三次迭代下来,我向图中实现了addRelation(id1, id2, value)、modifyRelation(id1, id2, value)、 add emojiMessage、add noticeMessage、add redEnvelopeMessage、storeEmojiId(id)、sendMessage(id)这几种方法,尽可能的覆盖图的构建方法。
除此之外,为保证完全覆盖图的可能情况,我额外捏了一些特殊图,在随机生成之后又手动加入了完全图、全是孤立点的图。
同时,我注意到,要求测试的方法中要比较调用前后的对象数组,而单纯的getXXX是浅克隆,在同学的提示下,我创建了影子图,前期构建时,shadow的操作同MyNetwork,最后对myNetwork调用需测试的方法、对shadow不做操作,由此,我们可以将shadow看作调用前的对象、将myNetwork看作调用后的对象。避免了浅克隆带来的对象的改变问题。
test编写
这一部分就老老实实按照JML编写即可。一些心得:
pureensures的判断ensures判断处输出一些信息,以此来看我们构造的数据是否成功覆盖该ensures在三次junit编写过程中,我都通过junit找到了自己的bug()。
不过不是要求测试的方法的bug,而是我在构造数据的过程中,基本上实现了图的各种构造方法(尤其是modifyRelation方法),于是就找到了构造方法的bug。
hw9中,起初我的并查集找根节点没完全写对,对于删边情况的判断不完全,这时test生成大量的随机数据,一下子就找到了root可能为空指针这一问题。
hw10中,modifyRelation又又又出了一点问题,test测试测出来了空指针。
hw11中,Network类的JML变动了一次,我对着旧版写了MyNetwork,对着新版写了test,test测试说明异常抛出错误。
总而言之,我觉得junit是一个很好的工具。因为在自己手工捏数据时,总是会按照自己的固有思维来,于是跑自己写的代码总是正确的,而junit可以随机生成大量数据,避免了这一问题。并且相比较对拍类型的测评机来说,junit测试是完全按照JML实现的,正确性更强(毕竟对拍的话可能两人错一块去了)。
单元测试:
单元测试是对代码中最小可测试单元的测试。对单个方法或者类的测试,编写测试用例,模拟输入和输出,然后验证实际输出是否符合预期结果,比如junit测试。
功能测试:
对整个功能或模块的测试,通常是从用户的角度出发,测试系统是否符合需求和规格说明。比如分别测试isCircle、queryBlockSum、queryTripleSum,queryTagAgeVar、queryBestAcquaintance、queryCoupleSum等方法。
集成测试:
测试不同模块之间的交互是否正常工作。比如,涉及多个类的多条不同指令混合出现,测试正确性。
压力测试:
测试系统在负载增加的情况下的稳定性和性能。比如电梯单元在同一时刻输入大量数据,检测正确性、稳定性;又比如本单元反复输入多个queryCoupleSum等,检测空间、时间性能。
回归测试:
在新的迭代之后,重新检测原有功能是否能正常实现。
isCircle、queryBlockSum、queryTripleSum,hw10关注了queryTagAgeVar、queryBestAcquaintance、queryCoupleSum,但忽略了queryTagValueSum,导致hw10中strong10 CPU_TLE。modifyRelation后,value如果与bestId对应的value相同的话,还应该比较id值的大小,再决定要不要修改bestId。针对此我捏了数据,与同学对拍,果然我是错的。myNetwork。hw9
强测、互测均没有问题。
hw10
强测strong10 Wa了。该点主要是连续不断地出现 addRelation/modifyRelation后询问tag的valueSum 或者 反复询问同一tag的valueSum。由于我完全按照JML实现、没有维护valueSum,导致每一次询问,都要遍历tag中的persons,复杂度为𝑂($𝑛^2$),于是造成了CPU_TLE。
修复方法见1.2 homework10 优化中 "MyTag类中动态维护 valueSum"。
hw10写代码的过程中,我对于tag和person之间的关系并没有很理解,尝试过维护valueSum。addPerson、delPerson中的valueSum的维护都比较好实现,当时我由于理解不到位,只做了modifyRelation中tag的valueSum的维护(而且现在想起来也是错的),没有考虑到addRelation也会导致tag中persons之间的value的改变。
hw11
强测、互测均没有问题。
规格与实现分离的理解
为了优化性能,我们需要将规格与实现分离:
在第一次接触到JML的时候,我就有一个疑问,可以不用JML中提供的容器实现吗——算起来,这是我规格与实现分离的初探。在面对大篇幅的BFS、DFS的时候,我会想有没有什么好的算法能避开这个东西;在for循环嵌套for循环,多次遍历获取同一个对象时,我会尝试将该对象记录下来、动态维护,减少每次遍历的时间损耗。
规格与实现分离,建立在完全理解规格要求的基础上:
正如hw10的tle,我认为我有将规格和实现分离的意识,但我并没有完全理解JML给出的关系,将规格和实现分离的能力较差,最终只好”翻译“,所以我觉得,规格与实现分离是建立在完全理解规格要求的基础上的,盲目的分离只会导致正确性的丢失。



