


301
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享黑箱测试:
数据整体采用了随机构造的策略,尽管不够好,但是个人认为还不错。个人认为数据构造需要考虑以下几个方面:
ln 100,这除了构造出一个大数据用来 hack 别人以外没有任何用处:难以 debug ,生成的图不见得覆盖了各种情况(实际上,能覆盖的情况少得可怜),并且写过 junit 的同学都知道 junit 不是增加数据量就能过的。多数同学的代码和世界上普遍代码一样:如果它在小数据范围正确,那么它在大数据范围也大概率是正确的。所有除非想要压力测试,否则完全没有必要ln 100,这只会徒徒增加 debug 复杂性。建议在测试正确性的时候用ln 10或者ln 15,因为足够了。qtvs定点爆破可能会取得不错的效果(900条qtvs都能hack到就离谱)messageId来生成emojiId去构造一个emojiMessage,导致自己搓的评测机完全测不出来的 bug 被别人轻松 hack 。这一部分主要叙述主流的解题思路和我采用的解题方法,不想看解题方法的思考过程的可以跳过。
这次作业完全就是数据结构&算法题,所以着重关注数据结构和算法。这次还是和第一次博客一样采用问题驱动型的方式来叙述我的解题思路。
1. 我们有哪些需求?
需求即为第九次作业需要支持的7种操作。此外,题目已经用JML规格为我们规定了一个邻接表,也就是Network中的persons和Person中的acquaintance,分别用来存储节点和节点的邻接节点们。如果用 V 表示节点数量,用 E 表示边的数量:
JML 遍历 O(V^2)分析后选用并查集来完成题目的解答,我们先看并查集。
2. 怎么使用并查集?
并查集的两个经典的优化分别是路径压缩 Path Compression和按秩合并 Union by rank。
可以发现并查集并不能直接套用在第九次作业上,因为并查集不支持删除边这一类操作。解决方法很简单,暴力重构即可。但是需要注意的是只需要重构删除的边所在的连通分量就行。重构分为两种情况:
此外,由于关系图可能会出现一条很长的链,所以深度优先搜索和路径压缩不能递归,否则有爆栈风险。
3. 是否要维护连通分量个数?是否要维护三阶完全子图个数?
个人认为后者必须,前者无所谓。
4. 需求分析。
通过第九次作业的复杂度分析可以发现,如果一个指令需要O(V)的时间,那么就绝对不会超时。但是如果是需要O(E),那么处于超时边缘。如果需要更多时间比如O(V^2),那么就完蛋了。
标签需要支持以下操作:
第十次作业几乎没有难点。主要问题集中在超时方面,也就是上面的操作7。在查询valueSum的时候有人没有维护valueSum。没维护也就罢了,偏偏用了O(V^2)的算法,导致互测直接超时。最舒服的方法应该是维护 valueSum,简单由实用,而且应该是我唯一能想到的不超时的方法。
此外,如果两个人决裂了,那么所有包含这两个人的tag都需要将这两个人的value给去掉,因为维护了valueSum。一个人只知道自己的tag都有哪些人,但是不知道自己在哪些tag中。因此我又维护了一个变量来让Network类知道每个人都在哪些tag当中。
此外方差可以用概统课上学的公式化简,注意不要化简错了就行。(这次方差的计算有很容易出错的取整问题,建议先算出公式再敲进IDEA中)
第十一次作业没有需要特别维护的变量,没有需要特别考虑的数据结构。除了将 JML 中的数组写为容器( HashMap HashSet ArrayList)等等没有任何特别之处。
此外没有什么特别的地方,个人认为没有必要进行叙述。本次作业也同样没有性能问题,也不进行叙述。
本次作业的简化UML图如下:
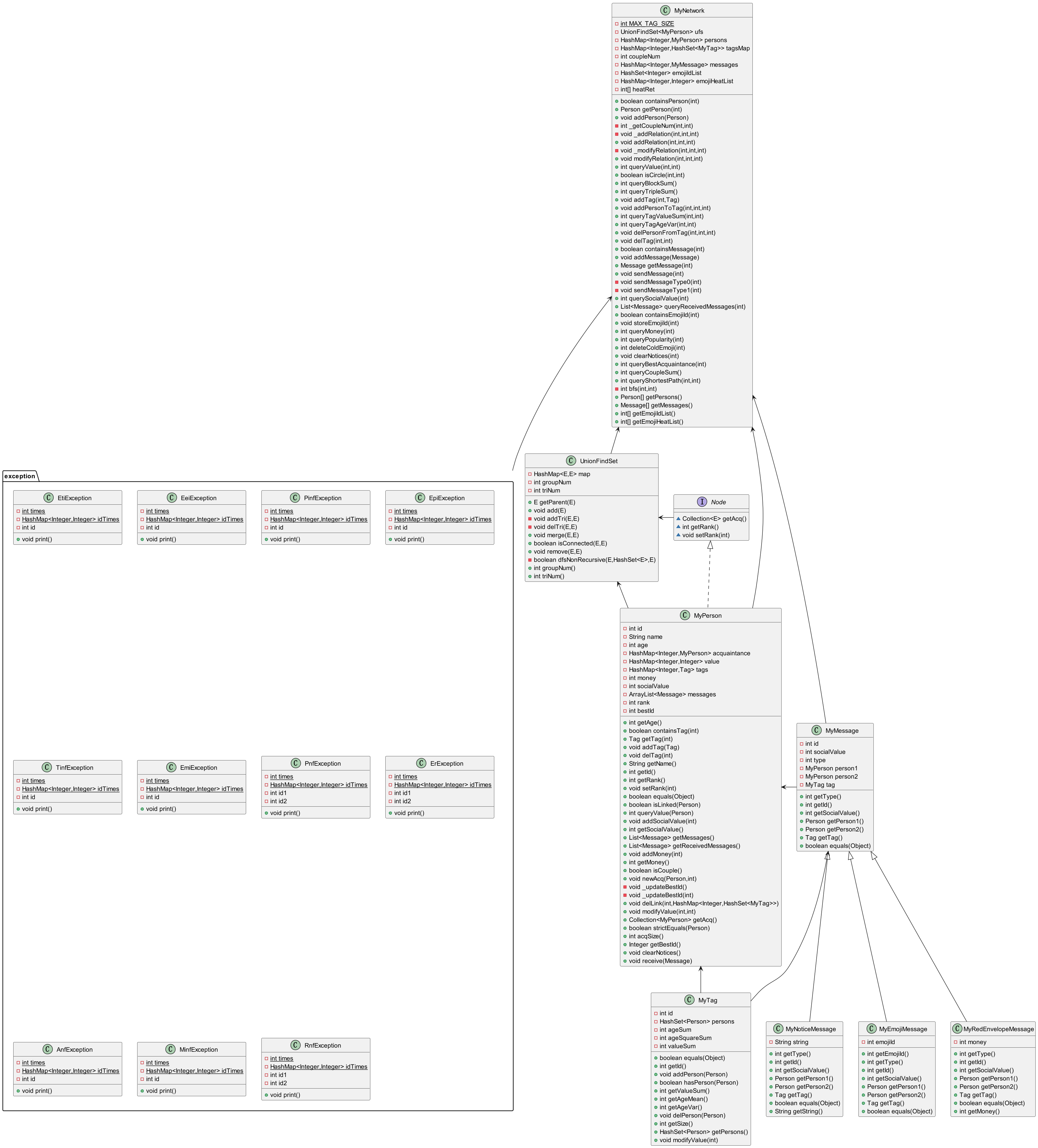
这次作业的复杂度也大概看了一圈。除去官方包的复杂度以外,剩余函数的复杂度主要来源于异常判断需要用到的if-else语句。所以整体设计还可以。
很庆幸,在第三单元本人没有出现性能问题,仅在正确性判断中出现了一些小bug而已。(显然第三单元的强测还是太弱了,第十次作业和第十一次作业强测都没有测出一个大bug,结果被第十一次的互测刀了)
上文已经分散地叙述过性能问题的产生、分析和避免,这里总结一下:
分析复杂度:
计算达到10^8量级会很危险,10^9量级基本爆10s,也就是超时。计算一波可以发现每一条指令的复杂度上限大概为:O(nlogn) or O(VlogV) or 小常数的O(E)
个人理解有以下几个方面:
一条路径和比其他路径都短两个方面,而不需要关心路径是如何得出的等具体实现。Junit测试在第三单元中,本人没有过多思考如何构建更好的Junit测试,而是完全按照 JML 完成 Junit 测试。利用 JML 进行 Junit 测试显然是不够好的,因为存在无法按照 JML 测试的情况,比如最短路径:我们显然不可能找出所有的路径然后取最短的值作为返回值。类似的情况还有很多。因此本人没有非常好的方法去进行具体的Junit测试。
虽然说JML可以进行形式化验证,但是个人感觉在一般的软件开发场景中也用不到。因此个人感觉最大的心得倒不是JML在形式化验证上的强大,而是契约式设计的强大之处。不论是个人的开发迭代,还是在团队合作完成项目,契约式设计都可以大大降低不同单元组件之间的衔接所需要花费的劳动。
同时,掌握契约式设计不仅仅可以应用在软件的开发和检测上。凡是需要涉及到不同单元组件组合成子系统之类的工程开发,都可以用到契约式实际。JML也十分符合面向对象的封装思想,将对外接口做出了相当精确的描述。之后的相关设计只要稍微复杂一点,个人认为都可以使用到JML背后的思想。
当然,另一方面,我也意识到JML拥有很大的弊病。比如JML并不关心实现细节,而只是考虑前置条件、后置条件、副作用等因素。这也会为开发者带来一定的困惑,比如如果开发者不能通过阅读JML规格来了解最短路径的实现,因而也不能正确地认识它的时间空间占用。
同时JML也为代码设计者带来了不小的挑战。代码设计者不仅仅要完成代码的编写,还需要完成JML的编写,这拓展了出错空间。而对于一些稍微难以描述的程序,其中的逻辑问题就成为了代码之外的新bug。如果设计者未能发现其他设计者的JML的bug,但是由需要使用到这一段JML对应的代码,就可能会出乱子。



