



301
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享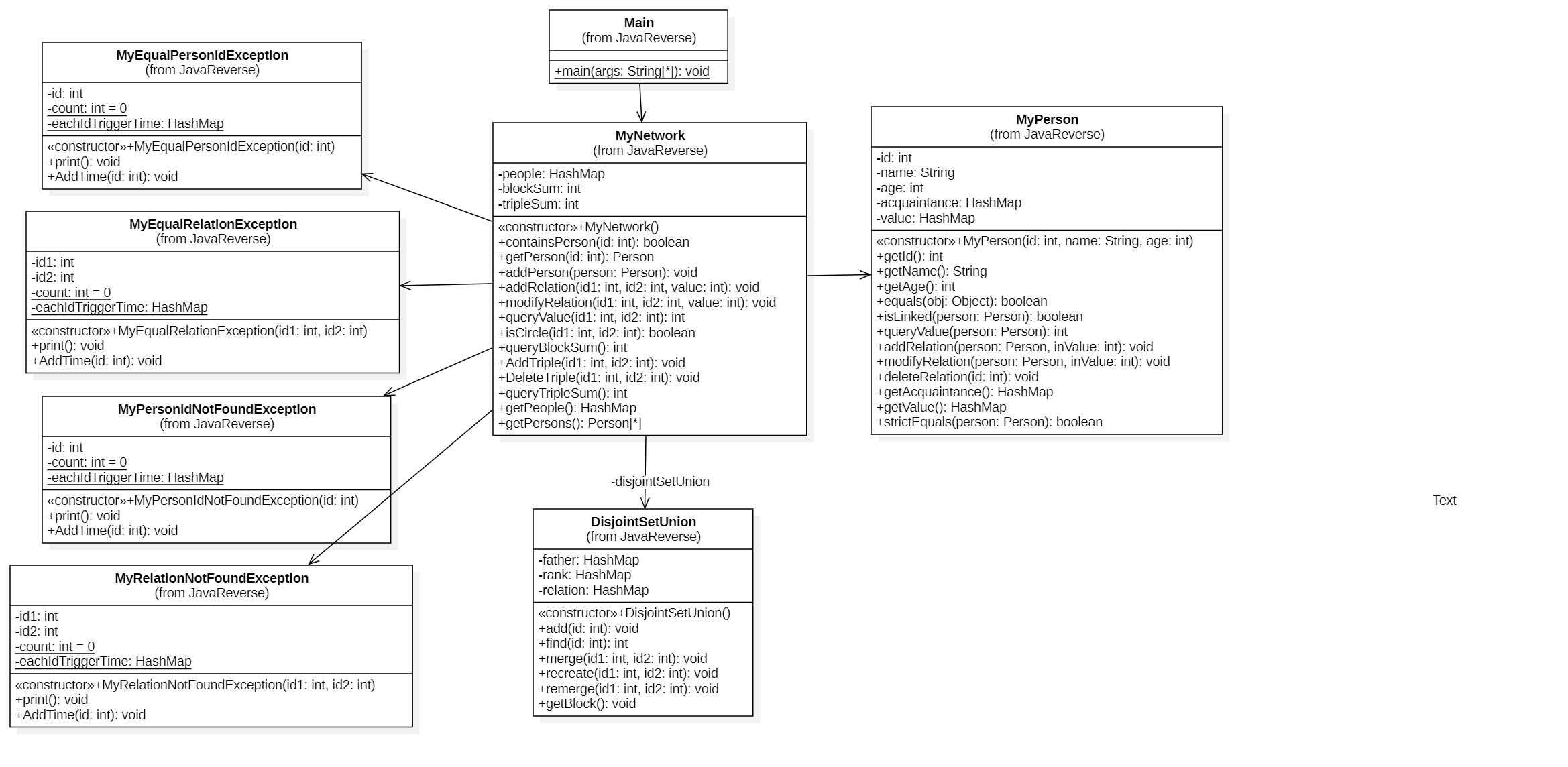
第一次作业的图还较为简单。MyNetwork为主图,其中每个MyPerson为一个节点,Person与Person之间的relation为边。每个MyPerson中记录了顶点的必要信息,包括id,name,age这些基本信息,以及一个熟人容器acquaintance,即相邻的节点,确保能够根据此找到点与点之间的联系,同时还有一个value,记录与熟人之间的关系值。
总的来说,图并不复杂,由于每个人都有唯一的id,数据容器方面选择了Hashmap,能够便于访问
同时,在这一次作业中的方法也都与图有关
| 方法名称 | 作用 |
|---|---|
addRelation | 在Network中添加一条边,即在图中增添一条边 |
modifyRelation | 修改两个Person的关系,带来的结果是value值的改变。且根据value的值,两个人之间的关系可能发生变化,即可能会导致图中边的删除 |
queryValue | 获得两个人之间的关系值 |
isCircle | 判断两个人是否有关系,即判断在Network图中两者是否连通 |
queryBlockSum | 即计算连通块个数 |
queryTripleSum | 计算三元环个数 |
前三个方法的实现都较为简单。
后三个方法的实现,我借助了并查集算法和动态维护。
isCircle方法只需要判断两个人在并查集中的根节点是否相同即可,若相同则说明两者连通,否则未连通。
queryBlockSum方法的实现,我则是动态维护了一个blocksum,当对Network图进行增删边操作时,相应的对blocksum进行修改,保证其正确性即可。
queryTripleSum方法的实现,我也是使用动态维护一个triplesum,在对Network图进行增删边操作时,遍历图的顶点,找到与该边的两个顶点都相连的点,若存在这样的点,则对triplesum做出修改。
在本次作业中并未出现性能问题,也没有出现bug,得益于数据容器的正确选择以及算法层面的优化,如果按照规格写的用两层for循环操作的话,在时间层面的优化效果应该会大打折扣。
本次作业中测试的方法是queryTripleSum,这个方法关注的点是Person以及Person间的关系。
首先是在数据构造方面,要考虑所构造的图的特征,应包含有稀疏图与稠密图等,即根据Person的数量,增添的relation也应该在一定的范围中。同时,如果规格有对前置条件的要求,构造的数据应该满足这个要求,不然用不满足要求的数据来测试方法是没有意义的,因为其不能保证正确性。
在测试方法的实现中,Junit测试需要对规格的直接翻译,确保能够准确按照规格的释义来完成方法的构建。queryTripleSum的规格中是一个三层循环来完成,相应的我们也因用三层循环来检验。
最后是正确性判断,主要是根据规格的ensure和pure的要求。对于每一个ensure,我们都需要构建相应的检测语句对这个确保满足的条件进行检验,对于pure,我们要检验前后是否有对象的值发生改变。对于queryTripleSum,ensure确保的是结果满足的条件,将三层循环得到的结果与方法结果比较即可;同时,其被pure修饰,需要检查方法前后,person[]的值是否发生改变。

这次作业变化最大的点是加入了Tag,相当于一个分组,这次作业新增的方法也都是围绕着这个Tag展开。
Tag中有一个Person[],以及围绕着这个容器的方法。
Network中新加的方法如下
| 方法名称 | 作用 |
|---|---|
addTag | 为指定的Person加入一个Tag |
addPersonToTag | 向指定的Person的指定Tag加入一个Person |
queryTagValueSum | 获得指定的Person的指定Tag中的ValueSum(与Tag的getValueSum相关) |
queryTagAgeVar | 获得指定的Person的指定Tag中的AgeVar(与Tag的getAgeVar相关) |
delPersonFromTag | 删除指定的Person的指定Tag中的指定Person |
delTag | 删除指定的Person的指定Tag |
queryBestAcquaintance | 获得指定id的person的最好熟人(即找到关系值最大的熟人) |
queryCoupleSum | 计算当前网络中互为最好熟人的对数 |
queryShortestPath | 计算两个人之间的最短路径 |
这次作业中新增的方法中,以qurey打头的几个方法是实现重点,其中大多数我都使用了动态规划。
对于queryTagValueSum方法,我是对于每个Tag动态维护了一个valuesum,当向这个Tag中增添Person或者删除Person时,对valuesum的值进行修改。同时,当有两个Person的关系的value被修改时,需要遍历所有的Tag,将含有这两个Person的Tag的valuesum进行相应的修改.
对于queryTagAgeVar方法,同样是对每个Tag动态维护了一个agevar,当向这个Tag中增添Person或者删除Person时,对agevar的值进行修改.
对于queryBestAcquaintance方法,我对于每个Person动态维护了一个bestid,对于bestid的修改分为两种,一种是向Person中新增关系或者修改不为与bestid的人的关系时,需要将新增的人或者修改的人与bestid的人的关系进行比较修改;另一种是在besid改变时(修改或者删除),需要重新寻找新的(即原第二大的)bestid。这个可以借助优先队列实现(但我没有完成这一点)。
对于queryCoupleSum方法,我则是在Network中动态维护了一个couplesum,当增添关系或者修改关系时,对couplesum进行维护。
对于queryShortestPath方法,因为对于最短路径的动态维护成本较高,我则是采取在查询时计算的策略。最短路径的算法很多,最开始我选择的是Dijkstra算法,后来强测爆掉了一个点也是因为这里,后来改成了bfs。
这次作业只有强测出现了一个bug,问题就是出在queryShortestPath方法的算法选择上面,最开始我选用的是Dijkstra算法,后来改成了bfs。由于在这次作业中,每个边的权值是一样的,使用Dijkstra算法会格外存储许多非必要的信息,相比之下,对于无权图,使用bfs的效率要高上许多。
本次作业测试的方法是queryCoupleSum,这个方法关注的重点在于acquaintance这个容器。
在数据构造方面,由于没有提供对于acquaintance的返回方法,因此针对每一个构造的Network,在生成的同时还需要生成一个相应的acquaintance来满足后续的测试需求。同样的,我们仍然需要考虑所构造的图的特征,应包含有稀疏图与稠密图等,即根据Person的数量,增添的relation也应该在一定的范围中。本次规格没有对前置条件的要求,数据构造没有这方面的限制。
在测试方法的实现中,这次的翻译有所不同,因为在这次的规格实现中,使用了queryBestAcquaintance方法,我们需要将其实现(如果不保证queryBestAcquaintance方法的正确性时),即将queryBestAcquaintance换为其规格翻译。
最后是正确性判断,对于queryCoupleSum,ensure确保的是结果满足的条件,将按照规格计算得到的结果与方法结果比较即可;同时,其被pure修饰,需要检查方法前后,person[]的值是否发生改变。

本次作业新增了Message及其相关的三个类EmojiMessage,NoticeMessage,RedEnvelopeMessage,即最后一次作业的实现是完成了我们社交网络的发消息功能。
Person中新增了收到消息容器ArrayList<Message> recivedmessages与社交值SocialValue,钱money.
Network中新增了存储消息的Message[] messages容器与emojiIdList,emojiHeatList两个与emoji有关的int [],新增的方法如下
| 方法名称 | 作用 |
|---|---|
containsMessage | 检查messgaes中是否含有指定id的message |
addMessage | 向messages中加入message |
getMessage | 从messages中得到指定id的message |
sendMessage | 从messages中发送指定id的message |
querySocialValue | 获得指定id的Person的社交值SocialValue |
queryReceivedMessages | 获得指定id的Person的收到消息recivedmessages |
containsEmojiId | 检查Network中是否含有指定id的emoji |
storeEmojiId | 向Network中加入指定id的emoji |
queryMoney | 获得指定id的Person的money |
queryPopularity | 获得指定id的emoji的Popularity,即相应的emojiHeatList中的值 |
deleteColdEmoji | 删除Network中emojiHeatList值不满足要求的对应emoji |
clearNotices | 清除NoticeMessage |
这次作业中对性能的考察不大,更多的考察是对规格的理解与实现。
本次作业也是在强测出现了bug,其原因也是对规格的实现上出现了问题,没有按照规格的要求进行“翻译”,做了一定的简化处理,但简化处理的实现逻辑与规格有一定的出入,从而导致出现了问题。具体来说就是在对money的处理中,规格中是将money先除以peoplo_size后再乘以people_size,而我直接将其简化,并未先除再乘,从而因为int类型的特性导致两者的结果其实并不相等。
本次作业测试的方法是deleteColdEmoji,其重点关注的是两个与emoji有关的容器emojiIdList,emojiHeatList,以及消息容器messages
因此在数据构造方面,我们这次构造的数据需要重点考虑messages的构造。首先message的种类有三种,每种message又有两种类型,因此在构造message时要充分考虑每一种可能性,确保数据的覆盖率。同时每种消息的数量和消息中所对应的emoji,tag等数据的大小也得在合适的范围,避免出现测试强度低,数据覆盖不完全的情况。
测试方法的实现,也是老老实实按照规格进行翻译。
最后是正确性判断,这次的deleteColdEmoji方法所对应的ensure较多,有6个,对于每个ensure我们都应该进行相应的正确性检查,其中包括了对改变后的emojiIdList,emojiHeatList,messages的相应变化。对于emojiIdList,emojiHeatList的变化只与limit有关,对于messages中的每个message,根据其类型的不同,做出的改变也不同,需要分别进行判断。
规格与实现分离顾名思义就是将代码的规格与他具体的实现分割开,通俗一点来讲就是,代码的实现并不一定需要照着规格一板一眼的直接翻译,而只需要满足规格所给定的要求,不限制具体的实现方式。
这么做固然带来了许多的好处。首先,这样讲规格与实现独立开来,规格定义了系统应该做什么,而实现则决定了如何做。这样,当需求变化时,只需要修改规格而不影响实现,当需要对系统进行维护或修改时,可以专注于修改实现细节,而不必考虑规格的改变。同时,这样十分方便测试,规格定义了系统的功能和行为,可以作为测试的基础,而实现则是根据规格进行开发和优化,测试其确保符合规格的要求。当然,规格与实现分离也有助于提高代码的可复用性。通过将规格定义清晰,可以将其作为接口或约定,使得不同的实现可以在不同的系统中复用。
Junit测试对规格信息的利用主要是三个方面,数据的构造,测试的实现,正确性的检验。
对于数据构造,通过规格我们可以明白该方法处理的前置条件,根据其我们可以构造出满足要求的各式各样的数据,也可以进行边界测试与异常测试等。对于测试的实现,我们要检验一个方法的正确性,需要依照规格写出直接翻译的实现,保证完全的正确性,从而能够作为我们方法实现的参照。而最后正确性的检验则是看修改内容与后置条件,我们修改的内容是否符合规格的规定,我们最后给出的结果是否满足规格给出的要求,这些内容都需要我们进行检验。
毫无疑问,Junit测试检验代码实现与规格的一致性的效果是突出的,但这建立在我们构造的测试具有完备性的基础之上。只有我们的测试数据覆盖的范围全面,才能够检查出所有可能存在的问题。这也是对我们编写Junit测试能力的考验
黑箱测试(Black-box Testing):在黑箱测试中,测试者对被测试系统的内部结构和实现细节一无所知。测试者只关注系统的输入和输出,通过给定的输入数据,验证系统是否能够正确产生预期的输出结果。黑箱测试侧重于测试系统的功能和行为,而不涉及内部的实现细节。它类似于将系统视为一个黑盒子,只对外部可见的接口和功能进行测试。
白箱测试(White-box Testing):在白箱测试中,测试者对被测试系统的内部结构和实现细节有详细的了解。测试者可以查看系统的源代码、算法、数据结构等信息,并基于这些信息设计测试用例。白箱测试主要关注系统的逻辑完整性、覆盖率和性能等方面,通过深入了解系统内部的实现细节来设计有效的测试用例。
老师一直强调我们既要有黑箱测试,又要有白箱测试。对于黑箱测试,我们常是用一大堆数据测试,有时候不清楚所给的测试数据的覆盖面如何,也许我们测试1万组,甚至更多,也无法保证测试完全了所有的情况,虽然这确实能够较好的检验我们所写程序的正确性。白箱测试我们更多的是分析代码的实现细节,构造特定的测试样例对程序进行检查,更加具有针对性,也能够弥补一些纯靠黑箱测试无法发现的问题。两个测试互为补充,缺一不可,将他们结合起来是对我们程序正确性判断的一个重要途径。
这些测试都能够用于我们的检测之中。
本单元的数据构造策略有两个,一个是功能测试,一个是压力测试,其具体内容如上。主要就是想要考虑在功能复杂和指令数量增多后程序的处理情况。
这单元的内容相较于前两单元,给了人一种不同的感受,尤其是在多线程单元之后。
第三单元的主题是JML规格,是我第一次接触这个内容。一开始的时候,我确实觉得编写规格有些多此一举了,明明自然语言一两句话就能描述清楚的问题,非要用规格来写一长串,读和写的难度都上了一个台阶。既然要多费功夫,自然得有花费带来的好处,自然语言有一个缺点就是不够严谨,规格做到了这点,这也是我们编写规格最主要的目的——力求方法的严谨,从前置条件到后置条件,再到方法过程中改变的对象等等,这些规格中都有体现,也是对我们编写程序的一种约束。由于这些约束,我们对一个方法有了清晰明了的认识。
现在我只是初步体验了规格和契约化设计,还不敢说已经有了多么深刻的体会,但也算是初步体验。说不定以后那次遇上了他,能够重拾这一段懵懂而跌跌撞撞的回忆吧。



