


301
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享对于黑箱测试,测试人员只关注软件的功能和用户界面,而不考虑内部结构和代码实现。测试人员通过输入不同的数据,检查软件的输出是否符合预期,以此来评估软件的正确性和完整性。目前我们接触的最典型的例子就是随机大量数据生成对作业进行测试,好处是设计简单,方便快捷,通用性强;坏处就是覆盖率不稳定,有可能有覆盖不到的bug,同时bug可复现性较差,有时候甚至不能复现。
对于白盒测试,测试人员需要了解软件的内部结构和代码实现。测试人员通过检查代码逻辑、路径覆盖等方式来评估软件的质量和稳定性。目前我们接触到的典例就是Juint的单元测试,优点是测试过程均可见,bug也容易精准定位并且容易复现,缺点就是设计与编写相对复杂。
单元测试是针对软件中最小的可测试单元进行的测试,通常是对函数、方法或类进行测试,以验证其功能是否按照预期工作;
功能测试是对软件系统的功能进行测试,以验证系统是否符合需求规格说明书中定义的功能要求;
集成测试是将各个单元或模块组合在一起进行测试,以验证它们在集成后是否能够正常工作。集成测试旨在发现模块之间的接口问题和集成问题,确保整个系统的功能正确性和一致性;
回归测试是在对软件进行修改或添加新功能后,重新运行之前的测试用例,以确保修改不会影响原有功能的正常运行。回归测试旨在验证软件的稳定性和兼容性,避免引入新的bug或问题。
并没有什么特殊策略,都是随机生成,同时保证覆盖尽可能全面的情况(比如稀疏图,稠密图均要有),因为自己没有写数据生成所以大部分都是借助评测机(
本单元的架构其实要说的比上两个单元要少很多,因为整体的结构其实由所给JML规格约束就已经定好,只不过由于性能要求,部分方法或者类的实现可能并不会完全按照JML的描述方法来,而是会采用一些优化后的实现方法,就像很多学长博客里说的,规格与实现分离,只要满足规格所要求的功能和约束,那么对于具体的实现方法是没有要求的。
本单元的整体架构即是以Person为点,person间的关系为边,同时有若干附属属性分组(如tag,group)的图(Network)的建立维护与管理,包含一些查询搜索方法(最短路径,连通性等)
在本单元的作业中最典型的优化就是关于图结构存储与维护方法,JML的描述中并没有对图的数据结构做出具体的要求,所有的person都用数组格式表示,但是实际存储时自己采用的存储容器以hashmap占主导,同时图的存储与查询直接采用JML中的三重循环会TLE,于是为了优化查询效率采用了并查集算法,保证了查找的效率,具体实现规格如下:
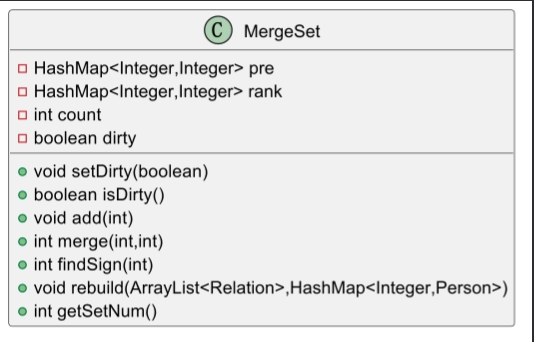
pre即用来存点的父节点的容器,key对应点id,value对应父节点id;
rank即存储每个节点的深度,用于按秩合并操作;
count用于存储并查集中的“couple”数目(queryCoupleSum需要查询),在并查集建立之后就一直进行维护;
dirty是脏位,一旦对边(relation)进行了修改则需要脏位置true,每次查询之前如果检测到脏位为true则对并查集进行重构,保证不会造成修改关系后查询但并查集为更新的问题,实现如下:
public void rebuild(ArrayList<Relation> relations,
HashMap<Integer, Person> persons) {
pre = new HashMap<>();
rank = new HashMap<>();
count = 0;
for (int id : persons.keySet()) {
this.add(id);
}
for (Relation relation : relations) {
int left = relation.getLeftId();
int right = relation.getRightId();
this.merge(left, right);
}
dirty = false;
}
其中relation为存储边的专用类;
而除了以上所说的基本属性,并查集保证效率最重要的两个方法就是路径压缩和按秩合并,下面简单介绍一下这两个方法的思想和实现:
路径压缩 目的:我们只关心一个元素对应的根节点,那么希望每个元素到根节点的路径尽可能短,最好只需要一步。 实现:只要在查询过程中,把沿途的每个节点的父节点都设为根节点即可。
public void add(int id) {
if (!this.pre.containsKey(id)) {
this.rank.put(id, 0);
this.pre.put(id, id);
count++;
}
}
按秩合并 目的:为了到根节点距离较长的节点个数尽量少,我们可以把简单的树往复杂的树上合并。 实现:用一个数组**rank[]**记录每个根节点对应的树的深度(如果不是根节点,其rank相当于以它作为根节点的子树的深度)。
public int merge(int id1, int id2) {
int sign1 = findSign(id1);
int sign2 = findSign(id2);
if (sign1 == sign2) {
return -1;
}
int rank1 = rank.get(sign1);
int rank2 = rank.get(sign2);
if (rank1 < rank2) {
pre.put(sign1, sign2);
count--;
} else {
if (rank1 == rank2) {
rank.put(sign1, rank1 + 1);
}
pre.put(sign2, sign1);
count--;
}
return 0;
}
虽然之前也说了是采用随机生成的策略并无太多技巧性,但是生成逻辑的不同对Junit测试严谨性与准确性的影响是非常大的,因此数据的生成就需要依照规格信息中对属性的约束和要求进行生成。比如第一次作业的测试中对图的生成就要求有足够大的数量(因为你是随机生成);第二次作业的测试中,就要求图的类型要尽量全面,不只要有一般图,稀疏图和稠密图这两种也要尽量覆盖到;第三次作业的测试对消息的类型的要求就很高了,如果你生成的时候没有覆盖全部类型的消息那么有一些测试点你就过不去,而且实际上也是不对的。
其实归根到底,Junit测试实现的最好方法就是根据规格信息翻译,只要能够保证规格信息中的约束均能被满足,测试点其实是都能通过的;三次Junit体验下来,每次测试点过不了的时候找出来的bug除了上面说的数据覆盖不全面都是ensures没有保证。所以最简单的保证Junit正确的方法就是根据规格信息设计一比一复现实现。
虽然Junit写起来很难但是只要你能够写好(满足规格信息)同时测试通过了,那么对于模块的正确性就能够得到保证;但是由于Junit要求用的方法本地都未实现,所以其实并没有很明确的测试提升体验(
本单元深刻体会到了契约式编程在项目开发中所起到的作用,即使是不同人的不同实现,但是在规格的约束下也能自由的交流;同时最终要进行测试的时候,规格约束也是最好的参考和标尺。
希望学到的这些在之后的coding中能够灵活运用,切实践行。



