



301
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享黑箱测试与白箱测试都是程序测试的两个重要方法,以前我们的测试更多的是黑箱测试,即更关注程序输出的正确性。但在本单元中综合采用两种测试方法,不仅要求程序输出正确,也要求程序内部实现正确。
测试人员根据程序的输入输出确定程序的正确性。黑箱,即一个不能被打开的箱子,程序内部实现细节对测试人员来说是透明的,因此测试人员无需考虑程序内部结构和特性的正确性,只对程序提供的接口进行测试。
我们之前数据结构、C语言等等编程课采用的大都是黑箱测试,评测机对我们的输出进行正确性判定。本单元中利用自己的评测机进行测试也是黑箱测试。
测试人员不仅要对程序的输入输出判定正确性,也要对程序内部逻辑进行检验。白箱,箱子里的东西是可见的,测试人员了解程序内部运作,因此程序人员还要对程序内部实现细节,即算法、数据结构等进行检查。
我们在junit测试中不仅要判定方法返回值是否正确,也要判定方法带来的副作用(如对象属性改变)是否正确,这是白箱测试。我们根据评测机的输入,逐行debug检查代码出错位置,也是白箱测试。
即对程序的最小可测试单元进行测试,通常是对函数、方法进行测试。测试代码量较小,可以逐一排查,精准定位可能出现错误的代码。Junit中的@Test方法测试就是单元测试。
对各个模块的功能进行测试,判断是否符合指导书。
相较于单元测试而言,集成测试是把各模块集成起来测试,判断各模块间交互是否正常,各模块间是否会互相影响而导致错误。
用大强度的数据对程序进行加压测试,观察它在极限情况下的运行正确性和运行速度,找到影响系统性能的瓶颈。如强测数据中,创建一个非常大的图,然后大量qbs、qts、qsv查询操作就是压力测试。而此时用idea自带的Intellij Profiler分析程序运行的时间,就能观察到花费时间最多的方法是哪个,从而找到程序性能的瓶颈。
修改代码后,对新代码重新测试,确保修改没有引入新的错误,在代码修复阶段采用的就是回归测试。
在Junit单元测试中,我的数据生成主要采用随机+边界的方式,随机产生Person、Relation、Message等信息,覆盖各种可能的情况,提高图的复杂度。
同时我也使用了评测机进行数据的生成和正确性判定。
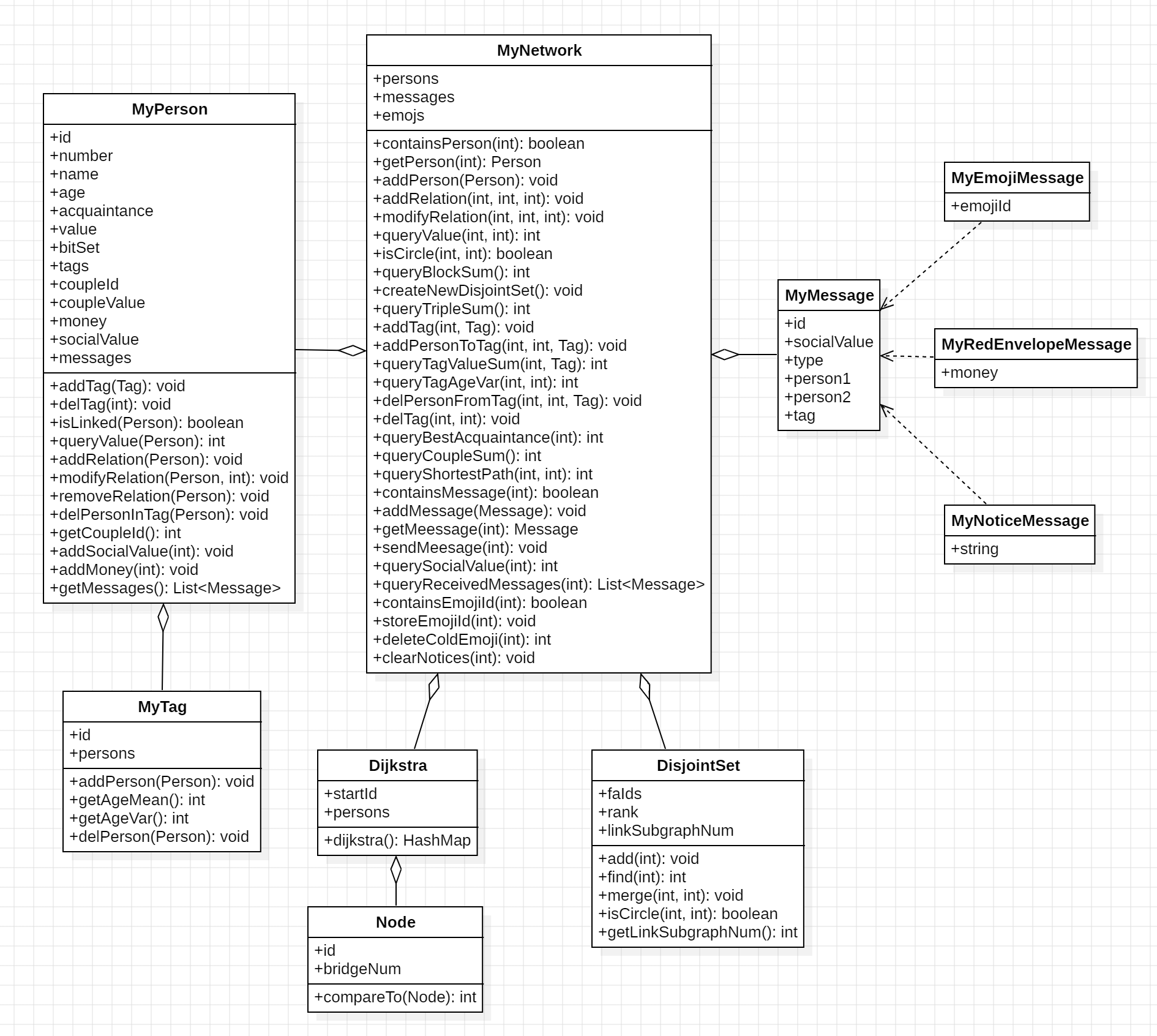
本单元的社交网络其实本质上就是一个图,如果只是根据JML的描述进行代码编写,由于算法效率低,一定会导致ctle而无法通过强测的压力测试,因此本单元我引入了很多图的优化算法,如并查集、bitSet、dijkstra,也采用了动态维护、脏位的思想。
在isCircle方法中,我们需要判断两人间是否存在路径。我采用了并查集算法,为了体现“面向对象”类的封装性,我新建了一个DisjointSet类实现并查集操作,并对外提供add()、merge()、isCircle()、getLinkSubgraphNum()等接口,以供MyNetwork在addPerson、addRelation时维护,和在isCircle、queryBlockSum时查询。
至于并查集的基本算法不过多赘述。并且,我们可以对并查集进行优化。
实现并查集的路径压缩,即当我们查找一个元素所在集合的代表元时,可以将查找路径上所有元素的直接上级设为代表元。这样能大大加快查询的速度。
public int find(int id) {
int rep = id;
while (rep != faIds.get(rep)) {
rep = faIds.get(rep);
}
int now = id;
while (now != rep) {
int fa = faIds.get(now);
faIds.replace(now, rep);
now = fa;
}
return rep;
}
在queryTripleSum方法中,我们需要查询三角关系的数量,如果按照JML暴力遍历,复杂度为O(N^3),显然会ctle。而采用bitSet进行优化,就能把复杂度降到O(N^2)。
bitSet是java自带的数据结构。bitSet,即位图,用每一位来存放某种状态,可以理解为一个很长的二进制串。这里我们就用bitSet记录每个Person的acquaintance,并在每次addRelation和modifyRelation删除关系时,维护每个Person的bitSet。在查询三角关系时,只需要将两个人的bitSet与一下,如果他们有共同的熟人,则代表三角关系成立。
BitSet bitSet = ((MyPerson) person1).getBitSet();
bitSet.and(((MyPerson) person2).getBitSet());
result += bitSet.cardinality();
但需注意,Person的id仅在int范围内,为防止bitSet过大,需要对其进行离散化处理,给每个Person赋一个number属性。使用Person类的一个静态变量即可实现。
在本单元中,动态维护是即为重要的一个思想,甚至可以弥合很多算法上的差距。对查询计算量较大的操作,在别的操作中进行动态维护,提前计算好需要的数据,在查询时就能直接得到数据,大大降低了查询复杂度。
采用了动态维护思想的有bestAcquaintance。在Person每次addRelation和modifyRelation时都动态维护每个Person的最好朋友,这样查询bestAcquaintance时间复杂度就是O(1)。
在deleteColdEmoji时也可以采用动态维护思想,原本需要在删除emoji时遍历整个messages队列,删除对应的EmojiMessage。但如果为每个emoji建立一个对应的EmojiMessages,并在每次addMessage和sendMessage时都维护这个EmojiMessages,就能在deleteColdEmoji时直接删除EmojiMessages里的message,不需要再去遍历整个messages队列。
对于修改复杂度较高的操作,设立脏位,标记是否修改过,推迟修改操作,能减少不必要的时间开销。
如在并查集维护中,加边是方便操作的,但减边就需要重建整个并查集。如果每次减边都重建,算法复杂度会非常高。因此我们设立一个“脏位”,若减边,则脏位置1,但不立刻对并查集进行重建,直到下次需要查询并查集时再重建。
queryShortestPath方法就是需要标准的dijkstra查询最短路径,为体现“面向对象”的特征,也为了不让MyNetwork太长而超过500行,建议单独写一个Dijkstra类进行封装。
dijkstra可以采用优先队列进行优化。
HashMap<Integer,Integer> dis = new HashMap<>();
HashMap<Integer,Boolean> vis = new HashMap<>();
PriorityQueue<Node> heap = new PriorityQueue<>();
//初始化dis和vis
...
heap.add(new Node(startId,0));
while (!heap.isEmpty()) {
Node minNode = heap.poll();
...
Person person = persons.get(minNode.getId());
for (Integer acquaintanceId : ((MyPerson) person).getAcquaintance().keySet()) {
//松弛
...
heap.add(new Node(acquaintanceId,dis.get(acquaintanceId)));
}
}
}
本单元作业中,互测没有被hack,强测各被hack了一次。由于我的算法设计较好,应用了很多图的优化算法和动态维护思想,因此强测的性能问题主要是由遍历方式不当导致的。
以第一次作业的queryTripleSum为例:
for (Integer i : persons.keySet()) {
for (Integer j : persons.keySet()) {
if (i < j && persons.get(i).isLinked(persons.get(j))) {
BitSet bitSet = ((MyPerson) persons.get(i)).getBitSet();
bitSet.and(((MyPerson) persons.get(j)).getBitSet());
result += bitSet.cardinality();
}
}
}
result /= 3;
Person[] arrayPersons = persons.values().toArray(new Person[0]);
for (int i = 0;i < arrayPersons.length;i++) {
for (int j = i + 1;j < arrayPersons.length;j++) {
if (arrayPersons[i].isLinked(arrayPersons[j])) {
BitSet bitSet = ((MyPerson) arrayPersons[i]).getBitSet();
bitSet.and(((MyPerson) arrayPersons[j]).getBitSet());
result += bitSet.cardinality();
}
}
}
result /= 3;
for (Person person1 : persons.values()) {
HashMap<Integer,Person> acquaintance = ((MyPerson) person1).getAcquaintance();
for (Person person2 : acquaintance.values()) {
BitSet bitSet = ((MyPerson) person1).getBitSet();
bitSet.and(((MyPerson) person2).getBitSet());
result += bitSet.cardinality();
}
}
result /= 6;
以上三种遍历方式都是双重遍历,目的都是遍历persons中所有认识的两个人,并把他们的bitSet相与、找到共同好友数。粗看似乎并无太大区别,但在压力测试下的运行时间却大相径庭。
前面两种遍历方式都是双重遍历每个Person,判断isLinked,第二种无非是把hashMap转成数组,减少一半的遍历工作量。而第三中种是遍历每个person和其acquaintance,虽然会导致同一条边被计算两次(因此第一二种都是result/=3,而第三种是result/=6),但从遍历角度来看,第三种的内层循环是遍历acquaintance,减少了很多无效遍历,因此性能最好。
经过实测,在强测压力测试下,第三种遍历的运行时间是1247 ms,而第一种和第二种分别是27551 ms和5907 ms。由此可见,一个细小的遍历细节能带来运行时间的巨大差异,压力测试的重要性也突显出来。
在互测阶段,我通过本地评测机跑别人的jar包,第一次和第三次作业有hack到别人,大都是因为优化而导致wrong answer。
规格与实现分离是指在软件开发过程中,将软件的需求规格和实现代码分开处理,使得两者的修改互相独立,从而提高软件的可维护性和可重用性。这也利于程序员在交接工作时,不会对上一个人写的代码功能有歧义。
JML与需求指导书类似,更多的是描述客户的最低功能需求,因此完全按照规格实现代码,运行效率很差。我们在实现时,要详细研究、深入理解规格,确保程序完全符合规格要求,也要兼顾性能,降低时间复杂度,这是对程序员的一个考验。
在Junit单元测试时,我们需要对规格的每一条requires、ensures、pure、assignable语句进行检测,确保方法的返回值和带来的副作用正确。
如在Junit单元测试中,需要对测试方法的前置条件、返回值进行检查,也要对方法运行过程中抛出的异常进行检查。如果有pure、assignable规格要求,则可以通过复制一个影子Network的方式,判断方法调用前后对象的改变是否符合规格,检验方法的副作用。
Junit单元测试应当对JML规格的每条语句都进行检查,这样才能保证方法的返回值、副作用均满足规格需求。这里用的是白箱测试,相比于黑箱测试而言,对程序内部结构也提出了要求。
本单元的学习重点是JML,从一开始对其繁杂的不理解,到慢慢体会到JML精准描述、无歧义的优势,再体会到规格与实现分离的可重用性和可维护性优势,我逐渐意识到规格在大型项目开发中的重要性。像荣文戈老师多次强调的那样,我们遇到一个问题,首先应该考虑整体的需求和规格,而不是先想到用什么具体方式来实现,需求有时候比代码实现和算法优化更难,规格与实现分离也显得格外重要。
这单元中图相关算法的应用也很有意思,大一的数据结构中我们对图更多的是浅尝辄止,在这单元中学习并应用并查集、dijkstra、最大堆最小堆、bfs等算法,让我体会到图的博大精深。
这单元最大的困难莫过于算法的选择和ctle,本单元的需求并不难理解,朴素实现也并无坑点,但如何优化时间复杂度、通过强测的压力测试,是一个巨大的挑战。idea自带的Intellij Profiler分析器相当有用,让我精确定位程序的性能瓶颈。
OO的学习过程已然大半,我遇到了很多困难,也解决了很多问题,现在我对第四单元的学习和未来参与中大型项目开发充满了信心。



