


301
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享黑箱测试与白箱测试
首先,黑箱测试是一种测试方法,测试人员无需了解被测试软件的内部结构和代码实现,而是基于软件的功能需求和规格说明书来设计测试用例。对比oo作业来说就是阅读指导书的数据限制,构造数据生成器,并构造正确性比较器,从而搭建自动化测试,用大量的数据去测试代码,将代码的输出与期望输出进行比对,从而保证代码实现功能的正确性。同时,白盒测试与黑盒测试相反,测试人员需要了解被测试软件的内部结构、设计和代码实现,通过分析代码路径、逻辑和流程来设计测试用例,并且常用的白箱测试技术包括路径覆盖、分支覆盖和条件覆盖。这让我想起在面向对象先导课程中Junit测试覆盖率的要求,而且这种白盒测试的思想正是与Junit单元测试相吻合,同时jml方法规格已经为我们定义了代码实现路径和流程,从而能够有效编写白盒测试样例,即Junit单元测试。在本单元的测试中,我采用的是黑箱测试和白箱测试相结合的方法,即在写完源代码之后先编写Junit单元测试,借助实验课用到的test随机多组测试的方法,测试方法能不能满足jml的规格定义,此为白箱测试。完成Junit的编写,我构造满足指导书定义的数据限制,编写数据生成器,并和他人代码的输出进行对拍,进行自动化测试,这阶段的测试用例数据量较大,而且只针对代码本身的输出是否符合预期,并不关注代码的具体实现,此为黑箱测试。
单元测试、功能测试、集成测试、压力测试、回归测试
单元测试是对软件系统的最小可测试单元(通常是函数或方法)进行的测试,确保该单元的正确性。
功能测试是基于软件功能需求进行的测试,验证软件的各个功能是否按预期工作。
集成测试是在单元测试的基础上,将多个单元或模块集成在一起进行的测试,验证它们之间的交互和协作是否正确。
压力测试是通过对软件施加超出正常工作负荷的压力,评估其在极端条件下的表现。
回归测试是在对软件进行修改(如修复缺陷、添加新功能)后,重新执行以前的测试用例,确保修改没有引入新的错误或破坏现有功能。
结合本单元的学习,单元测试即是对每一个类的方法进行测试,与Junit单元测试正好符合;功能测试是对每一条指令正确实现的测试,每一条指令可能需要调用多个方法,然而由于对每一条指令的具体功能实现是由官方包给出的,所以只需要保证每一个方法满足jml规格,就可以保证功能的正确性;集成测试就是将所有类型指令实现不同组合构造测试,验证最后输出结果的正确性;压力测试在本单元较为重要,因为很多方法在jml规格定义下的时间复杂度比较高,需要进行算法优化,否则会出现超时,而本单元我所做的压力测试就是通过反复执行时间复杂度比较高的方法,数据量为数据限制的最大,检查是否出现超时现象;回归测试对于像oo这样不断迭代的形式是很重要的,由于新的功能可能会对之前的功能实现产生影响,我在每实现新的功能后,都先将之前功能的测试点重新测试,保证在迭代开发的时候不会出现之前功能的问题。
数据构造策略
我在本单元的数据构造测试是基于正确性测试和时间性能测试进行的。完成代码编写后,首先就是对各指令的正确性进行测试,生成数据策略就是随机策略,由于是无向图模型,我会设定图的block数,然后随机进行增删改查的操作,判断正确性。压力测试是基于时间复杂度比较高的方法进行的,在保证正确性的前提下,构造数据时反复调用同一个指令,判断是否超时。
第一次作业
第一次作业的介绍了整个单元的作业框架,是基于无向图模型的维护和查询。而在第一次作业中,由于有着qci,qbs等查询指令,如果只是使用邻接矩阵的存储方式并在每次指令查询的时候暴力搜索,显然会存在较大的性能问题,对于此我应用了并查集算法,使得qci操作的复杂度大大降低。并查集的维护也是难点之一,加边维护并查集并不难,而删除关系时就需要对并查集进行重建,而如果全部重建,复杂度为O(V+E),强测的数据量在10000,很有可能超时,因此我采用了部分重建的方式,相当于剪枝,有比较好的效果。而对于qts指令,我在Person类中引入新的数据结构,用来存放与该Person有间接关系的Person对象,并且在增删关系的时候进行维护,并且维护的复杂度并不高,因此qts指令的实现复杂度也大大降低。
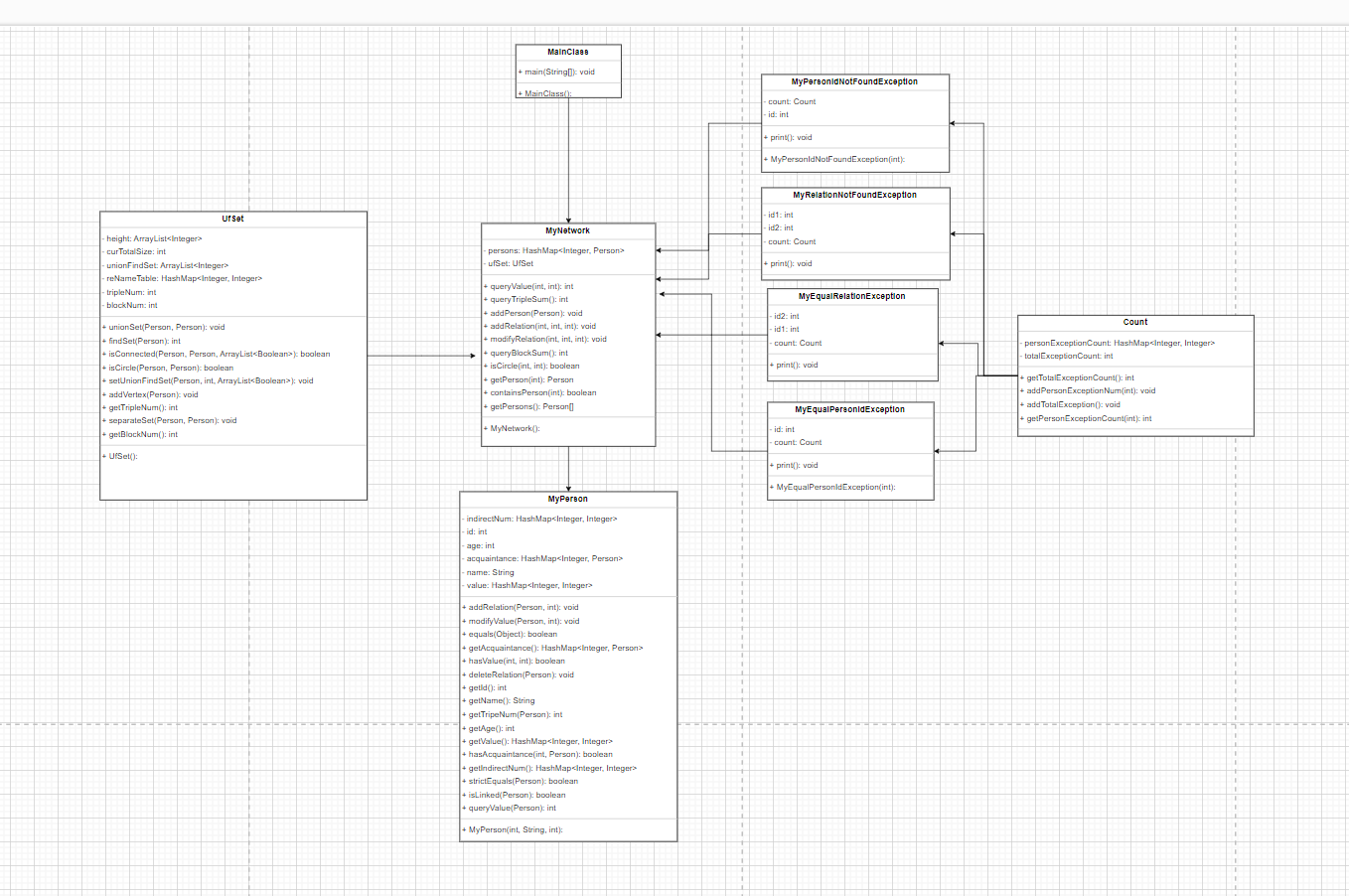
第二次作业
第二次作业引入了tag机制,并增加了关于tag的增删改查的指令,在有关tag的指令中,qtvs的实现复杂度较高,由于在对每个人增删改关系时,并不能直接得到这个人的所属tag,因此传统设置脏位并不能起到效果,为了降低复杂度,我在Person类中引入该人所属的tag的数据结构,因此在两个人增删改关系的时候能够找到两个人共同所属tag或者其中一人在另外一人中的tag进行维护,理论上每次维护的最坏情况为O(n),相比于传统暴力为O(n^2)性能提高不少。同时对于qba和qcs指令,我在Person类中引入bestPersonId,在增删改关系的时候进行维护,并且在这基础上,通过遍历已有的Person对象,得到每个Person对象中的bestPersonId,可以在复杂度O(n)的情况下得到coupleSum。最后是qsp指令,我采用的是bfs,同时在搜索的过程中记录下遍历过的路径,整体复杂度也是O(n),在每次qsp指令中,如果两点之间被记录,直接输出,否则bfs,同时在加减关系的时候清空已经记录的路径。
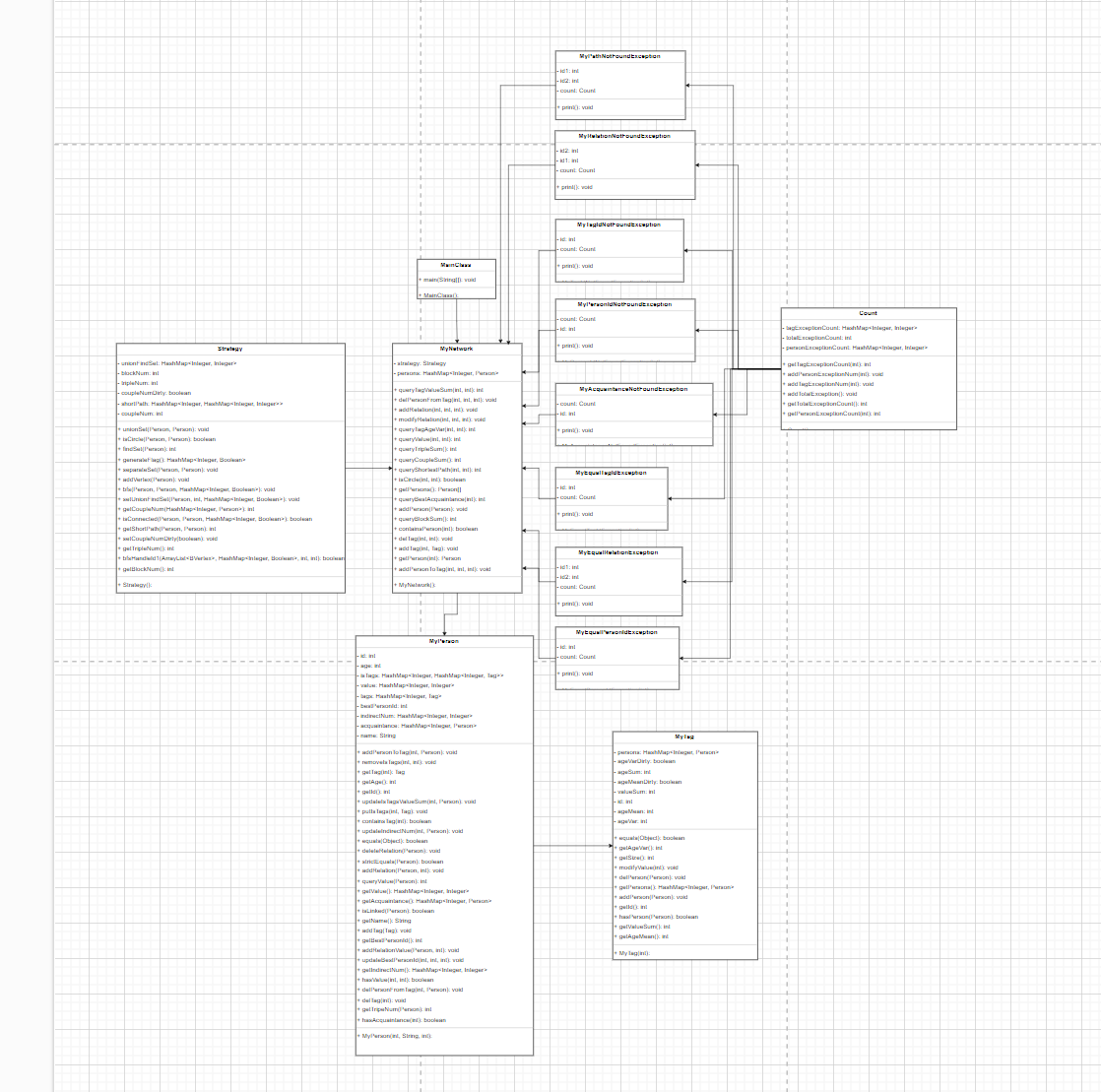
第三次作业
第三次作业并没有前两次作业对性能有很高的要求,但是和前两次作业相比,第三次作业中的jml代码规格是最多的,相较之下会有更多的细节。虽然第三次作业并没有很多性能要求,但是我还是做出了一些优化,主要体现在Person类中,我用LinkedList容器存储Message,这样好处是插入的效率较高,因为Message顺序的要求,每一次Person的Message插入都需要插入容器顶,如果用常用的ArrayList,插入第一个的效率比较低,比较而言LinkedList是更优的选择。

第三单元相比于前两单元,bug数少了很多,三次作业总共只出现了一个bug,是第三次作业中sendMessage方法中对jml规格没有正确实现导致出现的除零问题,虽然是一个小问题但是还是由于自己的疏忽而出现。我认为自己在本单元做的比较好的地方是没有性能问题出现,这都要归因于我对每个方法的复杂度进行了分析,本单元的数据量都在10000,只要控制每个方法的复杂度在O(n)并且稍微剪枝,就不存在性能问题,因此我在各种优化时都会考虑这点进行优化,最后也成功在性能方面没有出现问题。对于规格和实现分离的理解,首先虽然规格能够为我们提供实现方法,但是规格的实现总体来说是复杂度很高的方法,在实际中并没有很好的性能,因此我们的实现要脱离掉原本规格的实现方法,但是我们的实现需要满足规格的设计,比如在jml中,我们的实现方法需要满足后置条件和副作用,因此我们的实现基于规格但又不局限于规格。
在本单元中有Junit单元测试的设计,对于Junit的实现方法,我采用的课上实验的方法,生成随机数据进行测试的方法。我认为jml的规格和Junit单元测试非常契合,在本单元中,每一个核心方法都有着jml规格定义,因此我们Junit的测试方法只需要按照jml的规格编写即可,确保jml规格中的副作用和后置条件都满足,即可确定方法满足jml规格。本单元的公测中有关于Junit的测试,我遇到一种情况出现错误情况,是深克隆的问题,由于需要判断副作用的情况,而在调用方法前后属性很可能发生改变而无法比较,因此我在构造数据的时候就构造了两个一模一样的Network,这样实际上实现了深克隆,从而解决了问题。
通过本单元的学习,一方面对jml规格有了更深的了解,另一方面我对规格化设计有了更深的感受。在实际开发过程中,由于工程量较大,需要实现的功能众多,某一个环节出现问题都可能让整个项目崩溃,通过规格设计保证方法实现的正确性, 能够有效保证开发时的正确性和效率,减少debug带来的时间开销。



