


301
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享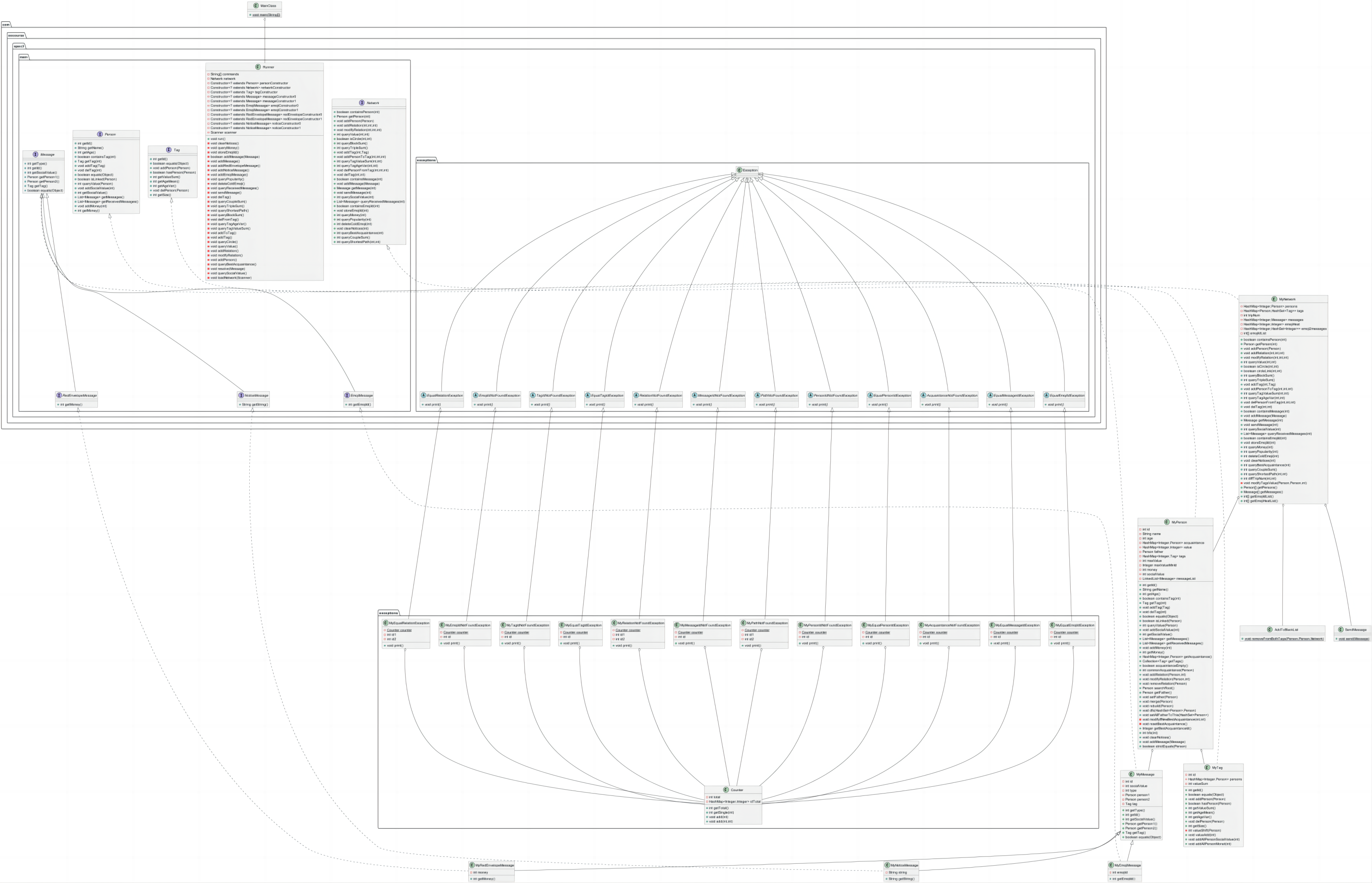
1.性能分析
由于设计相对完善,在公测互测中,我幸运地没有被找到性能问题。下面分析每一条单纯命令(帮忙其他命令维护的部分在其他命令处分析)的时间复杂度和可能需要使用某些容器/一定算法/动态维护的命令。
2.规格与实现分离
规格与实现分离在本次作业中主要体现为JML规格只是形式化地规定了本方法需要实现的功能,而没有指定具体怎么实现,具体的实现还需要由设计者设计,有可能设计时代码的逻辑和原来的规格逻辑很不相同。事实上,如果直接按照上面的形式直接实现,往往性能十分糟糕,甚至于有时候不能够实现,比如说最短路径的规格只是说明要找到一条最短的符合要求的节点序列,实际上没有办法找到全体符合要求的序列以后再找最短的,因为符合要求的序列有无穷多条。
但是之所以还要有规格是要给实现一个无二义的指导,以确保在设计阶段无bug。另外正如上面提到的,规格能也保证了测试和实现的分离。



