



301
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享黑箱测试和白箱测试的定义
黑箱测试:黑箱测试也被称为功能测试,主要是从用户的角度去测试,检查系统功能是否按照需求规格说明书的规定正常运行。在黑箱测试中,测试人员不需要知道内部结构、实现方法和数据结构等信息。
白箱测试:白箱测试也被称为结构测试,主要是从程序员的角度去测试,检查内部数据结构、算法的有效性、完整性和安全性。在白箱测试中,测试人员需要了解被测试的程序内部结构和实现。
其实, 黑箱和白箱测试之间的关系, 就与 jml 与程序的具体实现的关系一样, 只是黑箱白箱是测试层面, 而后者是功能与实现层面的.
黑箱关注的是 jml 中已经规定好的功能, 而白箱关注的是 jml 的实现.
jml 为黑箱测试提供了依据, 通过 jml, 知道了程序的功能怎样, 才能很好的进行黑箱测试.
而白箱测试必须要对程序内部具体的实现, 包括但不限于 jml 里并没有描述的数据结构, 算法等等, 进行测试.
从实用性上来讲, 可以简单地将这两个作为先后两个过程两个作为先后两个过程.
先通过写数据点, 进行黑箱测试, 看看结果对不对, 确定程序的功能是否正确; 然后再通过白箱测试, 包括调试, 确定程序的实现是否正确.
单元测试:单元测试是对软件中的最小可测试单元进行检查和验证。在单元测试中,通常会对函数、类、模块等进行测试。junit 测试就是单元测试的一种实现, 通过 junit 测试, 测试每个函数单元的功能是否正常.
功能测试:功能测试是对系统的各项功能进行全面的测试,主要的目的是发现系统的功能是否能正常使用。
对于这一单元的作业而言, 就是通过 junit 测试, 测试每个方法单元的功能是否正常. 最直观的办法, 就是直接将 jml 翻译成 junit 测试用例, 然后进行测试.
集成测试:集成测试是在所有模块单独测试通过后,将这些模块组合在一起进行的测试。主要的目的是发现模块与模块之间的接口问题。
比较简单的办法, 就是将所有的方法都放在一个测试类中, 然后进行测试. 尤其是第 1 次的 queryTripleSum, 由于我是使用并查集实现的, 所以, 在 modifyRelation 造成删关系时, 就要对并查集进行重建, 所以, 在测试 qts 时, 就可以多次调用 modifyRelation, 然后再调用 qts, 从而测试方法之间的接口问题.
压力测试:压力测试是为了测试系统在极限状态下的稳定性和可靠性。主要的目的是发现系统在高负载或者大数据量下可能存在的问题。
也可以说就是性能测试, 尝试发现系统在高负载下的性能问题. 本单元中涉及到的大量图算法, 实际上还是容易出性能问题的.
最简单的就是随机大量生成数据点, 疯狂加人加关系之类的.
在构造数据点时, 我还注意到, 有些数据点, 虽然人和关系都很多, 但是反而不会引起性能问题, 达不到测试的目的, 这时就需要调整数据生成的策略了.
回归测试:回归测试是在修改了旧代码或者增加了新代码后,重新进行的测试。主要的目的是检查修改或者新增代码是否影响了原有的功能。
这一单元几次作业的迭代中, 基本上没怎么出现需要改原来的代码的. 回归测试其实在本单元没有很明显的体现. 而之前两单元这个是重灾区.
手捏数据点: 有时候, 为了测试某个特定的功能, 可以手捏数据点, 使得这个功能的测试更加明显.
比如经典的闪电图之类的
课程组给的 jml 已经把框架基本上框死了, 基本上就是按照 jml 的规定来写就可以了, 没有太多的架构设计的空间.
我唯一多写的一个类就是并查集类了, 所以就直接放这个吧
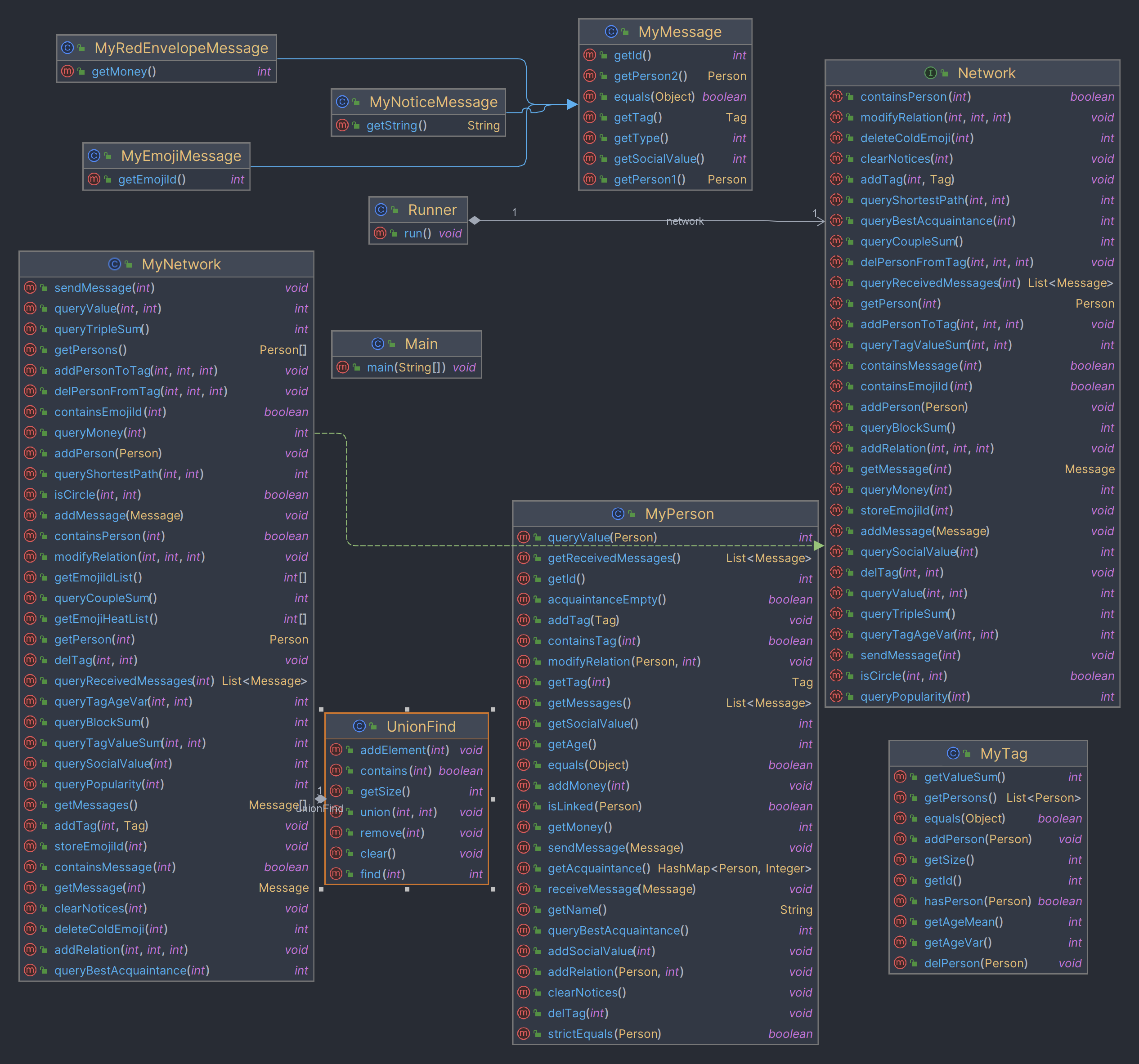
关于图的结构, 实际上, jml 里面已经规定的数据结构, 就足以将图的结构给定下来了
可以看到, Network 中, 有 persons 集合, 而 person 里又有 acquaintance 属性, 这就天然地形成了一个临界矩阵的结构, 图的大致结构就是这样的了.
dfs 的遍历, bfs 的遍历, 都是基于这个结构的.
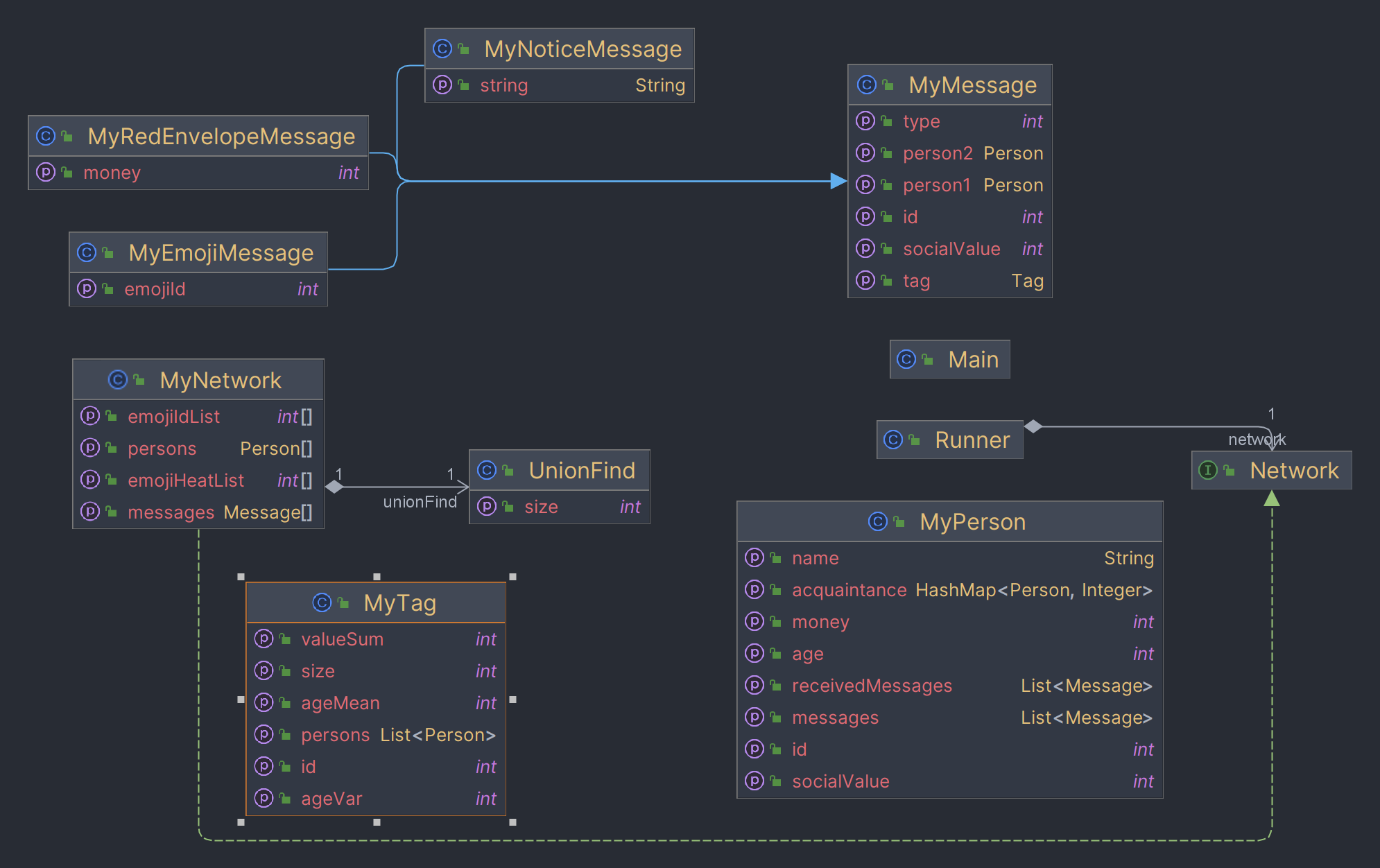
分析作业中出现的性能问题及其修复情况,谈谈自己对规格与实现分离的理解
并查集实现了路径压缩和按秩合并来优化性能.
src\UnionFind.java 12:
//路径压缩
public int find(int id) {
Stack<Integer> stack = new Stack<>();
int root = id;
while (parent.get(root) != root) {
stack.push(root);
root = parent.get(root);
}
while (!stack.isEmpty()) {
parent.put(stack.pop(), root);
}
return root;
}
//按秩合并
public void union(int id1, int id2) {
int root1 = find(id1);
int root2 = find(id2);
if (root1 != root2) {
if (rank.get(root1) < rank.get(root2)) {
parent.put(root1, root2);
rank.remove(root1); // 删除被合并集合的秩
} else if (rank.get(root1) > rank.get(root2)) {
parent.put(root2, root1);
rank.remove(root2); // 删除被合并集合的秩
} else {
parent.put(root1, root2);
rank.put(root2, rank.get(root2) + 1);
rank.remove(root1); // 删除被合并集合的秩
}
}
}
删边可能导致并查集中的连通块的分离,这一点如何处理
我一开始就简单地将并查集全部 clear 了, 重新构建. 但是这样的话, 会导致性能问题. 强测挂了一个点, 好在后来重测, 侥幸压线过了.
后来考虑到可以采用 dfs 局部重建并查集的思路。给定两个要被删除关系的 id1、id2,首先以 id1 为起点进行一次 dfs,并将构建一个遍历到的所有的点的 HashSet,若 id2 在其中,则不对并查集做处理,若不在,则再以 id2 为起点 dfs 取得 HashSet 并将两个 set 加入到并查集中去。这样一套流程下来实际上复杂度是 O(n)(n 是顶点数)。
求最短路时, 使用优先队列
PriorityQueue<int[]> queue = new PriorityQueue<>(Comparator.comparingInt(a -> a[1]));
大量使用 HashMap, 尤其是有 id 的地方, 用 HashMap 来存储, 非常方便查询
oohomework_2024_22371150_hw_11 * src\ExceptionCounter.java:
1: import java.util.HashMap;
4: private final HashMap<Integer, Integer> counts = new HashMap<>();
oohomework_2024_22371150_hw_11 * src\MyNetwork.java:
14: import java.util.HashMap;
24: private final HashMap<Integer, Person> persons = new HashMap<>();
27: private final HashMap<Integer, Message> messages = new HashMap<>();
28: private final HashMap<Integer, Integer> emojiHeatMap = new HashMap<>();
492: HashMap<Integer, Integer> bestFriends = new HashMap<>();
523: HashMap<Integer, Integer> distances = new HashMap<>();
oohomework_2024_22371150_hw_11 * src\MyPerson.java:
7: import java.util.HashMap;
16: private final HashMap<Person, Integer> acquaintance;
26: this.acquaintance = new HashMap<>();
27: this.tags = new HashMap<>();
34: public HashMap<Person, Integer> getAcquaintance() {
oohomework_2024_22371150_hw_11 * src\UnionFind.java:
1: import java.util.HashMap;
5: private final HashMap<Integer, Integer> parent = new HashMap<>();
6: private final HashMap<Integer, Integer> rank = new HashMap<>();
指导书里说的很清楚
在单元测试中,你需要对 JML 的全部内容进行检查,除了检验 requires 和 ensures,还有 pure、assignable 语句等等。例如,对于一个 pure 方法,调用方法前后的状态应该一致,如果前后状态不一致,那么我们认为这不符合给定的 JML。
一一对应就可以了
assert条件clone方法, 而是要使用课程组给定的 get 方法, 这涉及深浅克隆的问题.network对象 ( 有点影子电梯的味道了 ). 然后同时对两个 network 对象进行操作, 然后一个调用要进行测试的方法, 另一个不调用, 然后, 比较两个对象的各个状态是否一致, 来检查 pure 方法.只要能对应好, 实际上就完美地将 jml 纯粹地转化成 junit 测试用例了.
结合离散数学的知识, 这样的 junit 测试用例, 从纯理论的角度, 就完美符合 jml 的要求.
jml 啊 jml, 读懂了一通写, 爽! 读不懂看半天, 烦! 漏条件出 bug, de 不出, 痛!
尽管能看到课程组已经非常努力地将难度降到最低了, 但是, jml 这东西, 还是很抽象.
虽然, 它的目的就是抽象, 就是为了让我们不用关心具体的实现, 只关心功能, 但是, 人的大脑, 还是很难适应这种抽象的.
也只能希望学了能有用吧, 我反正是很难有主动去用的欲望了.
研讨课上, 让我们尝试去写 jml, 更加痛苦了. 助教佬们真的能忍.



