


301
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享在历经三次迭代作业的锤炼后,我深刻体会到本单元教学的核心并非仅限于编程技巧的掌握,而是引导我们学习和实践正向建模与开放的方法论。这种方法在软件系统设计与开发中占据举足轻重的地位,它强调系统设计阶段的重要性,通过构建模型来描绘系统的架构和动态行为,进而指导后续的业务代码实现。尤其当项目复杂度提升,脑海中的细节难以一次性梳理清晰时,UML建模的优越性便得以显现。它能够为我们提供一个高层次的抽象框架,指导我们在实际编码过程中保持清晰的方向和逻辑。
以往的作业实现中,我生怕自己粗浅的架构无法得到实现,于是每次非要先把每个函数写好了,才敢向上写封装。在这一单元中,我尝试了正向建模,即面向需求,自顶向下地设计和编写。经历了一个学期的打磨,我大致能够在设计的时候就对自己的框架有一个相对清晰的了解,将其用UML图绘制出来,然后才落实到代码的实现。
不可否认的是,这其实存在一定的风险。首先一开始我对官方输入输出包不太理解,所以对于函数参数的传递以及Main类和Library类的分工不太明确。其次,在一开始我为了层次化设计抽象了很多类,后来对于这一单元来说没有太大的必要,甚至造成了难看的冗余。可能相对正确一点的顺序是先规划出主要的类,比如Library,然后在实现的过程中思考我需要实现的功能是不是分出去会好一些(比如书籍的移动,或者是否允许借阅的判断),先假设底层已经实现了相应的代码,只负责顶层的架构和设计。在完成了上层大框架后,再来挨个实现下面的模块。这样的方法既保证了设计的合理性,又便于实现,似乎是沾了点模块化设计的优点。
终于可以放心地把类图放上来了
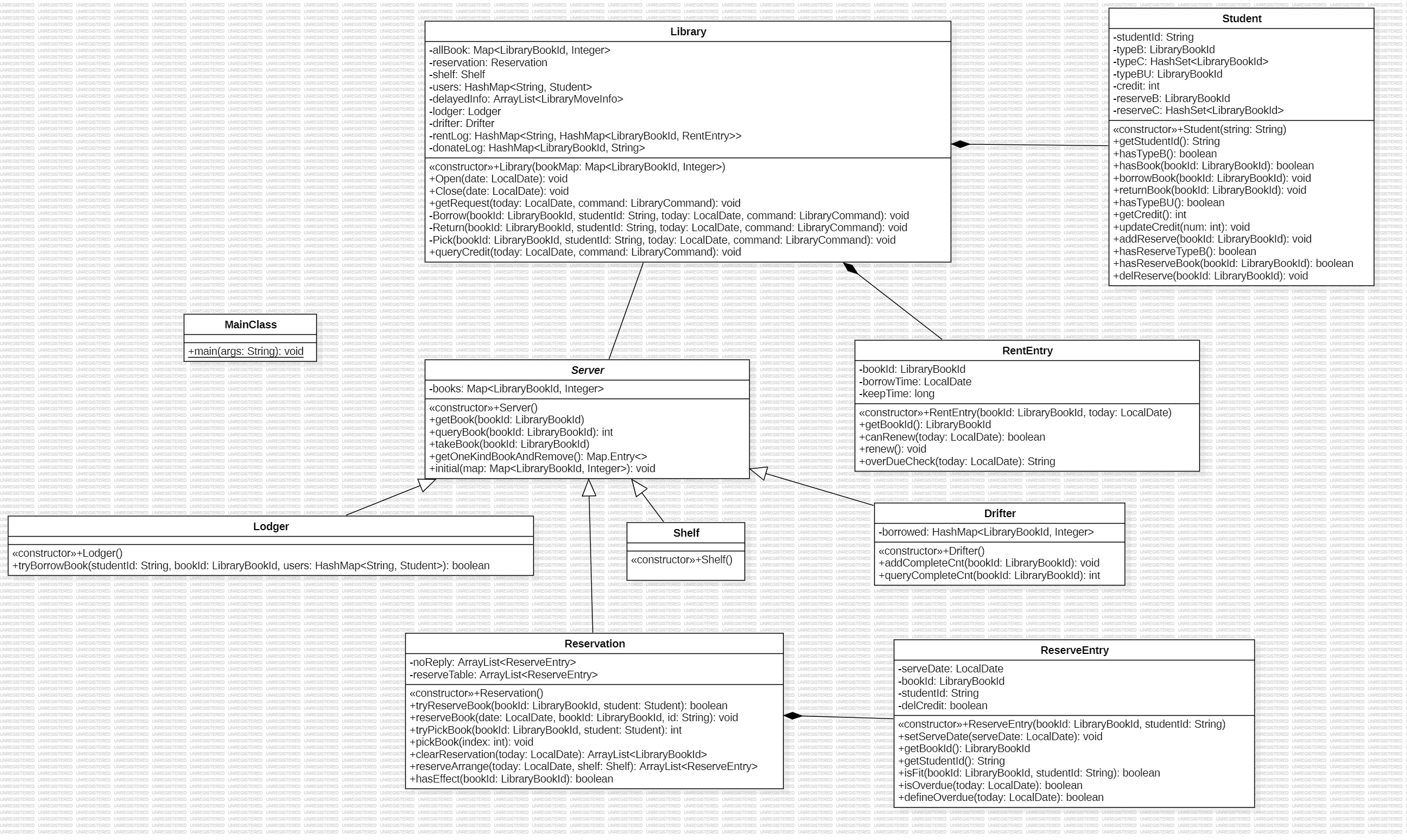
Library,负责开馆、闭馆和处理请求
RentEntry类辅助存储借阅信息以及借阅过期检测
Server,图书馆中的各种服务台的抽象,主要是实现简单的书籍容器以及取书存书操作。
Shell
Lodger专门判断是否可以借书(否则扣留)
Reservation专门处理预约相关的操作,有ReserveEntry类进行辅助
Drifter负责存储图书漂流角书本信息及相关操作实现
Student,存储持有书籍、预约请求以及捐赠书籍
第一次作业先建模再实现,结果发现由于在实现过程中改动过大最终仍然演变为先完成代码再实现。但是在之后的作业中是先在类图上标注出需要新增的类或者新增的方法,以及需要修改的方法,对着这份指南进行迭代开发,效率非常之高。
U1的时候认认真真地尝试面向对象编程,对照着实验代码撰写相对中规中矩的架构。这个时候存在的主要问题,一方面是尚且难以把握复杂的架构设计,甚至在写代码的时候脑子还是空空的,导致需要反复修改,甚至在第二次作业需要重构;另一方面,这样仅仅是结果展示了设计而中途并无设计思路的做法导致接口方法一团糟,出现了一个函数用在两个约束条件不同的情景isEmpty()导致不得不新增很多愚蠢且丑陋的函数打补丁isZero()的问题。
U2的时候情况似乎并没有改善,甚至因为对于多线程的不理解而选择放弃一部分面向对象的架构,追求安全性。这个时候开始反思第一单元出现的问题,学会了给自己的类和方法做出初等的约束(但由于这一单元的特点也没有很多可能需要复用的情况)。一言以蔽之就是少了第一单元的新鲜感,开始追求平稳了。
U3虽然是被骂的很惨的一个单元,并且本人在实现的时候也颇有怨言,但实际上个人认为从这一单元中学到的东西是最多的。首先,在JML已经告诉你有哪些类要实现哪些方法后,打工人的大多数精力只需要放在实现的优化上,而无需担忧架构接口等问题,于是本人是在这一单元爽学算法(虽然结果很惨烈)。其次,这样的爽感让我不免思考,如何复刻这样的舒适呢,在第四单元中,我在部分的函数前面注释了其ensure和require,虽然这样并没有像JML那样严格地限制或者严格地检查,但每次在调用方法的时候我都会查看“这个方法有没有要求调用者需要实现什么”或者在实现方法的时候谨慎一下“这里调用者有没有哪些情况不受限制而作为被调用者需要考虑的”。就是这样小小的一步,极大地提高了我代码的安全性。
U4虽然很轻松但是最重要的应该是其蕴含的设计逻辑。一方面是如同U3中提到了学到了一些实现中的小技巧,另一方面就是第一个板块中提到的自顶向下的设计。至此,之前单元中出现的一些疑惑或者困难似乎都得到了解决,可喜可贺。
测试思路大致演变如下:
搭测评机!自动化测试!数据压力!
搭不了,还是手搓吧
什么,手搓有遗漏?那借借别人的测评机吧
什么,别人的测评机数据生成器不够强?
于是,在课程的最后的最后,我才勉强窥得debug的正确方式。这里借用上次博客的内容。
本单元中最常用和最直接的测试方式仍然是黑盒测试。在初步编写完代码后,黑盒测试可以用大量数据测试代码是否能正常运作,是否在部分情况会出现bug。以往的我盲目相信黑盒测试,以至于认为通过了评测机的考验就大概率是没有bug的。这样忽略了两点,其一,评测机也是人造的,如果搭建评测机的人没有意识到某个可能出现bug的点,或者根本理解错误,那么该评测机也是错的。其二,评测机大多是通过随机生成数据,其中会有很多指令是触发异常的无效指令,即使在大量数据的倾倒下真正有用的信息也不多,针对本次复杂的关系网络,很难保证已经测试到所有的情况。
我对白盒测试比较直观的理解是人脑构造数据尽可能覆盖所有情况。构造数据已经很麻烦了,还要绞尽脑汁覆盖所有情况,这显然是工作量很大的事情。对于一些逻辑简单的代码,白盒测试似乎就没有很必要。而对于一些过于复杂的情况,比如计算
blockSum,该怎样才算是“覆盖了所有情况”呢?也难以界定。所以,白盒测试(至少在这样小规格项目中)适用情况并不多。但有一种情况尤其适合白盒测试,即涉及到很多隐性的if...else判断的方法。比如本单元中coupleSum的计算,其值只可能在增加或者修改关系的时候变化,这时候就尤其适合进行白盒测试,检查每一种情况是否检测到了变化并正确记录,以及是否有效的修改。
简而言之,就是黑盒加白盒,先用大量数据碾压,再针对一些特殊情况或者复杂度比较高的函数进行全覆盖的白盒测试。虽然这样一套下来非常非常消耗时间精力,但成效不错。
虽然一个学期下来还是留下了很多遗憾,但总归是结束了,还是完结撒花✿✿ヽ(°▽°)ノ✿
这门课以其轻松的上机和一点都不轻松的迭代开发,让我小小地体验了一把打工人的生活,面对着领导接踵而至的要求,也只能逼着自己去接触全新的工具链、开发方式,然后在实现的过程中尽力去做到最好。
总的来说从OO里学到的东西还是很多的(不像隔壁课完全不懂在做什么),面向对象是很流行的做法,也是大规模开发普遍采用的做法。然而,在OO课程正式开始之前,便已经有学长叮嘱过“不要为了面向对象而面向对象”。确实,一些听起来很OO的设计和做法在本课程中带来的不便往往是大于其带来的遍历的,诸如本来就在对多线程不熟练的情况下硬要写层层封装的线程池只会对debug造成不便,又或者在第四单元中采用美好的封装继承可能还不如直接写一个library类然后设置很多的容器。那么,我们到底为什么要OO。首先,OO是模块化的,这使得代码更加清晰、易于理解和维护,并且在修改某个功能时,只需要修改相关的对象或类即可,而不需要修改整个程序。其次,也是我后来才琢磨出来的一点,OO的多态性允许使用相同的接口来处理不同类型的对象,或许在平台移植等情况下会有很出色的表现。最后,OO在大多数情况下还是比面向过程要清晰一些,



