


301
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享本人向来不喜欢做规划,习惯于边做边想,随机应变,写代码也是如此。在程序的功能简单而单一时,这似乎没什么问题,能很快的完成任务。但对于规模大一点的项目而言,没有预先设计好的架构,在写代码的同时进行探索、试错,很容易浪费时间。在前三个单元中,我就遇到过这样的情况。整个程序只差最后一个功能,却发现在当前的数据结构下难以实现,只好对相关的部分进行重构,以方便最后一个功能的实现。
采用正向建模与开发的模式可以有效的避免上述问题,提高开发项目的效率。个人认为可行的流程如下:
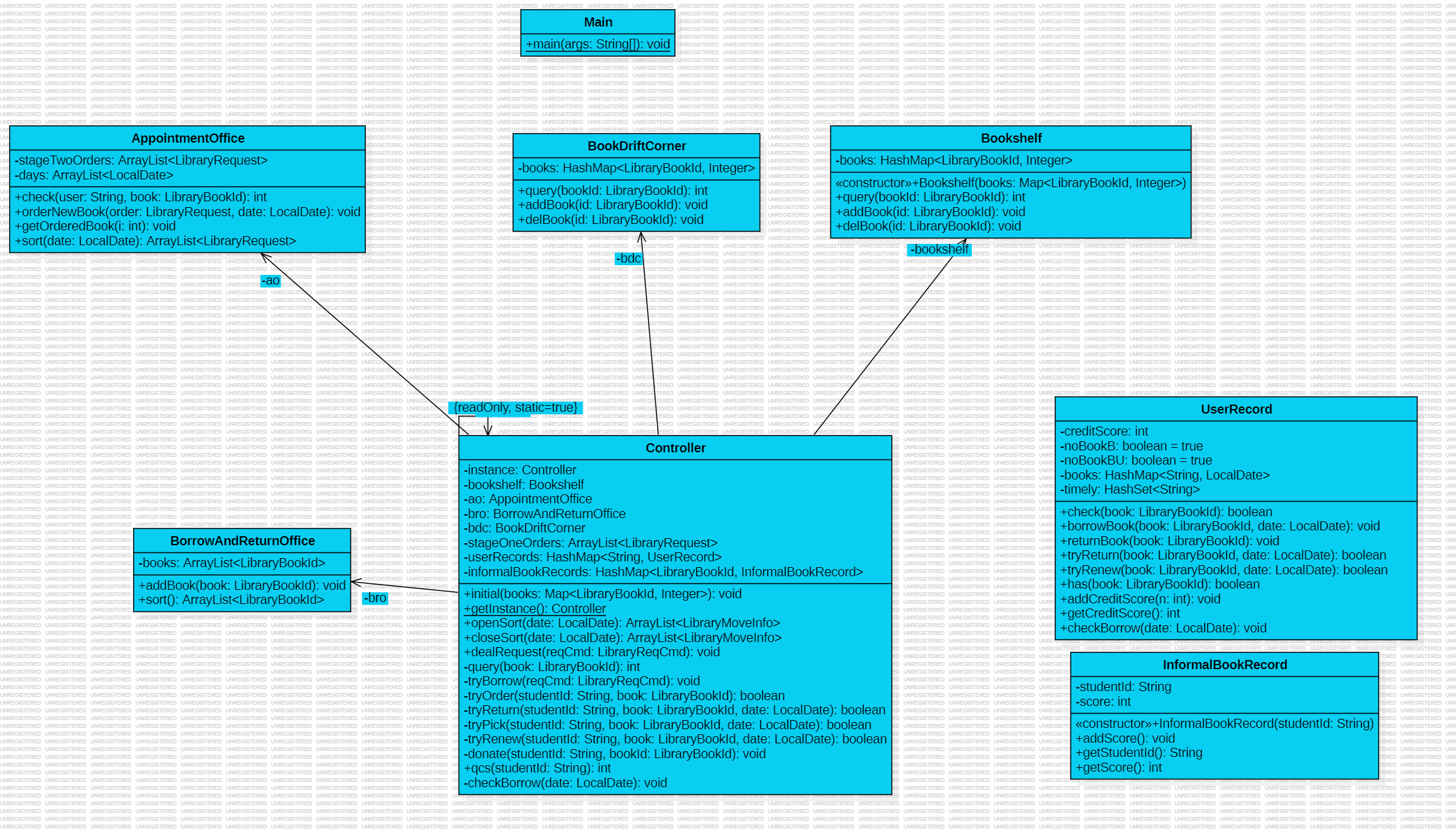
除了题目描述中提到的书架、借还处、预约处、图书漂流角外,设计了 Controller 作为中枢,用于解析请求,向各部门发送命令,并存储着用户的借书信息等重要数据。
个人认为追踪关系主要体现为代码与UML模型的一致性,主要有以下几点:
Unit1 中并没有明确的架构设计思维,只是仿照实验中的思路在写代码。类之间关系混乱,达不到低耦合的要求,进行过一次较大的重构。
Unit2 采用生产者-消费者模式,开始有意识地区分实体类和控制类,但主要心思在多线程的安全上,电梯、请求序列与电梯控制程序三个类间的分工与联系仍不清晰。
Unit3 由于 JML 规格的存在,不用花大心思进行架构设计,只需要完成 JML 中提出的要求即可。
Unit4 的架构自认为还算清晰合理,Controller 作为中枢,负责解析请求,向其他实体类发送命令,并存储着图书馆系统的核心数据。实体类只需要实现各自的功能,供 Controller 调用即可。
测试主要分为两种方法,一是根据题目要求和数据限制,手搓特定数据,争取覆盖所有可能情况及边界条件;二是用程序生成大量数据,查找可能存在的 bug。感谢 DPO 的存在, 满足了第二种方法的需求,所以这里只谈手搓的。
Unit1 的数据情况并不复杂,只需要对可能出现的几种情况分别进行测试,比如无自定义函数、有简单的自定义函数、在自定义函数的表达式中调用其他“已定义的”函数。此单元的性能问题不明显,也无需构造规模庞大的数据。
Unit2 则是性能问题非常突出的一个单元,根据数据限制,可以手搓一个负荷极大的样例,优化不好的程序很可能因此超时。
Unit3 的样例不方便手搓,不过可以写程序生成大量的查询指令进行压力测试,考察程序的性能。
Unit4 没有互测,也就没有花时间在测试上,主要借助评测机查找 bug。
面向对象的编程思想与面向过程有很大不同,四个单元的侧重点也各不相同。经过一学期的学习,自己的架构设计思维更加清晰了,Unit4 中勉强能达到高内聚低耦合的要求,也不存在非常复杂的单个方法,代码的可读性提高不少。正向建模与开发的模式也有效的减少了我试错的时间,提高了开发的效率。此外还有多线程、JML规格、UML图等知识。相信以上都会在我未来的码农生活中有所裨益。



