




4,653
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享本文基于知存科技举办的在线研讨会撰写发布。
本次研讨会主要围绕多模态大模型时代,探索异构计算的架构设计以及应用场景,从技术理论到项目实操,全方位近距离为技术爱好者们揭开新型算力架构的面纱。

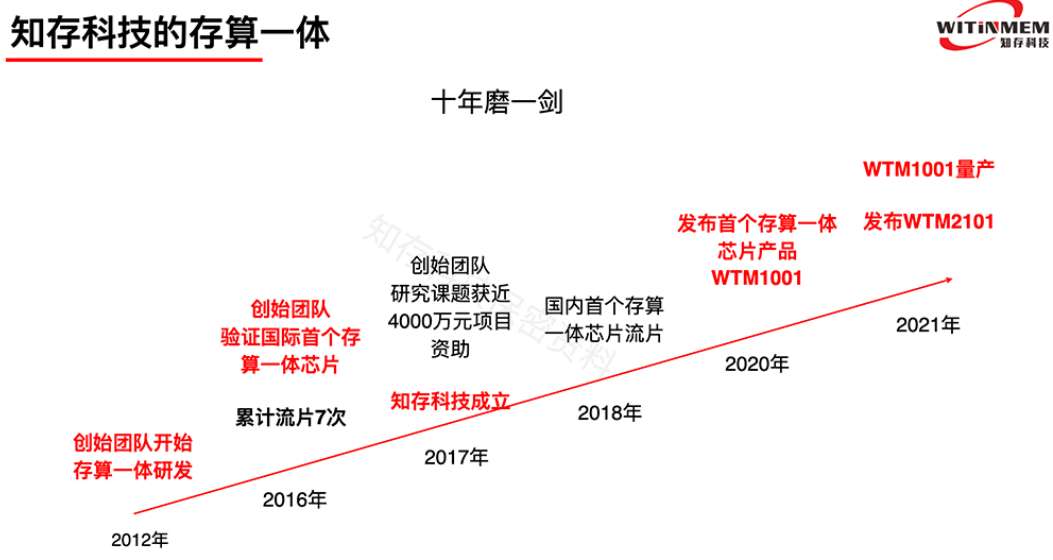
知存科技是一家专注于存内计算技术及芯片研发的创新型企业。该公司致力于开发基于新型存储器的存算一体AI芯片以及相应的智能终端系统。存内计算是一种将数据存储与计算过程紧密结合的技术,旨在解决传统计算架构中数据频繁移动导致的“存储墙”问题,从而提高计算效率和降低功耗。
知存科技的核心竞争力在于其自主研发的存算一体技术,该技术利用存储器自身的物理特性来执行计算操作,实现了数据存储与计算的深度融合。这种设计使得知存科技的芯片在处理AI任务时能够展现出更高的能效比和更快的响应速度,从而满足智能终端、物联网设备、边缘计算等领域对高效、低功耗AI计算的需求。
公司的产品线包括多个系列的存内计算芯片,这些芯片已被广泛应用于语音识别、图像识别、自然语言处理等多个AI应用场景。知存科技还积极与高校、科研机构及产业链上下游企业开展合作,共同推动存内计算技术的发展和应用。

知存科技的核心团队成员拥有丰富的行业经验和学术背景,包括北京大学、纽约大学、UCLA、UCSB等名校的学士和博士。其中,公司创始人兼CEO王绍迪是存储器和自动化设计专家,曾在ARM和Samsung实习,并收到ARM科学家职位offer。其他核心成员也在各自领域有着深厚的积累。


知存科技凭借其领先的存内计算技术和芯片产品,在市场上取得了显著的成绩。公司的芯片产品已广泛应用于智能终端、AR眼镜、降噪耳机等多个领域。
演讲嘉宾
周易,知存科技架构工程师
参与过多款芯片的架构设计,中科院微电子所硕士。在SOC,深度学习,存算一体方向有着丰富的芯片架构经验。
路英明,知存科技存算科学家,北京大学博士
长期从事新型存内计算架构、高效人工智能硬件系统等方面研究。
本次在线研讨会分别从两位专家演讲的两个方面展开,如下所述。
在现代计算技术的迅猛发展中,存内计算(In-Memory Computing, IMC)技术作为一种突破传统计算架构限制的前沿技术,正引起越来越多的关注。知存科技(KnowCurrent Technologies)的首席架构工程师周翊先生和存算科学家陆一鸣先生在最近的在线研讨会上深入探讨了这一主题。本文将基于他们的发言,详细解析存内计算技术的核心优势、应用场景以及未来发展趋势。
存内计算技术的核心思想是将计算操作直接嵌入到存储单元内部,从而减少传统冯诺依曼架构中计算和存储单元之间的数据传输。这一技术通过在存储器中嵌入计算功能,有效地缩短了数据传输路径,从而提高了计算效率和系统性能。
传统的计算架构中,CPU和内存之间的频繁数据传输导致了显著的带宽瓶颈和功耗问题。存内计算技术通过将计算逻辑集成到存储单元中,能够显著降低数据传输的需求,从而有效减少功耗和带宽消耗。

在多模态大模型时代,AI应用变得越来越复杂。以往的计算架构难以满足大模型所需的高效计算和实时处理需求。存内计算技术在这一背景下显示出了巨大的潜力和优势。
在当今大模型蓬勃发展的时代,传统的AI计算架构正面临严峻的性能瓶颈。大规模参数量的模型对存储带宽、计算功耗等提出了极高的要求,尤其在推理和训练阶段,传统架构难以支撑高效处理海量数据的需求。为应对这些挑战,存内计算(In-Memory Computing, IMC)技术正在逐渐成为一种备受关注的前沿方案。本文将基于最近技术会议的内容,详细解析存内计算在大模型中的应用优势、技术实现以及面临的挑战。
在讨论存内计算技术的优势之前,首先了解传统AI计算中的瓶颈是至关重要的。当前主流的AI计算框架,尤其是卷积神经网络,通常涉及百兆级别的权重参数量,计算密集型特点明显。大多数传统AI模型的运算过程涉及大量的计算资源,而对存储带宽的需求相对较低。然而,在大模型(如GPT-4、PaLM等)中,情况截然不同,这类模型不仅具有极大的参数量,还要求大规模的中间结果存储和高带宽的支持,进一步加剧了传统架构的瓶颈。
从功耗的角度来看,DDR(双倍数据速率内存)已经成为主流消费级产品的重要组件。然而,由于带宽和功耗限制,DDR技术的提升面临瓶颈,无论是通过增加I/O数量还是提高I/O频率,都难以满足未来大模型的需求。
存内计算(IMC)是一种将计算直接嵌入到存储单元中的技术,通过消除传统架构中计算单元与存储单元之间的数据传输,提高计算效率,降低功耗。在大模型时代,存内计算提供了有效解决高带宽需求和能效瓶颈的潜在方案。具体来说,存内计算能够显著减少存储单元和计算单元之间的数据交互,尤其是在处理神经网络中的矩阵乘法任务时,表现出极高的计算效率。
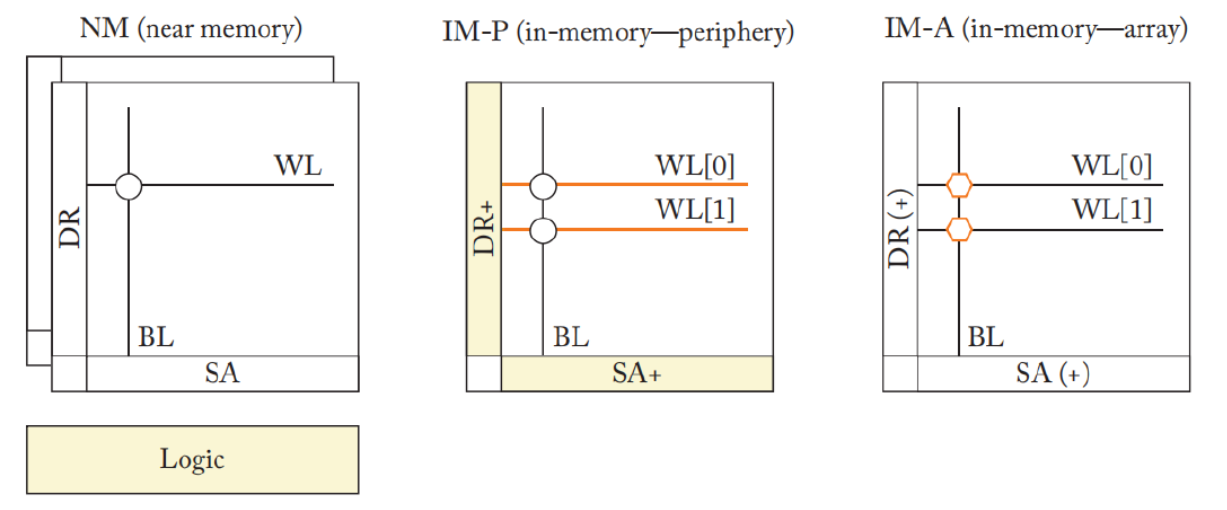
上图给出了近存计算和存内计算的两种模式,近存计算不对存储阵列作出任何修改,主要是将逻辑单元摆放在接近存储阵列的位置上。而存内计算则分为在外围电路产生计算结果的IM-P(In-Memory-Periphery)方式和在阵列内部产生计算结果的IM-A(In-Memory-Array)方式。
IM-P 可以进一步分为仅处理数字信号的数字IM-P 方法和在模拟域中执行计算的模拟 IM-P 方法。 修改后的外围电路能够实现超出正常读/写的操作,例如与不同的单元交互或加权读电压。 此类修改包括支持字线驱动器中的多行激活以及用于多级激活和感测的 DAC/ADC。 它们被设计用于实现从逻辑运算到算术运算的多种运算类型,例如向量矩阵乘法中的点积。 虽然结果是在外围电路中产生的,但存储器阵列执行了大量的计算。对外围电路的改变可能需要与传统存储器中使用的阵列不同的电流/电压读写方式。 因此,IM-P 可能会修改存储单元来提高鲁棒性。 此外,用于支持复杂功能的外围设备的附加电路可能会导致高成本。
IM-A 架构可以提供最大的带宽和能源效率,因为计算完全发生在存储阵列内部。 IM-A 可以为简单的操作提供最大的吞吐量,但其复杂的操作可能会导致高延迟。 此外,IM-A 经常需要为这种特殊的计算操作重新设计存储单元,修改正常的位线和字线结构。 由于单元和阵列的设计和布局针对特定电压/电流读写进行了高度优化。因此单元和阵列的访问方法的变化需要进行大量的重新设计工作。 此外,有时需要修改外围电路(即执行读写操作所需的逻辑电路,例如字线驱动器和读出放大器)以支持 IM-A 计算。
存内计算技术可以分为两大类:数字层存内计算和模拟层存内计算。这两种方式各有优劣,适用于不同的场景和应用需求。
模拟层存内计算
模拟层存内计算是通过模拟存储单元的方式来进行矩阵运算。它具有密度高、计算并行度大的特点,非常适合处理大规模矩阵乘法任务。在大模型中,由于模型的词向量(token embedding)和序列长度(sequence length)较大,模拟层存内计算能够在这些场景中发挥极大的优势。举例来说,在一个大模型中,我们可以实现2000×2000规模的矩阵乘法,这种能力在传统架构中是难以实现的。
然而,模拟层存内计算的一个缺点在于它的精度较难保证。由于模拟计算的特性,存在一定的噪声和误差。但正如神经网络的鲁棒性,适度的噪声不会显著影响最终结果,因此在AI推理过程中,这种误差是可以容忍的。
数字层存内计算
数字层存内计算采用数字存储单元(如SRAM)来进行计算,其主要优势在于精度高,可以达到百分之百的计算正确性。与模拟层存内计算相比,数字层的精度优势非常明显,但其劣势在于存储密度较低。例如,SRAM单元通常由六个晶体管组成,这使得它难以实现大规模矩阵运算。此外,数字层存内计算的并行度也较低,每次只能进行1比特的运算,对于8比特输入,需要逐位累加,进而得到最终结果。
存内计算技术在大模型应用中具有显著优势,特别是在以下几个方面:
AIGC等人工智能新兴产业的快速发展离不开算力,算力的基础是人工智能芯片。当前CPU/GPU在执行计算密集型任务时需要将海量参数(ωij)从内存中读取出来再进行计算,读取时间与参数规模成正比,计算芯片的功耗和性能受限,GPU算力利用率甚至不到8%。存内计算芯片实现了存储单元与计算单元的物理融合,无需读出参数,直接利用存储参数的单元(ωij)与输入矩阵X进行计算,极大节约内存读写,大幅提高计算效率,突破物理极限。
存内计算做到了存储单元和计算单元完全融合;没有独立的计算单元,直接通过在存储器颗粒上嵌入算法,由存储器芯片内部的存储单元完成计算操作,实现计算能效数量级提升。
近存计算
存储与计算分离,通过将数据靠近计算单元,缩小数据移动的延迟、减少功耗,是当前主流芯片提升性能方案,已经达到物理极限,提升能效有限且成本高昂。
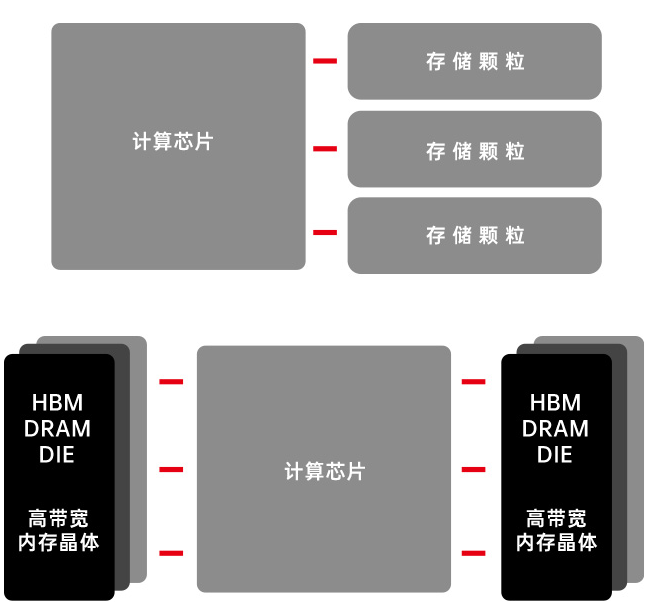
存内处理
“存”与“算”距离更近,但电路设计仍然是分离的,计算由存储器内部的独立计算单元完成。

存内计算
直接消除“存”“算”界限,无需来回搬运数据,大幅度提升芯片性能,大幅降低功耗且成本可控,是真正的存算一体。

存内计算技术在大模型时代显示出巨大的潜力,但其发展也面临着一些技术挑战。首先,如何在保持高精度的同时进一步提高存储密度和计算性能,是数字层存内计算技术需要解决的问题。其次,模拟层存内计算的精度控制也是一个关键挑战,尤其是在对精度要求更高的应用场景中,需要进一步优化计算单元的设计。
在未来,3D堆叠技术和高带宽存储器(HBM)的引入,有望进一步推动存内计算的发展。通过3D堆叠,可以实现更高密度的存储单元,进一步提升存内计算的性能。同时,HBM的高带宽特性也将弥补DDR在大模型时代的瓶颈。
存内计算技术作为未来AI计算架构的重要发展方向,已经展现出其在大模型中的巨大潜力。通过有效利用存储和计算单元的紧密结合,存内计算能够大幅提升计算效率,降低带宽消耗和功耗。在大模型推理和训练中,存内计算的应用将越来越广泛,成为支撑下一代AI应用的重要基础技术。
随着技术的不断进步,存内计算有望进一步优化现有的AI计算架构,为未来的大规模模型推理和训练提供更高效、更经济的解决方案。
近年来,随着以GPT为代表的大规模深度学习模型飞速发展,人工智能应用逐渐渗透到图像识别、语义分析、自然语言处理、自动驾驶等领域。尽管模型的性能大幅提升,但其参数规模和计算需求也呈指数级增长,对计算硬件提出了严峻的挑战。然而,传统的冯·诺依曼架构面临计算性能和存储性能之间的鸿沟,无法满足当今对大算力的需求。在这种背景下,存算一体架构(In-Memory Computing)应运而生,并迅速发展,成为解决这一瓶颈的重要技术。
在过去的几十年中,摩尔定律推动了集成电路计算性能的飞速提升。然而,随着半导体制造技术逐渐接近物理极限,单靠缩小晶体管尺寸来提升计算能力变得越来越困难。同时,传统的冯·诺依曼架构存在“存算分离”的设计,处理器和存储器分离,使得每次计算都需要通过总线来搬运数据。这导致了内存带宽瓶颈和数据搬运能耗过高等问题。随着处理器吞吐量的增长速度远超内存带宽,“冯诺依曼瓶颈”逐渐成为限制计算性能的主要因素。
为了解决这些问题,存算一体架构打破了处理器和存储器的界限,将计算直接集成到存储器中,避免了频繁的数据搬运,从而显著降低了能耗并提升计算性能。
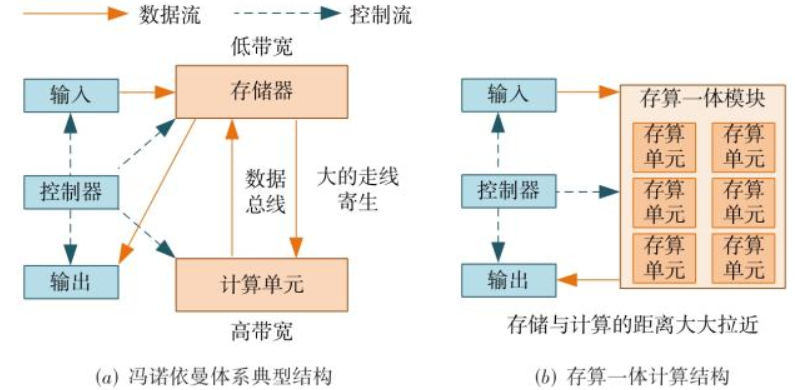
存算一体架构的核心思想是通过在存储器阵列中直接执行计算,将数据存储和计算操作紧密结合。目前,存算一体架构主要基于新型存储器件,如RRAM(电阻式存储器)、PCM(相变存储器)、MRAM(磁阻存储器)等。这些存储器件不仅具备存储功能,还能够通过电导率的调节来执行矩阵向量乘法运算。
存算一体架构中,数据的存储和计算是在同一个物理空间内进行的。例如,矩阵中的每个元素可以映射为存储器的电导值,输入向量则映射为存储器的输入电压。存储器阵列通过应用物理法则(如欧姆定律和基尔霍夫定律)来完成矩阵向量乘法,最终输出的电流即为乘法结果。这种计算方式减少了数据搬运的时间复杂度,从传统的O(N^2)降为O(1)。
在神经网络应用中,矩阵向量乘法通常是有符号的。通过电压和电流的极性来表示正负号,存算一体架构也可以轻松实现有符号的计算。具体实现时,负数权重可以通过相邻行或相邻列存储器件之间的差值来表示。
存算一体架构最早应用于加速全连接神经网络,通过将权重矩阵映射为存储器阵列的电导值,输入向量映射为电压信号,并通过外围电路读出结果,实现了显著的加速效果。这种加速方式已经被广泛应用于计算密集型任务,如深度神经网络中的矩阵运算。
近年来,存算一体架构的应用场景已经从全连接网络扩展到了更具实用性的卷积神经网络(CNN)。通过将卷积核展平为向量,并将输入数据窗口转换为矩阵,存算一体架构能够在存储器阵列中完成卷积运算,大幅度提升了计算速度和能效。此外,这种架构还能够应用于循环神经网络(RNN),从而实现时间序列预测和记忆功能。
除了加速神经网络外,存算一体架构还可以应用于其他机器学习算法的加速。例如,在K-Means聚类算法中,计算输入样本与中心点之间的欧式距离是一个矩阵向量乘法问题,完全可以通过存储器阵列来加速计算。
尽管存算一体架构在提升计算性能和能效方面表现出色,但它仍然面临一些挑战:
由于存储器阵列的物理特性限制,存算一体架构执行的计算通常为近似计算。在某些应用中,如何在保证精度的前提下实现高效计算是一个重要的研究课题。
新型存储器件的制造工艺仍在发展中,如何保证其长期工作稳定性和数据存储可靠性是工程界面临的难题。
目前存算一体架构的存储容量和计算规模仍然受到物理尺寸和工艺的限制,如何提升系统的扩展性并支持更大规模的计算任务,是未来发展需要解决的问题。
为了解决这些问题,研究人员提出了诸如多层阵列设计、改进存储器制造工艺、优化电路设计等多种解决方案。同时,提升阵列的容错能力和开发混合精度计算方法,也成为了存算一体架构发展的重要方向。
存算一体架构作为后摩尔时代的创新计算架构,凭借其独特的存储和计算融合设计,突破了传统冯·诺依曼架构的瓶颈,成为支持大规模人工智能模型计算的理想平台。尽管该架构仍然面临一些技术挑战,但其在能效、吞吐量等方面的优势无疑使其成为未来计算领域的核心技术之一。随着新型存储器件和相关技术的不断进步,我们有理由相信存算一体架构将在人工智能、数据处理等领域发挥越来越重要的作用。

知存科技的在线研讨会探讨了存内计算技术在多模态大模型时代的应用及其架构设计。存内计算作为一种突破传统计算架构的技术,能够将计算操作直接嵌入存储单元内部,有效减少数据传输、提高计算效率和降低功耗。知存科技凭借其存算一体芯片技术,解决了传统计算架构中“存储墙”问题,尤其在大规模AI模型的处理上展示了显著的性能优势。
该技术在智能终端、边缘计算和大规模数据中心等场景中展现出广泛应用潜力,特别是在面对日益复杂的多模态大模型时,存内计算可以显著提高系统效率,满足大模型的实时计算需求。此外,知存科技还详细介绍了其产品线和技术创新,通过自主研发的芯片为各类AI应用提供了低功耗、高性能的解决方案。
存内计算技术的发展,虽然面临诸如复杂操作的高延迟等挑战,但其在提升AI计算效率和节能方面的潜力,使其在未来的AI时代中占据重要地位。


