




4,692
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
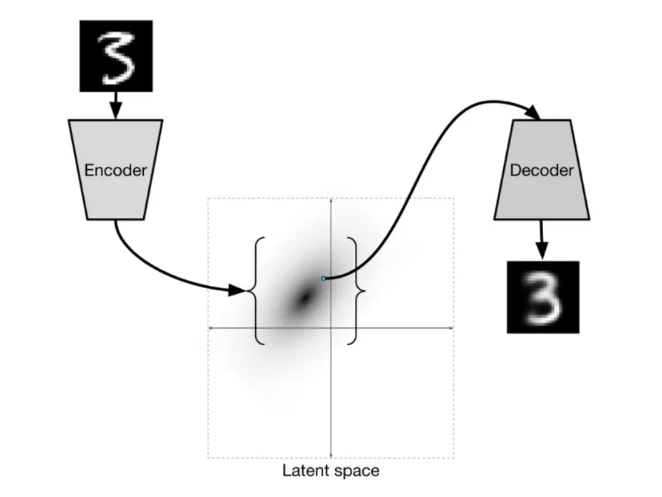
分享变分自编码器(Variational Autoencoder, VAE)是一种生成模型,在人工智能生成内容(AI-Generated Content, AIGC)领域中具有广泛的应用。本文将介绍VAE的基本原理、技术细节,并通过代码实例展示其在AIGC中的具体应用。
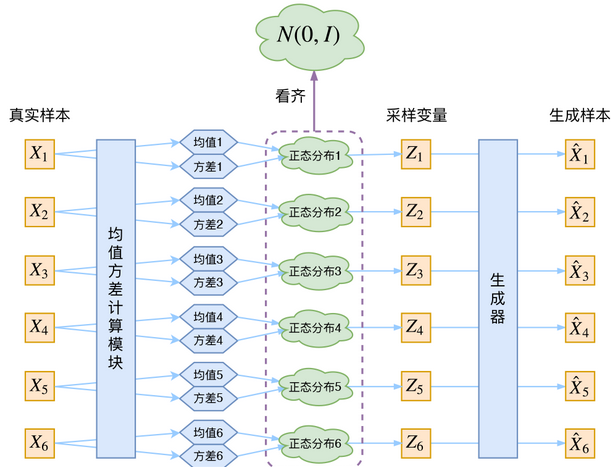
VAE是Kingma和Welling在2013年提出的一种生成模型,旨在学习数据的潜在表示,并能够生成新的数据样本。与传统的自编码器不同,VAE在编码器和解码器之间引入了概率分布的概念,使得生成的样本更加多样化和连续。
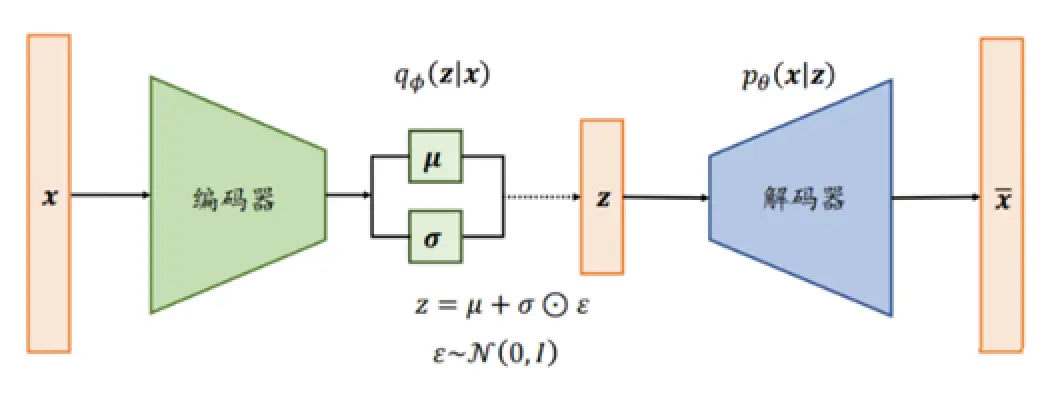
VAE的结构由两个主要部分组成:编码器和解码器。
编码器和解码器通常使用神经网络来实现,参数通过最大化证据下界(Evidence Lower Bound, ELBO)来进行优化。
VAE的损失函数由两部分组成:
损失函数公式为:
[ \mathcal{L} = \mathbb{E}_{q(z|x)} [\log p(x|z)] - \text{KL}(q(z|x) | p(z)) ]
其中,( q(z|x) )是编码器输出的潜在分布,( p(x|z) )是解码器生成的分布,( p(z) )是先验分布,通常假设为标准正态分布。
VAE在AIGC领域有许多应用,包括图像生成、文本生成和音频生成等。以下以图像生成为例,展示VAE的具体应用。
在图像生成任务中,VAE可以学习图像的潜在表示,并生成与训练数据相似的新图像。下面是一个使用VAE生成手写数字图像的代码示例。
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
# 定义编码器
class Encoder(nn.Module):
def __init__(self, input_dim, hidden_dim, latent_dim):
super(Encoder, self).__init__()
self.fc1 = nn.Linear(input_dim, hidden_dim)
self.fc_mu = nn.Linear(hidden_dim, latent_dim)
self.fc_logvar = nn.Linear(hidden_dim, latent_dim)
def forward(self, x):
h = torch.relu(self.fc1(x))
mu = self.fc_mu(h)
logvar = self.fc_logvar(h)
return mu, logvar
# 定义解码器
class Decoder(nn.Module):
def __init__(self, latent_dim, hidden_dim, output_dim):
super(Decoder, self).__init__()
self.fc1 = nn.Linear(latent_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, output_dim)
def forward(self, z):
h = torch.relu(self.fc1(z))
x_reconstructed = torch.sigmoid(self.fc2(h))
return x_reconstructed
# 定义VAE模型
class VAE(nn.Module):
def __init__(self, input_dim, hidden_dim, latent_dim):
super(VAE, self).__init__()
self.encoder = Encoder(input_dim, hidden_dim, latent_dim)
self.decoder = Decoder(latent_dim, hidden_dim, input_dim)
def reparameterize(self, mu, logvar):
std = torch.exp(0.5 * logvar)
eps = torch.randn_like(std)
return mu + eps * std
def forward(self, x):
mu, logvar = self.encoder(x)
z = self.reparameterize(mu, logvar)
x_reconstructed = self.decoder(z)
return x_reconstructed, mu, logvar
# 定义损失函数
def loss_function(x, x_reconstructed, mu, logvar):
BCE = nn.functional.binary_cross_entropy(x_reconstructed, x, reduction='sum')
KLD = -0.5 * torch.sum(1 + logvar - mu.pow(2) - logvar.exp())
return BCE + KLD
# 加载数据集
transform = transforms.ToTensor()
train_dataset = datasets.MNIST('./data', train=True, download=True, transform=transform)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=128, shuffle=True)
# 初始化模型和优化器
input_dim = 784
hidden_dim = 400
latent_dim = 20
model = VAE(input_dim, hidden_dim, latent_dim)
optimizer = optim.Adam(model.parameters(), lr=1e-3)
# 训练模型
epochs = 10
for epoch in range(epochs):
model.train()
train_loss = 0
for batch_idx, (data, _) in enumerate(train_loader):
data = data.view(-1, input_dim)
optimizer.zero_grad()
x_reconstructed, mu, logvar = model(data)
loss = loss_function(data, x_reconstructed, mu, logvar)
loss.backward()
train_loss += loss.item()
optimizer.step()
print(f'Epoch {epoch + 1}, Loss: {train_loss / len(train_loader.dataset):.4f}')
在VAE中,编码器和解码器的设计对生成效果有着重要影响。编码器负责将输入数据映射到潜在空间,解码器则将潜在变量映射回数据空间。在设计编码器和解码器时,需考虑网络的深度、激活函数的选择以及潜在空间的维度等因素。
重参数技巧是VAE的一项关键技术,使得模型可以通过反向传播来训练。具体来说,编码器输出的潜在变量是通过均值和方差生成的随机变量,重参数技巧通过引入一个标准正态分布的随机变量来实现这一过程,从而使得整个网络是可微的。
KL散度项在VAE的训练中起到正则化作用,使得潜在分布接近于先验分布。在实践中,可以通过引入一个权重因子来调节KL散度项的影响,避免过度正则化。
VAE在图像生成领域的应用非常广泛,尤其是在生成逼真的图像和进行图像处理方面。以下是一些具体的应用案例:
VAE可以用于生成逼真的人脸图像。通过训练VAE模型,能够学习到人脸图像的潜在表示,并生成与训练集相似但不完全相同的全新图像。这对于数据增强和隐私保护有重要意义。
# 加载CelebA数据集
transform = transforms.Compose([
transforms.CenterCrop(148),
transforms.Resize(64),
transforms.ToTensor(),
])
celeba_dataset = datasets.CelebA(root='./data', split='train', download=True, transform=transform)
celeba_loader = torch.utils.data.DataLoader(celeba_dataset, batch_size=128, shuffle=True)
# 定义VAE模型,输入尺寸修改为图像的尺寸
input_dim = 64 * 64 * 3
hidden_dim = 400
latent_dim = 100
model = VAE(input_dim, hidden_dim, latent_dim)
optimizer = optim.Adam(model.parameters(), lr=1e-3)
# 训练模型的代码同上
通过上述代码,可以使用CelebA数据集训练VAE模型,生成新的64x64的人脸图像。
VAE还可以用于图像去噪任务。通过训练模型学习干净图像的分布,VAE能够从噪声图像中恢复出干净的图像。
# 对于去噪任务,可以对MNIST数据集添加噪声进行训练
def add_noise(img, noise_factor=0.5):
noisy_img = img + noise_factor * torch.randn(*img.shape)
noisy_img = torch.clip(noisy_img, 0., 1.)
return noisy_img
# 加载并添加噪声
train_dataset_noisy = datasets.MNIST('./data', train=True, download=True, transform=transform)
train_loader_noisy = torch.utils.data.DataLoader(train_dataset_noisy, batch_size=128, shuffle=True)
# 修改VAE的输入为噪声图像,训练模型的代码同上
VAE在文本生成中的应用也逐渐增加,尤其是结合序列模型如RNN或LSTM,实现自然语言的生成。
通过使用VAE和RNN的结合,可以生成多样化且连贯的句子。
class SentenceVAE(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim, latent_dim):
super(SentenceVAE, self).__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim)
self.encoder_rnn = nn.LSTM(embedding_dim, hidden_dim, batch_first=True)
self.fc_mu = nn.Linear(hidden_dim, latent_dim)
self.fc_logvar = nn.Linear(hidden_dim, latent_dim)
self.decoder_rnn = nn.LSTM(latent_dim, hidden_dim, batch_first=True)
self.fc_out = nn.Linear(hidden_dim, vocab_size)
def encode(self, x):
embedded = self.embedding(x)
_, (h, _) = self.encoder_rnn(embedded)
mu = self.fc_mu(h[-1])
logvar = self.fc_logvar(h[-1])
return mu, logvar
def reparameterize(self, mu, logvar):
std = torch.exp(0.5 * logvar)
eps = torch.randn_like(std)
return mu + eps * std
def decode(self, z, seq_len):
z = z.unsqueeze(1).repeat(1, seq_len, 1)
h, _ = self.decoder_rnn(z)
return self.fc_out(h)
def forward(self, x):
mu, logvar = self.encode(x)
z = self.reparameterize(mu, logvar)
return self.decode(z, x.size(1)), mu, logvar
# 定义损失函数和数据集,进行训练同上
VAE在音频生成和处理方面也有显著的应用。例如,在语音合成和音频去噪中,通过学习音频信号的潜在表示,能够生成高质量的音频样本或去除噪声。
通过训练VAE模型,可以合成不同说话人声音的语音片段。
# 定义语音数据集处理
# 假设我们有语音数据集X,每个样本为一段语音信号
# 预处理语音数据,将其转换为频谱图,输入VAE进行训练
虽然VAE在生成任务中表现出色,但与GAN(生成对抗网络)相比,生成质量仍有差距。未来的研究可以探索VAE与GAN的结合,利用VAE的结构化潜在空间和GAN的高质量生成能力,提升生成效果。
处理高维数据(如高分辨率图像和长文本序列)是VAE面临的一大挑战。研究者可以通过设计更深层的网络结构或引入新型的正则化技术,提升VAE对高维数据的处理能力。
多模态生成(如同时生成图像和文本)是VAE未来的重要发展方向。通过学习不同模态数据的联合分布,VAE可以实现跨模态生成任务,为多媒体内容生成带来新的可能性。
条件变分自编码器(CVAE)是VAE的一种扩展,它能够在生成过程中引入额外的信息(条件),以控制生成结果的某些属性。CVAE通过将条件信息与输入数据一起传递给编码器和解码器,学习条件信息和数据之间的关系。
在图像生成任务中,CVAE可以根据特定的标签生成对应类别的图像。例如,生成手写数字时,可以指定生成的数字类别。
class CVAE(nn.Module):
def __init__(self, input_dim, hidden_dim, latent_dim, condition_dim):
super(CVAE, self).__init__()
self.fc1 = nn.Linear(input_dim + condition_dim, hidden_dim)
self.fc_mu = nn.Linear(hidden_dim, latent_dim)
self.fc_logvar = nn.Linear(hidden_dim, latent_dim)
self.fc2 = nn.Linear(latent_dim + condition_dim, hidden_dim)
self.fc3 = nn.Linear(hidden_dim, input_dim)
def encode(self, x, c):
h = torch.relu(self.fc1(torch.cat([x, c], dim=-1)))
mu = self.fc_mu(h)
logvar = self.fc_logvar(h)
return mu, logvar
def decode(self, z, c):
h = torch.relu(self.fc2(torch.cat([z, c], dim=-1)))
x_reconstructed = torch.sigmoid(self.fc3(h))
return x_reconstructed
def reparameterize(self, mu, logvar):
std = torch.exp(0.5 * logvar)
eps = torch.randn_like(std)
return mu + eps * std
def forward(self, x, c):
mu, logvar = self.encode(x, c)
z = self.reparameterize(mu, logvar)
return self.decode(z, c), mu, logvar
# 条件信息c是one-hot编码的数字标签
# 定义损失函数和训练过程的代码同VAE,只是输入多了条件信息
递归变分自编码器(RVAE)将VAE与递归神经网络(RNN)结合,用于处理序列数据,如文本或时间序列。RVAE在编码器和解码器中引入递归结构,使得模型能够捕捉序列数据中的时间依赖关系。
RVAE可以用于生成连续的文本或时间序列数据。例如,生成一段特定风格的文本或预测未来的时间序列值。
class RVAE(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim, latent_dim):
super(RVAE, self).__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim)
self.encoder_rnn = nn.LSTM(embedding_dim, hidden_dim, batch_first=True)
self.fc_mu = nn.Linear(hidden_dim, latent_dim)
self.fc_logvar = nn.Linear(hidden_dim, latent_dim)
self.decoder_rnn = nn.LSTM(latent_dim, hidden_dim, batch_first=True)
self.fc_out = nn.Linear(hidden_dim, vocab_size)
def encode(self, x):
embedded = self.embedding(x)
_, (h, _) = self.encoder_rnn(embedded)
mu = self.fc_mu(h[-1])
logvar = self.fc_logvar(h[-1])
return mu, logvar
def reparameterize(self, mu, logvar):
std = torch.exp(0.5 * logvar)
eps = torch.randn_like(std)
return mu + eps * std
def decode(self, z, seq_len):
z = z.unsqueeze(1).repeat(1, seq_len, 1)
h, _ = self.decoder_rnn(z)
return self.fc_out(h)
def forward(self, x):
mu, logvar = self.encode(x)
z = self.reparameterize(mu, logvar)
return self.decode(z, x.size(1)), mu, logvar
# 定义损失函数和数据集,进行训练同上
离散变分自编码器(DVAE)是一种专门处理离散数据的VAE扩展。DVAE通过对潜在空间进行离散化处理,使得模型能够更好地处理离散数据,如文本或分类数据。
DVAE可以用于生成离散文本数据,尤其是生成自然语言句子。通过对潜在空间进行离散化处理,DVAE能够学习文本数据的离散表示,并生成新的句子。
class DVAE(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim, latent_dim, num_embeddings):
super(DVAE, self).__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim)
self.encoder_rnn = nn.LSTM(embedding_dim, hidden_dim, batch_first=True)
self.latent_embedding = nn.Embedding(num_embeddings, latent_dim)
self.fc_out = nn.Linear(hidden_dim, num_embeddings)
def encode(self, x):
embedded = self.embedding(x)
_, (h, _) = self.encoder_rnn(embedded)
logits = self.fc_out(h[-1])
return logits
def reparameterize(self, logits):
probs = torch.softmax(logits, dim=-1)
return torch.argmax(probs, dim=-1)
def decode(self, z):
z_embedded = self.latent_embedding(z)
return z_embedded
def forward(self, x):
logits = self.encode(x)
z = self.reparameterize(logits)
z_embedded = self.decode(z)
return z_embedded, logits
# 定义损失函数和数据集,进行训练同上
VAE在半监督学习中也有重要应用。通过利用少量有标签数据和大量无标签数据,VAE能够提高模型的泛化能力。
在半监督图像分类任务中,VAE可以通过生成未标记数据的潜在表示,辅助分类器进行分类。
class SemiSupervisedVAE(nn.Module):
def __init__(self, input_dim, hidden_dim, latent_dim, num_classes):
super(SemiSupervisedVAE, self).__init__()
self.encoder = Encoder(input_dim, hidden_dim, latent_dim)
self.decoder = Decoder(latent_dim, hidden_dim, input_dim)
self.classifier = nn.Linear(latent_dim, num_classes)
def forward(self, x):
mu, logvar = self.encoder(x)
z = self.reparameterize(mu, logvar)
x_reconstructed = self.decoder(z)
class_logits = self.classifier(z)
return x_reconstructed, mu, logvar, class_logits
# 定义损失函数,包含重构误差、KL散度和分类损失
# 训练过程同上,只是加入分类损失
在医疗领域,VAE被用于生成和分析医疗图像。通过学习病理图像的潜在表示,VAE能够生成高质量的医疗图像,辅助医生进行诊断。
VAE可以用于生成不同类型的病理图像,辅助医疗研究和教育。
# 定义医疗图像数据集和VAE模型
# 训练过程同上
在推荐系统中,VAE被用于学习用户和物品的潜在表示,从而提供个性化推荐。
通过将用户的行为数据输入VAE,生成用户的潜在表示,从而推荐符合用户兴趣的物品。
class RecommendationVAE(nn.Module):
def __init__(self, num_items, hidden_dim, latent_dim):
super(RecommendationVAE, self).__init__()
self.encoder = Encoder(num_items, hidden_dim, latent_dim)
self.decoder = Decoder(latent_dim, hidden_dim, num_items)
def forward(self, x):
mu, logvar = self.encoder(x)
z = self.reparameterize(mu, logvar)
x_reconstructed = self.decoder(z)
return x_reconstructed, mu, logvar
# 定义损失函数和数据集,进行训练同上
VAE在异常检测中也有应用,通过学习正常数据的分布,VAE能够检测出异常数据。
在工业领域,VAE可以用于检测设备运行中的异常情况,提前预警故障。
class AnomalyDetectionVAE(nn.Module):
def __init__(self, input_dim, hidden_dim, latent_dim):
super(AnomalyDetectionVAE, self).__init__()
self.encoder = Encoder(input_dim, hidden_dim, latent_dim)
self.decoder = Decoder(latent_dim, hidden_dim, input_dim)
def forward(self, x):
mu, logvar = self.encoder(x)
z = self.reparameterize(mu, logvar)
x_reconstructed = self.decoder(z)
return x_reconstructed, mu, logvar
# 定义损失函数和数据集,进行训练同上
# 通过计算重构误差判断异常

变分自编码器在AIGC领域的应用非常广泛,涵盖图像、文本和音频的生成与处理。通过不断探索VAE的技术扩展和实际应用,研究人员可以在生成任务中取得更好的效果,推动AIGC领域的进一步发展。未来,随着技术的不断进步,VAE将在更多实际应用中发挥重要作用,为人类创造更加丰富多彩的数字世界。


