




4,700
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享人工智能生成内容(AIGC,AI-Generated Content)在图像生成领域取得了显著的进展。本文将探讨从卷积神经网络(CNN)到风格迁移(Style Transfer)的技术演变,并通过代码实例展示其应用。
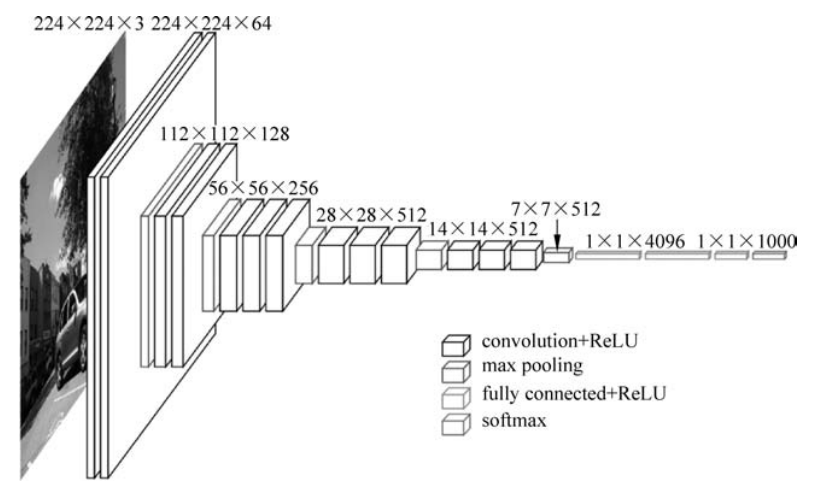
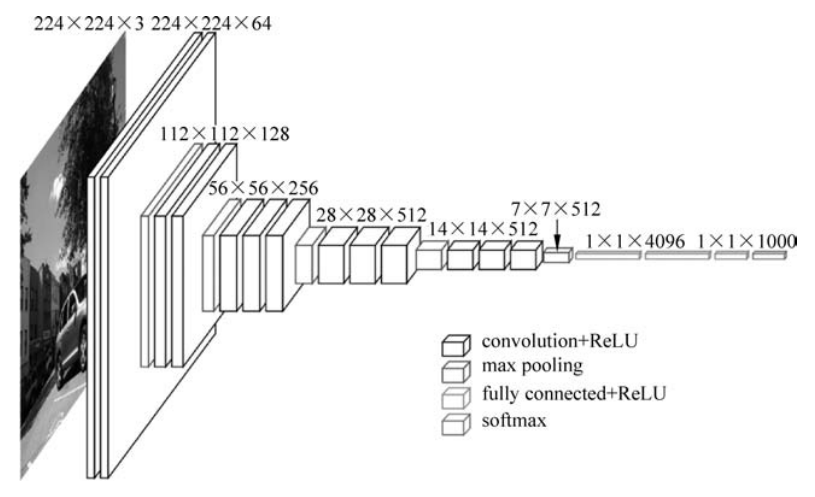
卷积神经网络是图像处理的基石。它通过卷积层、池化层和全连接层对图像进行特征提取和分类。下面是一个简单的CNN模型,用于对CIFAR-10数据集进行图像分类。
import tensorflow as tf
from tensorflow.keras import layers, models
import matplotlib.pyplot as plt
import numpy as np
# 加载CIFAR-10数据集
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.cifar10.load_data()
# 数据预处理
x_train, x_test = x_train / 255.0, x_test / 255.0
# 定义CNN模型
model = models.Sequential([
layers.Conv2D(32, (3, 3), activation='relu', input_shape=(32, 32, 3)),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(64, (3, 3), activation='relu'),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(64, (3, 3), activation='relu'),
layers.Flatten(),
layers.Dense(64, activation='relu'),
layers.Dense(10)
])
# 编译模型
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
# 训练模型
history = model.fit(x_train, y_train, epochs=10,
validation_data=(x_test, y_test))
# 绘制训练结果
plt.plot(history.history['accuracy'], label='accuracy')
plt.plot(history.history['val_accuracy'], label = 'val_accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.ylim([0, 1])
plt.legend(loc='lower right')
plt.show()
该模型包括三个卷积层,每个卷积层后面跟一个最大池化层,用于减少特征图的尺寸。最后,通过两个全连接层进行分类。
风格迁移是图像生成的一个重要应用。它通过将一幅图像的内容与另一幅图像的风格结合,生成新的图像。其背后的核心技术是卷积神经网络和基于梯度优化的图像重构。
风格迁移算法通常包括以下步骤:
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.applications import vgg19
from tensorflow.keras.preprocessing import image
from tensorflow.keras.models import Model
# 加载并预处理图像
def preprocess_image(img_path):
img = image.load_img(img_path, target_size=(224, 224))
img = image.img_to_array(img)
img = np.expand_dims(img, axis=0)
img = vgg19.preprocess_input(img)
return img
def deprocess_image(x):
x[:, :, 0] += 103.939
x[:, :, 1] += 116.779
x[:, :, 2] += 123.68
x = x[:, :, ::-1]
x = np.clip(x, 0, 255).astype('uint8')
return x
# 加载VGG19模型
content_image = preprocess_image('path_to_content_image.jpg')
style_image = preprocess_image('path_to_style_image.jpg')
# 定义模型
model = vgg19.VGG19(weights='imagenet', include_top=False)
# 提取内容和风格特征
content_layer = 'block5_conv2'
style_layers = ['block1_conv1', 'block2_conv1', 'block3_conv1', 'block4_conv1', 'block5_conv1']
content_model = Model(inputs=model.input, outputs=model.get_layer(content_layer).output)
style_models = [Model(inputs=model.input, outputs=model.get_layer(layer).output) for layer in style_layers]
# 定义损失函数
def content_loss(base, target):
return tf.reduce_mean(tf.square(base - target))
def gram_matrix(x):
x = tf.transpose(x, (2, 0, 1))
features = tf.reshape(x, (tf.shape(x)[0], -1))
gram = tf.matmul(features, tf.transpose(features))
return gram
def style_loss(base, gram_target):
return tf.reduce_mean(tf.square(gram_matrix(base) - gram_target))
# 初始化生成图像
generated_image = tf.Variable(preprocess_image('path_to_initial_image.jpg'))
# 优化器
optimizer = tf.optimizers.Adam(learning_rate=0.02)
# 风格迁移训练步骤
@tf.function
def train_step(generated_image):
with tf.GradientTape() as tape:
content_output = content_model(generated_image)
content_output_target = content_model(content_image)
c_loss = content_loss(content_output, content_output_target)
s_loss = 0
for style_model, target in zip(style_models, style_image):
style_output = style_model(generated_image)
target_gram = gram_matrix(style_model(style_image))
s_loss += style_loss(style_output, target_gram)
total_loss = c_loss + s_loss
grad = tape.gradient(total_loss, generated_image)
optimizer.apply_gradients([(grad, generated_image)])
return total_loss
# 进行风格迁移
epochs = 1000
for epoch in range(epochs):
loss = train_step(generated_image)
if epoch % 100 == 0:
print(f'Epoch {epoch}, Loss: {loss.numpy()}')
# 显示结果
output_image = deprocess_image(generated_image.numpy()[0])
plt.imshow(output_image)
plt.show()
该模型使用预训练的VGG-19网络提取内容图像和风格图像的特征,通过最小化内容损失和风格损失来优化生成图像。内容损失确保生成图像保留内容图像的主要结构,风格损失确保生成图像具有风格图像的纹理特征。

生成对抗网络(GAN)是图像生成领域的另一重要技术。由Ian Goodfellow等人于2014年提出,GAN通过两个网络(生成器和判别器)之间的对抗训练,生成逼真的图像。
GAN由生成器(Generator)和判别器(Discriminator)组成:
生成器的目标是生成逼真到足以欺骗判别器的图像,而判别器的目标是尽可能准确地区分真实图像和生成图像。这种对抗训练使得生成器能够逐步生成更加逼真的图像。
import tensorflow as tf
from tensorflow.keras import layers
import numpy as np
import matplotlib.pyplot as plt
# 定义生成器模型
def build_generator():
model = tf.keras.Sequential([
layers.Dense(256, input_dim=100),
layers.LeakyReLU(alpha=0.2),
layers.BatchNormalization(momentum=0.8),
layers.Dense(512),
layers.LeakyReLU(alpha=0.2),
layers.BatchNormalization(momentum=0.8),
layers.Dense(1024),
layers.LeakyReLU(alpha=0.2),
layers.BatchNormalization(momentum=0.8),
layers.Dense(28 * 28 * 1, activation='tanh'),
layers.Reshape((28, 28, 1))
])
return model
# 定义判别器模型
def build_discriminator():
model = tf.keras.Sequential([
layers.Flatten(input_shape=(28, 28, 1)),
layers.Dense(512),
layers.LeakyReLU(alpha=0.2),
layers.Dense(256),
layers.LeakyReLU(alpha=0.2),
layers.Dense(1, activation='sigmoid')
])
return model
# 编译判别器
discriminator = build_discriminator()
discriminator.compile(loss='binary_crossentropy', optimizer=tf.keras.optimizers.Adam(0.0002, 0.5), metrics=['accuracy'])
# 编译生成器
generator = build_generator()
# 生成器输入噪声,输出生成图像
z = layers.Input(shape=(100,))
img = generator(z)
# 使判别器在生成器训练期间保持不变
discriminator.trainable = False
# 判别器判断生成图像的真伪
valid = discriminator(img)
# 创建组合模型(生成器+判别器)
combined = tf.keras.Model(z, valid)
combined.compile(loss='binary_crossentropy', optimizer=tf.keras.optimizers.Adam(0.0002, 0.5))
# 加载MNIST数据集
(x_train, _), (_, _) = tf.keras.datasets.mnist.load_data()
x_train = (x_train / 127.5) - 1.0
x_train = np.expand_dims(x_train, axis=3)
# 训练GAN
batch_size = 64
epochs = 10000
save_interval = 1000
# 真实和生成标签
real = np.ones((batch_size, 1))
fake = np.zeros((batch_size, 1))
for epoch in range(epochs):
# 训练判别器
idx = np.random.randint(0, x_train.shape[0], batch_size)
real_imgs = x_train[idx]
noise = np.random.normal(0, 1, (batch_size, 100))
gen_imgs = generator.predict(noise)
d_loss_real = discriminator.train_on_batch(real_imgs, real)
d_loss_fake = discriminator.train_on_batch(gen_imgs, fake)
d_loss = 0.5 * np.add(d_loss_real, d_loss_fake)
# 训练生成器
noise = np.random.normal(0, 1, (batch_size, 100))
g_loss = combined.train_on_batch(noise, real)
# 输出进度
if epoch % save_interval == 0:
print(f"{epoch} [D loss: {d_loss[0]} | D accuracy: {100 * d_loss[1]}] [G loss: {g_loss}]")
# 保存生成的图像样本
r, c = 5, 5
noise = np.random.normal(0, 1, (r * c, 100))
gen_imgs = generator.predict(noise)
gen_imgs = 0.5 * gen_imgs + 0.5
fig, axs = plt.subplots(r, c)
cnt = 0
for i in range(r):
for j in range(c):
axs[i, j].imshow(gen_imgs[cnt, :, :, 0], cmap='gray')
axs[i, j].axis('off')
cnt += 1
plt.show()
该GAN模型采用MNIST数据集,生成器接收100维的随机噪声并生成28x28的灰度图像。判别器负责判断输入图像是真实的还是生成的。在训练过程中,生成器和判别器通过对抗性训练不断优化,使生成的图像逐渐接近真实图像。
变分自动编码器(VAE)是一种生成模型,通过学习数据的概率分布来生成新图像。VAE将输入图像编码为一个潜在空间的分布,然后从该分布中采样并解码为新图像。
VAE由编码器(Encoder)和解码器(Decoder)组成:
VAE通过最大化似然函数和最小化KL散度来优化模型。
import tensorflow as tf
from tensorflow.keras import layers, models
import numpy as np
import matplotlib.pyplot as plt
# 编码器模型
latent_dim = 2
def build_encoder():
inputs = layers.Input(shape=(28, 28, 1))
x = layers.Conv2D(32, 3, activation='relu', strides=2, padding='same')(inputs)
x = layers.Conv2D(64, 3, activation='relu', strides=2, padding='same')(x)
x = layers.Flatten()(x)
x = layers.Dense(16, activation='relu')(x)
z_mean = layers.Dense(latent_dim)(x)
z_log_var = layers.Dense(latent_dim)(x)
return models.Model(inputs, [z_mean, z_log_var], name='encoder')
# 采样函数
def sampling(args):
z_mean, z_log_var = args
batch = tf.shape(z_mean)[0]
dim = tf.shape(z_mean)[1]
epsilon = tf.keras.backend.random_normal(shape=(batch, dim))
return z_mean + tf.exp(0.5 * z_log_var) * epsilon
# 解码器模型
def build_decoder():
latent_inputs = layers.Input(shape=(latent_dim,))
x = layers.Dense(7 * 7 * 64, activation='relu')(latent_inputs)
x = layers.Reshape((7, 7, 64))(x)
x = layers.Conv2DTranspose(64, 3, activation='relu', strides=2, padding='same')(x)
x = layers.Conv2DTranspose(32, 3, activation='relu', strides=2, padding='same')(x)
outputs = layers.Conv2DTranspose(1, 3, activation='sigmoid', padding='same')(x)
return models.Model(latent_inputs, outputs, name='decoder')
# 构建VAE模型
encoder = build_encoder()
decoder = build_decoder()
inputs = layers.Input(shape=(28, 28, 1))
z_mean, z_log_var = encoder(inputs)
z = layers.Lambda(sampling)([z_mean, z_log_var])
outputs = decoder(z)
vae = models.Model(inputs, outputs, name='vae')
# VAE损失函数
reconstruction_loss = tf.reduce_mean(tf.keras.losses.binary_crossentropy(inputs, outputs))
reconstruction_loss *= 28 * 28
kl_loss = 1 + z_log_var - tf.square(z_mean) - tf.exp(z_log_var)
kl_loss = tf.reduce_mean(kl_loss)
kl_loss *= -0.5
vae_loss = reconstruction_loss + kl_loss
vae.add_loss(vae_loss)
vae.compile(optimizer='adam')
# 加载MNIST数据集
(x_train, _), (x_test, _) = tf.keras.datasets.mnist.load_data()
x_train = np.expand_dims(x_train, axis=-1).astype('float32') / 255
x_test = np.expand_dims(x_test, axis=-1).astype('float32') / 255
# 训练VAE
vae.fit(x_train, epochs=50, batch_size=128, validation_data=(x_test, None))
# 生成图像
def plot
_latent_space(vae, n=30, figsize=15):
scale = 1.0
figure = np.zeros((28 * n, 28 * n))
grid_x = np.linspace(-scale, scale, n)
grid_y = np.linspace(-scale, scale, n)
for i, yi in enumerate(grid_y):
for j, xi in enumerate(grid_x):
z_sample = np.array([[xi, yi]])
x_decoded = vae.decoder.predict(z_sample)
digit = x_decoded[0].reshape(28, 28)
figure[i * 28: (i + 1) * 28, j * 28: (j + 1) * 28] = digit
plt.figure(figsize=(figsize, figsize))
plt.imshow(figure, cmap='Greys_r')
plt.show()
plot_latent_space(vae)
该VAE模型采用MNIST数据集,通过编码器将输入图像编码为潜在空间的均值和方差,再通过采样和解码器生成新的图像。VAE通过最大化重建图像的似然和最小化潜在空间的KL散度来进行训练,生成的图像在潜在空间中具有良好的连续性和多样性。
自回归模型是另一类生成模型,通过逐步预测图像的像素或块来生成图像。典型的自回归模型包括PixelCNN和PixelRNN,它们通过条件概率分布来建模图像生成过程。

自回归模型的核心思想是将图像生成过程视为一个序列问题,通过先前生成的像素或块的条件概率来生成当前像素或块。这样可以捕捉图像的局部依赖性和全局结构。
以下是一个简单的PixelCNN模型示例,应用于MNIST数据集。
import tensorflow as tf
from tensorflow.keras import layers, models
import numpy as np
import matplotlib.pyplot as plt
# PixelCNN模型
def build_pixelcnn():
inputs = layers.Input(shape=(28, 28, 1))
x = layers.Conv2D(64, (7, 7), padding='same', activation='relu')(inputs)
for _ in range(7):
x = layers.Conv2D(64, (3, 3), padding='same', activation='relu')(x)
outputs = layers.Conv2D(256, (1, 1), activation='softmax')(x)
return models.Model(inputs, outputs, name='pixelcnn')
# 编译PixelCNN模型
pixelcnn = build_pixelcnn()
pixelcnn.compile(optimizer='adam', loss='sparse_categorical_crossentropy')
# 加载MNIST数据集
(x_train, _), (x_test, _) = tf.keras.datasets.mnist.load_data()
x_train = np.expand_dims(x_train, axis=-1).astype('float32') / 255
x_test = np.expand_dims(x_test, axis=-1).astype('float32') / 255
# 训练PixelCNN
pixelcnn.fit(x_train, x_train, epochs=10, batch_size=64, validation_data=(x_test, x_test))
# 生成图像
def generate_image(model, seed=None):
if seed is not None:
np.random.seed(seed)
img = np.zeros((1, 28, 28, 1))
for i in range(28):
for j in range(28):
logits = model.predict(img)
probs = logits[0, i, j]
pixel = np.random.choice(256, p=probs)
img[0, i, j, 0] = pixel / 255.0
return img[0, :, :, 0]
generated_image = generate_image(pixelcnn, seed=42)
plt.imshow(generated_image, cmap='gray')
plt.show()
该PixelCNN模型通过逐像素预测图像生成过程。模型由多个卷积层组成,通过条件概率分布逐步生成图像像素。训练时,模型优化每个像素的交叉熵损失。生成图像时,模型依赖先前生成的像素预测当前像素,从而生成完整图像。
扩散模型是一类生成模型,通过逆过程从噪声中逐步还原图像。它们通常由两个过程组成:前向扩散过程和逆向还原过程。扩散模型近年来在图像生成任务中取得了显著成果。
扩散模型的前向过程将图像逐步添加噪声,最终得到纯噪声图像。逆向过程则从纯噪声图像开始,通过逐步去噪,还原出原始图像。模型通过学习这两个过程的概率分布来实现图像生成。
以下是一个简单的扩散模型示例,应用于MNIST数据集。
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
# 定义扩散模型
class DiffusionModel(tf.keras.Model):
def __init__(self, input_shape):
super(DiffusionModel, self).__init__()
self.encoder = tf.keras.Sequential([
tf.keras.layers.Conv2D(64, (3, 3), activation='relu', padding='same', input_shape=input_shape),
tf.keras.layers.MaxPooling2D((2, 2)),
tf.keras.layers.Conv2D(128, (3, 3), activation='relu', padding='same'),
tf.keras.layers.MaxPooling2D((2, 2)),
])
self.decoder = tf.keras.Sequential([
tf.keras.layers.Conv2DTranspose(128, (3, 3), activation='relu', padding='same'),
tf.keras.layers.UpSampling2D((2, 2)),
tf.keras.layers.Conv2DTranspose(64, (3, 3), activation='relu', padding='same'),
tf.keras.layers.UpSampling2D((2, 2)),
tf.keras.layers.Conv2DTranspose(1, (3, 3), activation='sigmoid', padding='same'),
])
def call(self, inputs):
encoded = self.encoder(inputs)
decoded = self.decoder(encoded)
return decoded
# 编译扩散模型
input_shape = (28, 28, 1)
diffusion_model = DiffusionModel(input_shape)
diffusion_model.compile(optimizer='adam', loss='mse')
# 加载MNIST数据集
(x_train, _), (x_test, _) = tf.keras.datasets.mnist.load_data()
x_train = np.expand_dims(x_train, axis=-1).astype('float32') / 255
x_test = np.expand_dims(x_test, axis=-1).astype('float32') / 255
# 训练扩散模型
diffusion_model.fit(x_train, x_train, epochs=10, batch_size=64, validation_data=(x_test, x_test))
# 生成图像
def generate_diffused_image(model, input_image, steps=100):
noise = np.random.normal(size=input_image.shape)
for step in range(steps):
t = step / steps
alpha = 1.0 - t
noisy_image = alpha * input_image + (1 - alpha) * noise
denoised_image = model.predict(np.expand_dims(noisy_image, axis=0))[0]
input_image = denoised_image
return denoised_image
# 测试生成过程
input_image = x_test[np.random.randint(len(x_test))]
generated_image = generate_diffused_image(diffusion_model, input_image)
# 显示结果
plt.figure(figsize=(10, 5))
plt.subplot(1, 2, 1)
plt.title('Input Image')
plt.imshow(input_image.squeeze(), cmap='gray')
plt.subplot(1, 2, 2)
plt.title('Generated Image')
plt.imshow(generated_image.squeeze(), cmap='gray')
plt.show()
扩散模型通过逐步添加和去除噪声来实现图像生成。模型由卷积神经网络组成,包括编码器和解码器部分。前向过程将图像逐步添加噪声,逆向过程通过模型逐步去噪还原图像。通过训练,模型学习如何从噪声中生成逼真的图像。
风格迁移(Style Transfer)是指将一种图像的内容与另一种图像的风格相结合,生成新的图像。这种技术在艺术创作和图像处理领域有广泛应用。
风格迁移的核心思想是利用卷积神经网络(CNN)来提取图像的内容特征和风格特征,然后通过优化算法将两者结合。通常使用预训练的VGG网络提取图像的特征:
通过优化一个输入图像,使其内容特征接近内容图像,而风格特征接近风格图像,从而实现风格迁移。
以下是一个简单的风格迁移代码示例,使用TensorFlow和VGG19模型。
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
# 加载VGG19模型
vgg = tf.keras.applications.VGG19(include_top=False, weights='imagenet')
vgg.trainable = False
# 提取VGG19的特定层作为特征提取器
content_layers = ['block5_conv2']
style_layers = ['block1_conv1', 'block2_conv1', 'block3_conv1', 'block4_conv1', 'block5_conv1']
num_content_layers = len(content_layers)
num_style_layers = len(style_layers)
# 构建特征提取模型
def vgg_model(layer_names):
outputs = [vgg.get_layer(name).output for name in layer_names]
model = tf.keras.Model([vgg.input], outputs)
return model
content_model = vgg_model(content_layers)
style_model = vgg_model(style_layers)
# 加载并预处理图像
def load_and_process_img(path):
img = tf.keras.preprocessing.image.load_img(path)
img = tf.keras.preprocessing.image.img_to_array(img)
img = tf.image.resize(img, (224, 224))
img = tf.keras.applications.vgg19.preprocess_input(img)
return np.expand_dims(img, axis=0)
def deprocess_img(processed_img):
x = processed_img.copy()
if len(x.shape) == 4:
x = np.squeeze(x, 0)
x[:, :, 0] += 103.939
x[:, :, 1] += 116.779
x[:, :, 2] += 123.68
x = x[:, :, ::-1]
x = np.clip(x, 0, 255).astype('uint8')
return x
content_path = 'path_to_content_image.jpg'
style_path = 'path_to_style_image.jpg'
content_image = load_and_process_img(content_path)
style_image = load_and_process_img(style_path)
# 定义内容损失和风格损失
def content_loss(base_content, target):
return tf.reduce_mean(tf.square(base_content - target))
def gram_matrix(input_tensor):
result = tf.linalg.einsum('bijc,bijd->bcd', input_tensor, input_tensor)
input_shape = tf.shape(input_tensor)
num_locations = tf.cast(input_shape[1]*input_shape[2], tf.float32)
return result / num_locations
def style_loss(base_style, gram_target):
height, width, channels = base_style.get_shape().as_list()
gram_style = gram_matrix(base_style)
return tf.reduce_mean(tf.square(gram_style - gram_target))
# 定义总变差损失
def total_variation_loss(image):
x_deltas, y_deltas = image[:, :, 1:, :] - image[:, :, :-1, :], image[:, 1:, :, :] - image[:, :-1, :, :]
return tf.reduce_sum(tf.abs(x_deltas)) + tf.reduce_sum(tf.abs(y_deltas))
# 提取内容和风格特征
def get_feature_representations(model, content_path, style_path):
content_image = load_and_process_img(content_path)
style_image = load_and_process_img(style_path)
style_outputs = style_model(style_image)
content_outputs = content_model(content_image)
style_features = [style_layer[0] for style_layer in style_outputs]
content_features = [content_layer[0] for content_layer in content_outputs]
return style_features, content_features
style_features, content_features = get_feature_representations(vgg, content_path, style_path)
# 创建风格迁移模型
class StyleContentModel(tf.keras.models.Model):
def __init__(self, style_layers, content_layers):
super(StyleContentModel, self).__init__()
self.vgg = vgg_model(style_layers + content_layers)
self.style_layers = style_layers
self.content_layers = content_layers
self.num_style_layers = len(style_layers)
self.vgg.trainable = False
def call(self, inputs):
"Expects float input in [0,1]"
inputs = inputs * 255.0
preprocessed_input = tf.keras.applications.vgg19.preprocess_input(inputs)
outputs = self.vgg(preprocessed_input)
style_outputs, content_outputs = (outputs[:self.num_style_layers], outputs[self.num_style_layers:])
style_outputs = [gram_matrix(style_output) for style_output in style_outputs]
content_dict = {content_name:value for content_name, value in zip(self.content_layers, content_outputs)}
style_dict = {style_name:value for style_name, value in zip(self.style_layers, style_outputs)}
return {'content':content_dict, 'style':style_dict}
# 定义优化过程
style_content_model = StyleContentModel(style_layers, content_layers)
opt = tf.keras.optimizers.Adam(learning_rate=0.02, beta_1=0.99, epsilon=1e-1)
@tf.function()
def train_step(image):
with tf.GradientTape() as tape:
outputs = style_content_model(image)
style_loss_val = tf.add_n([style_loss(outputs['style'][name], style_features[i])
for i, name in enumerate(outputs['style'])])
style_loss_val *= 1e-2 / num_style_layers
content_loss_val = tf.add_n([content_loss(outputs['content'][name], content_features[i])
for i, name in enumerate(outputs['content'])])
content_loss_val *= 1e4 / num_content_layers
loss = style_loss_val + content_loss_val
loss += 30 * total_variation_loss(image)
grad = tape.gradient(loss, image)
opt.apply_gradients([(grad, image)])
image.assign(tf.clip_by_value(image, clip_value_min=0.0, clip_value_max=1.0))
# 初始化生成图像
image = tf.Variable(content_image, dtype=tf.float32)
# 训练模型
epochs = 10
steps_per_epoch = 100
step = 0
for n in range(epochs):
for m in range(steps_per_epoch):
step += 1
train_step(image)
print(".", end='', flush=True)
display.clear_output(wait=True)
plt.imshow(deprocess_img(image.numpy()))
plt.title(f"Train step: {step}")
plt.show()
上述风格迁移模型使用VGG19网络提取图像的内容特征和风格特征。通过优化一个随机初始化的输入图像,使其内容特征接近内容图像,风格特征接近风格图像。最终生成的图像融合了内容图像的结构和风格图像的纹理,实现了风格迁移。
AIGC(AI Generated Content)图像生成技术在近年来取得了显著进展。卷积神经网络、生成对抗网络、变分自动编码器、自回归模型、扩散模型和风格迁移等技术的出现,使得机器生成图像的质量和多样性显著提升。
未来,AIGC图像生成技术将继续向以下几个方向发展:
随着技术的不断进步,AIGC图像生成技术将变得更加成熟,应用前景也将更加广阔。


