




4,693
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享在人工智能生成内容(AIGC,Artificial Intelligence Generated Content)领域,强化学习(RL,Reinforcement Learning)技术发挥着重要作用。强化学习是机器学习的一种方法,通过与环境的交互,智能体(agent)学会采取行动以最大化累积奖励。在AIGC中,强化学习能够用于生成艺术作品、音乐、文本内容等。本文将探讨强化学习的基本原理,并通过代码实例展示其在AIGC中的应用。
强化学习涉及以下几个核心概念:
强化学习的目标是通过试错(trial-and-error)过程,找到最优策略以最大化累积奖励。
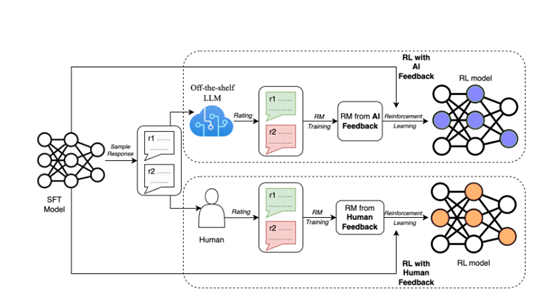
强化学习算法主要包括:
强化学习可以用于优化生成模型,使其生成高质量、连贯的文本内容。例如,使用策略梯度方法优化生成文本的质量。
下面是一个基于策略梯度的简单文本生成模型示例:
import numpy as np
import tensorflow as tf
from tensorflow.keras import layers
class TextGenerator(tf.keras.Model):
def __init__(self, vocab_size, embedding_dim, rnn_units):
super().__init__()
self.embedding = layers.Embedding(vocab_size, embedding_dim)
self.gru = layers.GRU(rnn_units, return_sequences=True, return_state=True)
self.dense = layers.Dense(vocab_size)
def call(self, inputs, states=None, return_state=False, training=False):
x = self.embedding(inputs, training=training)
if states is None:
states = self.gru.get_initial_state(x)
x, states = self.gru(x, initial_state=states, training=training)
x = self.dense(x, training=training)
if return_state:
return x, states
else:
return x
def compute_loss(labels, logits):
loss = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=labels, logits=logits)
return tf.reduce_mean(loss)
@tf.function
def train_step(model, inputs, labels, optimizer):
with tf.GradientTape() as tape:
predictions = model(inputs)
loss = compute_loss(labels, predictions)
grads = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(grads, model.trainable_variables))
return loss
# 数据准备和训练过程(简化示例)
vocab_size = 5000 # 假设词汇表大小为5000
embedding_dim = 256
rnn_units = 1024
model = TextGenerator(vocab_size, embedding_dim, rnn_units)
optimizer = tf.keras.optimizers.Adam()
# 假设inputs和labels是准备好的训练数据
# inputs = ...
# labels = ...
EPOCHS = 10
for epoch in range(EPOCHS):
loss = train_step(model, inputs, labels, optimizer)
print(f'Epoch {epoch+1}, Loss: {loss.numpy()}')
强化学习还可以应用于图像生成,例如使用生成对抗网络(GAN)和强化学习结合,优化生成图像的质量和多样性。
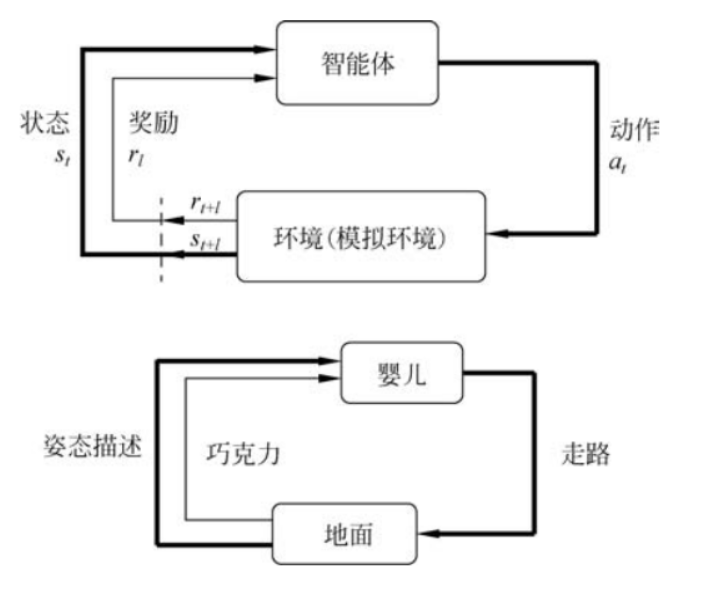
以下是一个结合强化学习和GAN的简单示例:
import tensorflow as tf
from tensorflow.keras import layers
class Generator(tf.keras.Model):
def __init__(self):
super().__init__()
self.dense1 = layers.Dense(7 * 7 * 256, use_bias=False)
self.batch_norm1 = layers.BatchNormalization()
self.leaky_relu1 = layers.LeakyReLU()
self.reshape = layers.Reshape((7, 7, 256))
self.conv2d_transpose1 = layers.Conv2DTranspose(128, (5, 5), strides=(1, 1), padding='same', use_bias=False)
self.batch_norm2 = layers.BatchNormalization()
self.leaky_relu2 = layers.LeakyReLU()
self.conv2d_transpose2 = layers.Conv2DTranspose(64, (5, 5), strides=(2, 2), padding='same', use_bias=False)
self.batch_norm3 = layers.BatchNormalization()
self.leaky_relu3 = layers.LeakyReLU()
self.conv2d_transpose3 = layers.Conv2DTranspose(1, (5, 5), strides=(2, 2), padding='same', use_bias=False, activation='tanh')
def call(self, inputs, training=False):
x = self.dense1(inputs)
x = self.batch_norm1(x, training=training)
x = self.leaky_relu1(x)
x = self.reshape(x)
x = self.conv2d_transpose1(x, training=training)
x = self.batch_norm2(x, training=training)
x = self.leaky_relu2(x)
x = self.conv2d_transpose2(x, training=training)
x = self.batch_norm3(x, training=training)
x = self.leaky_relu3(x)
return self.conv2d_transpose3(x)
class Discriminator(tf.keras.Model):
def __init__(self):
super().__init__()
self.conv2d1 = layers.Conv2D(64, (5, 5), strides=(2, 2), padding='same')
self.leaky_relu1 = layers.LeakyReLU()
self.dropout1 = layers.Dropout(0.3)
self.conv2d2 = layers.Conv2D(128, (5, 5), strides=(2, 2), padding='same')
self.leaky_relu2 = layers.LeakyReLU()
self.dropout2 = layers.Dropout(0.3)
self.flatten = layers.Flatten()
self.dense = layers.Dense(1)
def call(self, inputs, training=False):
x = self.conv2d1(inputs)
x = self.leaky_relu1(x)
x = self.dropout1(x, training=training)
x = self.conv2d2(x)
x = self.leaky_relu2(x)
x = self.dropout2(x, training=training)
x = self.flatten(x)
return self.dense(x)
# 数据准备和训练过程(简化示例)
cross_entropy = tf.keras.losses.BinaryCrossentropy(from_logits=True)
def discriminator_loss(real_output, fake_output):
real_loss = cross_entropy(tf.ones_like(real_output), real_output)
fake_loss = cross_entropy(tf.zeros_like(fake_output), fake_output)
return real_loss + fake_loss
def generator_loss(fake_output):
return cross_entropy(tf.ones_like(fake_output), fake_output)
generator = Generator()
discriminator = Discriminator()
generator_optimizer = tf.keras.optimizers.Adam(1e-4)
discriminator_optimizer = tf.keras.optimizers.Adam(1e-4)
@tf.function
def train_step(images):
noise = tf.random.normal([BATCH_SIZE, noise_dim])
with tf.GradientTape() as gen_tape, tf.GradientTape() as disc_tape:
generated_images = generator(noise, training=True)
real_output = discriminator(images, training=True)
fake_output = discriminator(generated_images, training=True)
gen_loss = generator_loss(fake_output)
disc_loss = discriminator_loss(real_output, fake_output)
gradients_of_generator = gen_tape.gradient(gen_loss, generator.trainable_variables)
gradients_of_discriminator = disc_tape.gradient(disc_loss, discriminator.trainable_variables)
generator_optimizer.apply_gradients(zip(gradients_of_generator, generator.trainable_variables))
discriminator_optimizer.apply_gradients(zip(gradients_of_discriminator, discriminator.trainable_variables))
# 假设train_dataset是准备好的训练数据
# for epoch in range(EPOCHS):
# for image_batch in train_dataset:
# train_step(image_batch)
强化学习在游戏内容生成方面也具有显著的应用价值。通过训练智能体,可以自动生成游戏关卡、角色行为模式等,使游戏更加多样化和具有挑战性。
以下示例展示了如何使用Q学习算法生成简单的游戏关卡:
import numpy as np
import random
class GridWorld:
def __init__(self, size=5):
self.size = size
self.grid = np.zeros((size, size))
self.state = (0, 0)
self.end_state = (size-1, size-1)
self.actions = [(0, 1), (1, 0), (0, -1), (-1, 0)] # 右、下、左、上
self.grid[self.end_state] = 1 # 目标状态
def reset(self):
self.state = (0, 0)
return self.state
def step(self, action):
new_state = (self.state[0] + action[0], self.state[1] + action[1])
if 0 <= new_state[0] < self.size and 0 <= new_state[1] < self.size:
self.state = new_state
reward = 1 if self.state == self.end_state else -0.1
done = self.state == self.end_state
return self.state, reward, done
def get_state(self):
return self.state
def q_learning(env, episodes=1000, alpha=0.1, gamma=0.9, epsilon=0.1):
q_table = np.zeros((env.size, env.size, len(env.actions)))
for _ in range(episodes):
state = env.reset()
done = False
while not done:
if random.uniform(0, 1) < epsilon:
action_idx = random.choice(range(len(env.actions)))
else:
action_idx = np.argmax(q_table[state[0], state[1]])
action = env.actions[action_idx]
next_state, reward, done = env.step(action)
next_max = np.max(q_table[next_state[0], next_state[1]])
q_table[state[0], state[1], action_idx] = q_table[state[0], state[1], action_idx] + \
alpha * (reward + gamma * next_max - q_table[state[0], state[1], action_idx])
state = next_state
return q_table
env = GridWorld(size=5)
q_table = q_learning(env)
def generate_level(q_table, env):
level = np.zeros((env.size, env.size))
state = env.reset()
level[state] = 1
done = False
while not done:
action_idx = np.argmax(q_table[state[0], state[1]])
action = env.actions[action_idx]
state, _, done = env.step(action)
level[state] = 1
return level
level = generate_level(q_table, env)
print("Generated Level:")
print(level)
在音乐生成领域,强化学习可以用于创作旋律、和弦进程等。通过奖励函数,可以评估音乐片段的和谐美感,进而指导生成高质量的音乐。
以下示例展示了如何使用强化学习生成简单的音乐片段:
import numpy as np
import random
class MusicEnvironment:
def __init__(self, sequence_length=16, num_notes=12):
self.sequence_length = sequence_length
self.num_notes = num_notes
self.state = [0] * sequence_length
self.end_state = [1] * sequence_length # 简化的终止状态
self.actions = list(range(num_notes))
def reset(self):
self.state = [0] * self.sequence_length
return self.state
def step(self, action):
self.state.pop(0)
self.state.append(action)
reward = self._evaluate_sequence(self.state)
done = self.state == self.end_state
return self.state, reward, done
def _evaluate_sequence(self, sequence):
# 简单的评价函数,鼓励更多变化的音符
unique_notes = len(set(sequence))
return unique_notes / len(sequence)
def get_state(self):
return self.state
def q_learning(env, episodes=1000, alpha=0.1, gamma=0.9, epsilon=0.1):
q_table = np.zeros((env.sequence_length, env.num_notes, len(env.actions)))
for _ in range(episodes):
state = env.reset()
done = False
while not done:
if random.uniform(0, 1) < epsilon:
action = random.choice(env.actions)
else:
action = np.argmax(q_table[tuple(state)])
next_state, reward, done = env.step(action)
next_max = np.max(q_table[tuple(next_state)])
q_table[tuple(state)][action] += alpha * (reward + gamma * next_max - q_table[tuple(state)][action])
state = next_state
return q_table
env = MusicEnvironment(sequence_length=16, num_notes=12)
q_table = q_learning(env)
def generate_music(q_table, env):
sequence = env.reset()
done = False
music = []
while not done:
action = np.argmax(q_table[tuple(sequence)])
sequence, _, done = env.step(action)
music.append(action)
return music
music = generate_music(q_table, env)
print("Generated Music Sequence:")
print(music)
强化学习还可以应用于视频内容生成,特别是在生成动画、视频片段以及优化视频编辑流程等方面。通过强化学习算法,智能体可以学习如何生成连续的视觉内容,保持视觉连贯性和艺术风格。
以下示例展示了如何使用深度强化学习生成连续的视频帧,模拟视频内容生成:
import tensorflow as tf
from tensorflow.keras import layers
import numpy as np
class VideoGenerator(tf.keras.Model):
def __init__(self, input_shape):
super().__init__()
self.conv1 = layers.Conv2D(64, (3, 3), activation='relu', padding='same')
self.conv2 = layers.Conv2D(128, (3, 3), activation='relu', padding='same')
self.flatten = layers.Flatten()
self.dense1 = layers.Dense(256, activation='relu')
self.dense2 = layers.Dense(np.prod(input_shape), activation='sigmoid')
self.reshape = layers.Reshape(input_shape)
def call(self, inputs, training=False):
x = self.conv1(inputs)
x = self.conv2(x)
x = self.flatten(x)
x = self.dense1(x)
x = self.dense2(x)
return self.reshape(x)
class VideoDiscriminator(tf.keras.Model):
def __init__(self):
super().__init__()
self.conv1 = layers.Conv2D(64, (3, 3), activation='relu', padding='same')
self.conv2 = layers.Conv2D(128, (3, 3), activation='relu', padding='same')
self.flatten = layers.Flatten()
self.dense1 = layers.Dense(256, activation='relu')
self.dense2 = layers.Dense(1, activation='sigmoid')
def call(self, inputs, training=False):
x = self.conv1(inputs)
x = self.conv2(x)
x = self.flatten(x)
x = self.dense1(x)
return self.dense2(x)
# 假设input_shape是视频帧的形状,例如(64, 64, 3)
input_shape = (64, 64, 3)
generator = VideoGenerator(input_shape)
discriminator = VideoDiscriminator()
generator_optimizer = tf.keras.optimizers.Adam(1e-4)
discriminator_optimizer = tf.keras.optimizers.Adam(1e-4)
cross_entropy = tf.keras.losses.BinaryCrossentropy(from_logits=True)
def discriminator_loss(real_output, fake_output):
real_loss = cross_entropy(tf.ones_like(real_output), real_output)
fake_loss = cross_entropy(tf.zeros_like(fake_output), fake_output)
return real_loss + fake_loss
def generator_loss(fake_output):
return cross_entropy(tf.ones_like(fake_output), fake_output)
@tf.function
def train_step(generator, discriminator, images, noise_dim):
noise = tf.random.normal([BATCH_SIZE, noise_dim])
with tf.GradientTape() as gen_tape, tf.GradientTape() as disc_tape:
generated_images = generator(noise, training=True)
real_output = discriminator(images, training=True)
fake_output = discriminator(generated_images, training=True)
gen_loss = generator_loss(fake_output)
disc_loss = discriminator_loss(real_output, fake_output)
gradients_of_generator = gen_tape.gradient(gen_loss, generator.trainable_variables)
gradients_of_discriminator = disc_tape.gradient(disc_loss, discriminator.trainable_variables)
generator_optimizer.apply_gradients(zip(gradients_of_generator, generator.trainable_variables))
discriminator_optimizer.apply_gradients(zip(gradients_of_discriminator, discriminator.trainable_variables))
# 假设train_dataset是准备好的视频帧训练数据
# for epoch in range(EPOCHS):
# for image_batch in train_dataset:
# train_step(generator, discriminator, image_batch, noise_dim)
尽管强化学习在AIGC中的应用潜力巨大,但仍面临一些挑战:
为解决这些挑战,未来可以考虑以下方向:
强化学习在对话系统(如聊天机器人和虚拟助手)中也具有重要应用。通过与用户的交互,系统可以不断学习和优化对话策略,提供更自然、连贯和有价值的对话体验。
以下示例展示了如何使用深度强化学习(DQN)优化对话系统的回复策略:
import numpy as np
import tensorflow as tf
from tensorflow.keras import layers
from collections import deque
import random
class DQN(tf.keras.Model):
def __init__(self, state_shape, action_size):
super(DQN, self).__init__()
self.dense1 = layers.Dense(24, activation='relu', input_shape=state_shape)
self.dense2 = layers.Dense(24, activation='relu')
self.dense3 = layers.Dense(action_size, activation=None)
def call(self, state):
x = self.dense1(state)
x = self.dense2(x)
return self.dense3(x)
class ReplayBuffer:
def __init__(self, max_size):
self.buffer = deque(maxlen=max_size)
def add(self, experience):
self.buffer.append(experience)
def sample(self, batch_size):
return random.sample(self.buffer, batch_size)
def size(self):
return len(self.buffer)
class DialogueEnvironment:
def __init__(self):
self.state = None
self.action_space = ["Hi", "How can I help you?", "Goodbye"]
self.state_space = 3 # Simplified state space
self.action_size = len(self.action_space)
def reset(self):
self.state = np.zeros(self.state_space)
return self.state
def step(self, action):
reward = random.choice([1, -1])
done = random.choice([True, False])
next_state = np.random.rand(self.state_space)
return next_state, reward, done
def train_dqn(env, episodes=1000, batch_size=64, gamma=0.99, epsilon=1.0, epsilon_min=0.1, epsilon_decay=0.995, alpha=0.001):
state_shape = (env.state_space,)
action_size = env.action_size
q_network = DQN(state_shape, action_size)
q_network.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=alpha), loss='mse')
replay_buffer = ReplayBuffer(10000)
for episode in range(episodes):
state = env.reset()
done = False
while not done:
if np.random.rand() <= epsilon:
action = random.randrange(action_size)
else:
q_values = q_network.predict(np.array([state]))
action = np.argmax(q_values[0])
next_state, reward, done = env.step(action)
replay_buffer.add((state, action, reward, next_state, done))
state = next_state
if replay_buffer.size() > batch_size:
minibatch = replay_buffer.sample(batch_size)
states = np.array([experience[0] for experience in minibatch])
actions = np.array([experience[1] for experience in minibatch])
rewards = np.array([experience[2] for experience in minibatch])
next_states = np.array([experience[3] for experience in minibatch])
dones = np.array([experience[4] for experience in minibatch])
target_q_values = rewards + gamma * np.amax(q_network.predict(next_states), axis=1) * (1 - dones)
target_f = q_network.predict(states)
for i, action in enumerate(actions):
target_f[i][action] = target_q_values[i]
q_network.fit(states, target_f, epochs=1, verbose=0)
if epsilon > epsilon_min:
epsilon *= epsilon_decay
return q_network
env = DialogueEnvironment()
dqn_model = train_dqn(env)
def generate_reply(dqn_model, state):
q_values = dqn_model.predict(np.array([state]))
action = np.argmax(q_values[0])
return env.action_space[action]
# 示例对话生成
state = env.reset()
for _ in range(5):
reply = generate_reply(dqn_model, state)
print(f"Bot: {reply}")
state, _, done = env.step(random.randrange(env.action_size))
if done:
break
个性化推荐系统通过分析用户的行为数据,推荐合适的内容(如电影、商品、新闻等)。强化学习能够不断优化推荐策略,提供更精准的推荐结果。
以下示例展示了如何使用强化学习优化推荐策略:
import numpy as np
import tensorflow as tf
from tensorflow.keras import layers
from collections import deque
import random
class DQN(tf.keras.Model):
def __init__(self, state_shape, action_size):
super(DQN, self).__init__()
self.dense1 = layers.Dense(24, activation='relu', input_shape=state_shape)
self.dense2 = layers.Dense(24, activation='relu')
self.dense3 = layers.Dense(action_size, activation=None)
def call(self, state):
x = self.dense1(state)
x = self.dense2(x)
return self.dense3(x)
class ReplayBuffer:
def __init__(self, max_size):
self.buffer = deque(maxlen=max_size)
def add(self, experience):
self.buffer.append(experience)
def sample(self, batch_size):
return random.sample(self.buffer, batch_size)
def size(self):
return len(self.buffer)
class RecommendationEnvironment:
def __init__(self, num_users=100, num_items=100):
self.num_users = num_users
self.num_items = num_items
self.state = np.zeros(num_items)
self.action_space = list(range(num_items))
self.state_space = num_items
self.action_size = num_items
def reset(self):
self.state = np.zeros(self.state_space)
return self.state
def step(self, action):
reward = random.choice([1, -1])
done = random.choice([True, False])
next_state = np.random.rand(self.state_space)
return next_state, reward, done
def train_dqn(env, episodes=1000, batch_size=64, gamma=0.99, epsilon=1.0, epsilon_min=0.1, epsilon_decay=0.995, alpha=0.001):
state_shape = (env.state_space,)
action_size = env.action_size
q_network = DQN(state_shape, action_size)
q_network.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=alpha), loss='mse')
replay_buffer = ReplayBuffer(10000)
for episode in range(episodes):
state = env.reset()
done = False
while not done:
if np.random.rand() <= epsilon:
action = random.randrange(action_size)
else:
q_values = q_network.predict(np.array([state]))
action = np.argmax(q_values[0])
next_state, reward, done = env.step(action)
replay_buffer.add((state, action, reward, next_state, done))
state = next_state
if replay_buffer.size() > batch_size:
minibatch = replay_buffer.sample(batch_size)
states = np.array([experience[0] for experience in minibatch])
actions = np.array([experience[1] for experience in minibatch])
rewards = np.array([experience[2] for experience in minibatch])
next_states = np.array([experience[3] for experience in minibatch])
dones = np.array([experience[4] for experience in minibatch])
target_q_values = rewards + gamma * np.amax(q_network.predict(next_states), axis=1) * (1 - dones)
target_f = q_network.predict(states)
for i, action in enumerate(actions):
target_f[i][action] = target_q_values[i]
q_network.fit(states, target_f, epochs=1, verbose=0)
if epsilon > epsilon_min:
epsilon *= epsilon_decay
return q_network
env = RecommendationEnvironment()
dqn_model = train_dqn(env)
def recommend(dqn_model, state):
q_values = dqn_model.predict(np.array([state]))
action = np.argmax(q_values[0])
return action
# 示例推荐生成
state = env.reset()
for _ in range(5):
item = recommend(dqn_model, state)
print(f"Recommended item: {item}")
state, _, done = env.step(random.randrange(env.action_size))
if done:
break
本文探讨了强化学习技术在AIGC(人工智能生成内容)中的广泛应用,并通过详细的代码实例展示了其在文本生成、图像生成、游戏关卡生成、音乐生成、视频内容生成、对话系统和个性化推荐系统等多个领域的应用。强化学习通过不断与环境交互,优化生成策略,能够生成高质量、个性化和多样化的内容。
尽管强化学习在AIGC中展现了巨大的潜力,但仍面临计算资源需求高、奖励设计复杂、数据依赖性强和模型稳定性等挑战。


