




4,683
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
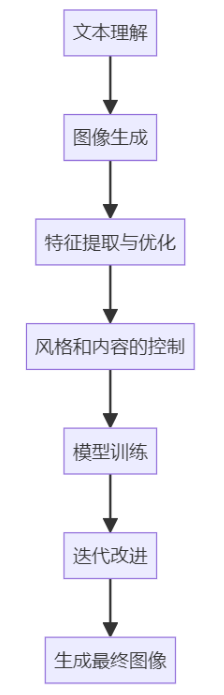
分享人工智能在创造艺术领域的应用日益广泛,特别是AI生成艺术的技术。这些技术利用深度学习模型和复杂的算法,使计算机能够创作出视觉艺术作品,例如画作、音乐或诗歌,其艺术性和创造力令人惊叹。本文将探讨AI生成艺术的技术基础,重点介绍其中的算法和模型,并通过代码实例来展示其实际运作。
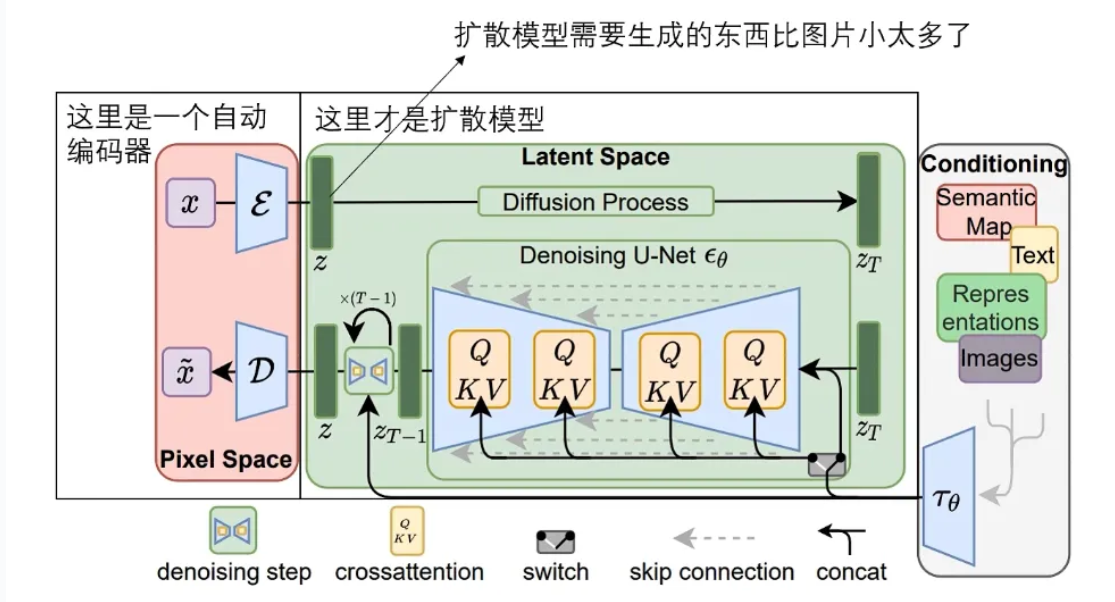
AI生成艺术的关键在于其算法能力,其中最重要的包括生成对抗网络(GAN)和变分自编码器(VAE)等。
生成对抗网络是一种由两个神经网络组成的系统:生成器和判别器。生成器负责生成看起来像真实艺术作品的图像,而判别器则负责评估这些图像的真实性。两者通过对抗训练的方式相互竞争,最终使得生成器能够生成逼真且富有创意的艺术作品。
# 示例代码:生成对抗网络(GAN)的基本结构
import tensorflow as tf
from tensorflow.keras.layers import Dense, Reshape, Flatten
from tensorflow.keras.models import Sequential
from tensorflow.keras.optimizers import Adam
# 生成器模型
generator = Sequential([
Dense(256, input_dim=100, activation='relu'),
Dense(512, activation='relu'),
Dense(784, activation='sigmoid'),
Reshape((28, 28))
])
# 判别器模型
discriminator = Sequential([
Flatten(input_shape=(28, 28)),
Dense(512, activation='relu'),
Dense(256, activation='relu'),
Dense(1, activation='sigmoid')
])
# 编译判别器模型
discriminator.compile(loss='binary_crossentropy', optimizer=Adam(lr=0.0002, beta_1=0.5))
# GAN模型(连接生成器和判别器)
gan = Sequential([generator, discriminator])
gan.compile(loss='binary_crossentropy', optimizer=Adam(lr=0.0002, beta_1=0.5))
变分自编码器是一种学习数据的概率分布并生成新数据的神经网络模型。它通过学习数据分布的潜在变量来生成具有艺术性的图像或其他形式的作品。VAE通过优化编码和解码的过程,使得生成的结果不仅具有多样性,还能在潜在空间内进行插值和探索。
# 示例代码:变分自编码器(VAE)的基本结构
from tensorflow.keras.layers import Input, Lambda, Dense
from tensorflow.keras.models import Model
import tensorflow.keras.backend as K
# 编码器
inputs = Input(shape=(784,))
h = Dense(256, activation='relu')(inputs)
z_mean = Dense(2)(h)
z_log_var = Dense(2)(h)
# 采样函数
def sampling(args):
z_mean, z_log_var = args
epsilon = K.random_normal(shape=(K.shape(z_mean)[0], 2), mean=0., stddev=1.)
return z_mean + K.exp(z_log_var / 2) * epsilon
z = Lambda(sampling)([z_mean, z_log_var])
# 解码器
decoder_h = Dense(256, activation='relu')
decoder_mean = Dense(784, activation='sigmoid')
h_decoded = decoder_h(z)
x_decoded_mean = decoder_mean(h_decoded)
# VAE模型
vae = Model(inputs, x_decoded_mean)
# 定义VAE的损失函数
xent_loss = 784 * tf.keras.losses.binary_crossentropy(inputs, x_decoded_mean)
kl_loss = -0.5 * K.sum(1 + z_log_var - K.square(z_mean) - K.exp(z_log_var), axis=-1)
vae_loss = K.mean(xent_loss + kl_loss)
vae.add_loss(vae_loss)
vae.compile(optimizer='adam')
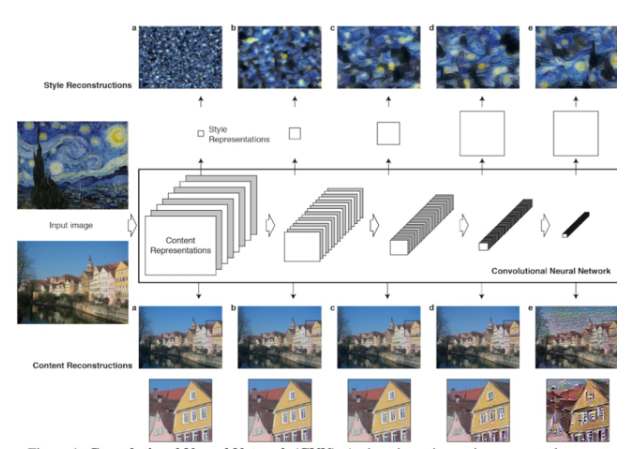
AI生成艺术的模型不仅限于单一的算法,而是通过不断创新和组合多种技术来提高生成作品的质量和创意。然而,这些技术也面临着数据需求大、模型训练时间长、结果评估主观等挑战。
在未来,随着计算能力和算法的进步,AI生成艺术有望进一步融入到日常生活中,为艺术家和创作者提供更多的灵感和工具。通过不断深入研究和技术创新,AI生成艺术将成为推动艺术创新和文化发展的重要力量。
总结来说,AI生成艺术的技术基础在于强大的深度学习算法和模型,如GAN和VAE,它们通过复杂的神经网络结构和优化算法使计算机能够生成高质量和富有创意的艺术作品,这不仅是技术进步的体现,也为艺术和文化领域带来了新的可能性和机遇。
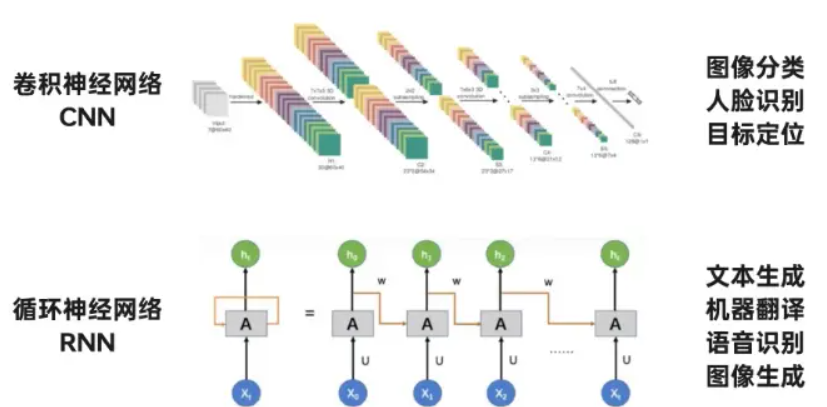
随着人工智能技术的发展,艺术生成模型不仅仅局限于静态图像的生成,还涉及到音乐、文本和视频等多媒体形式的创作。以下将介绍一些进阶的应用与实例,展示AI在不同艺术形式中的创作能力和潜力。
文本生成模型通过学习大量文本数据的语言模式和结构,能够生成具有语法正确性和语义连贯性的新文本。其中,循环神经网络(RNN)和长短时记忆网络(LSTM)等模型被广泛应用于文本生成任务。
# 示例代码:基于LSTM的文本生成模型
import tensorflow as tf
from tensorflow.keras.layers import LSTM, Dense
from tensorflow.keras.models import Sequential
from tensorflow.keras.optimizers import RMSprop
import numpy as np
# 准备数据(假设已有文本数据)
text = "......" # 文本数据
maxlen = 40 # 每个输入序列的长度
step = 3 # 每隔step个字符采样一个新序列
sentences = [] # 存储提取的序列
next_chars = [] # 存储目标(下一个字符)
# 提取序列和目标
for i in range(0, len(text) - maxlen, step):
sentences.append(text[i: i + maxlen])
next_chars.append(text[i + maxlen])
# 向量化(字符级别one-hot编码)
chars = sorted(list(set(text)))
char_indices = dict((char, chars.index(char)) for char in chars)
x = np.zeros((len(sentences), maxlen, len(chars)), dtype=np.bool)
y = np.zeros((len(sentences), len(chars)), dtype=np.bool)
for i, sentence in enumerate(sentences):
for t, char in enumerate(sentence):
x[i, t, char_indices[char]] = 1
y[i, char_indices[next_chars[i]]] = 1
# 构建模型
model = Sequential([
LSTM(128, input_shape=(maxlen, len(chars))),
Dense(len(chars), activation='softmax')
])
# 编译模型
model.compile(loss='categorical_crossentropy', optimizer=RMSprop(learning_rate=0.01))
# 训练模型
model.fit(x, y, batch_size=128, epochs=20)
音乐生成模型通过学习音乐片段的节奏、旋律和和声,能够创作出新颖且富有节奏感的音乐作品。深度学习模型如基于Transformer架构的音乐生成器在这方面取得了显著进展。
# 示例代码:基于Transformer的音乐生成模型
# (这里展示基本概念,具体代码需要适应音乐数据和模型结构)
import tensorflow as tf
from tensorflow.keras.layers import Transformer
from tensorflow.keras.models import Sequential
# 构建Transformer模型
model = Sequential([
Transformer(num_layers=4, d_model=128, num_heads=8,
dff=512, input_vocab_size=vocab_size,
target_vocab_size=vocab_size)
])
# 编译模型
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy')
# 训练模型(假设有音乐数据)
model.fit(train_dataset, epochs=10)
视频生成模型涉及到对动态内容的理解和创作,例如视频的帧生成和动作预测。这需要模型能够理解时间序列数据和空间信息,例如基于卷积神经网络(CNN)和长短时记忆网络(LSTM)的结合应用。
# 示例代码:基于CNN-LSTM的视频生成模型
import tensorflow as tf
from tensorflow.keras.layers import Conv2D, LSTM, TimeDistributed, Dense
from tensorflow.keras.models import Sequential
# 构建模型
model = Sequential([
TimeDistributed(Conv2D(64, (3, 3), activation='relu'), input_shape=(10, 224, 224, 3)),
TimeDistributed(Conv2D(64, (3, 3), activation='relu')),
TimeDistributed(tf.keras.layers.MaxPooling2D((2, 2))),
TimeDistributed(tf.keras.layers.Flatten()),
LSTM(256, return_sequences=True),
Dense(10, activation='softmax')
])
# 编译模型
model.compile(loss='categorical_crossentropy', optimizer='adam')
# 训练模型(假设有视频数据)
model.fit(train_data, epochs=10, batch_size=32)
尽管AI生成艺术已经取得了显著的进展,但仍面临着一些挑战和限制。
AI生成艺术模型通常需要大量的高质量数据来训练,特别是对于复杂和多样化的艺术形式。缺乏足够的多样性和质量高的数据集可能导致生成的作品缺乏创意和多样性。
训练复杂的AI艺术生成模型需要大量的计算资源和时间。尤其是对于像GAN这样的模型,需要进行长时间的训练以达到理想的生成效果,这对于普通研究者和艺术家来说可能是一个挑战。
生成的艺术作品往往需要通过主观的审美评估来确定其艺术性和创意程度。如何量化和客观评估这些作品,以及如何使AI生成的作品与人类艺术创作保持相似的情感和表现力,是一个尚未完全解决的问题。
AI生成艺术引发了一系列法律和伦理问题,例如知识产权归属、创作者权益保护以及作品责任等。如何在法律框架内解决这些问题,保护艺术创作者的权利和作品的合法性,是当前亟待解决的问题之一。
尽管面临这些挑战,AI生成艺术的未来仍然充满了潜力和机遇。未来,随着技术的进步和算法的改进,我们可以期待以下几个方面的发展:
综上所述,AI生成艺术的技术基础在于先进的深度学习算法和模型,通过不断的研究和创新,我们可以期待AI在艺术创作领域的更多突破和进展,为人类文化的发展贡献力量。随着技术的进步和社会的接受,AI生成艺术有望成为未来艺术创作的重要组成部分,为全球文化带来新的视角和表现形式。


