




4,683
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享人工智能生成内容(AIGC)技术正在迅速演进,其在视频生成领域的应用尤为引人注目。本文将深入探讨AIGC生成视频的底层技术原理,并结合代码实例进行详细解析。
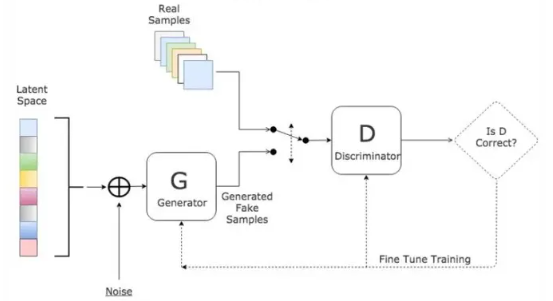
AIGC生成视频的基本原理依赖于深度学习模型,特别是生成对抗网络(GAN)的应用。GAN由生成器和判别器组成,生成器负责从随机噪声生成逼真图像或视频帧,而判别器则评估生成的内容是否真实。通过对抗训练,生成器逐步优化生成的质量,使其能够逼近真实视频的视觉特征和动态变化。
在视频生成中,GAN通常会结合卷积神经网络(CNN)来处理时间序列数据,例如视频帧。生成器和判别器被设计为能够处理时空信息,以在视频生成过程中保持连贯性和真实感。
视频生成的第一步是数据预处理,包括帧提取、大小调整和格式转换。这些步骤旨在为模型提供一致的输入数据格式,以确保生成器能够有效地处理和生成视频内容。
# 示例:视频帧提取和预处理
import cv2
import numpy as np
def preprocess_video(video_path):
cap = cv2.VideoCapture(video_path)
frames = []
while True:
ret, frame = cap.read()
if not ret:
break
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB) # 转换为RGB格式
frame = cv2.resize(frame, (256, 256)) # 调整大小为256x256
frames.append(frame)
cap.release()
return np.array(frames)
video_frames = preprocess_video('input_video.mp4')
视频生成模型通常基于类似DCGAN(深度卷积生成对抗网络)的架构,但在处理时间序列数据时需要进行适当的调整。以下是一个简化的视频生成器示例:
# 示例:简化的视频生成器模型
import tensorflow as tf
from tensorflow.keras.layers import Conv2DTranspose, BatchNormalization, Reshape
def build_video_generator():
model = tf.keras.Sequential([
# 输入噪声向量
tf.keras.layers.Input(shape=(100,)),
# 全连接层
tf.keras.layers.Dense(8 * 8 * 128, use_bias=False),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.LeakyReLU(),
# 重塑为图像张量
tf.keras.layers.Reshape((8, 8, 128)),
# 反卷积层,逐步放大特征图
Conv2DTranspose(64, (5, 5), strides=(2, 2), padding='same', use_bias=False),
BatchNormalization(),
tf.keras.layers.LeakyReLU(),
Conv2DTranspose(3, (5, 5), strides=(2, 2), padding='same', use_bias=False, activation='tanh')
])
return model
generator = build_video_generator()
训练过程中,生成器通过生成视频帧来欺骗判别器,而判别器则努力区分真实视频和生成视频之间的差异。以下是一个简化的训练循环示例:
# 示例:简化的训练循环
def train(generator, discriminator, dataset, epochs):
for epoch in range(epochs):
for batch in dataset:
# 随机噪声输入
noise = tf.random.normal([batch_size, noise_dim])
with tf.GradientTape() as gen_tape, tf.GradientTape() as disc_tape:
# 生成视频帧
generated_frames = generator(noise, training=True)
# 判别器评估真实视频和生成视频
real_output = discriminator(real_frames, training=True)
fake_output = discriminator(generated_frames, training=True)
# 计算生成器和判别器的损失
gen_loss = generator_loss(fake_output)
disc_loss = discriminator_loss(real_output, fake_output)
# 应用梯度更新
gradients_of_generator = gen_tape.gradient(gen_loss, generator.trainable_variables)
gradients_of_discriminator = disc_tape.gradient(disc_loss, discriminator.trainable_variables)
generator_optimizer.apply_gradients(zip(gradients_of_generator, generator.trainable_variables))
discriminator_optimizer.apply_gradients(zip(gradients_of_discriminator, discriminator.trainable_variables))
尽管AIGC在生成视频方面取得了显著进展,但仍面临多种挑战和优化需求。
生成视频的主要挑战之一是保持内容的一致性和真实感。即使生成器能够生成逼真的静态图像,处理视频时必须处理时间维度上的连续性。这需要模型能够有效地捕捉和生成复杂的动态场景,如物体移动、光照变化和场景转换。
生成高质量视频的关键在于训练数据的质量和多样性。模型需要大量真实的视频数据来学习和模仿不同场景下的视觉特征和动态变化。此外,合成数据和增强技术也可以用来扩展训练数据集,从而提高模型的泛化能力。
由于视频生成涉及大量的计算和内存资源,需要强大的硬件设备来支持模型训练和推理。现代GPU和TPU的使用已经成为推动AIGC技术发展的重要因素,同时也需要优化算法和模型结构以提高计算效率。
在实际应用中,视频生成的代码示例可以进一步扩展和优化,以适应不同的需求和场景。例如,可以增加对视频内容和语义信息的理解,以改进生成的视觉质量和内容一致性。
在生成器模型中集成语义信息,可以帮助模型更好地理解和生成具有逻辑连贯性的视频内容。以下是一个简化的示例:
# 示例:结合语义信息的视频生成器模型设计
def build_semantic_video_generator():
input_noise = tf.keras.layers.Input(shape=(100,))
input_semantic = tf.keras.layers.Input(shape=(num_classes,))
# 将语义信息和噪声向量合并
combined_input = tf.keras.layers.concatenate([input_noise, input_semantic])
# 通过全连接层处理合并后的输入
x = tf.keras.layers.Dense(256, activation='relu')(combined_input)
# 继续建立和训练你的生成器模型
# ...
return generator_model
利用风格迁移技术和增强技术,可以改善生成视频的视觉质量和多样性。例如,可以使用循环一致性损失(cycle-consistency loss)来确保生成的视频在时间上连贯和真实。
随着人工智能技术的不断进步和应用场景的扩展,AIGC生成视频在教育、娱乐、广告等领域具有广阔的应用前景。未来的发展方向包括更复杂的生成模型、更高效的算法实现以及更智能的内容生成和编辑工具。
总结而言,AIGC生成视频技术在理论和实践上都有着深远的影响。通过深入理解其底层技术和实际代码示例,我们可以更好地探索和推动这一领域的发展,为创造出色的视频内容生成新的可能性。
生成对抗网络(GAN)作为AIGC视频生成的核心技术之一,其在视频内容生成中的应用具有重要意义。以下是GAN在视频生成中的关键应用和技术细节:
在视频生成任务中,传统的GAN架构需要进行适当的调整和优化,以处理时间序列数据的连续性和动态变化。一种常见的做法是引入时空卷积层(spatio-temporal convolutional layers)或者利用3D卷积结构来捕捉视频帧之间的时空关系。
# 示例:基于3D卷积的生成器模型设计
def build_3d_video_generator():
model = tf.keras.Sequential([
# 输入噪声向量
tf.keras.layers.Input(shape=(100,)),
# 全连接层
tf.keras.layers.Dense(16 * 16 * 128, use_bias=False),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.LeakyReLU(),
# 重塑为3D张量
tf.keras.layers.Reshape((16, 16, 16, 128)),
# 3D卷积层,逐步放大特征图
tf.keras.layers.Conv3DTranspose(64, (5, 5, 5), strides=(2, 2, 2), padding='same', use_bias=False),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.LeakyReLU(),
tf.keras.layers.Conv3DTranspose(3, (5, 5, 5), strides=(2, 2, 2), padding='same', use_bias=False, activation='tanh')
])
return model
为了增强生成视频的多样性和可控性,可以引入条件生成对抗网络(Conditional GANs)。这种方法允许在生成器和判别器中集成额外的条件信息,如语义标签或者特定的视频场景描述,以指导生成的视频内容。
# 示例:条件生成对抗网络模型设计
def build_conditional_video_generator():
# 生成器输入:噪声向量 + 条件信息
input_noise = tf.keras.layers.Input(shape=(100,))
input_condition = tf.keras.layers.Input(shape=(condition_dim,))
# 将条件信息和噪声向量合并
combined_input = tf.keras.layers.concatenate([input_noise, input_condition])
# 通过全连接层处理合并后的输入
x = tf.keras.layers.Dense(256, activation='relu')(combined_input)
# 继续建立和训练你的生成器模型
# ...
return generator_model
在训练和生成过程中,评估生成视频的质量和时序一致性至关重要。可以使用多种指标和损失函数,如结构相似性指标(SSIM)、时序一致性损失(temporal consistency loss)等,来帮助优化模型并确保生成视频在时间上的流畅性和真实感。
# 示例:时序一致性损失函数
def temporal_consistency_loss(real_video, generated_video):
# 计算视频序列间的差异
# ...
# 返回时序一致性损失
return loss
随着AIGC视频生成技术的进一步发展和实践应用,我们可以期待更多创新和突破。未来的研究方向包括但不限于以下几个方面:
增强生成器的视觉感知能力:引入更复杂的视觉感知模块和注意力机制,以提高生成视频的视觉质量和逼真度。
结合强化学习的视频生成优化:利用强化学习技术来优化生成器模型,以实现更精准和高效的视频内容生成。
跨模态生成技术的融合:将多模态数据(如文本描述、图像和视频)融合到一个统一的生成框架中,实现更多样化和创新性的内容生成。
通过深入理解和不断探索AIGC视频生成技术的前沿,我们可以为未来的多媒体内容生成和创新应用开辟新的可能性,推动人工智能在视频创作和娱乐领域的广泛应用。
本文深入探讨了人工智能生成内容(AIGC)技术在视频生成领域的底层技术原理和实际应用。以下是关键要点的总结:
技术背景与原理:
技术细节与代码示例:
应用场景与挑战:
未来展望与研究方向:
通过深入研究和实践,AIGC视频生成技术不断拓展其在内容创作和娱乐产业的边界,为创新和艺术提供了全新的可能性和工具。随着技术的进步和应用场景的扩展,我们有望看到更加智能和多样化的视频生成系统的出现,为用户和创作者带来更丰富和个性化的视觉体验。


