





4,693
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享在人工智能的广阔领域中,从文本生成图像(Text-to-Image Generation)的技术取得了显著的进展。DALL-E和MidJourney作为这一领域的代表性模型,展示了强大的生成能力和广泛的应用前景。本文将深入解读这两种技术的原理、架构和实现,并通过代码实例展示其具体应用。
DALL-E是OpenAI开发的一种基于Transformer架构的生成模型,能够根据文本描述生成高质量的图像。DALL-E的名字源于艺术家Salvador Dalí和动画角色Wall-E,体现了其在创造性和技术方面的融合。
DALL-E的核心技术是Transformer,它是一种序列到序列的神经网络模型,最早用于自然语言处理任务。DALL-E通过对大规模文本和图像数据进行训练,学会了将文本描述映射到图像空间。
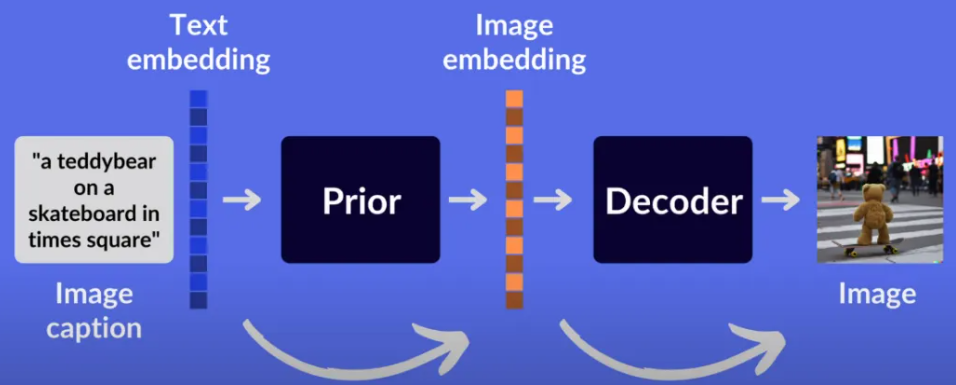
以下是一个简单的代码示例,演示如何使用OpenAI的DALL-E模型生成图像:
import openai
# 设置API密钥
openai.api_key = 'your-api-key'
# 定义文本描述
text_description = "A two-story pink house shaped like a shoe."
# 生成图像
response = openai.Image.create(
prompt=text_description,
n=1,
size="1024x1024"
)
# 获取图像URL
image_url = response['data'][0]['url']
print("Generated Image URL:", image_url)
MidJourney是一个基于生成对抗网络(GANs)的文本生成图像模型,其目标是实现更高的图像逼真度和多样性。MidJourney通过对抗训练(adversarial training),使生成器(Generator)和判别器(Discriminator)相互竞争,从而提升生成图像的质量。
MidJourney的架构由两个主要部分组成:生成器和判别器。
以下是一个简单的代码示例,演示如何使用MidJourney模型生成图像(假设我们有一个预训练的MidJourney模型):
import torch
from torchvision.utils import save_image
from midjourney import MidJourneyModel
# 加载预训练模型
model = MidJourneyModel()
model.load_state_dict(torch.load('midjourney_model.pth'))
# 定义文本描述
text_description = "A futuristic cityscape with flying cars."
# 生成图像
generated_image = model.generate_image(text_description)
# 保存生成的图像
save_image(generated_image, 'generated_image.png')
print("Generated Image saved as 'generated_image.png'")
DALL-E的实现涉及许多细节,包括数据预处理、模型训练和优化技术。以下是一些关键点:
DALL-E需要大规模的图像-文本对数据集进行训练。在数据预处理中,首先将图像进行标准化处理,并将文本描述编码为一系列嵌入向量。
DALL-E采用自回归方式生成图像,这需要大量的计算资源。训练过程中的关键是找到合适的超参数,如学习率、批量大小等,以确保模型的稳定训练。
import torch
from transformers import DALL_E
# 加载预训练的DALL-E模型
model = DALL_E.from_pretrained('dall-e')
# 定义文本描述
text_description = "A futuristic robot with neon lights."
# 文本编码
text_encoded = model.encode_text(text_description)
# 图像生成
generated_image = model.generate_image(text_encoded)
# 显示生成的图像
import matplotlib.pyplot as plt
plt.imshow(generated_image)
plt.show()
为了提高DALL-E的生成速度和质量,可以采用以下优化技术:
MidJourney的实现基于生成对抗网络(GANs),其训练过程涉及生成器和判别器的对抗训练。以下是一些关键点:
与DALL-E类似,MidJourney需要大规模的图像-文本对数据集进行训练。预处理步骤包括图像的标准化和文本描述的编码。
MidJourney采用GANs架构,需要同时训练生成器和判别器。训练过程中,生成器试图欺骗判别器,使其认为生成的图像是真实的,而判别器则不断提升自身的判别能力。
import torch
from torch import nn
from torchvision import transforms
# 定义生成器
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
# 定义生成器的网络结构
self.model = nn.Sequential(
# 网络层定义...
)
def forward(self, x):
return self.model(x)
# 定义判别器
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
# 定义判别器的网络结构
self.model = nn.Sequential(
# 网络层定义...
)
def forward(self, x):
return self.model(x)
# 加载预训练模型
generator = Generator()
generator.load_state_dict(torch.load('generator.pth'))
# 文本编码
text_description = "A serene mountain landscape with a river."
text_encoded = encode_text(text_description)
# 生成图像
generated_image = generator(text_encoded)
# 显示生成的图像
import matplotlib.pyplot as plt
plt.imshow(generated_image)
plt.show()
为了提高MidJourney的生成质量和速度,可以采用以下优化技术:
在实验和评估方面,需要使用各种指标来衡量生成模型的性能。常用的评估指标包括:
from torchvision.models import inception_v3
from torchmetrics.image.fid import FrechetInceptionDistance
from torchmetrics.image.inception import InceptionScore
# 加载Inception模型
inception_model = inception_v3(pretrained=True)
# 计算FID
fid = FrechetInceptionDistance()
fid_score = fid(real_images, generated_images)
# 计算IS
is = InceptionScore(inception_model)
is_score = is(generated_images)
print("FID Score:", fid_score)
print("Inception Score:", is_score)
文本生成图像技术已经在多个领域展现出广泛的应用前景:
随着技术的不断进步,文本生成图像的质量和速度将进一步提升。未来可能的发展方向包括:
从文本到图像的生成技术是人工智能领域的一大突破,DALL-E和MidJourney作为这一技术的代表,展示了各自的独特优势和广泛的应用前景。DALL-E基于Transformer架构,擅长捕捉文本与图像之间的复杂关系,生成高质量和富有创意的图像;MidJourney基于生成对抗网络(GANs),通过对抗训练提升图像的逼真度和多样性。
通过详细的技术解析,我们了解了DALL-E和MidJourney在数据预处理、模型训练和性能优化等方面的实现细节。此外,通过代码实例展示了如何使用这些模型生成图像,进一步增强了对其实际应用的理解。
在实验与评估方面,常用的感知质量、FID和IS等指标有助于衡量生成模型的性能,为模型优化提供了重要参考。
现实应用中,文本生成图像技术已经在创意设计、广告与营销、游戏与娱乐等领域展现出广泛的应用前景。未来,随着技术的不断进步,文本生成图像的质量和速度将进一步提升,发展方向包括更高分辨率、多模态融合和自适应生成等。
总之,DALL-E和MidJourney作为文本生成图像技术的先锋,展示了人工智能在创造性和技术领域的巨大潜力。未来,这一技术将继续发展,并在更多领域中发挥重要作用,为我们的生活和工作带来更多创新和便利。


