


4,667
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享一、2024诺贝尔物理学奖揭晓,授予人工智能领域两位科学家
北京时间10月8日,2024年诺贝尔物理学奖在瑞典皇家科学院揭晓。今年该奖项将为授予两位科学家:美国普林斯顿大学教授约翰·霍普菲尔德 (John J. Hopfield)和加拿大多伦多大学教授杰弗里·辛顿(Geoffrey E. Hinton),以表彰他们“因在利用人工神经网络实现机器学习方面的基础性发现和发明而获奖”。诺贝尔官网表明,两位诺贝尔物理学奖得主使用物理学训练人工神经网络:约翰·霍普菲尔德创建了一个联想内存,它可以存储和重建数据中的图像和其他类型的模式;杰弗里·辛顿发明了一种方法,可以自主查找数据中的属性,从而执行诸如识别图片中的特定元素等任务[1]。

图1 2024诺贝尔物理学家得主[2]
约翰·霍普菲尔德于1933年出生于美国伊利诺伊州芝加哥市,1958年获得美国康奈尔大学博士学位,现任美国普林斯顿大学教授。
1986年,约翰·霍普菲尔德与他人共同创立了加州理工学院计算与神经系统博士项目,并发现了联想记忆神经网络技术,通常称为“霍普菲尔德网络”。霍普菲尔德网络利用了物理学中描述物质特性的原理,整个网络以与物理学中自旋系统能量相当的方式描述,并通过为节点之间的连接找到值来进行训练,以使保存的图像具有低能量。当向霍普菲尔德网络输入扭曲或不完整的图像时,它会系统地遍历节点并更新它们的值,从而使网络的能量降低。因此,网络会逐步找到与输入的不完美图像最相似的保存图像。
杰弗里·辛顿于1947年出生于英国伦敦,1978年获得英国爱丁堡大学博士学位,现任加拿大多伦多大学教授。
基于霍普菲尔德网络,20世纪90年代,辛顿与他的同事特伦斯·塞诺夫斯基利用统计物理学的工具,创建了一个采用不同方法的新网络:玻尔兹曼机,它能够学习识别给定类型数据中的特征元素。辛顿使用了统计物理学的工具,通过向机器提供在运行时极有可能出现的示例来训练该机器。玻尔兹曼机可用于对图像进行分类或创建其训练过的模式类型的新示例。辛顿在此基础上进行了进一步研究,推动了当前机器学习的爆炸式发展。
二、从感知机到MLLM(多模态大语言模型),人工神经网络的进化之路
人工神经网络的发展历程可追溯到1957年。当时美国科学家弗兰克·罗森布拉特(Frank Rosenblatt)提出了感知机(Perceptron)的概念[3]。感知机模型是一种模拟人类神经元功能的二分类算法,它可以对输入数据进行线性分类,并通过调节权重来学习。然而,由于感知机只能解决线性可分问题,后来被马文·明斯基(Marvin Minsky)和西摩尔·帕普特(Seymour Papert)在1969年证明无法应对非线性问题,这一领域的研究一度陷入停滞[4]。
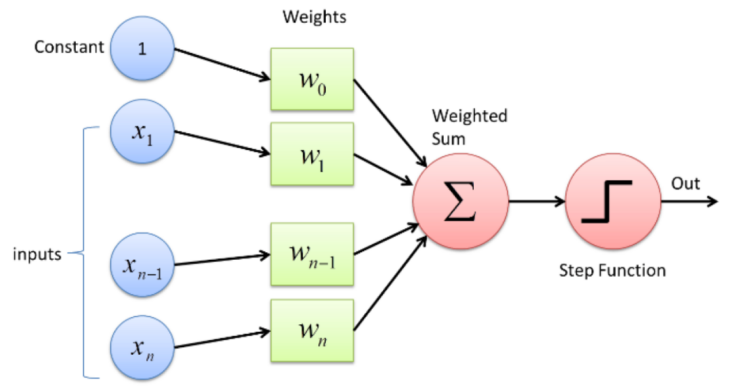
图2 感知机结构示意图(图源:机器之心)
直到20世纪80年代,反向传播算法(Backpropagation)的提出为人工神经网络注入了新的活力。由Geoffrey Hinton(2024诺贝尔物理学奖得主)、David Rumelhart和Ronald Williams等人开发的反向传播算法,解决了多层神经网络的梯度计算问题,使得训练深层网络成为可能[5]。这一突破推动了深度学习的兴起,并逐步奠定了人工神经网络在计算机视觉、自然语言处理等领域中的核心地位。
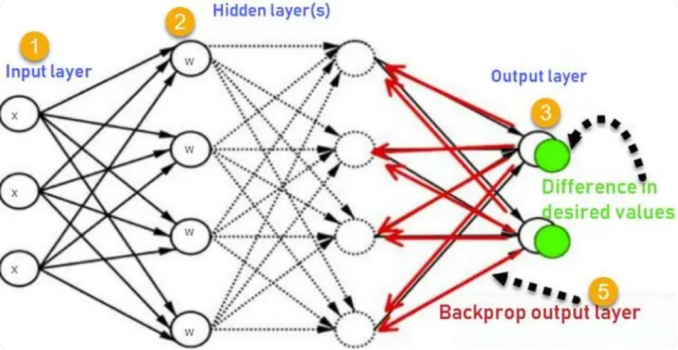
图3 反向传播示意图(图源:deephub)
在进入21世纪后,卷积神经网络(CNN)成为了计算机视觉领域的主流模型。2012年,由Hinton的学生Alex Krizhevsky开发的AlexNet在ImageNet竞赛中大放异彩,其深度卷积结构大幅度提高了图像分类的精度,并成为推动深度学习浪潮的重要里程碑[6]。自此之后,深度学习迅速扩展到语音识别、机器翻译等多个领域。随着更大规模数据和更强计算能力的支持,神经网络的模型结构不断深化,网络层数也逐渐增加,ResNet、VGG等架构相继问世。
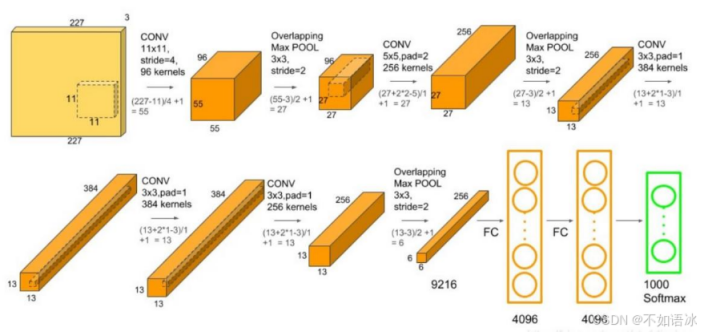
图4 AlexNet网络结构示意图(图源:CSDN@不如语冰)
近年来,多模态大语言模型(MLLM)的崛起进一步推动了人工神经网络的发展。MLLM不仅局限于处理单一模态数据(如文本),还能结合图像、音频等多种模态进行统一的理解和生成。这种突破使得机器能够更好地理解和处理复杂的、多样化的数据环境[7]。例如,OpenAI于2019年推出的GPT-2展示了出色的语言生成能力,而随后的GPT-3进一步将参数量提升至1750亿,并显著增强了模型的对话与推理能力[8]。随着GPT-4在2023年发布,MLLM的多模态能力实现了新突破,能够同时处理文本和图像输入,为智能助手和生成式AI开辟了更多应用场景[9]。
图5 GPT-4生成的对于MLLM的示意图
然而,模型规模的激增也带来了计算资源消耗和能耗问题。在这个背景下,研究人员开始探索新的硬件架构与模型优化技术。量化、蒸馏等模型压缩技术逐步兴起,帮助减轻了训练和推理的计算负担。同时,存内计算等新兴硬件架构的出现,为大规模神经网络的计算提供了全新的解决方案[10]。未来,随着多模态大语言模型的不断演进,我们有望见证人工神经网络在更复杂的任务中展现出更强的智能能力。
三、模型大小、参数量激增,存内计算赋能神经网络加速器
在第二部分中,我们简要介绍了神经网络从感知机到MLLM(多模态大语言模型)的人工神经网络进化之路。随着机器学习、大规模神经网络的不断发展,特别是MLLM在各类任务中的突破,神经网络模型的规模和参数量呈现爆炸式增长。GPT-2(2019)拥有15亿参数是OpenAI的第二代生成预训练转换模型,尽管它的参数量相对较小,但已经展示了语言生成任务的强大能力。之后,OpenAI推出GPT-3(2020),其拥有1750亿参数,成为当时最为复杂的自然语言处理模型之一。随后,谷歌推出的LaMDA (2021)专注于对话应用,拥有1730亿参数;推出的PaLM(2022)参数量达到了5400亿,成为多模态和多任务学习的基础模型之一。2023年,OpenAI推出GPT-4,实现了多模态大语言模型的进一步突破,参数量达到了1.76万亿,与GPT-3相比,GPT-4展示了更强的多模态处理能力,能够处理文本、图像等多种数据形式[11]。短短几年内,模型参数量实现了从数亿到数万亿的飞跃,这也带来了巨大的计算和硬件需求。在MLLM规模持续扩展的背景下,如何开发出高效的硬件加速器成为了当务之急。
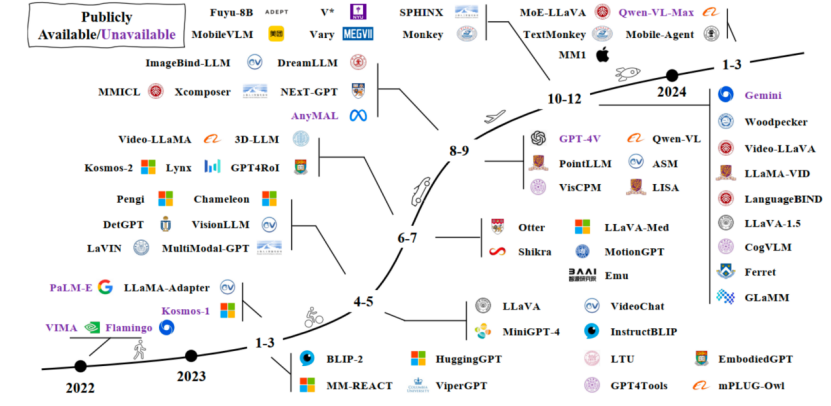
图1 MLLM发展趋势图[12]
作为一种新的计算架构,存内计算(Computing In Memory,CIM)被认为是具有潜力的革命性技术。重点是将存储与计算融合,有效克服冯·诺依曼架构瓶颈,并结合后摩尔时代先进封装、新型存储器件等技术,实现计算能效的数量级提升。在MLLM领域,存内计算技术可以在MLLM训练和推理时提供显著的计算加速,由于神经网络巡礼和推理的核心是大规模的矩阵乘法和卷积操作,存内计算可以在存储单元中直接进行矩阵乘加运算,并在进行大量并行计算时表现出色。知存科技作为国内存内计算芯片领域的领先企业,量产WTM-8存内计算芯片,可实现图像AI超分、插帧、HDR识别和检测等复杂功能;量产WTM-2101存内计算芯片,已经实现了满足端侧算力需求的语音识别等功能。在未来,存内计算芯片将为MLLM训练、推理加速带来更多可能性,助力MLLM发展迈上新台阶。


图2 知存科技WTM-8与WTM-2101实物图
参考文献:
[1]The Nobel Prize in Physics 2024 - NobelPrize.org
[2]2024诺贝尔物理学奖颁给两位“AI教父”,这是AI学术领域的重要时刻_腾讯新闻 (qq.com)
[3]Rosenblatt, F. (1958). The Perceptron: A probabilistic model for information storage and organization in the brain. Psychological Review, 65(6), 386-408.
[4]Minsky, M., & Papert, S. (1969). Perceptrons: An introduction to computational geometry. MIT Press.
[5]Rumelhart, D. E., Hinton, G. E., & Williams, R. J. (1986). Learning representations by back-propagating errors. Nature, 323(6088), 533-536.
[6]Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2012). ImageNet classification with deep convolutional neural networks. Advances in neural information processing systems, 25, 1097-1105.
[7]Bommasani, R., Hudson, D. A., Adeli, E., & others. (2021). On the Opportunities and Risks of Foundation Models. arXiv preprint arXiv:2108.07258.
[8]Brown, T. B., Mann, B., Ryder, N., & others. (2020). Language models are few-shot learners. Advances in neural information processing systems, 33, 1877-1901.
[9]OpenAI. (2023). GPT-4 Technical Report. OpenAI.
[10]Cheng, J., & Wang, L. (2023). Computing-In-Memory for Efficient Large-Scale AI Models. IEEE Transactions on Neural Networks and Learning Systems.
[11]OpenAI GPT-4 Documentation.(https://openai.com/index/gpt-4-research/)
[12]A Survey on Multimodal Large Language Models.
(https://arxiv.org/abs/2306.13549)

