



4,684
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享一、引言
1. DCIM概述
数字存内计算(Digital Computing-in-Memory, DCIM)是一种将计算操作直接集成到存储单元中的新兴计算架构。传统计算模型(冯·诺依曼架构)中的计算和存储是分离的,数据必须频繁在存储器和处理单元之间移动,在大数据和人工智能应用中会导致显著的延迟和能耗开销。数字存内计算的目标是通过在存储单元中直接执行计算任务,减少数据移动,提高系统整体的能效。在DCIM架构中,存储单元不仅用于存储数据,还可以直接执行简单的计算任务,如加法、乘法、逻辑操作等。在实际应用中,DCIM特别适用于矩阵向量乘法、神经网络加速等高并行度的任务。
2. 论文背景介绍-传统DCIM的面积开销
在传统的DCIM架构中,常见的乘加运算通常依赖于全加器树来完成累加操作。这种全加器树虽然能实现高精度的运算,但在规模化应用中,其面积和功耗开销显著增加,限制了系统的扩展性和能效表现。另外,近几年常被用作存内计算存储器的eDRAM也迫使设计者需要在存储密度和计算密度之间做出权衡。eDRAM和传统DRAM不同的是将曾经整块的存储单元嵌入到各个计算单元中,实现存内计算。在实际应用中,eDRAM在精度和吞吐量上表现突出,但也同样需要定期刷新以维持数据的准确性。
由此,本文提出了一种基于eDRAM-LUT的存内计算架构,希望借此突破传统DCIM设计中的部分问题,提高计算密度和能效。
课题组简介
刘勇攀教授课题组隶属于清华大学电子工程系电路与系统研究所,主要研究方向包括高能效计算芯片和感存算融合系统等。课题组致力于探索后摩尔时代的器件-架构-算法协同优化,针对新型器件和应用带来的挑战,开展跨层次的研究与创新。
课题组在高能效芯片设计领域取得了多项成果,包括全球首款非易失处理器和STICKER系列人工智能芯片。研究成果已在学术界发表,并获得多个国际奖项和荣誉。团队同时参与多项国家级科研项目,并积极参与国际会议和期刊的学术交流与合作。
二、论文创新点
1. eDRAM-LUT
eDRAM(嵌入式DRAM)是一种高密度、低功耗的存储技术,本质上是通过将DRAM单元嵌入到处理器或其他芯片上,减少了数据传输的延迟和功耗,实现存内计算。eDRAM技术的显著优点是具有比SRAM更高的存储密度,更适用于存算一体芯片这种需要大容量存储但同时受限于面积的环境应用。
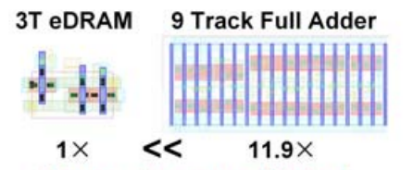
图1 3T eDRAM的面积小于经典的9-Track全加器
LUT(Look-Up Table,查找表)是一种常用于FPGA的可编程逻辑器件中的组件,用于存储预定义的计算结果,以便在需要时快速查找。LUT可以看作是一个用于实现逻辑函数的存储单元,通过预先存储函数的结果,在实际计算时只需要根据输入条件从表中读取相应的输出,无需实时计算。
该论文提出的设计在传统DCIM的基础上进行了创新,通过将eDRAM单元重新配置为查找表(LUT)用于执行乘加(MAC, Multiply-Accumulate)操作,提高计算和存储的密度。eDRAM不仅仅作为存储器使用,还在存储器内部执行计算任务,从而实现存内计算,减少数据在存储单元和计算单元之间的移动,提高了MAC操作的能效和计算密度。
2. 设计架构
论文中使用的核心架构设计如图2所示,称为CS-DCA(Computation-Storage Dual-Mode Array,计算-存储双模阵列),其包括256×160的eDRAM单元,被分为16个独立的Bank。每个Bank内含有16个eDRAM- LUT加法器(eLAD),每个eLAD的存储容量为160b。CS-DCA不仅能用作常规的数据存储内存,还能执行深度学习和大数据分析的4×8b权重MAC运算。
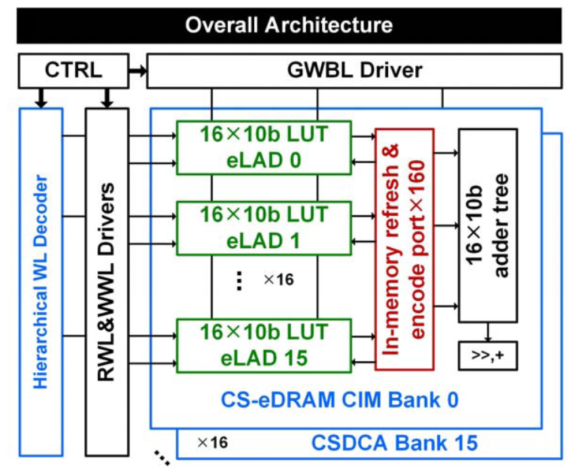
图2 CS-DCA的核心架构
CS-DCA是一种设计灵活的电子架构,能够无缝切换计算模式(CIM模式)和存储模式(Memory模式),以应对不同的处理和存储需求。双模功能主要依赖于如图3所示的分层解码器和eLAD(eDRAM LUT加法器)协同工作。

图3 双模式功能图解
在计算模式下,CS-DCA负责数据的运算处理。这一模式适用于执行多重加权累加(MAC)操作,也是神经网络和其他算法常见的计算类型。eLAD作为核心组件之一,使用内置的LUT(如图4所示)来存储和执行基于输入激活和权重的预定义加法操作。每个eLAD包含多个LUT,能够并行处理一组特定的输入激活和权重(如图5所示)。此外,分层解码器在CIM模式下作为一个16路的4:16激活解码器工作,根据四个输入通道并行地选择相应的权重组合,从而允许快速访问存储在eLAD中的查找表。
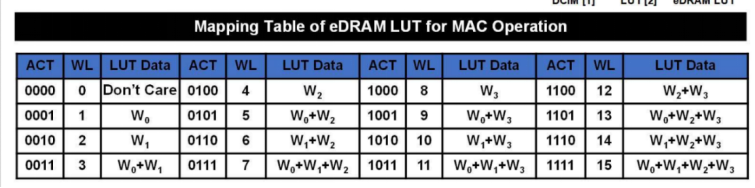
图4 eDRAM LUT的乘积-累加操作映射表
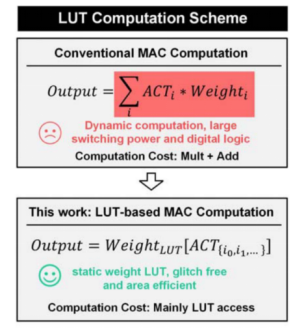
图5 LUT计算方案优势
在存储模式下,CS-DCA可作为传统存储器来使用,负责数据的保存和检索。在这种模式下,分层解码器的工作方式可看作传统的8:256解码器,用于选择单一的读/写字线(RWL/WWL)进行数据的读取或写入。
3. 电路设计与实现
基于eDRAM- LUT的加法器(eLAD)的内存计算架构通过优化数据存储和处理性能来提升整体系统效率。eLAD的电路设计如图6所示,通过将160位的存储容量划分为16个10位的子阵列,eLAD可处理基于LUT的复杂计算操作。每个子阵列的独立操作减少了数据处理中的冲突和延时,优化了读写过程。
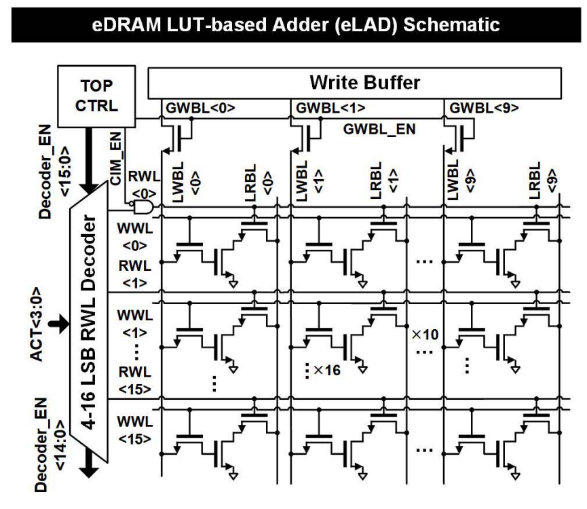
图6 eLAD的电路设计
此外,eLAD采用分层写字线(WBL)来进一步优化子阵列间的数据写入,设计权重组合的存储顺序基于相应的激活二进制代码,使得架构可以根据计算需求动态调整存储数据,从而有效利用存储空间并加速数据处理。
在硬件设计方面,eLAD采用的3T eDRAM单元(如图7)的面积只有传统6T SRAM单元的一半,提高存储密度并降低制造成本。为了进一步降低能耗,eLAD在写字线选择器上使用了增强型高阈值电压(eHVT)晶体管,以最小化漏电流。同时,eLAD在读取端口采用低阈值电压(LVT)晶体管以减少访问延迟。
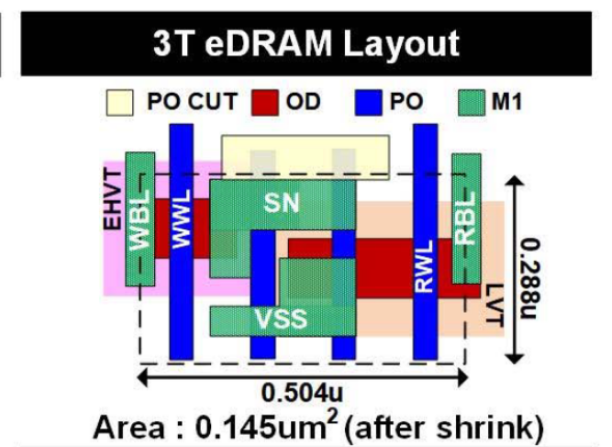
图 7 3T eDRAM单元布局
IMREP(内存刷新和编码端口)主要针对提升内存刷新与数据编码的效率。通过引入动态锁存结构以及两条特定的写回路径,IMREP优化了内存的操作效率与速度。
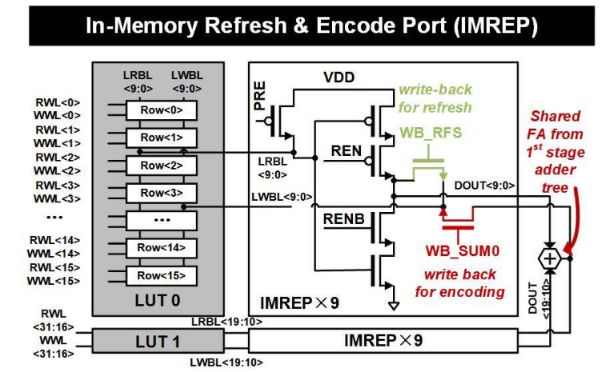
图8 IMREP架构
4. 芯片测试与对比
文章提出的存算一体芯片在28nm HKMG工艺下实现,总面积为0.017 mm2,其存储单元采用的是面积为0.145 um2的3T eDRAM。该芯片由5✖10个具有40Kb存储容量的eDRAM核组成,其能在供电电压为0.9-1.2V、频率为400-1100 MHz时正常工作且芯片的总吞吐量为10 TOPS。
在性能方面,由于 eHVT NMOS写选择器的 Vt,<1V 的芯片频率受写功能的限制,而>1V的芯片频率受计算能力的限制。另一方面,当电压为0.9V、输入稀疏度为10%时芯片能够实现最好的能效19.7 TOPS/mm2 8b。保留时间是在1V电源电压下测量的,在25°C和60°C时的刷新间隔分别为1.3和0.5 us,这受到高泄漏 eDRAM单元的限制。此外,芯片的面积和能量分布揭示了eDRAM和数字逻辑之间的均衡分配,使其有别于其他具有数字部分的DCIM设计。
如图9所示,与之前的模拟eDRAM-CIM设计相比,这些设计以精度为代价换取更高的峰值能效,而这项工作保持了完全精度并实现了高标准化能效。与基于SRAM的DCIM工作相比,基于 eDRAM LUT的设计提高了高性能工作的面积和能效,而不会损失精度。
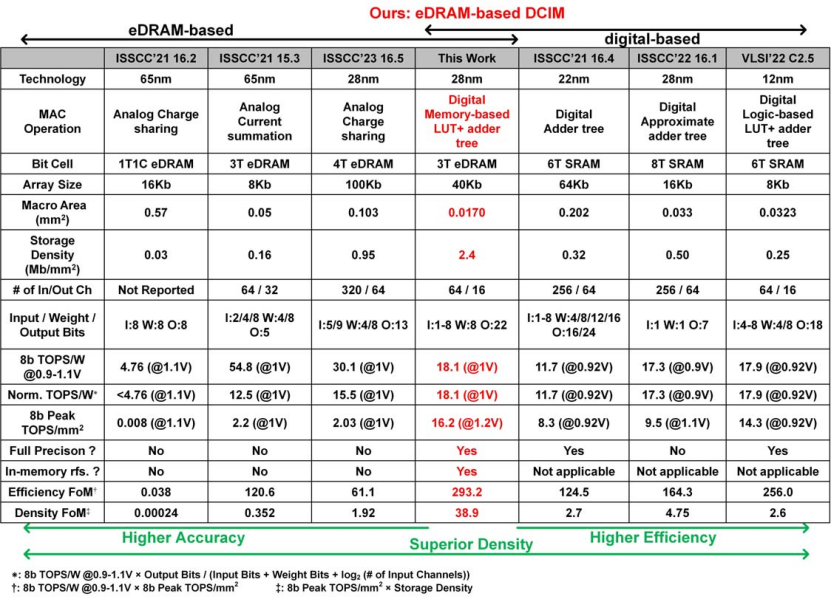
图9 横向芯片参数对比
本文提出的工作结合了eDRAM和DCIM的优势,做到了精度、存储和计算密度方面的平衡。选用eDRAM存储单元,使得面积开销仅为6T SRAM存储单元的50%,从而可以在一个核上集成更多的存储单元;利用LUT实现加法器数,降低了高精度数字逻辑的面积开销;存内eDRAM内部设计支持权重更新和编码的电路,在提供并行度的同时降低时间开销。与之前的模拟 eDRAM-CIM设计相比,这些设计以精度为代价换取更高的峰值能效,而本文工作保持了完全精度并实现了高标准化能效。与基于SRAM的DCIM工作相比,基于eDRAM LUT的设计提高了高性能工作的面积和能效而不会明显损失精度。
此外,大多数之前的工作都具有固定的CIM宏配置和大小,当宏的大小小于数据的维度时,需要进行重复的内存访问,消耗了CIM功率的40%以上。在相反的情况下,宏则会出现未充分利用的情况。而本文实现的存储和计算相结合的功能,能够根据任务的不同动态调整和优化宏架构,以在数据处理中实现更高的系统级效率和吞吐量。
三、未来展望
存内计算技术通过将计算能力直接嵌入存储单元中,提供了一种解决数据传输瓶颈和能效问题的新途径,其发展将依赖于新材料、新工艺和新架构的持续创新。忆阻器、相变存储器和磁阻存储器等新型存储器件具有非易失性、高密度和低功耗的特点,能够显著提升存内计算的性能和效率;3D堆叠技术和纳米级制造工艺将显著提高集成度和性能,减少数据传输延迟;新型计算架构如混合存内计算、可重构计算和神经形态计算,通过灵活的配置和高效的计算模式,进一步优化不同应用场景的性能和能效。在高性能计算中,存内计算可以显著提升数据密集型任务的处理效率,减少数据传输瓶颈;在人工智能领域,存内计算将加速神经网络的训练和推理过程,提高深度学习模型的性能;专用的AI芯片(如TPU、NPU)结合存内计算技术,可以实现更高效的计算和存储集成,满足复杂AI任务的需求。
未来,研究者应着重于进一步提高存内计算技术的集成度和能效,以及解决现有技术中的限制问题。优化存储器件,实现更高密度和更低功耗的存储单元;解决存内计算技术中的可靠性和耐久性问题,提高存储器件在数据存储和计算过程中的稳定性和错误率;开发适用于存内计算的编程模型和开发工具,简化开发过程,确保不同设备和系统之间的兼容性和互操作性。持续的创新和研究将推动这一领域不断前进,为解决现代计算中的瓶颈问题提供有效的解决方案。

