



4,684
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享1.1 强化学习
强化学习(Reinforcement Learning, RL)是与监督学习和无监督学习并列的一种机器学习方法,其用于描述和解决智能体(agent)在与环境的交互过程中通过学习策略以达成回报最大化或实现特定目标的问题。
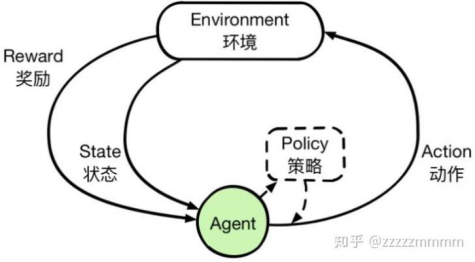
图1 强化学习的工作流程
具体说来,强化学习由动作、智能体、状态、奖励、回报和策略五大元素组成,如图1所示[1]。以“Flappy bird”游戏为例[1],如果小鸟躲过了各种水管而飞得越远则能获得更高的积分奖励,如图2所示。在这个游戏中,小鸟充当智能体,动作是让小鸟用力向上飞一下或者保持不动,状态包括小鸟的位置、高度、速度等,奖励是获得的积分,回报是获得的奖励的总和,策略是小鸟选择避开水管而飞得更远的依据。从上面的描述中可以看出,与监督学习不同的是,强化学习中不存在“标签”而只能从自身的经验中学习;与无监督学习不同的是,强化学习并非寻找隐藏的数据集结构而其目标是最大化奖励[2]。

图2 Flappy bird游戏
从强化学习发展至今,已在自动驾驶、工业、贸易金融、自然语言处理、医疗保健、游戏、机器人等领域中有着广泛的应用。例如,自动驾驶汽车AWS DeepRacer使用摄像头查看赛道,并使用强化模型来控制油门和方向盘; Alvin C. Grissom II等人提出了基于强化学习的同步机器翻译方法[3];AlphaStar 在《星际争霸2》中以 10:1 击败了人类顶级职业玩家[4];谷歌将深度学习与强化学习相结合以训练机械臂的长期推理能力[5]。
RL对大模型复杂推理能力提升有关键作用,然而RL 复杂的计算流程以及现有系统局限性,也给训练和部署带来了挑战[6]。其一,所需的样本数量太大,可能导致计算成本较高且难以部署在边缘设备上。其二,探索阶段代价太大,难以对环境进行准确建模从而对训练效果造成影响。其三,稳定性较差,导致学习效果不佳或无法收敛到最优策略。其四,超参数的影响非常大,即使是细微的超参数区别也会影响最终的效果。
1.2 豆包大模型
近日,字节跳动豆包大模型团队与香港大学联合提出HybridFlow,一个灵活且高效的大模型 RL 训练框架,兼容多种训练和推理框架,支持灵活的模型部署和多种 RL 算法实现。
HybridFlow 采用混合编程模型,将单控制器的灵活性与多控制器的高效性相结合,解耦了控制流和计算流。基于 Ray 的分布式编程,动态计算图,异构调度能力,通过封装单模型的分布式计算、统一模型间的数据切分,以及支持异步 RL 控制流,HybridFlow 能够高效地实现和执行各种 RL 算法,复用计算模块和支持不同的模型部署方式,大大提升了系统的灵活性和开发效率。实验结果表明,HybridFlow 在各种模型规模和 RL 算法下,训练吞吐量相比其他框架提升了 1.5 倍至 20 倍。
目前,该论文已被 EuroSys 2025 接收,代码仓库也对外公开。
论文链接:HybridFlow: A Flexible and Efficient RLHF Framework - 研究成果 - 豆包大模型团队
代码链接:GitHub - volcengine/verl: veRL: Volcano Engine Reinforcement Learning for LLM

图3 豆包模型大家族
如图3所示,豆包大模型团队成立于2023年致力于开发业界最先进的AI大模型技术,成为世界一流的研究团队,为科技和社会发展作出贡献,其下设Foundation、Vision、Speech、LLM四个分支[7]。Foundation 团队负责大模型的工程架构、模型结构设计、代码生成等方面工作,其开发的豆包 MarsCode工具支持智能识别当前编码任务相关的上下文信息,同时将代码理解、生成、优化、推荐、补全、审查等多维能力融为一体,帮助开发者提升代码开发质量和效率。Vision团队致力于视觉理解和生成的多模态基础模型研发,其开发的豆包·文生图模型现已应用于抖音、剪映、豆包、星绘等产品。Speech团队的使命是利用多模态语音技术丰富交互和创作方式,其开发的Seed-Music 工具提供了可控音乐生成、谱转曲、词曲编辑、零样本人声克隆四大核心功能。 LLM 研究大模型研发的基础问题,包括但不限于模型的自学习、记忆和长文本生成、可解释性等方向。
HybridFlow框架的核心在于将强化学习和人类反馈强化学习(RLHF)有机结合,以实现更高效、更精准的模型训练。
RLHF是一种让人工智能(尤其是大型语言模型)通过人类反馈进行改进的训练方法,其主要由三个步骤组成:首先,预训练一个语言模型(LM);其次,聚合问答数据并训练一个奖励模型 (Reward Model,RM) ;最后,用强化学习(RL)方式微调LM。以PPO(Proximal Policy Optimization)模型为例,假设你在教一只智能机器人(AI助手)回答问题:首先(生成阶段),AI助手通过自回归生成来生成一组提示的响应;其次(准备阶段),评论家计算生成响应的价值,参考策略计算参考的对数概率,奖励模型计算奖励值;最后(学习/训练阶段),演员和评论家模型利用Adam优化器更新,通过之前生成的数据和损失函数来训练模型。
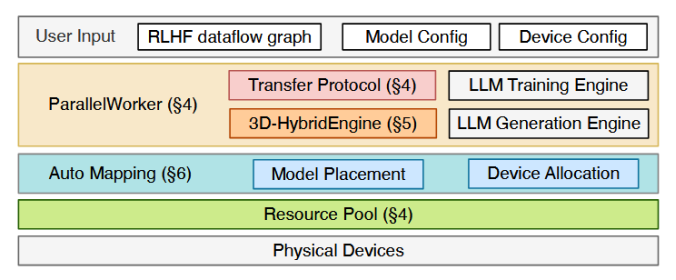
图4 HybridFlow框架
如图4所示,HybridFlow框架主要由Hybrid Programming Model、3D-HybridEngine和Auto-Mapping algorithm组成:Hybrid Programming Model以实现RLHF数据流的灵活表达和数据流中模型的高效计算;3D-HybridEngine专为高效训练和生成演员模型而设计;Auto-Mapping algorithm以最大化RLHF的吞吐量。在该框架中,RLHF的工作流程如下:首先,用户提供输入信息,包括模型配置、设备配置等;其次,初始化RLHF数据流中的模型并分配虚拟资源池;然后,多控制器程序实现Parallel-Worker类,构建各模型的并行组,并调用3D-HybridEngine来执行演员模型的训练和生成;最后,单一控制程序协调传输协议以实现数据传输与重分配.
在HybridFlow框架中,RL和RLHF的结合主要体现在以下几个方面:第一,数据增强:通过人类反馈,可以为模型提供更加丰富和多样化的训练数据,从而增强模型的泛化能力和鲁棒性。第二,策略优化:人类反馈可以作为额外的奖励信号,引导模型在关键决策点上做出更优的选择。第三。错误纠正:在训练过程中,人类可以及时发现并纠正模型的错误行为,避免模型陷入局部最优解[8]。
HybridFlow通过3DParallelWorker基类实现了模型的分布式计算封装。该基类负责初始化模型权重,并建立模型的3D并行组,支持张量并行(TP)和数据并行(DP)。这种架构允许每个模型类,如ActorWorker或CriticWorker,(如图5)独立执行其分布式计算任务,包括前向和反向传播,自回归生成,以及优化器的更新。这种封装方式简化了复杂计算的实现,使得模型能够有效地在多GPU环境中并行处理。
利用ResourcePool类,HybridFlow为模型部署提供了极大的灵活性。这个类将GPU设备集虚拟化,允许开发者根据需要将模型映射到指定的设备上。这种设计使得相同ResourcePool实例的模型可以共享同一组GPU,而不同实例则可以部署在不同的GPU集上,从而优化资源配置和使用效率。
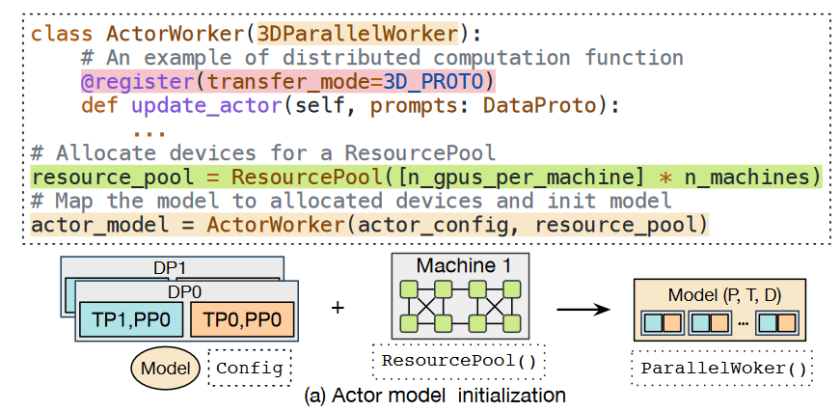
图5 Actor模型初始化
HybridFlow通过定义统一的数据传输协议(如3D_PROTO),管理模型间的数据流。每个协议包括一个集合函数和一个分发函数,这些函数负责在模型间高效地聚合和分配数据。例如,Actor模型的输出通过集合函数被送至单一控制器,然后通过分发函数按需分配给Critic模型。这种统一的数据切分机制确保了数据在不同并行组件间的正确同步和最小化延迟。
HybridFlow支持模型在分布式环境中的异步执行。(如图6)当模型部署在不同设备上时,它们的执行可以在输入数据准备就绪后立即触发,而无需等待其他模型。这种异步执行策略提高了整体的计算效率,使系统能够更快响应并处理复杂的RL任务。
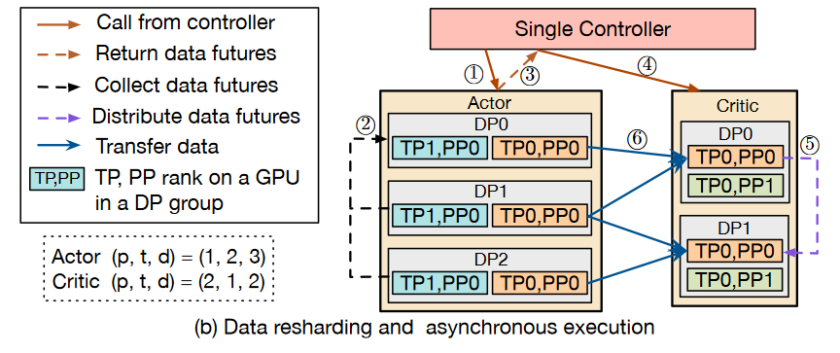
图6 在两个模型之间使用 3D_PROTO 中的收集和分发函数进行异步数据重分配
HybridFlow的API设计使得开发者可以用少量代码灵活实现多种强化学习算法。通过修改或添加简单的代码行,可以调整或实现如PPO、ReMax及Safe-RLHF等不同的RL算法。这种模块化的API设计大大降低了算法实现的复杂度,加快了开发和测试新算法的速度。

图7 用户可以通过简单地添加或删除几行代码来适应不同的 RLHF 算法
在在线强化学习(Online RL)中,Actor模型在训练和生成(Rollout)阶段需要频繁切换并适应不同的并行处理策略,造成了在传统计算框架下高额的通信和内存开销。3D-HybridEngine的设计旨在优化在线强化学习(RLHF)中actor模型的训练和生成过程,通过高效地管理模型权重重整和数据流转,显著提升系统的整体性能和资源利用率。3D-HybridEngine在一次迭代中的具体流程如图8所示。
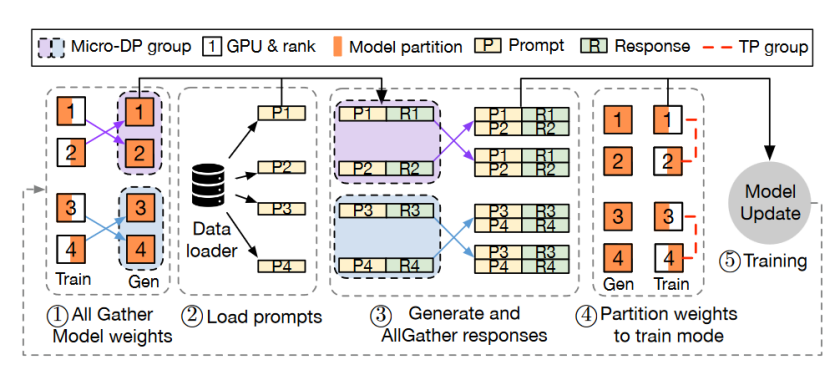
图8 3D-HybridEngine 一次迭代的流程
在RLHF迭代开始时,3D-HybridEngine首先从上一迭代中收集更新后的actor模型参数。这一步通过所有GPU进行一个“all-gather”操作,确保每个计算单元都同步更新到最新状态。如图9(a)和9(b),显示了在训练与生成不同阶段使用的并行组。
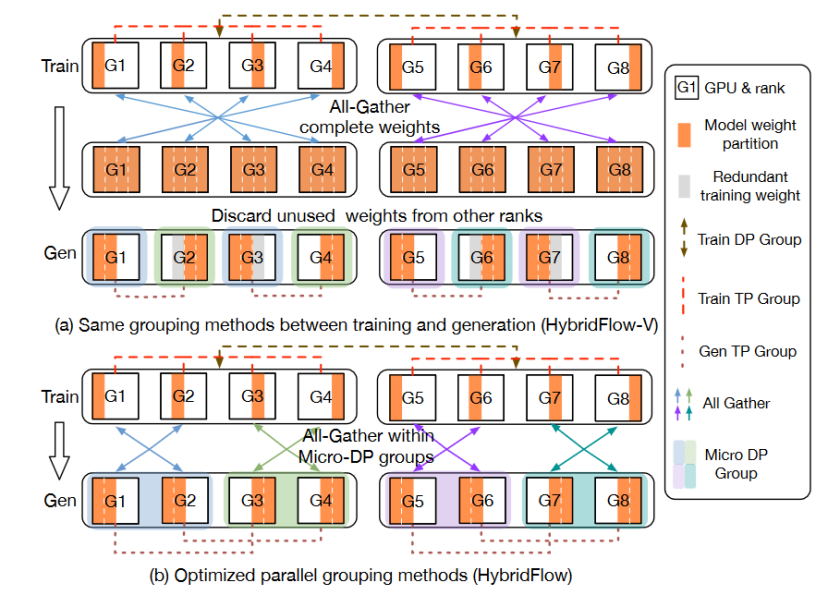
图9 模型权重重分片。 使用两台机器,每台机器配备4个GPU,用于Actor训练和生成。
加载到每个模型副本的提示数据后,系统利用当前的模型参数生成响应。此阶段每个微数据并行(micro DP)组独立处理其数据子集。生成阶段完成后,3D-HybridEngine在每个微DP组内执行“all-gather”操作,聚合生成的响应数据。
根据生成阶段的需要,模型参数按新的并行组配置重新划分,以准备进入训练阶段。通过巧妙地重新定义生成阶段的并行分组,可以使每个 GPU 在生成阶段复用训练阶段已有的模型参数分片,避免在 GPU 内存中保存额外的模型参数,消除内存冗余。完成模型权重、提示和响应数据的正确分配后,计算actor模型的损失并更新模型权重,以根据RLHF算法进行优化。
3D-HybridEngine通过优化通信流程显著降低了模型训练和生成阶段之间的通信开销。通过在各个微数据并行组内局部执行“all-gather”操作,而非在所有GPU上进行广泛的数据聚合,该设计不仅减少了全局的通信需求,还提高了各GPU的独立处理能力,从而有效提升了整体计算效率并减少了系统资源的消耗。
团队在 16 台 A100 GPU 集群上,对 HybridFlow 和主流 RLHF 框架进行对比实验。HybridFlow 的性能优势体现在其对不同强化学习算法如PPO、ReMax、和Safe-RLHF的处理上,其通过改进的数据处理和并行计算策略在各种模型尺度上显示出卓越的性能。
如图10和图11显示,HybridFlow在使用PPO和ReMax算法时,在128个GPU上处理13B参数模型的吞吐量是其他系统(如DeepSpeed-Chat和OpenRLHF)的数倍。对于PPO算法,HybridFlow在处理13B参数模型时,比DeepSpeed-Chat快最高达18.96倍(图10b)。在使用ReMax算法时,HybridFlow在相同的GPU配置下处理13B参数模型,速度提升高达3.66倍(图11b)。
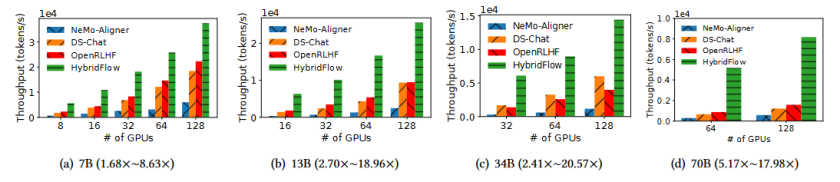
图10 PPO 吞吐量。 括号内的数字表示与基线相比的 HybridFlow 加速比。
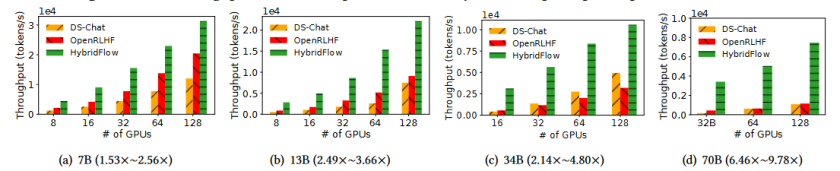
图11 ReMax 吞吐量。 括号内的数字表示与基线相比的 HybridFlow 加速比。
在图12中,HybridFlow显著减少了训练和生成阶段之间的过渡时间。例如,在使用70B模型时,HybridFlow的过渡时间比DeepSpeed-Chat减少了71.2%,HybridFlow采用的并行策略减少了必要的全局数据同步操作,从而大大减少了整体迭代时间。

图12 Actor训练与生成之间的过渡时间。
如图13所示,在16个GPU上运行7B模型时,通过适当调整生成阶段的TP大小,HybridFlow的生成时间比使用最大TP大小(即训练时的配置)减少了60.3%。HybridFlow通过调整并行策略,有效利用了GPU资源,减少了执行时间。

图13 在16个GPU上的Actor模型不同生成并行大小的时间分解

