


113
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享| 这个作业属于哪个课程 | https://bbs.csdn.net/forums/2401_CS_SE_FZU |
|---|---|
| 这个作业要求在哪里 | https://bbs.csdn.net/topics/619470310 |
| 这个作业的目标 | 个人技术总结——CRNN模型详解与实战 |
| 其他参考文献 | 无 |
CRNN结合了CNN和RNN,用于处理图像中的序列数据。CNN提取空间特征,RNN捕捉序列信息,常用于场景文本识别等。学习CRNN有助于解决图像中信息提取和文字识别,技术难点在于如何高效地结合CNN与RNN,并解决标签与输出序列长度不一致的问题。
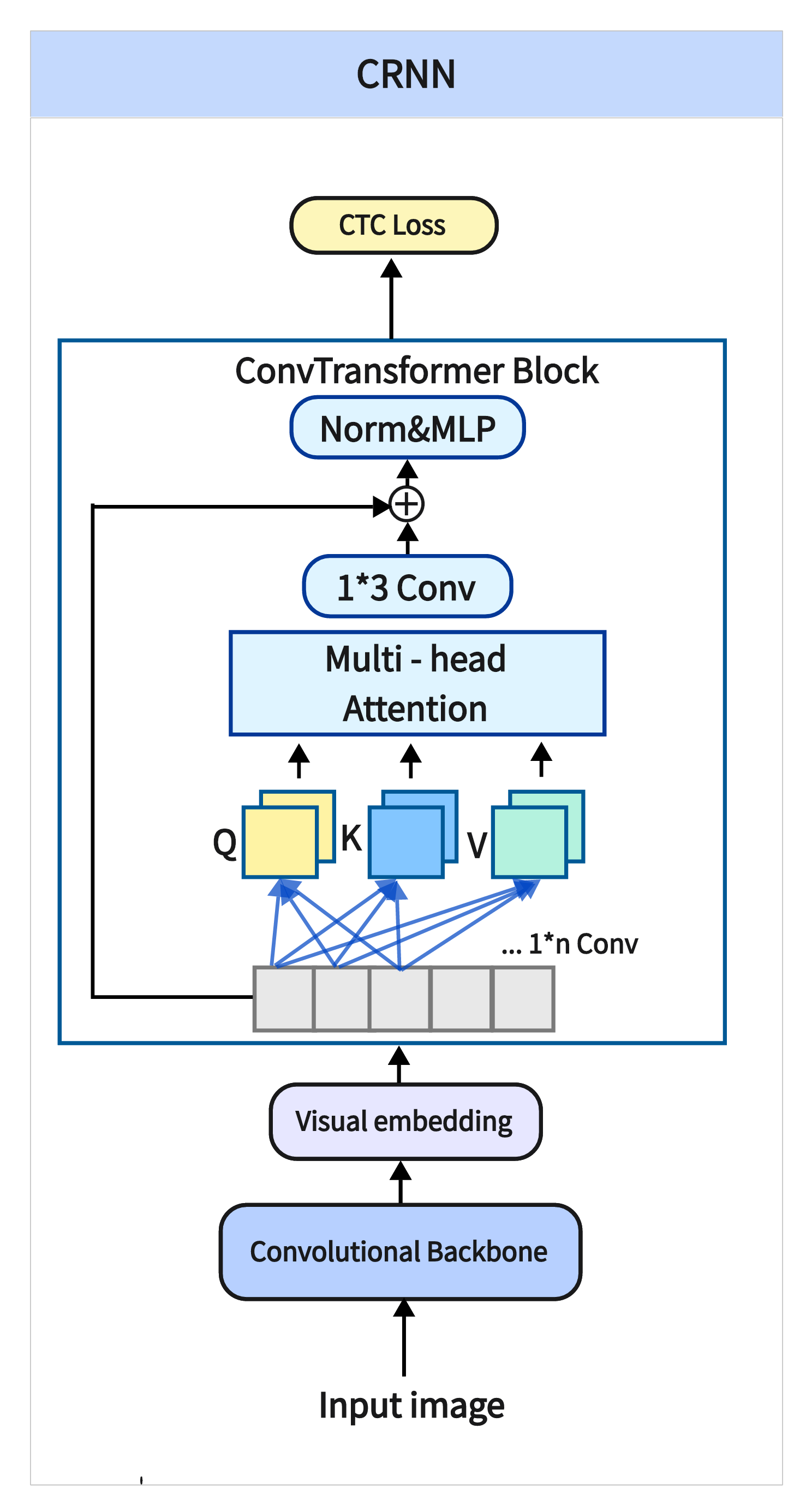
大部分的CV项目或AI模型都需要安装多个技术框架来进行训练或预测,推荐使用Anaconda进行环境配置,最好减少pip安装(无法解决版本冲突),以下是该项目所需的主要依赖库及安装步骤:
安装Anaconda、创建并激活虚拟环境
python -m venv crnn_env
source crnn_env/bin/activate # 在Linux/macOS上
# 或者在Windows上:
crnn_env\Scripts\activate
使用conda命令安装所需依赖库
torch和torchvision的安装请参照pytorch的安装命令,因为这个和电脑配置以及cuda版本有关,版本不对就会出现很多有的没的问题
lmdb:用于高效地读取和存储数据。LMDB 是一种内存映射数据库,主要用于存储大规模数据集。
numpy:用于数组和矩阵操作,是许多科学计算的基础库。
Pillow:图像处理库,常用于图像的加载、保存和预处理。
six:用于编写兼容 Python 2 和 Python 3 的代码的工具库。
torch:PyTorch 主要库,用于构建和训练神经网络。
torchvision:PyTorch 官方库,提供了图像处理、数据集等工具,支持常见的 CV 操作和模型。
训练一个深度学习模型通常包括以下步骤:准备数据集、定义模型结构、选择损失函数和优化器,最后进行训练。
在训练之前,首先需要准备和预处理数据。这包括以下步骤:
数据集加载:从硬盘加载图像数据集,并分为训练集和验证集。
数据增强:为了提高模型的泛化能力,可以使用数据增强技术(如旋转、缩放、裁剪等)。
数据预处理:如归一化、调整大小等,使得数据符合模型的输入要求。
使用PyTorch的DataLoader加载数据:
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
train_transforms = transforms.Compose([
transforms.Resize((32, 100)),
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,)),
])
train_dataset = datasets.ImageFolder(root='train_data_path', transform=train_transforms)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
根据任务的需求,定义网络结构。在CRNN的场景下,使用卷积层(CNN)提取特征,然后使用LSTM或GRU等循环神经网络层进行序列建模。
以下是模型代码:
import torch.nn as nn
class BidirectionalLSTM(nn.Module):
def __init__(self, nIn, nHidden, nOut):
super(BidirectionalLSTM, self).__init__()
self.rnn = nn.LSTM(nIn, nHidden, bidirectional=True)
self.embedding = nn.Linear(nHidden * 2, nOut)
def forward(self, input):
recurrent, _ = self.rnn(input)
T, b, h = recurrent.size()
t_rec = recurrent.view(T * b, h)
output = self.embedding(t_rec) # [T * b, nOut]
output = output.view(T, b, -1)
return output
class CRNN(nn.Module):
def __init__(self, imgH, nc, nclass, nh, n_rnn=2, leakyRelu=False):
super(CRNN, self).__init__()
assert imgH % 16 == 0, 'imgH has to be a multiple of 16'
# 定义CNN部分
ks = [3, 3, 3, 3, 3, 3, 2]
ps = [1, 1, 1, 1, 1, 1, 0]
ss = [1, 1, 1, 1, 1, 1, 1]
nm = [64, 128, 256, 256, 512, 512, 512]
cnn = nn.Sequential()
def convRelu(i, batchNormalization=False):
nIn = nc if i == 0 else nm[i - 1]
nOut = nm[i]
cnn.add_module('conv{0}'.format(i), nn.Conv2d(nIn, nOut, ks[i], ss[i], ps[i]))
if batchNormalization:
cnn.add_module('batchnorm{0}'.format(i), nn.BatchNorm2d(nOut))
cnn.add_module('relu{0}'.format(i), nn.LeakyReLU(0.2, inplace=True) if leakyRelu else nn.ReLU(True))
convRelu(0)
cnn.add_module('pooling0', nn.MaxPool2d(2, 2)) # 64x16x64
convRelu(1)
cnn.add_module('pooling1', nn.MaxPool2d(2, 2)) # 128x8x32
convRelu(2, True)
convRelu(3)
cnn.add_module('pooling2', nn.MaxPool2d((2, 2), (2, 1), (0, 1))) # 256x4x16
convRelu(4, True)
convRelu(5)
cnn.add_module('pooling3', nn.MaxPool2d((2, 2), (2, 1), (0, 1))) # 512x2x16
convRelu(6, True) # 512x1x16
self.cnn = cnn
self.rnn = nn.Sequential(
BidirectionalLSTM(512, nh, nh),
BidirectionalLSTM(nh, nh, nclass)
)
def forward(self, input):
conv = self.cnn(input)
b, c, h, w = conv.size()
assert h == 1, "the height of conv must be 1"
conv = conv.squeeze(2)
conv = conv.permute(2, 0, 1) # [w, b, c]
output = self.rnn(conv)
return output
对于序列标注任务,通常使用 CTC(Connectionist Temporal Classification)损失函数。优化器可以选择 Adam 或 RMSprop。
criterion = nn.CTCLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
训练模型时,我们要根据每个批次的数据计算损失,进行反向传播,并更新模型参数。在训练同时,保存固定批次的模型权重。
训练代码如下:
for epoch in range(num_epochs):
model.train() # 训练模式
for i, (images, labels) in enumerate(train_loader):
images = images.cuda()
labels = labels.cuda()
# 前向传播
outputs = model(images)
# 计算损失
loss = criterion(outputs, labels)
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
if i % 100 == 0:
print(f"Epoch [{epoch}/{num_epochs}], Step [{i}/{len(train_loader)}], Loss: {loss.item()}")
torch.save(model.state_dict(), f'crnn_model.pth_{i}')
在进行预测时,首先需要对输入图像进行处理。这包括调整图像的尺寸、归一化等,使其符合模型的输入要求。
以下为图像预处理代码:
import cv2
import numpy as np
def preprocess_image(image_path, imgH=32):
# 读取图像并转换为灰度图
image = cv2.imread(image_path, cv2.IMREAD_GRAYSCALE)
# 将图像高度调整为imgH,宽度根据图像比例自适应调整
image = cv2.resize(image, (int(image.shape[1] * imgH / image.shape[0]), imgH))
# 归一化并增加通道维度
image = image / 255.0 # 归一化
image = np.expand_dims(image, axis=-1) # 增加通道维度
return image
加载已保存的训练模型权重,并设置模型为评估模式。
model = CRNN(32, 1, len(alphabet)+1, 256)
model.load_state_dict(torch.load('crnn_model.pth'))
model.eval() # 设置为评估模式
if torch.cuda.is_available():
model = model.cuda()
将预处理后的图像输入到模型中,并解码预测结果。这里使用CTC解码器将模型的输出转换为文本。
def predict(image, model, converter):
with torch.no_grad():
preds = model(image) # 模型预测
preds_size = torch.IntTensor([preds.size(0)] * image.size(0)) # 每个批次的时间步
_, preds = preds.max(2) # 获取最大概率的字符索引
preds = preds.squeeze(2).transpose(1, 0).contiguous().view(-1) # 调整形状
sim_preds = converter.decode(preds.data, preds_size.data, raw=False) # 解码
return sim_preds
predicted_text = predict(image, model, converter)
print("Predicted Text:", predicted_text)
问题描述:在使用 CRNN 进行中文字符识别时,可能会遇到模型对中文字符的识别准确度较低的问题,尤其是在文本较复杂、字符之间存在相似性或形态较为特殊时,模型的表现可能无法达到预期效果。
解决方案:针对这个问题,优化模型的首要策略是使用更适合中文文本识别的数据集进行训练。考虑到该项目主要应用于识别录取通知书中的印刷体文字(即主要为规范字体、印刷体),但原数据集可能存在不适配的情况,换用中文语料库(新闻 + 文言文)组合而成的**chinese_ocr数据集**针对这个问题,优化模型的首要策略是使用更适合中文文本识别的数据集进行训练。
问题描述:在更换数据集后,由于新数据集内存较大,共约364万张图片,约10G左右,在使用GPU进行加速训练时,由于CUDA内存溢出导致训练无法进行。
训练方案:降低训练时批次大小,降低 batch_size,减少每次训练所需的内存,虽然这样可能会导致训练速度稍慢,但可以避免内存溢出。
问题描述:模型训练过程中,遇到训练收敛缓慢和精度无法提升问题。
解决方案:
学习率调整:使用学习率衰减策略(每经过一定的 epoch 降低学习率)来避免学习率过大导致训练不稳定,或者学习率过小导致收敛过慢。
优化器选择:尝试不同的优化器(Adam、RMSprop、Adadelta),并调整其参数(学习率、权重衰减),以找到最适合的优化方案。
CRNN能够高效地提取图像特征,并结合RNN的序列建模能力,处理文字识别中的时序依赖问题,适合用于手写识别、场景文本识别等任务。
CRNN作为一种强大的模型,在处理中文字符识别时展现了其巨大潜力。然而,随着文本的复杂性增加,模型仍然面临一些挑战。未来可以通过引入更深的网络结构、更高效的优化算法以及更加丰富的数据集来进一步提升模型的表现。同时,结合更多领域的前沿技术(如Transformer、Attention机制等),可以使得CRNN在各种实际应用场景下达到更高的识别准确率,推动OCR技术向更广泛的行业应用发展。
『OCR_Recognition』CRNN
作者:libo-coder
链接:https://blog.csdn.net/libo1004/article/details/111595054
CTC理论和实战
作者:李理
链接:https://fancyerii.github.io/books/ctc/
LSTM 与 GRU 的比较:选择最佳的时间序列网络
作者:陈光剑
链接:https://juejin.cn/post/7315846670641659942


