


113
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享| 这个作业属于哪个课程 | 2401_CS_SE_FZU |
|---|---|
| 这个作业要求在哪里 | 软件工程实践总结&个人技术博客 |
| 这个作业的目标 | 软件工程实践以及个人掌握的技术的总结 |
| 软件工程实践总结 | 《构建之法》 |
一、前言
二、技术详述
1、请求和响应
2、解析网页
3、数据存储
三、项目实战
总结
在本学期我本来是准备学习算法,但在项目的进行过程中需要爬虫的技术,我个人也对于爬虫产生了兴趣,所以更改学习计划,学习爬虫。
在爬虫技术中,请求和响应是最基本的概念。我们使用HTTP请求来获取网页内容,然后解析响应内容以提取所需数据。
发送HTTP请求:
Python中,requests库是最常用的HTTP客户端库,它允许我们发送HTTP/1.1请求。
import requests
# 发送GET请求
response = requests.get('http://example.com')
# 发送POST请求
data = {'key': 'value'}
response = requests.post('http://example.com', data=data)
# 检查响应状态码
if response.status_code == 200:
print('请求成功')
else:
print('请求失败')
处理请求头和Cookie:
有时候,我们需要模拟浏览器行为,这可能涉及设置请求头(User-Agent)和发送Cookie。
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'}
cookies = {'session_id': '123456789'}
response = requests.get('http://example.com', headers=headers, cookies=cookies)
获取到网页的HTML内容后,我们需要解析这些内容以提取有用的数据。
使用BeautifulSoup解析HTML:
BeautifulSoup是一个可以从HTML或XML文件中提取数据的Python库。
from bs4 import BeautifulSoup
# 假设html_content是包含HTML内容的字符串
soup = BeautifulSoup(html_content, 'html.parser')
# 提取所有<a>标签
links = soup.find_all('a')
# 提取具有特定class属性的<div>标签
divs = soup.find_all('div', class_='some-class')
# 提取id为“title”的<h1>标签的文本
title = soup.find('h1', id='title').text
使用lxml解析HTML:
lxml是一个高效的XML和HTML解析库,它提供了XPath和CSS选择器。
from lxml import etree
html = '<html><body><p>Hello World</p></body></html>'
parser = etree.HTMLParser()
tree = etree.fromstring(html, parser)
# 使用XPath提取<p>标签
p_tags = tree.xpath('//p')
# 使用CSS选择器提取<p>标签
p_tags_css = tree.cssselect('p')
提取的数据需要被存储起来,以便后续分析和使用。
存储到文件:
我们可以将数据存储到文本文件、CSV文件等。
# 存储到文本文件
with open('output.txt', 'w') as file:
file.write('Hello World')
# 存储到CSV文件
import csv
data = [['Name', 'Age'], ['Alice', 24], ['Bob', 19]]
with open('output.csv', 'w', newline='', encoding='utf-8') as csvfile:
writer = csv.writer(csvfile)
writer.writerows(data)
存储到数据库:
对于更复杂的应用,我们可能需要将数据存储到数据库中,如SQLite、MySQL、MongoDB等。
import sqlite3
# 连接到SQLite数据库
# 如果文件不存在,会自动在当前目录创建一个数据库文件
conn = sqlite3.connect('example.db')
# 创建一个Cursor:
cursor = conn.cursor()
# 执行一条SQL语句,创建user表:
cursor.execute('CREATE TABLE IF NOT EXISTS user (id VARCHAR(20) PRIMARY KEY, name VARCHAR(20))')
# 插入一行记录:
cursor.execute('INSERT INTO user (id, name) VALUES (\'1\', \'Michael\')')
# 提交事务:
conn.commit()
# 关闭Cursor:
cursor.close()
# 关闭Connection:
conn.close()
爬取酒店数据的爬虫代码片段
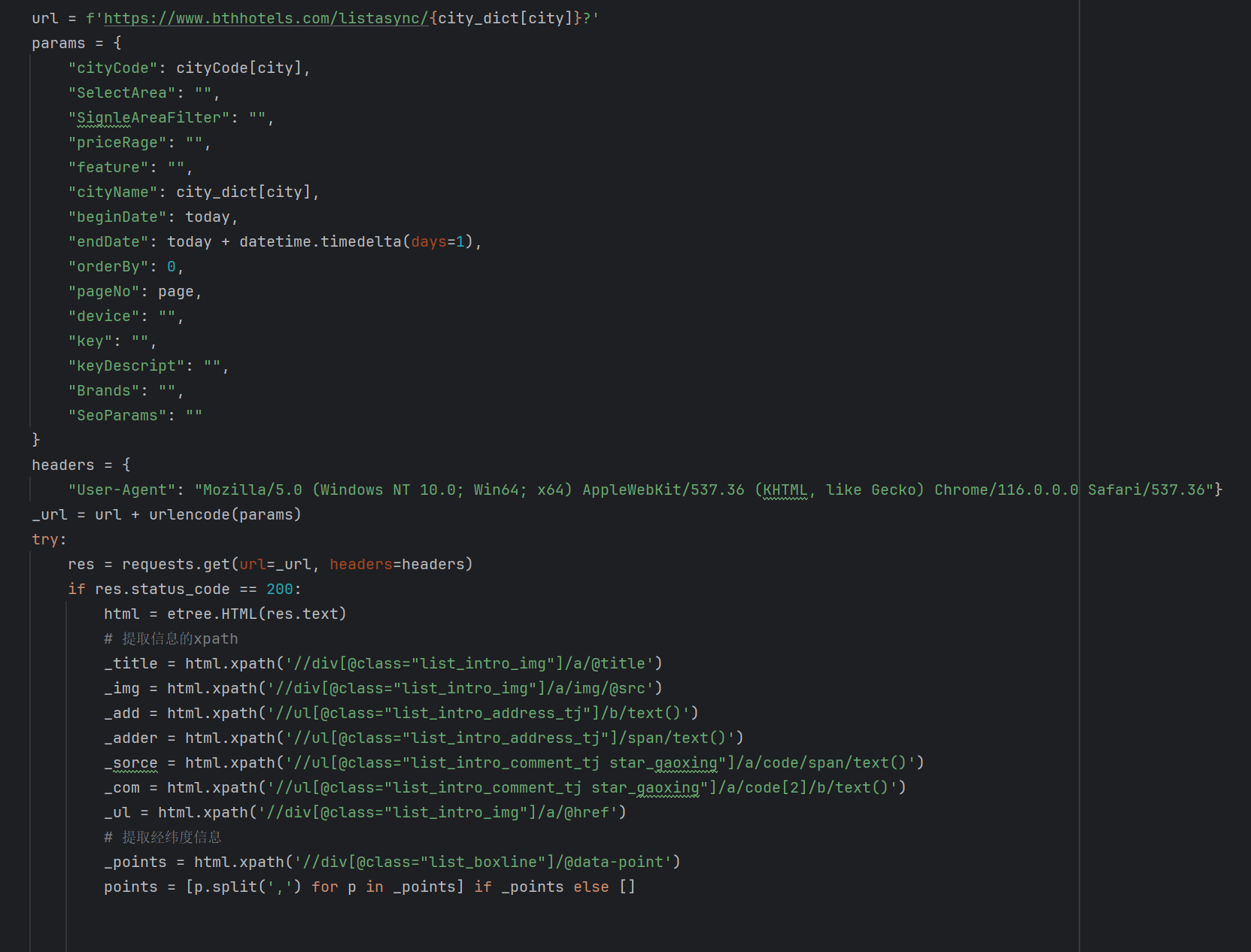
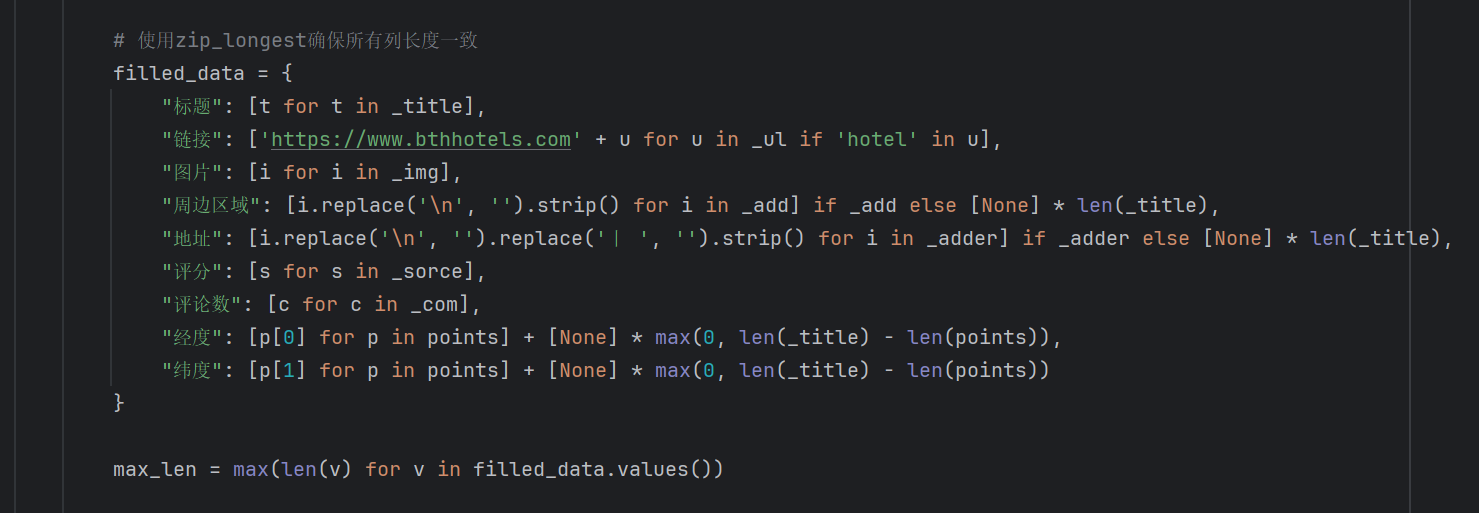
爬虫技术是一种自动化从互联网收集数据的工具,它通过发送网络请求、解析网页内容并提取信息。这项技术需要掌握HTTP请求、HTML解析、反反爬虫策略,并在法律和伦理框架内使用。正确运用爬虫技术可以在遵守规则的前提下,为数据分析、内容聚合等提供有力支持。
核心机制:爬虫技术基于发送HTTP请求来获取网页数据,并使用HTML解析工具来提取所需信息,最后将这些信息存储以供后续使用。
技术要点:
熟练掌握HTTP协议和请求库,如Python的requests库。
精通HTML和CSS选择器,以及至少一种解析库,如BeautifulSoup或lxml。
能够处理JavaScript渲染的页面,可能需要使用Selenium或Pyppeteer。
了解并实施反反爬虫策略,如使用代理、设置合理的请求间隔。
掌握分布式爬虫技术,以提高大规模数据抓取的效率。
爬虫案例1000讲
作者:写python的鑫哥
爬虫实战进阶
作者:写python的鑫哥

