



4,215
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享随着人工智能技术的飞速发展,内容创作领域正迎来一场前所未有的革命。AGI(通用人工智能)工具的崛起,特别是 AI 视频生成技术的突破,正在彻底改变我们创作和消费内容的方式。从 OpenAI 震撼业界的 Sora,到国内迅速崛起的 Vidu、可灵、即梦等,这些强大的工具正赋予创作者们无限的想象空间和前所未有的创作效率。本文将盘点国内外最具代表性的 AI 视频生成工具,并深入探讨其背后的技术原理、应用场景以及开源模型的下载链接,为广大内容创作者提供一份详尽的 AGI 工具合集,共同见证这场内容创作新革命的到来。
一、国外AGI工具
(1)Sora(https://openai.com/sora/)
2024年2月16日,OpenAI发布Sora预览版模型。12月10日,该功能正式上线对ChatGPT Plus和Pro用户开放。据OpenAI介绍,Sora可为用户生成1080P下最长20s的各种比例视频,并且允许用户基于已有视频进行修改、融合或基于文本提示词生成全新的内容。
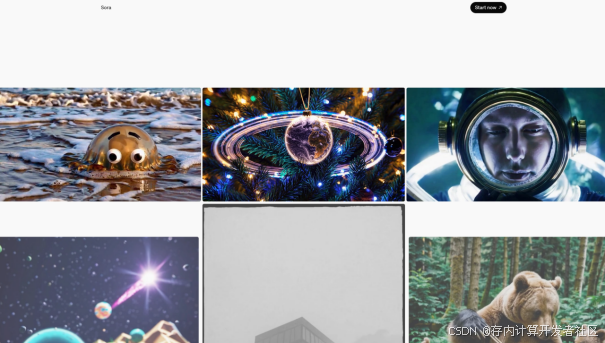
图1 Sora界面
Sora支持以下视频功能:Remix,替换、删除、创造视频中的元素;Re-cut,扩展视频中部分帧的内容;Storyboard,根据提示词生成多场景的视频内容;Loop,修剪并创建无缝重复视频;Blend,将两个视频丝滑地串联在一起;Style presets,根据提示词基于原视频修改风格。
价格方面,20美元会员(ChatGPT Plus 单月价格)支持最多50个快速视频生成,支持分辨率最高720P、长度5s;200美元会员(ChatGPT Pro 单月价格)支持最多500次快速视频生成,无限次relaxed视频生成,分辨率最高1080P、长度20s,可并发生成5个,允许无水印下载。
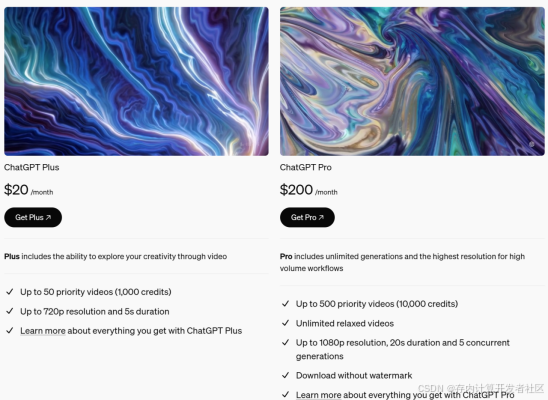
图2 ChatGPT会员充值界面
(2)runway Gen3-Alpha(https://runwayml.com/product)
2024年7月17日,runway发布了runway Gen3-Alpha,虽有又更新了其turbo版本,允许用户编写提示词生成最高10s、分辨率1280x768的视频。与Gen2版本项目,此版本主要提升点在保真度、一致性和运动稳定性上均有提升。可以根据提示词生成特写、为原有视频添加特效效果,为照片中的指定物体实现运动效果。
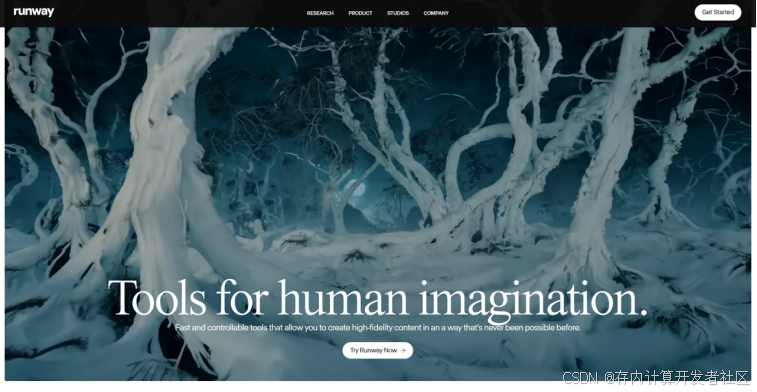
图3 Gen3-Alpha网页端
不过,在8月30日,runway删除了其在Hugging face上的开源信息,并宣布不再对其进行维护。
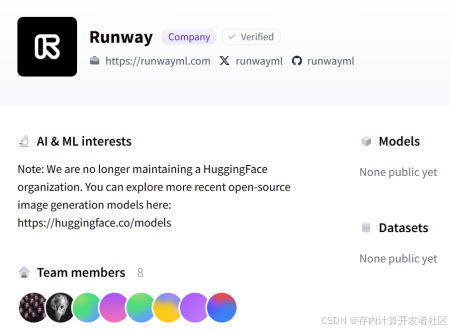
图4 runway不再维护开源的Gen3-Alpha
(3)Stable Video(https://github.com/Stability-AI/generative-models)
Stability Al在2023年11月21日推出了开源模型Stable Vedio diffusion,可以在576x1024分辨率下根据给定图像生成最多25帧的画面。2024年3月18日和7月24日,Stability AI分别提出了模型的3D版本和4D版本,4D版本能够根据给定输入的视频以576x576的分辨率生成40帧(5个视频帧x8个机位)的视频图像,给定5个上下文帧(输入视频)和8个参考视图(从输入视频的第一帧合成,使用3D多视图扩散模型)。该模型聚焦于生成内容的稳定性和运动表征能力。
图5 开源模型Stable Vedio diffusion
(4)Pika(Pika AI: Pika 2.0 Now Available!)
2024年12月13日,美国AI初创公司Pika发布了其2.0版本。新推出的Scen ingredients功能允许用户上传/自定义角色、物体和场景,再辅以文本进行描述,可将准确的人物/物体融合进描绘的场景,为用户提供高定制化的体验
图6 Pika2.0界面
二、国内AGI工具
(1)Vidu(https://www.vidu.studio/zh)
2024年4月27日,在2024中关村论坛—未来人工智能先锋论坛上,中国首个长时长、高一致性、高动态性视频大模型Vidu正式发布。Vidu是由生数科技和清华大学自主烟花,采用原创的Diffusion与Transformer融合的架构U-ViT,支持一键生成长达16秒、分辨率高达1080p的高清视频内容。Vidu不仅能够模拟真实物理世界,还拥有丰富想象力,具备多镜头生成、时空一致性高等特点。
Vidu是自Sora发布之后全球率先取得重大突破的视频大模型,性能全面对标国际顶尖水平,并在加速迭代提升中。2024年7月30日,Vidu宣布全球上线,Vidu宣布全球上线,支持参考生视频、图生视频、文生视频等功能,具有低于30秒的生成时间、强大的语义理解能力和高动态性表现,支持用户自由、高效地创作。
图7 Vidu网页界面
(2)Jimeng(https://jimeng.jianying.com)
2024年4月,字节跳动旗下的剪映推出了一款AI创作平台Dreamina,主要功能包括AI图片创作和视频生成。用户可以通过输入文案,快速生成创意图像或视频。2024年5月9日,Dreamina正式更名为即梦(Jimeng),并推出网页版,上线之初只有图片生成、智能画布和视频生成三大功能。2024年8月6日,该应用移动版正式上架至苹果应用商店,拥有文生图和文/图生视频等功能。目前,Jimeng支持3s/6s/9s/12s的视频长度,支持16:9、21:9、4:3、1:1等视频比例,也具有24fps、30fps、60fps的补帧以及二倍超分的能力。
图8 即梦网页界面
(3)Kling(https://klingai.kuaishou.com)
2024年6月6日,快手发布自研视频生成大模型“可灵(Kling)”,,并同步开放邀测体验。7月6日,快手可Kling AI网页端正式上线,限时免费,集成文生图、文生视频、图生视频、视频续写等相关能力。得益于高效的训练基础设施、极致的推理优化和可扩展的基础架构,Kling能够生成长达2分钟的视频,且帧率达到30fps。基于自研3D VAE,Kling能够生成1080p分辨率的电影级视频,支持自由的输出视频宽高比。同时,Kling具有强大的概念组合能力,能够模拟真实世界的物理特性,能够更好地建模复杂时空运动。
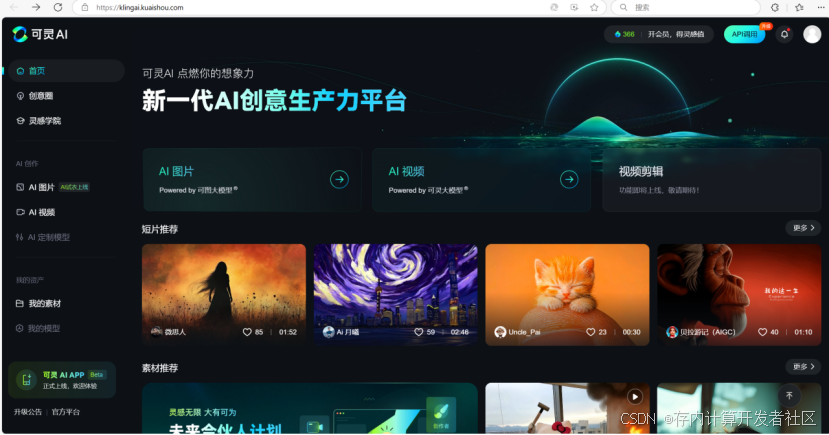
图9 可灵网页界面
2024年12月12日,在首届“2024AIGC视觉应用论坛”上,快手副总裁、大模型团队负责人张迪透露,Kling AI将于近期推出全新的1.6版本模型,新模型将带来更好、更稳定的视频质量,在文本遵循、动态表现、风格一致性等方面将有大幅提升。
(4)MiniMax-Video-01(https://www.minimaxi.com/en/news/video-01)
2024年8月31日,国内在人工智能领域表现突出的公司MiniMax发布了首款视频生成大模型video-01,同时展示了一条由该大模型生成的视频《魔法硬币》,整个视频共计1分55秒,展示了雨林沙漠、天空大海、魔法科幻等场景,体现了不亚于Sora、Runway等的视频效果。

图10 《魔法硬币》视频截图
video-01支持生成720p分辨率和25fps的高清视频,拥有高压缩率、出色的文本响应能力和多样化的样式,具有电影般的摄像机移动效果。它可以根据文本描述快速创建具有视觉冲击力的内容。目前,video-01支持生成长达6秒的视频,下一个主要版本将支持长达10秒的视频,提供两种模式:文本到视频和图像到视频。用户可以选择仅根据文本描述生成视频,也可以上传参考图像和文本描述来创建视频。目前MiniMax的API开放平台已经提供了视频模型video-01的API文档。
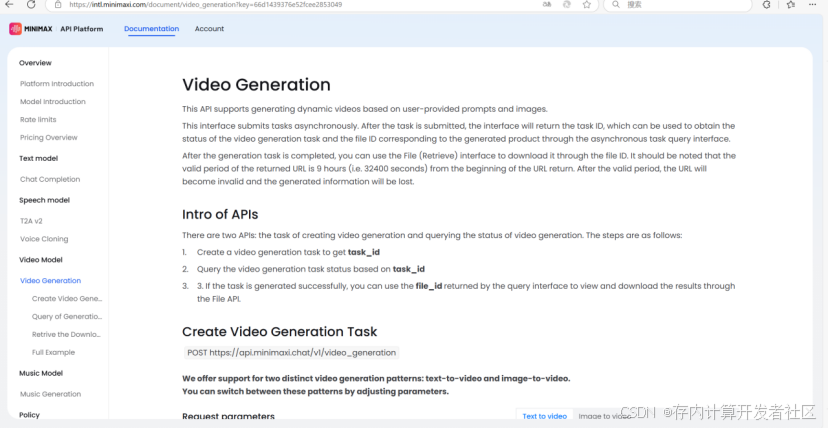
图10 video-01的API文档
三、开源AGI工具
除了商业化的 AGI 工具外,开源社区也涌现出了一批优秀的 AI 视频生成模型。这些模型为研究者和开发者提供了更多探索和创新的空间,也为用户提供了更多定制化和低成本的选择。
(1)ModelScope Video
ModelScope Video 是阿里巴巴达摩院开源的文本到视频生成模型,它基于扩散模型架构,能够根据用户输入的文本描述生成相应的视频内容。ModelScope Video 采用了多阶段的扩散模型,包括文本编码器、视频扩散模型和视频解码器,并利用大规模的文本-视频数据集进行训练。该模型对中文文本有较好的支持,并支持生成多种风格的视频,如卡通、写实等。用户可以在 ModelScope 平台上直接输入文本体验视频生成,也可以通过 API 将模型集成到自己的应用中。ModelScope 平台提供了在线体验和 API 调用两种方式,以及详细的代码和文档,用户可以方便地使用和部署该模型。ModelScope Video 生成的视频质量和文本相关性都比较好,且生成速度较快,是一个优秀的中文文本到视频生成模型。
下载链接:
代码和文档:
https://github.com/modelscope/modelscope
该模型基于 Apache License 2.0 许可证发布, 允许商业用途。

图11 ModelScope Video可生成各类视频
(2)AnimateDiff
AnimateDiff 是一个流行的开源框架,它的主要作用是将已有的、个性化的文本到图像(Text-to-Image, T2I)模型转变为动画生成器。不同于直接从头训练一个完整的文本到视频模型,AnimateDiff 提供了一种更为灵活和模块化的方法。它通过在预训练的 T2I 模型(例如 Stable Diffusion)中插入一个运动建模模块来实现动画生成。这个运动建模模块通常是一个时间注意力网络,它被设计用来捕捉视频帧之间的时间依赖关系和运动模式。在训练过程中,T2I 模型保持冻结状态,只有新加入的运动模块会通过视频片段进行微调。这种方法的好处在于,它可以利用现有的、已经非常强大的 T2I 模型,而无需从零开始训练,大大节省了时间和计算资源。

图12 AnimateDiff生成动画流畅稳定
AnimateDiff 的另一个优势在于其灵活性和可扩展性。用户可以根据自己的需求选择不同的基础 T2I 模型,并结合不同的运动建模模块来生成各种风格的动画。此外,AnimateDiff 还支持多种控制运动的方式,例如结合 ControlNet 等工具,用户可以更精细地控制生成动画中的运动效果。由于其开源的特性,AnimateDiff 拥有一个庞大且活跃的社区,不断有新的模型和工具被开发出来,用户可以方便地获取和使用这些资源。AnimateDiff 的性能在很大程度上取决于所使用的基础 T2I 模型和运动建模模块,但总的来说,它可以生成流畅且多样化的动画,并且在生成质量和计算资源消耗之间取得了较好的平衡。
下载链接:
https://github.com/guoyww/AnimateDiff
该模型基于 MIT 许可证发布, 允许商业用途。
(3)Lumiere
Lumiere是由谷歌研究院推出的一种基于时空扩散模型的文本到视频生成模型。它通过一种新颖的时空 U-Net 架构,能够在单个过程中生成整个视频的时间长度,而不是像传统方法那样先生成关键帧再进行时间超分辨率。这种方法使得 Lumiere 能够直接生成低分辨率的完整视频,并通过空间和时间超分辨率模块将其提升到高分辨率。Lumiere 的核心创新在于其时空 U-Net 架构,它通过在空间和时间维度上进行下采样和上采样,实现了高效的计算和高质量的视频生成。此外,Lumiere 还引入了多重扩散(Multidiffusion)技术,使得用户能够利用单个生成模型进行多种不同的视频编辑任务,如视频修复和风格化。Lumiere 在文本到视频生成、图像到视频生成、风格化生成等任务上都表现出了领先的性能。
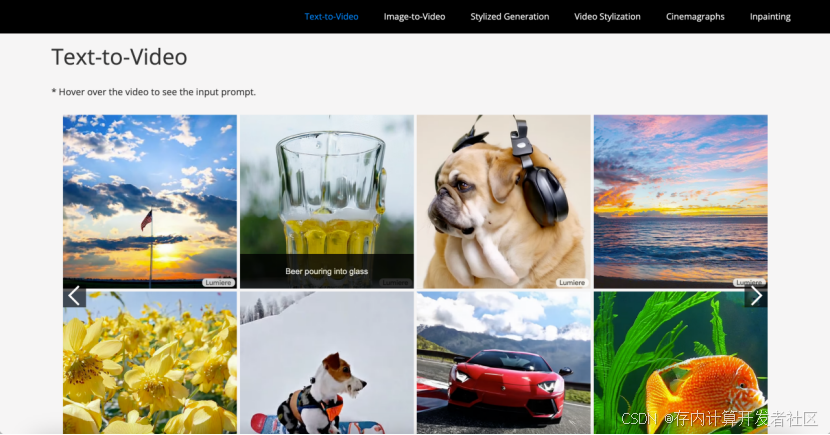
图13 Lumiere文本生成视频展示界面
目前,Lumiere 的论文已经发布,但代码尚未完全开源。用户可以关注谷歌研究院的官方网站和 GitHub 仓库以获取最新的更新信息。
论文地址:https://arxiv.org/abs/2401.12945
项目主页:Lumiere
虽然代码尚未开源,但其创新的时空 U-Net 架构和多重扩散技术为视频生成领域提供了新的思路和方向,值得关注和期待。
四、归纳总结
|
名称 |
类别 |
开发机构/公司 |
功能简介 |
链接 |
|
Sora |
国外 |
OpenAI |
可生成最长 60 秒的 1080P 视频,支持多种比例,基于文本提示词生成内容,可修改、融合已有视频。支持 Remix、Re-cut、Storyboard、Loop、Blend、Style presets 等功能。 | |
|
Runway Gen3-Alpha |
国外 |
Runway |
可生成最长 10 秒、分辨率 1280x768 的视频,支持文本提示词生成特写、添加特效、使照片中物体运动。 | |
|
Pika 2.0 |
国外 |
Pika |
支持上传/自定义角色、物体和场景,并结合文本描述生成视频,提供高定制化体验。 | |
|
Vidu |
国内 |
生数科技 & 清华大学 |
可生成最长 16 秒、分辨率 1080p 的高清视频,支持文生视频、图生视频、参考视频生成,模拟真实物理世界,具备多镜头生成、时空一致性高等特点。 | |
|
即梦 (Jimeng) |
国内 |
字节跳动 |
支持文生图、文/图生视频,可生成 3s/6s/9s/12s 的视频,支持多种视频比例和帧率,具备补帧和超分能力。 | |
|
可灵 (Kling) |
国内 |
快手 |
可生成最长 2 分钟、30fps、1080p 的视频,支持文生图、文生视频、图生视频、视频续写,支持自由宽高比,具有强大的概念组合能力,能模拟真实世界的物理特性。 | |
|
MiniMax-Video-01 |
国内 |
MiniMax |
可生成最长 6 秒(下一版本支持 10 秒)、720p、25fps 的视频,支持文本到视频和图像到视频两种模式,具有高压缩率、出色的文本响应能力和多样化的样式。 | |
|
Lumiere |
开源 |
谷歌研究院 |
基于时空扩散模型的文本到视频生成模型,采用时空 U-Net 架构,支持多种视频编辑任务,如视频修复和风格化。 |
论文:https://arxiv.org/abs/2401.12945 主页:Lumiere |
|
ModelScope Video |
开源 |
阿里巴巴达摩院 |
基于扩散模型的文本到视频生成模型,支持中文文本,可生成多种风格的视频,提供在线体验和 API 调用。 |
模型: 代码: |
|
AnimateDiff |
开源 |
社区 |
将个性化的文本到图像模型转化为动画生成器的框架,通过插入运动建模模块实现动画生成,支持多种控制运动的方式。 | |
|
Stable Video Diffusion |
开源 |
Stability AI |
基于潜在扩散模型,根据输入的静态图像生成动态视频,支持多分辨率输出,可控制生成的视频帧率。有3D和4D扩展。 |


