




4,229
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享AI Agent,作为自主决策和智能行为的核心技术,正逐渐成为人工智能领域中的重要研究方向。通过集成深度学习、强化学习、传感器数据融合等技术,AI Agent不仅能够执行任务,还能在复杂和动态的环境中进行自主学习和决策。本文将深入探讨AI Agent的核心技术,包括自主学习、决策算法、感知系统以及多模态数据的融合。同时,文章也将展望AI Agent在未来的技术发展趋势,如全感知决策、增强学习、情感理解等领域的潜力。通过实例代码分析,本文力求为读者提供一个全面、深刻的理解。
关键词
AI Agent;自主学习;决策算法;感知系统;深度学习;强化学习;多模态数据;全感知决策
随着人工智能技术的不断发展,AI Agent作为一种能够自主决策并执行任务的智能体,已经成为了人工智能研究中的重要分支。从最初的规则驱动型系统,到如今基于深度学习和强化学习的智能代理,AI Agent的能力和应用范围已经得到了极大的拓展。特别是在自动驾驶、机器人、金融、医疗等领域,AI Agent的应用已经渗透到社会的方方面面。本文将详细分析AI Agent的核心技术,并讨论其未来发展趋势,特别是在全感知决策方面的潜力。
AI Agent的基本目标是使其能够在复杂环境中自主感知、决策并执行任务。在这一过程中,AI Agent需要处理多种挑战,包括环境的不确定性、信息的时效性和完整性、任务的多样性等。本文将从以下几个方面进行深入讨论:自主学习和决策算法、感知技术、多模态数据的融合、以及全感知决策等。
传统建模仿真理论中,系统模型同样以各种实体为建模基本元素,如面向对象(object-oriented)建模即将系统抽象为对象(object)及其属性(property)、对 象方法(method)和对象间消息(message)构成的集合。 与传统建模方法比较,基于agent的系统模型在基于实体建模基础上,对系统 中的智能实体和非智能实体加以区分,提供对系统模型更精确的描述。具体地, 多agent 建模将系统非智能组成建模为对象,保留面向对象建模良好的封装性和普 适性。同时,将系统中智能组成以多agent理论研究中成熟的agent结构模式、agent 交互模式、agent关系模式等进行建模,从而模型能更准确、更丰富反映系统的知 识与信息,也大大减少了纯粹对象建模方法的冗余描述和在描述元素智能性上的 不足。 多agent 研究的两个不同领域即复杂适应系统建模和 MAS 建模在使用 agent 概念对系统进行抽象上具有不同表述,但其基本思想是一致的。
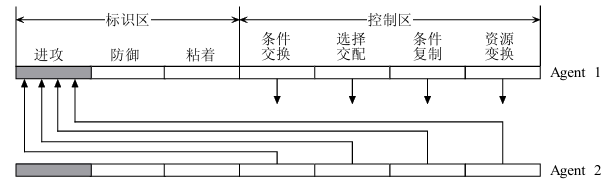
MAS理论同样认为“多agent系统是由多个相互交互的,成为agent的计算单元组成的系统”,而“agent是处在某个环境中的计算机系统,该系统有能力在这个环境中自主行动以实现其设计目标”。给出MAS软件工程研究中使用 的一个基本世界模型(world model)
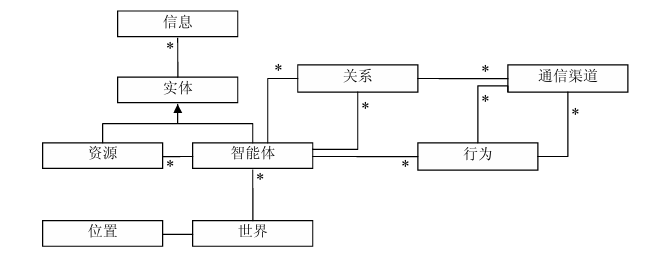
自主学习是AI Agent能够适应新环境并提升决策能力的关键技术。与传统的编程规则不同,自主学习让AI Agent通过与环境的交互来优化其行为,从而实现智能决策。强化学习(Reinforcement Learning, RL)是自主学习的重要技术之一,它通过奖惩机制,帮助AI Agent在动态环境中不断调整策略。
强化学习的核心是“状态-动作-奖励”模型(State-Action-Reward)。在这个模型中,AI Agent通过与环境的交互来感知当前状态,并根据策略选择动作,最终通过奖励信号来调整策略。这种方法能够有效地解决决策问题,尤其是在没有明确标签和环境规则的情况下。
import gym
import numpy as np
# 创建环境
env = gym.make('CartPole-v1')
# Q-learning 算法
Q = np.zeros([env.observation_space.shape[0], env.action_space.n])
alpha = 0.1 # 学习率
gamma = 0.9 # 折扣因子
epsilon = 0.1 # 探索概率
for episode in range(1000):
state = env.reset()
done = False
while not done:
# epsilon-贪婪策略选择动作
if np.random.uniform(0, 1) < epsilon:
action = env.action_space.sample() # 随机选择
else:
action = np.argmax(Q[state, :]) # 选择最大Q值的动作
# 执行动作并获得反馈
next_state, reward, done, _ = env.step(action)
# 更新Q值
Q[state, action] = Q[state, action] + alpha * (reward + gamma * np.max(Q[next_state, :]) - Q[state, action])
state = next_state
该代码示例展示了如何在OpenAI Gym中的CartPole环境中使用强化学习来训练一个AI Agent,通过不断的状态-动作更新来优化决策策略。
AI Agent的感知能力是其决策和行动的基础。感知系统通过从环境中采集数据并进行处理,使AI Agent能够理解周围的世界。常见的传感器数据包括摄像头、雷达、激光雷达(LiDAR)、传感器和音频数据等。
传感器融合技术是将来自不同传感器的数据进行整合,从而为AI Agent提供更为全面和准确的环境感知。例如,自动驾驶汽车结合了摄像头、雷达和LiDAR数据,通过融合这些信息,可以实现对车辆周围环境的全面理解,提升决策的精确度和安全性。
import numpy as np
# 假设我们有两种传感器数据,分别来自相机和雷达
camera_data = np.array([0.5, 0.2, 0.9]) # 假设是从摄像头获得的深度图像信息
radar_data = np.array([0.6, 0.3, 1.0]) # 假设是从雷达获得的距离信息
# 对数据进行加权融合
camera_weight = 0.7
radar_weight = 0.3
fused_data = camera_weight * camera_data + radar_weight * radar_data
print("融合后的传感器数据:", fused_data)
在该示例中,通过简单的加权方法,将不同传感器的数据进行融合,提供给AI Agent用于后续的决策。
AI Agent的感知不仅仅局限于单一的传感器数据,而是能够从多个模态的数据源中获取信息,包括视觉、听觉、触觉等。多模态数据融合技术使得AI Agent能够通过综合不同种类的信息来进行更加准确和全面的感知。
例如,AI Agent在执行复杂任务时,不仅依赖视觉传感器来识别物体,还可以结合触觉和听觉信息来优化其行为。在情感计算和情境感知方面,AI Agent也需要通过融合来自语音、面部表情、肢体动作等多个渠道的数据来进行判断。
import tensorflow as tf
from tensorflow.keras import layers
# 假设我们有两个模态的数据,分别是图像数据和音频特征
image_input = layers.Input(shape=(224, 224, 3)) # 图像输入
audio_input = layers.Input(shape=(128,)) # 音频特征输入
# 图像处理网络
x1 = layers.Conv2D(32, (3, 3), activation='relu')(image_input)
x1 = layers.Flatten()(x1)
# 音频处理网络
x2 = layers.Dense(64, activation='relu')(audio_input)
# 合并多模态数据
merged = layers.concatenate([x1, x2])
# 最终输出
output = layers.Dense(10, activation='softmax')(merged)
# 构建模型
model = tf.keras.Model(inputs=[image_input, audio_input], outputs=output)
model.summary()
该示例展示了如何将图像数据和音频数据进行融合,通过深度学习网络处理后,得到一个合并的特征表示,并用于后续的分类任务。
随着技术的发展,未来的AI Agent将不再局限于基于传统感知技术的数据输入,而是能够实现全感知决策。全感知决策意味着AI Agent不仅能够感知来自多个传感器的信息,还能够理解更复杂的环境上下文、情感状态及意图识别等高级特征。这将使AI Agent能够在动态且复杂的环境中进行更为高效、准确的决策。
全感知决策涉及到多个技术的整合,包括增强学习(Imitation Learning)、情感计算(Affective Computing)、以及深度因果推断(Deep Causal Inference)。这些技术的结合将使AI Agent在进行任务决策时,不仅考虑当前环境的状态,还能够预测未来状态和潜在的影响,做出更加全面、灵活的决策。
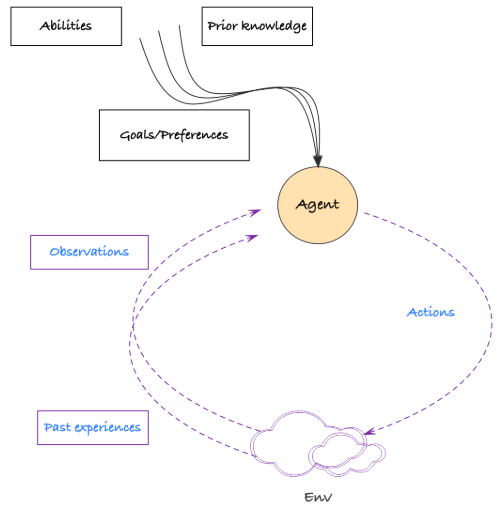
随着技术的不断进步,AI Agent正在迈向全感知决策的新时代。全感知决策不仅仅依赖于单一的传感器数据,而是将多种感知信息、环境上下文以及历史经验进行整合,以便在复杂和动态的环境中做出更为高效、智能的决策。
全感知决策(Fully Perceptive Decision-Making)指的是AI Agent能够全面理解其所处环境的状态,并结合多种感知信息,做出优化的决策。它不仅依赖于传感器数据(如图像、音频、雷达等),还结合了来自外部环境的动态信息、上下文背景、任务目标以及未来预测。这种决策模式不仅考虑即时反馈,还能够预测未来的变化,进而选择最优策略。
例如,在自动驾驶中,传统的AI Agent可能只能依赖摄像头和激光雷达来进行简单的障碍物避让。然而,结合实时交通数据、天气变化、道路施工信息等,这些Agent便能够根据更全面的环境理解做出动态调整,确保驾驶安全和流畅。
在全感知决策中,增强学习(Imitation Learning)和多模态数据理解将扮演重要角色。增强学习使AI Agent能够通过模仿和奖励机制不断优化决策策略,适应复杂环境。多模态理解则指的是AI Agent能够将来自不同感知通道(如视觉、听觉、触觉等)的数据整合成统一的认知框架,从而做出更为准确的判断。
以下是一个简单的增强学习与多模态数据融合的实例代码:
import tensorflow as tf
from tensorflow.keras import layers
# 假设我们有两种模态的数据,图像数据与文本数据
image_input = layers.Input(shape=(224, 224, 3)) # 图像输入
text_input = layers.Input(shape=(100,)) # 文本输入(例如,环境描述)
# 图像处理网络
x1 = layers.Conv2D(32, (3, 3), activation='relu')(image_input)
x1 = layers.Flatten()(x1)
# 文本处理网络
x2 = layers.Embedding(input_dim=1000, output_dim=64)(text_input)
x2 = layers.LSTM(64)(x2)
# 融合图像和文本特征
merged = layers.concatenate([x1, x2])
# 强化学习的决策输出
output = layers.Dense(4, activation='softmax')(merged)
# 构建模型
model = tf.keras.Model(inputs=[image_input, text_input], outputs=output)
model.summary()
这段代码展示了如何融合图像和文本数据,并通过强化学习模型生成决策输出。这种多模态理解为AI Agent提供了更丰富的环境认知能力,有助于决策的准确性和灵活性。
未来的AI Agent还需要具备情感计算和情境感知的能力,能够理解和反应人类的情感状态和环境情境。这种能力对于人机交互尤其重要,例如在智能家居、医疗和客服等应用场景中,AI Agent不仅需要理解环境信息,还要能够感知人的情感状态,调整其行为以提供个性化的服务。
情感计算通过分析语言、面部表情、语音语调等多种信号,识别并模拟人的情感反应。而情境感知则要求AI Agent能够根据任务目标和当前环境动态调整决策策略,确保其行为符合实际需求。
以下代码展示了如何结合语音输入和面部表情来进行情感计算:
import numpy as np
from keras.models import Sequential
from keras.layers import Dense
# 模拟语音特征和面部表情特征
speech_features = np.array([[0.7, 0.2, 0.1], [0.6, 0.3, 0.1], [0.8, 0.1, 0.1]]) # 假设是语音特征
facial_features = np.array([[0.5, 0.4], [0.6, 0.3], [0.7, 0.2]]) # 假设是面部表情特征
# 合并语音和面部表情特征
combined_features = np.concatenate((speech_features, facial_features), axis=1)
# 建立情感计算模型
model = Sequential()
model.add(Dense(32, activation='relu', input_dim=5)) # 假设5维输入
model.add(Dense(3, activation='softmax')) # 输出3种情感类别:快乐、悲伤、愤怒
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# 模拟情感识别
model.fit(combined_features, np.array([[1, 0, 0], [0, 1, 0], [0, 0, 1]]), epochs=10)
该代码示例中,我们将语音特征和面部表情特征进行融合,通过神经网络模型来分类情感状态。AI Agent通过感知情感变化来调整其行为,从而实现情感智能和更为人性化的决策。
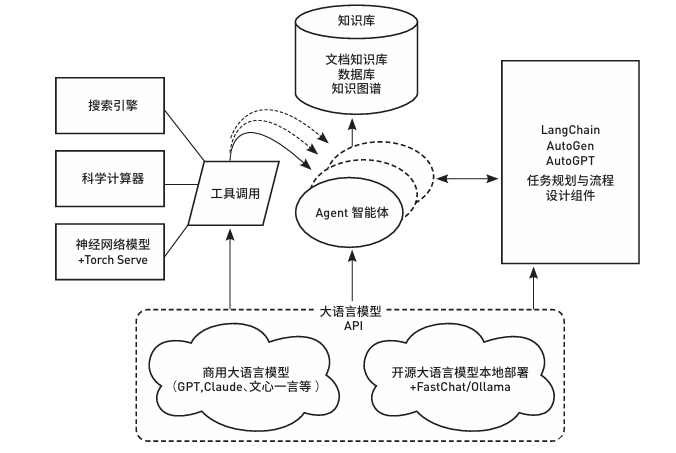
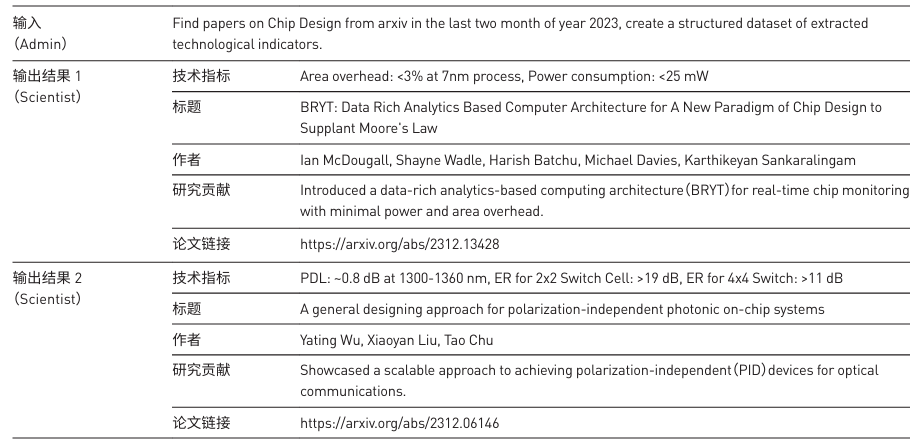
实验通过用户指令,经大模型理解并匹配对应的 Cypher功能模块,智能检索分析知识图谱数据后再经 大模型整合输出结果。相比于基于本地文档知 识库的RAG应用,基于知识图谱的RAG更具诸如结构 化的知识表示、更高准确性和一致性、更高效的信息检索、更好的关系理解、辅助推理能力、易于集成和更新 等优势。同时,利用AI Agent可外延拓展的丰富能力, 基于知识图谱RAG的AI Agent能够更好地理解用户 的实际需求并有效调用更适合的外部工具或其他智能 体,以实现更丰富场景下的知识挖掘与智能情报推理 应用。本研究仅作初步的实验性探索,后续研究可以 开发更加完善的UI交互以及多样化需求的情报分析应 用,例如将新发表的科技文献或相关科技报告上传并 自动化提取文献中的创新技术指标,同时与知识图谱 中相似技术指标对象进行技术指标先进性推理,进一步满足科技情报工作的自动化与智能化需求,设计系 统化的评测方案以便更好地验证及实现大模型结合知 识库与AI Agent在情报领域中的应用价值。
AI Agent的技术正在向更高层次的自主智能发展。未来,我们将看到以下几个趋势:
尽管AI Agent在很多领域取得了显著进展,但仍然面临一些挑战。例如,如何有效地处理海量感知数据并实现实时决策,如何在不确定和复杂的环境中确保决策的稳定性和可靠性,如何使AI Agent在与人类交互时具有足够的情感和社会智能等,都是未来需要解决的重要问题。
随着技术的不断发展,AI Agent将在越来越多的实际应用中发挥作用,改变我们的工作和生活方式。无论是在自动驾驶、智慧医疗,还是智能家居和客服行业,AI Agent的能力将不断提升,推动社会的数字化、智能化进程。
[1]王益国,杨洁,李馥孜,等.基于AI Agent的高校图书推荐架构研究[J].大学图书情报学刊,2024,42(06):3-8.
[2]吴集.多智能体仿真支撑技术、组织与AI算法研究[D].国防科学技术大学,2006.
[3]赵浜,曹树金.生成式AI大模型结合知识库与AI Agent开展知识挖掘的探析[J/OL].图书情报知识,1-14
[4]喻国明,李卓为,胡佳慧.具身AI:人机交融进程中的智能行动者[J].延边大学学报(社会科学版),2025,58(01):109-120+143.



