





6,474
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享class 为定义类的关键字,以栈为例:Stack 为类的名字,{} 中为类的主体,注意类定义结束时后⾯分号不能省略。类体中内容称为类的成员:类中的变量称为类的属性或成员变量;类中的函数称为类的方法或者成员函数 _ 或者 m 开头,注意 C++ 中这个并不是强制的,只是⼀些惯例,具体看公司的要求 inline(内联) #include<iostream>
using namespace std;
#include<cassert>
typedef int STDataType;
class Stack
{
public:
//成员函数
//1、对栈初始化
void StackInit(int n = 4)
{
array = (STDataType*)malloc(sizeof(STDataType) * n);
if (array == nullptr)
{
perror("malloc fail!");
exit(1);
}
capacity = 4;
top = 0;
}
//2、入栈操作
void StackPush(STDataType x)
{
//增容操作
if (top == capacity)
{
int newCapacity = capacity == 0 ? 4 : 2 * capacity;
STDataRtpe* temp = (STDataType*)realloc(array, newCapacity * sizeof(STDataType));
if (temp == nullptr)
{
perror("realloc fail!");
exit(1);
}
array = temp;
capacity = newCapacity;
}
array[top++] = x;
}
//3、检擦栈顶元素
STDataRtpe StackTop()
{
assert(!StackEmpty());
return array[top - 1];
}
//4、判空操作
bool StackEmpty()
{
return top == 0;
}
//5、出栈操作
void StackPop()
{
assert(!StackEmpty());
/*
断言:
条件为ture,程序继续执行
条件为false,程序停止运行
*/
top--;
}
//6、销毁栈
void StackDestroy()
{
if(array)
free(array);
array = nullptr;
top = capacity = 0;
}
private:
//成员变量(多个变量的符合)
STDataType* array;
size_t capacity;
size_t top;
};
int main()
{
Stack st;
st.StackInit();
return 0;
}
数据结构 ** 中的栈数据写在 结构体中 ,栈操作实现方法在 结构体外,而在类中将数据(成员变量)与实现方法(成员函数)统一写在类内**
C++ 中 struct 也可以定义类,**C++** 兼容C中 struct 的⽤法,同时 struct 升级成了类,明显的变化是 struct 中可以定义函数,⼀般情况下我们还是推荐⽤ class 定义类 struct** 的结构体成员默认持有公共权限 public,而 class 的成员对象默认持有私有权限 private以链表为例:
/*
C++ 将 struct 升级为了类
1、结构体类中可以定义函数
2、struct 名称就可以代表数据类型
*/
//C++兼容 C 中 struct 的用法
typedef int LTDataType;
typedef struct ListNodeC
{
LTDataType val;
struct ListNodeC* next;//不可以直接在结构体中 ListNodeC* next;
}LTNode;
//不需要 typedef 修饰,结构体名 ListNodeCPP 就是数据类型
struct ListNodeCPP
{
//不仅可以定义变量,也可定义函数
void LTInit(LTDataType x)
{
val = x;
next = nullptr;
}
private:
LTDataType val;
ListNodeCPP* next;
};
int main()
{
LTNode* node1 = NULL;
struct ListNodeC* node2 = NULL;
ListNodeCPP* node = nullptr;
node->LTInit(1);
return 0;
}
本质上:
class Date
{
public:
void Init(int year, int month, int day)
{
this->year = year;
this->month = month;
this->day = day;
}
private:
//成员变量是类中的声明(没有开辟任何空间)
int year;
int month;
int day;
};
int main()
{
//通过类所实例化出的对象为成员变量开辟空间
Date d1, d2;
return 0;
}
分析⼀下类对象中哪些成员呢?类实例化出的每个对象,都有独⽴的数据空间,所以对象中肯定包含 成员变量,那么成员函数是否包含呢?
⾸先 函数被编译后是⼀段指令,在实例对象中没办法存储,这些指令 存储在⼀个单独的区域(代码段),那么实例对象中⾮要存储的话,只能通过 成员函数的指针。
再分析⼀下,实例对象中是否有存储指针的必要呢,Date 实例化 d1 和 d2两 个对象,d1 和 d2 都有各⾃独⽴的成员变量 year/_month/_day 存储各⾃的数据,但是 d1 和 d2 的成员函数 Init/Print 指针却是⼀样的,存储在对象中就浪费了。
class Date
{
public:
void Init(int year, int month, int day)
{
this->year = year;
this->month = month;
this->day = day;
}
private:
//成员变量是类中的声明(没有开辟任何空间)
int year;
int month;
int day;
};
int main()
{
//通过类所实例化出的对象为成员变量开辟空间
Date d1, d2;
cout << sizeof(Date) << endl;
cout << sizeof(d1) << endl;
return 0;
}

汇编角度:函数调用,被定义结束后是一串指令,这串指令会存储到一个单独的区域(常量区,在操作系统的角度上:也称代码段)

成员变量需要独立的空间存放各种来自外界传入的值
C++
//通过不同实例对象调用的 year 需要不同空间存储独立的值(本质:存储地址不同)
d1.year++;
d2.year++;
//成员函数 Print,所有对象共享同一份函数代码,而非单独存储在某一个对象上
d1.Print();
d2.Print();
如果⽤ Date 实例化100个对象,那么 成员函数指针 就重复存储100次,太浪费了。这⾥需要再额外哆嗦⼀下,其实 函数指针 是不需要存储的,函数指针是⼀个地址,调⽤函数被编译成汇编指 令[call 地址],其实编译器在编译链接时,就要找到函数的地址,不是在运⾏时找, 只有动态多态是在运⾏时找,就需要存储函数地址,这个我们以后会讲解
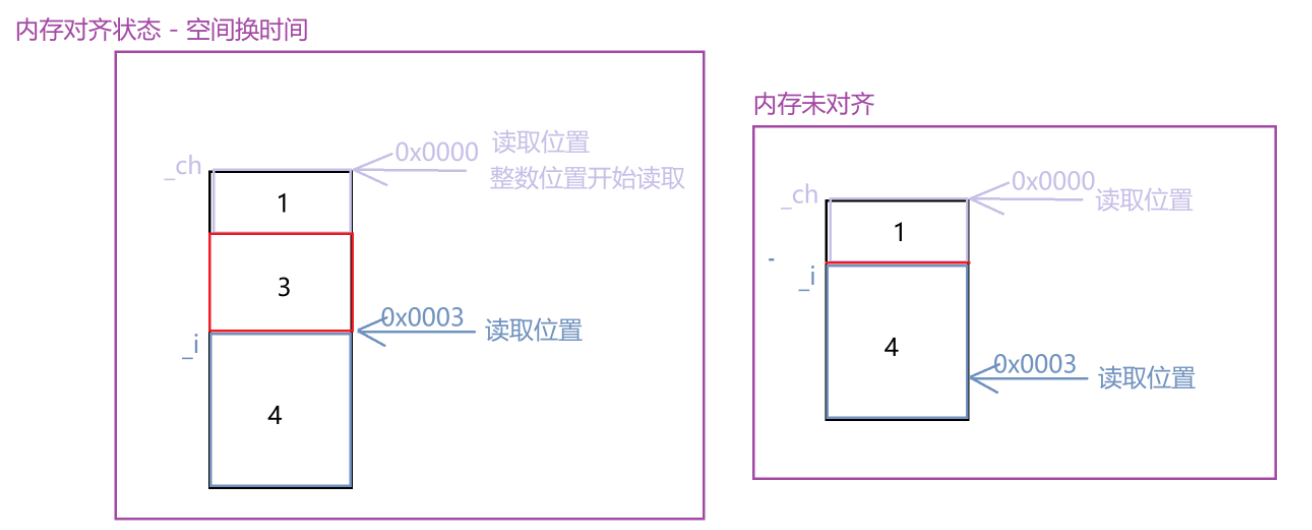
上面我们分析了 实例对象只存储成员变量,C++ 规定类实例化的对象也要符合 **内存对齐 **的规则
设计思路:以空间换时间,每个对象从对齐数的位置开始存放
class A
{
public:
void Print()
{
cout << _ch << endl;
}
private:
char _ch;
int _i;
};
class B
{
public:
void Print()
{
//...
}
};
class C
{ };
int main()
{
cout << sizeof(A) << endl;//8
cout << sizeof(B) << endl;//1
cout << sizeof(C) << endl;//1
return 0;
}
面试经典问题:为什么需要内存对齐?

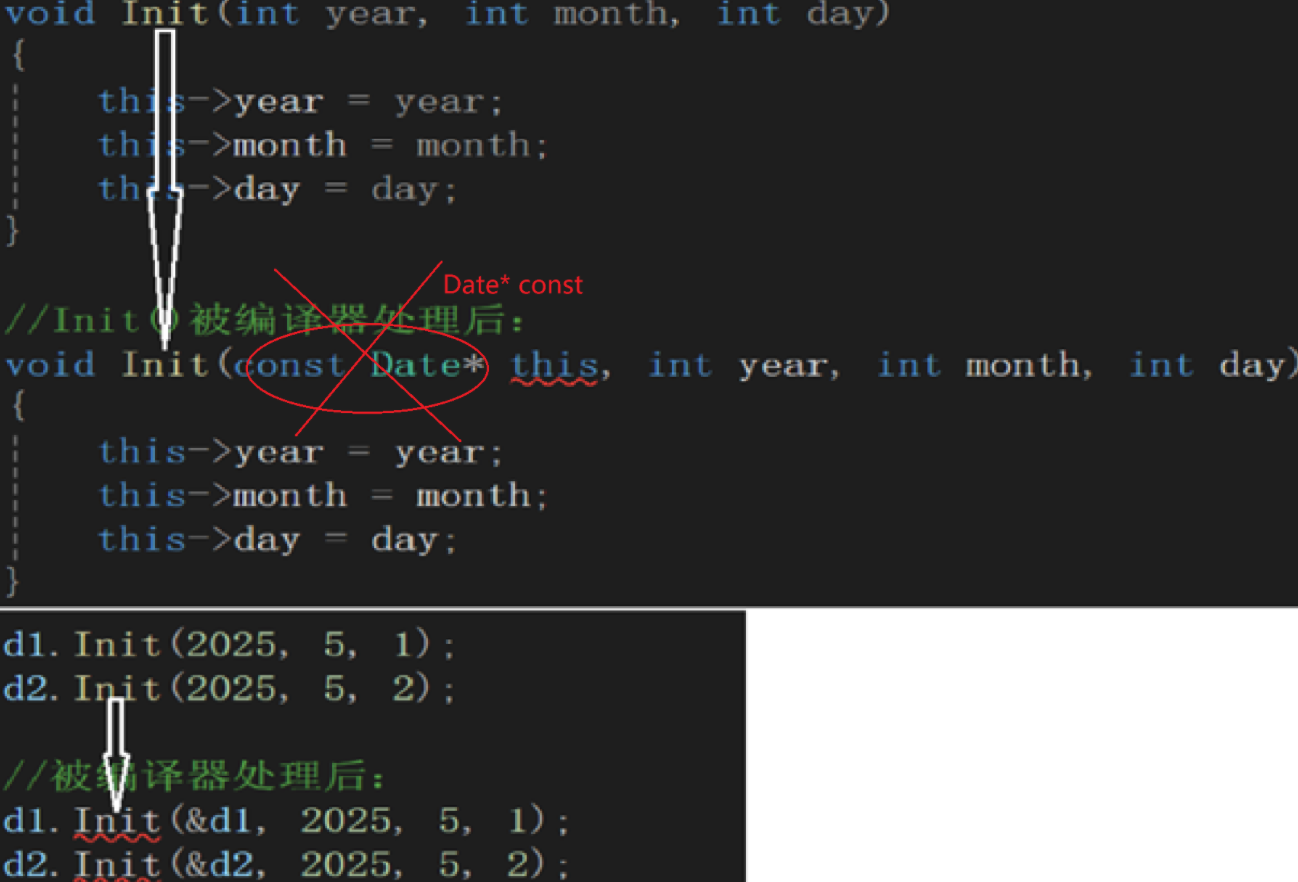
Date 类中有 Init 与 Print 两个成员函数,函数体中没有关于不同对象的区分,那当 d1 调⽤ Init 和 Print 函数时,该函数是如何知道应该访问的是 d1 对象还是 d2 对象呢?那么这⾥就要看到 C++ 给了 ⼀个隐含的 this 指针解决这⾥的问题 this指针 (编译时编译器会处理),但是可以在函数体内显 ⽰使⽤ this指针class Date
{
public:
void Init(int year, int month, int day)
{
this->year = year;
this->month = month;
this->day = day;
}
void Print()
{
cout << year << "/" << month << "/" << day << endl;
}
private:
int year;
int month;
int day;
};
int main()
{
Date d1, d2;
d1.Init(2025, 5, 1);
d2.Init(2025, 5, 2);
d1.Print();
d2.Print();
return 0;
}
思考:d1、d2 调用的是同一个 Print,执行的是同一个函数,参数相同,那为什么输出的值不同?
我们先前调用同一个函数,执行出的结果不同,是因为我们传入了不同的参数
编译阶段,编译器为我们处理隐藏过程。实际上,我们调用同一个函数 Print() 执行出了不同结果,还是因为我们传入了不同参数
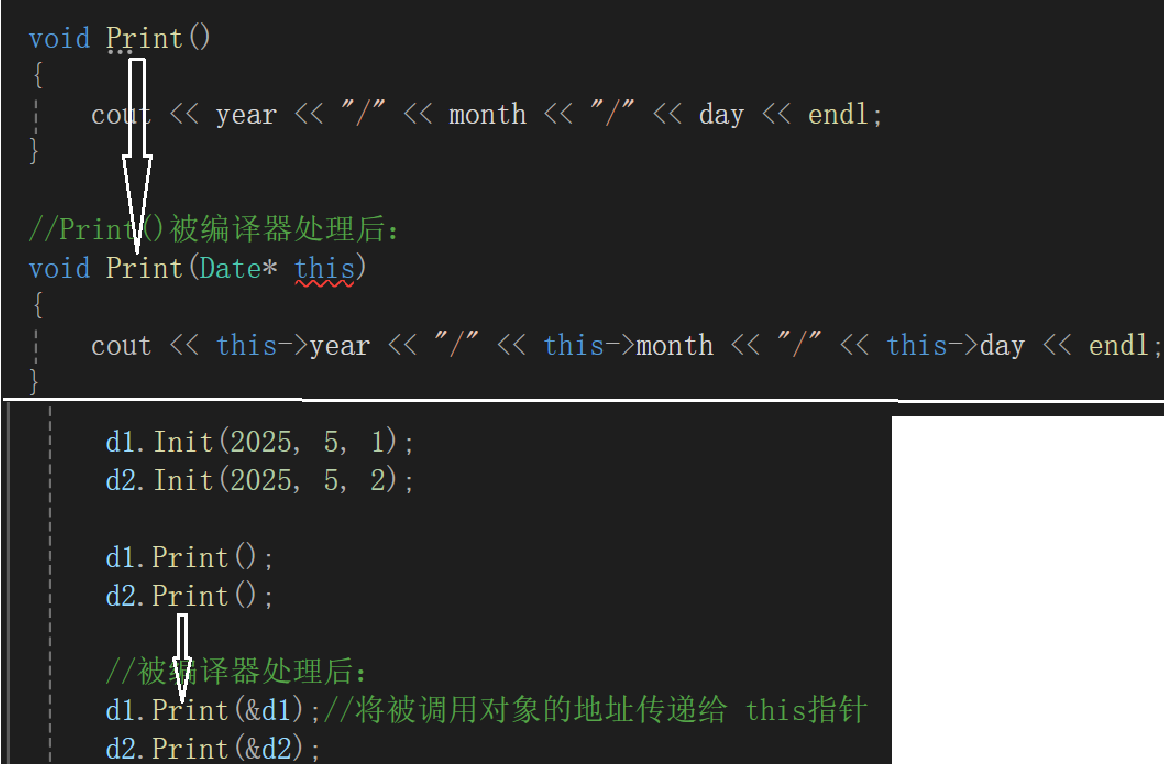
同样地,
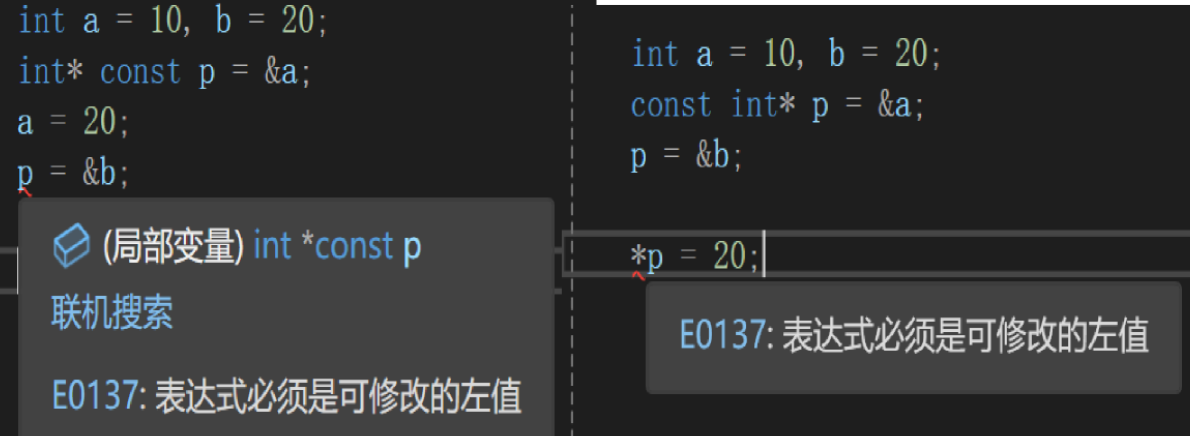
this 本身无法被修改:this = nullptr(false)

验证 this 指针指向 d1/d2对象地址:
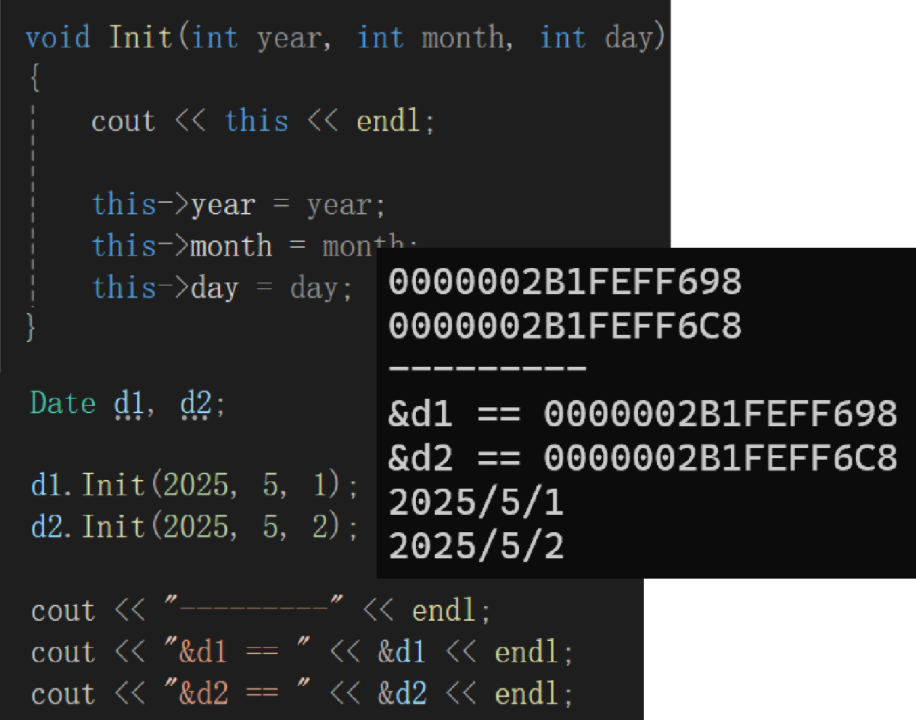

答案:
正常运行

Print() 编译时确定地址,不存在 对空指针进行解引用的行为
对象 p 的作用:
this指针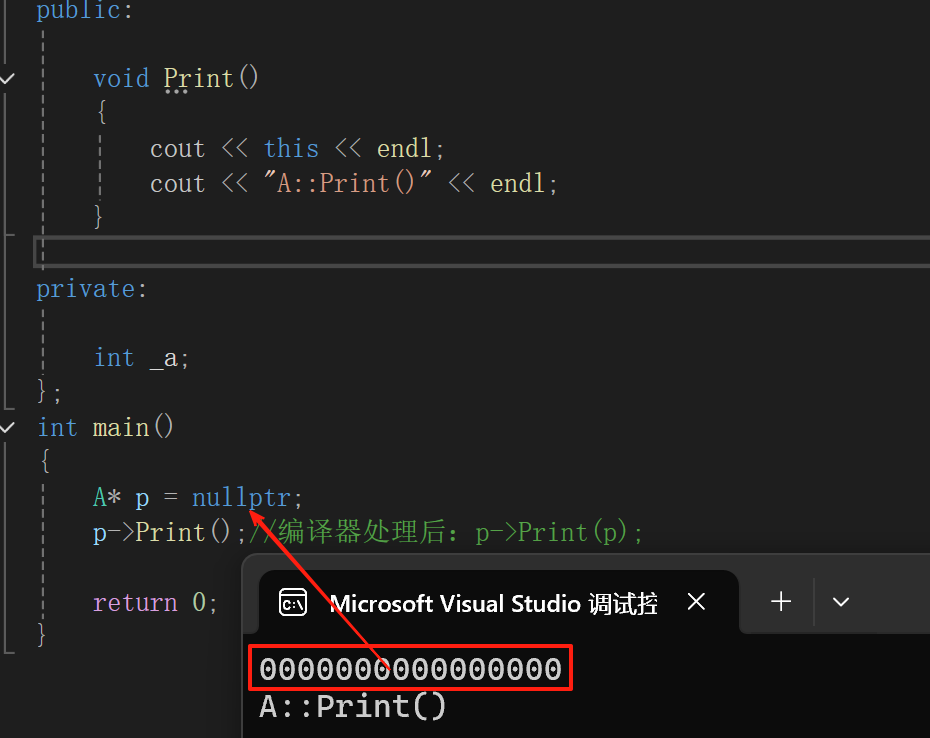

答案:
运行崩溃
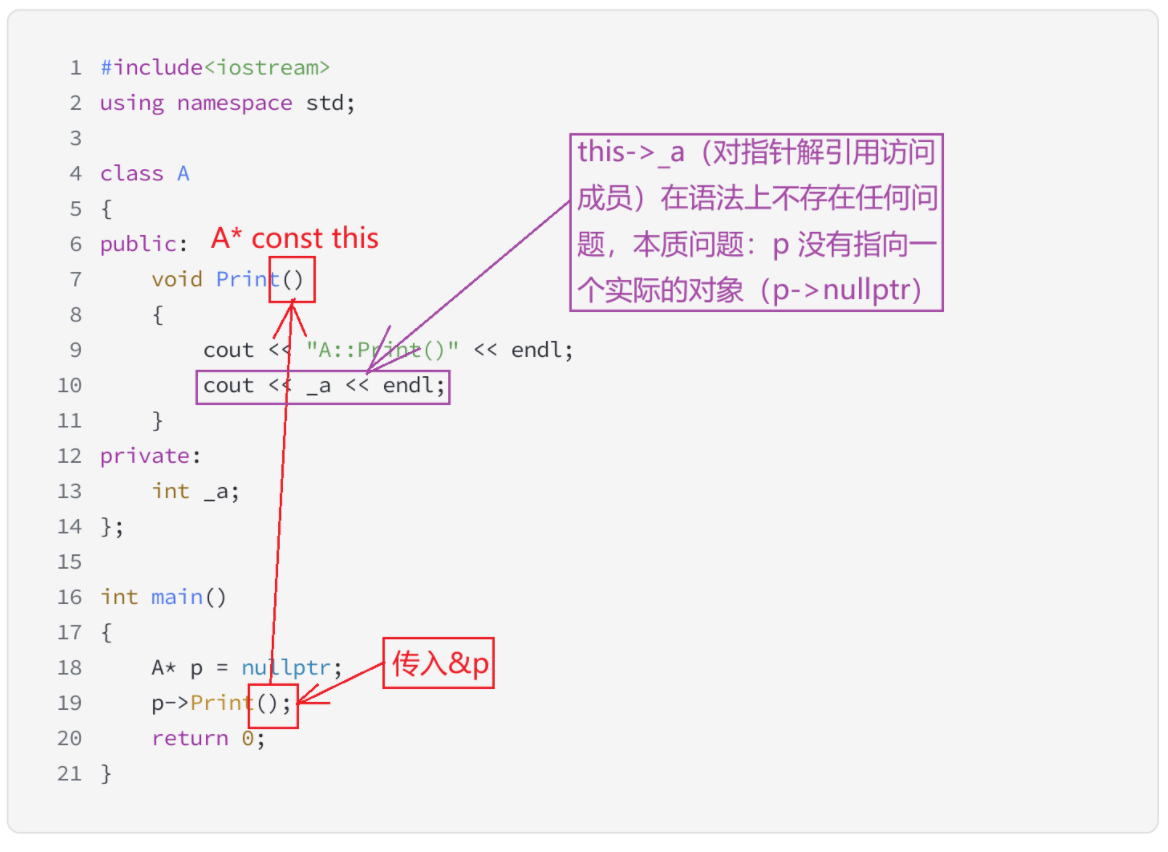
(*p).Print(); 同理
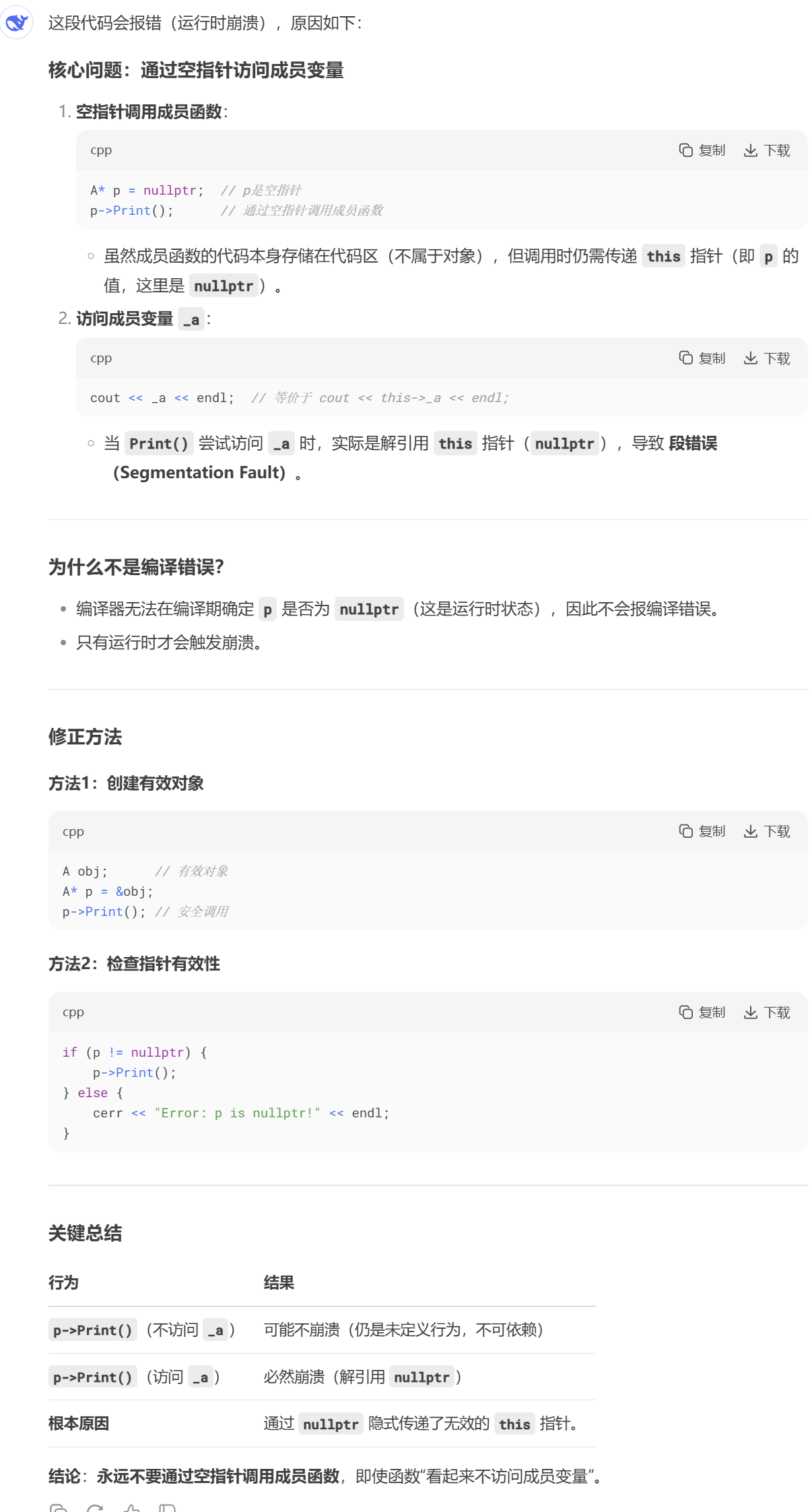
解决方法:使 指针p 指向一个有效对象
C++
A aa;
A* p = &aa;//或 A* p = new A();

常量区(语言层面) - 代码段(或叫数据段 - 操作系统角度)(函数被编译成指令后,存储在常量区)
代码段:将函数编译好的代码指令(因此代码指令存储在常量区/代码段)
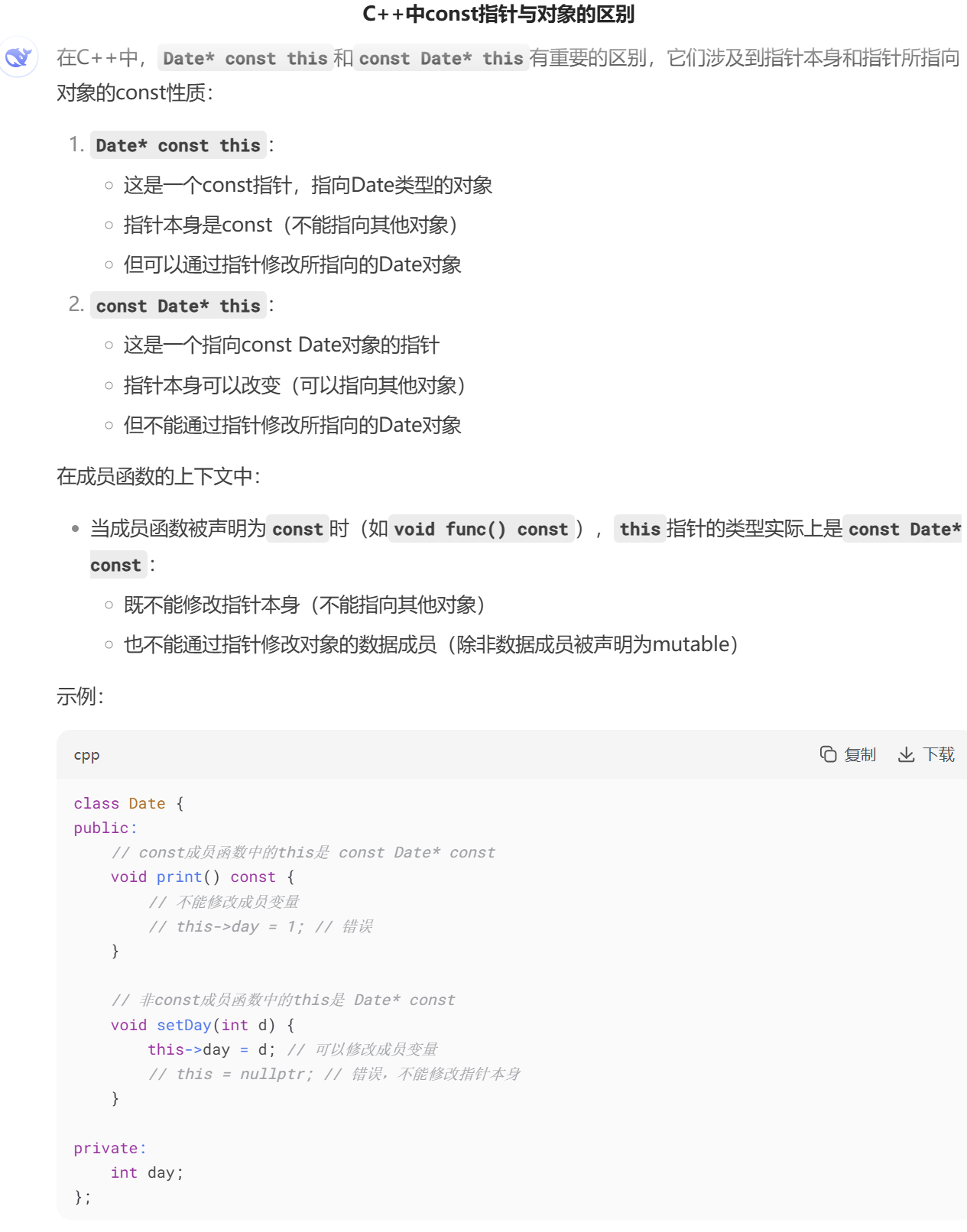
this指针 所存放的区域中,this指针 存放在对象中这一选项或许会有些许疑虑,但很简单,如果其存放在对象中,那么 sizoef(指针) == 4;这就与我们前面提到的 sizeof(p)(或sizeof(Person))== 1; 背道而驰了,因此,可论证: this指针 并不存储在实例对象中
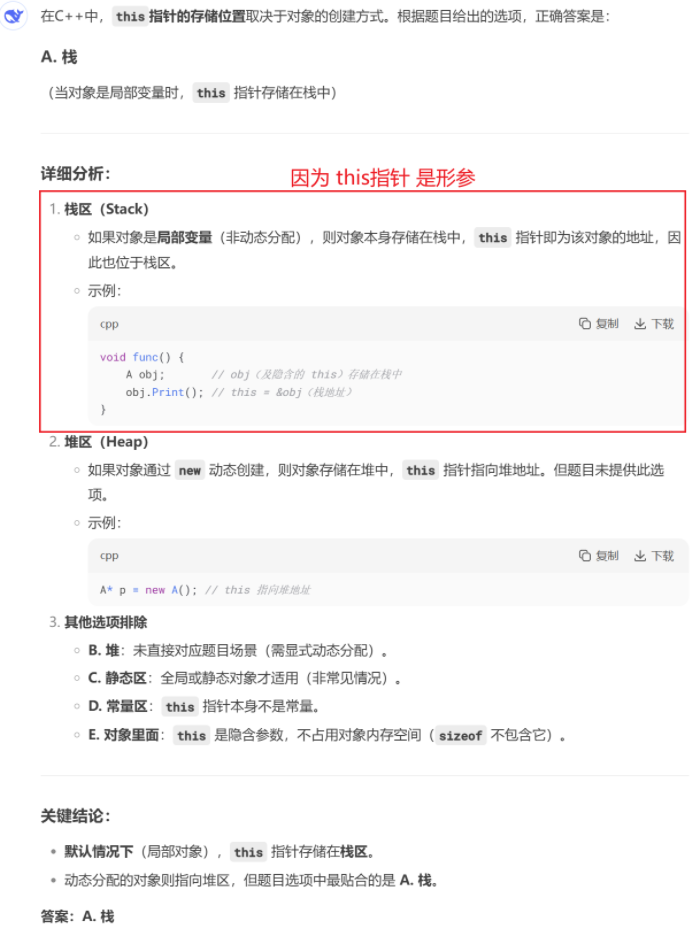
this指针 是形式参数,严格一点是存储在 栈和寄存器 上

⾯向对象三⼤特性:封装、继承、多态,下⾯的对⽐我们可以初步了解⼀下封装。 通过下⾯两份代码对⽐,我们发现 C++ 实现 Stack 形态上还是发⽣了挺多的变化,底层和逻辑上没啥变化
以栈为例,C++ 对栈的各项操作进行了严格封装(减少了 C语言 多样化,但易错误的代码形态),而 C语言 则更依赖于程序员应对形式多样化代码能力的素质
C
STack st;
//访问栈顶元素,方式一(直接调用函数 - 推荐):
st.STop();
//方式二:
st.arr[st.top - 1];
方式二:存在一定的不安全性,比如数组越界、0 - 1 == -1 等情况
Init 给的缺省参数会⽅便很多,成员函数每次不需要传对象地址,因为 this指针 隐含的传递了,⽅便了很多,使⽤类型不再需要 typedef ⽤类名就很⽅便 文章来源: https://blog.csdn.net/2401_87692970/article/details/147749689
版权声明: 本文为博主原创文章,遵循CC 4.0 BY-SA 知识共享协议,转载请附上原文出处链接和本声明。


