

86
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享背景:Apple公司研究里大模型在手机端的推理加速问题
https://aclanthology.org/2024.acl-long.678.pdf
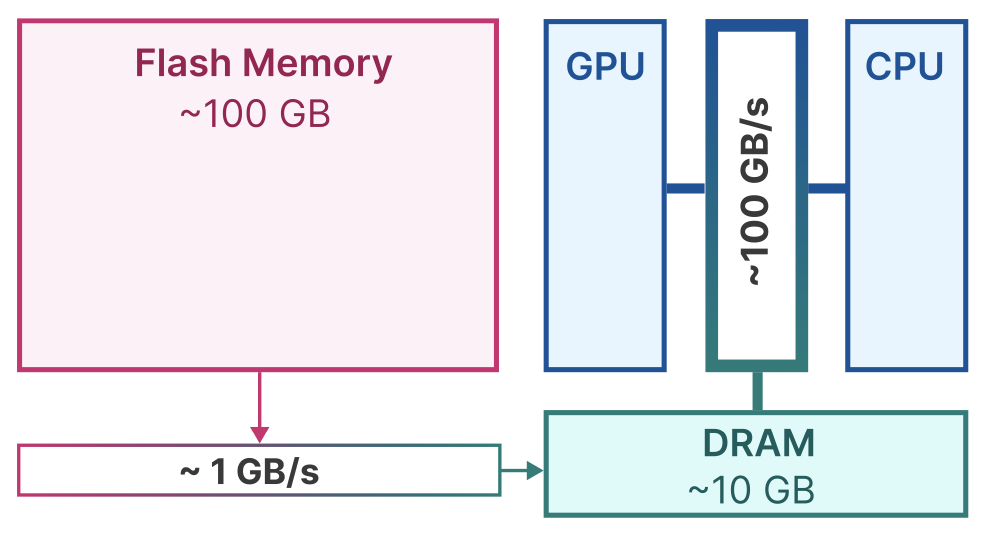
主要挑战:主存空间小,需要将大模型存放在闪存中,按需交换到主存中,但传输速度慢成为主要瓶颈
研究思路:探索大模型推理中的局部性以及神经元的可预测性,尽可能发挥缓存作用和无效交换
实验结论:能够在CPU和GPU分别加速4和20倍推理速度
观察分析:大模型本地化部署,或许能替代siri,是乔布斯理想的智能化方向,也能解决隐私问题;但模型过小难以支持复杂应用,推理加速也是影响大模型本地化部署的瓶颈问题。大模型推理问题会是未来长期研究方向和重点,也是各公司发挥大模型价值的重要阵地。

文章逻辑如手术刀般精准,案例拆解直击行业痛点,方法论可落地性极强。从底层原理到实操技巧层层递进,读完立刻想实践,堪称领域「避坑指南」与「创新灵感库」的完美结合!
