OpenHands:面向通用智能体的开源平台,支持软件工程、网页交互与多模态任务
社区首页 (3662)
 我加入的社区 我管理的社区 官方推荐社区
76
其他社区
3662
我加入的社区 我管理的社区 官方推荐社区
76
其他社区
3662
请编写您的帖子内容
社区频道(7)
显示侧栏
卡片版式
全部
运营指南
问题求助
交流讨论
学习打卡
社区活动
活动专区
最新发布
最新回复
标题
阅读量
内容评分
精选
200
评分
回复


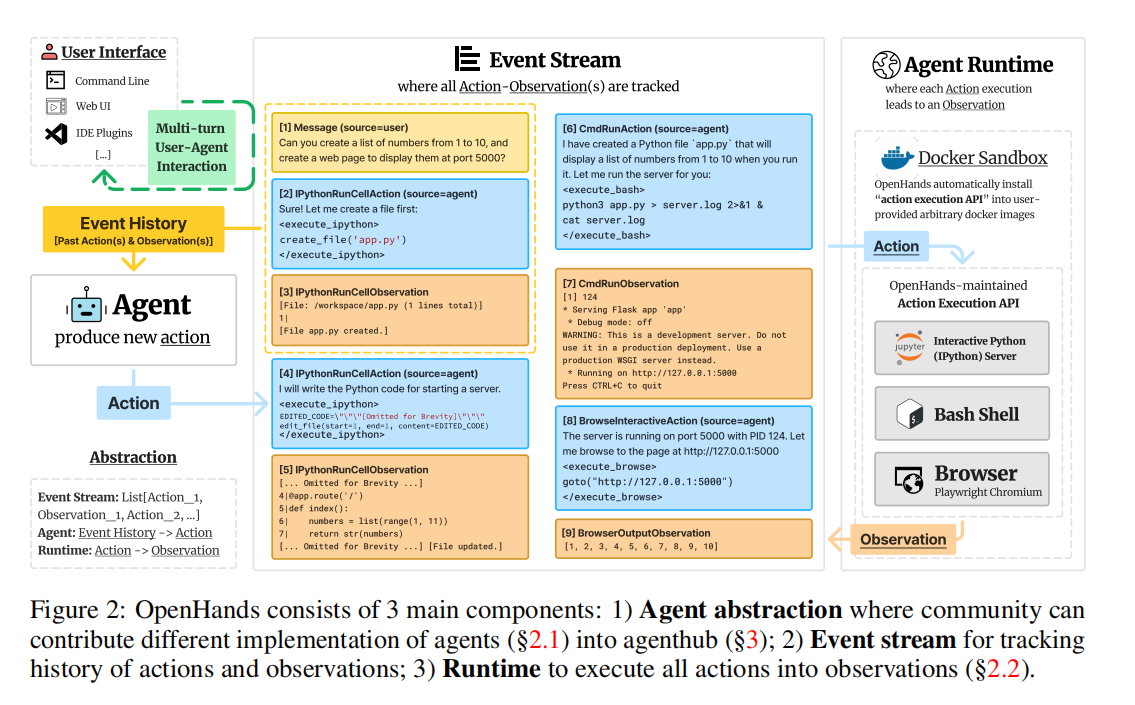
OpenHands:面向通用智能体的开源平台,支持软件工程、网页交互与多模态任务
在 LLM 智能体(AI Agent)研究迅猛发展的当下,研究者面临三大核心挑战: 工具碎片化:每个新任务都需要重新设计工具、环境与评估流程; 复现困难:多数 SOTA 系统(如 SWE-agent、GPTSwarm)缺乏完整开源实现; 评估不统一:
复制链接 扫一扫
分享
学习打卡
271
评分
回复

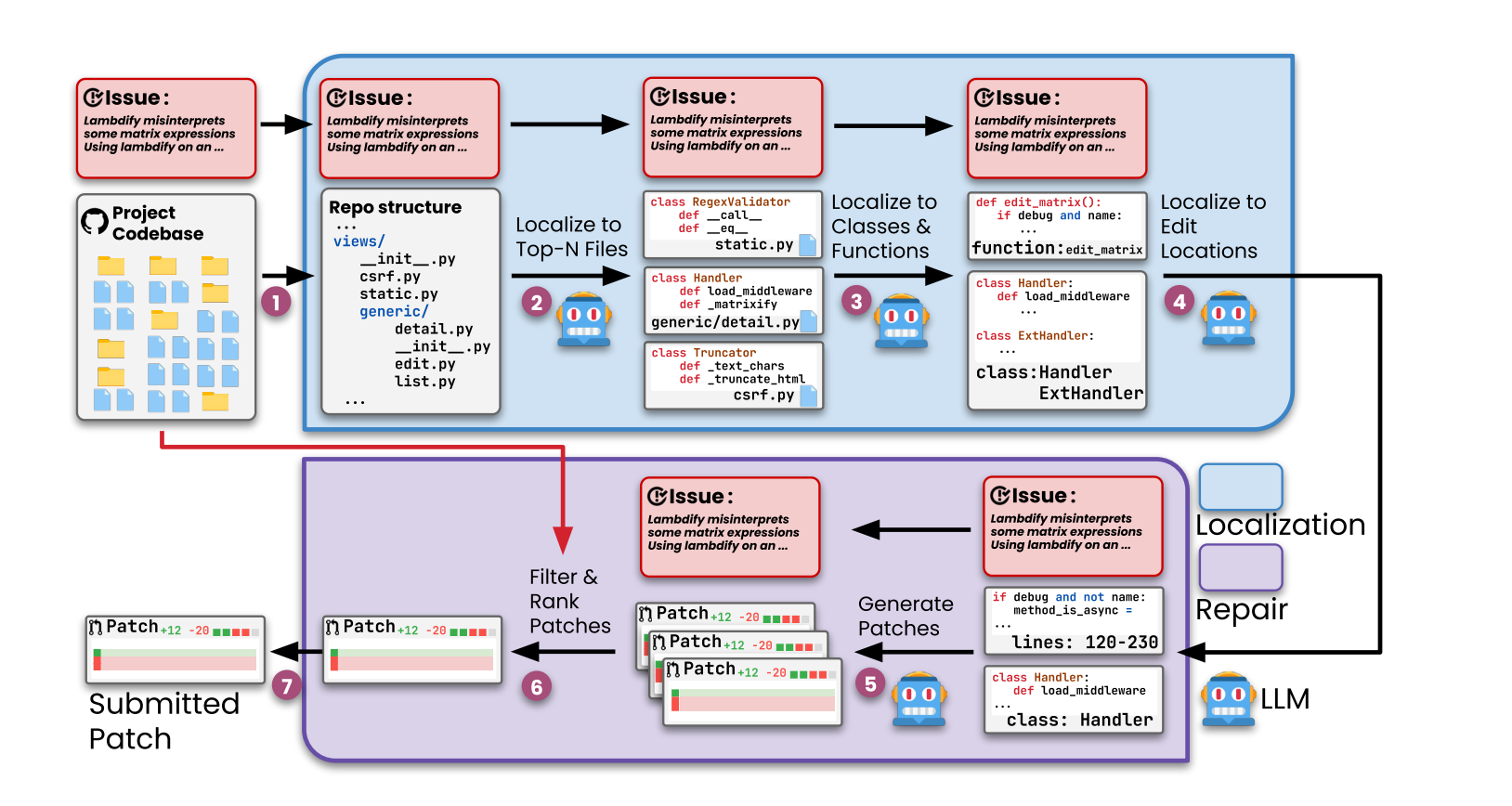
Agentless:无需智能体的仓库级软件修复新范式 —— 性能反超、成本最低、可解释性更强
在 LLM 代理(LLM Agent)风靡软件工程领域的当下,研究者们普遍认为:只有通过多轮交互、工具调用、自主规划的智能体(Agent)。然而,来自伊利诺伊大学厄巴纳-香槟分校(UIUC)的研究团队在最新论文《AGENTLESS: Demystif
复制链接 扫一扫
分享
学习打卡
187
评分
回复
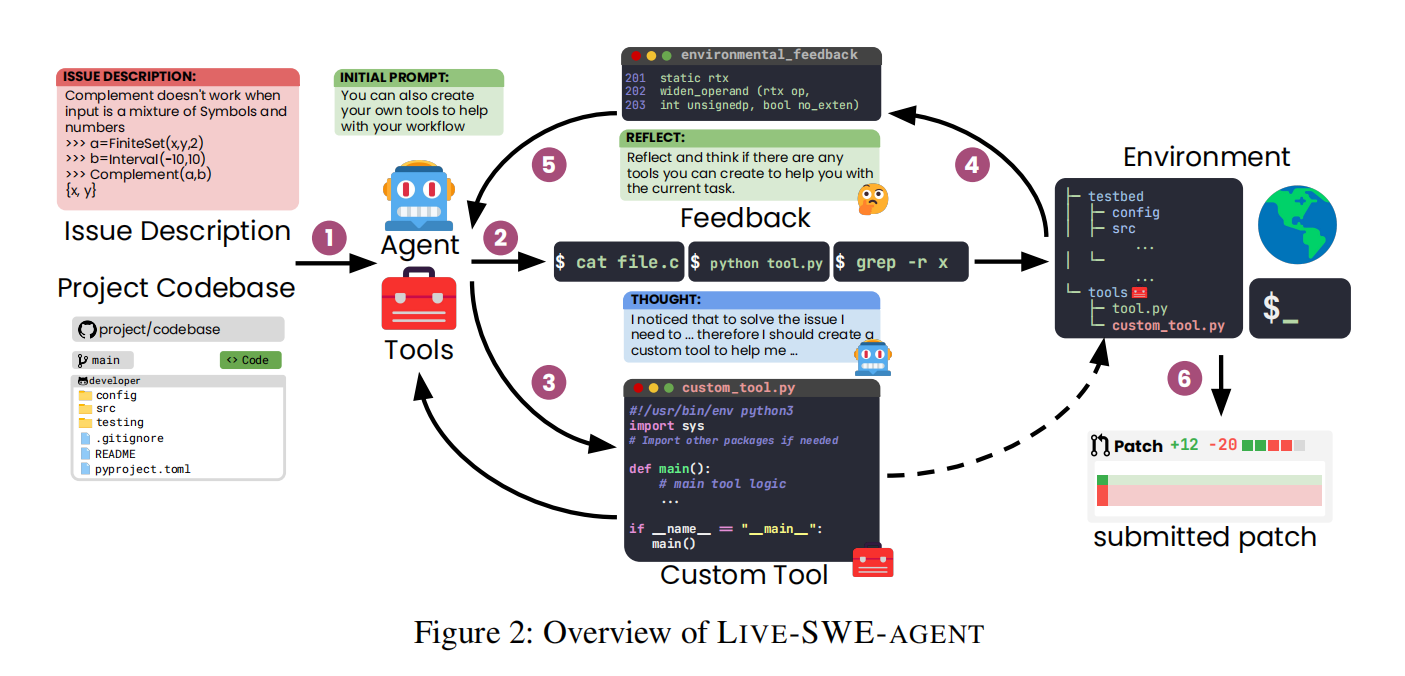
LIVE-SWE-AGENT:首个支持运行时自进化的软件工程智能体,SWE-bench Verified 修复率达 77.4%
在 LLM 驱动的软件工程智能体(Software Engineering Agent)领域,当前主流方法(如 SWE-agent、Agentless、AutoCodeRover)普遍采用静态架构设计——即工具集、工作流、提示模板等在部署前固定,无法
复制链接 扫一扫
分享
学习打卡
147
评分
回复
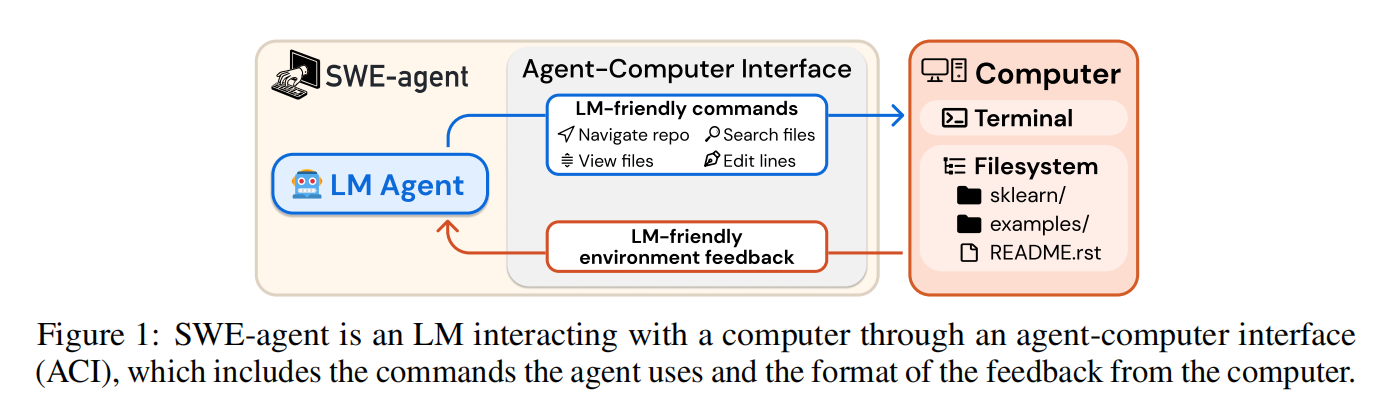
SWE-agent:通过代理-计算机接口实现自动化软件工程的范式突破
在仓库级软件修复(Repository-level Software Repair)任务中,如何让大语言模型(LLM)?现有方法多直接复用人类交互界面(如 Linux Shell、VSCode),但 LLM 与人类在认知能力、上下文处理、错误恢复等方
复制链接 扫一扫
分享
学习打卡
169
评分
回复
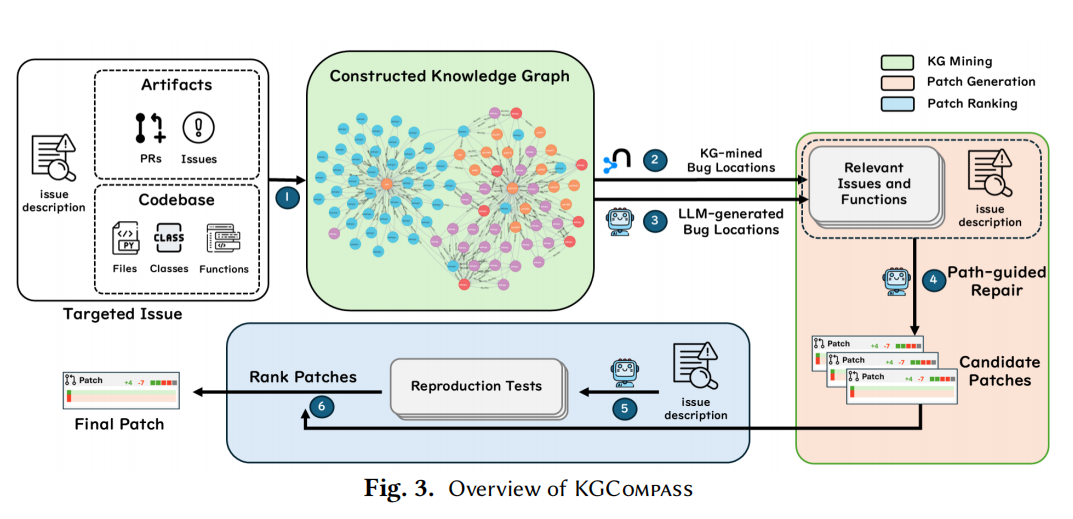
KGCompass:基于仓库感知知识图谱的可解释、低成本、高精度仓库级软件修复框架
在仓库级软件修复(Repository-level Software Repair)任务中,精准定位故障函数是自动修复成功的关键前提。然而,现实中的 GitHub Issue 通常未明确提及修改位置(仅 32.7% 含显式文件/函数名),且代码库规模
复制链接 扫一扫
分享
学习打卡
141
评分
回复

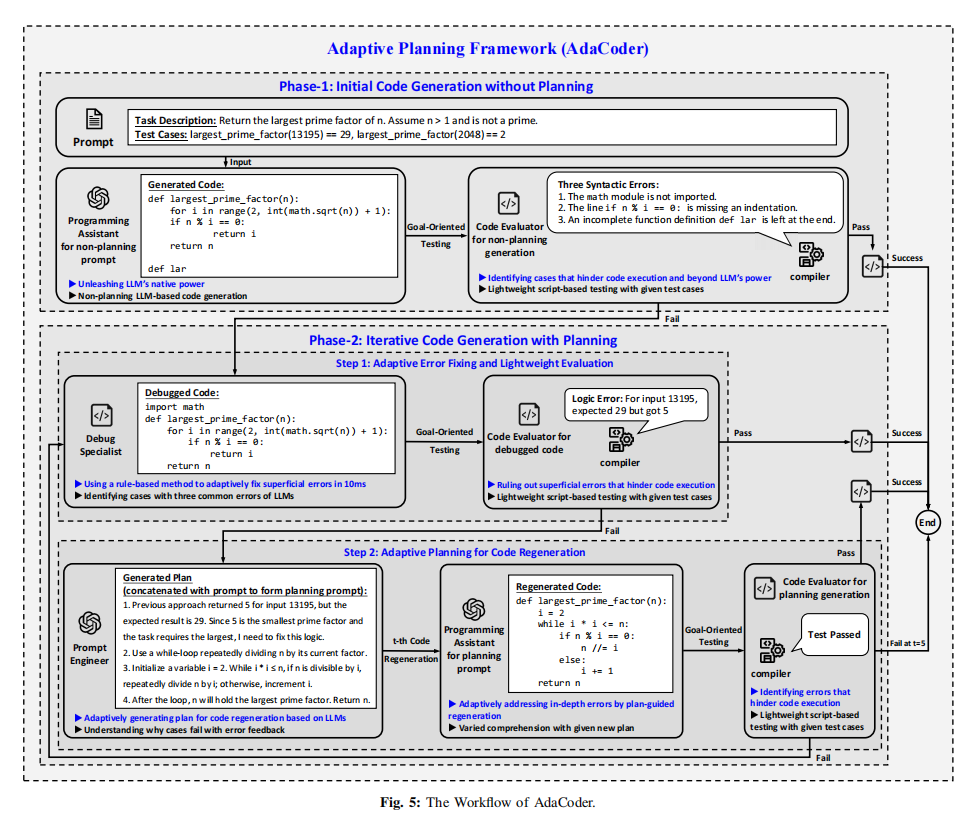
AdaCoder:面向多样化大语言模型的自适应规划式多智能体代码生成框架
近年来,基于大语言模型(LLM)的多智能体代码生成框架(如 MapCoder、AgentCoder)在 HumanEval 等基准上取得了显著进展。然而,现有工作几乎全部围绕 ChatGPT 系列闭源模型(如 GPT-4)进行设计与验证,其在开源 L
复制链接 扫一扫
分享
学习打卡
155
评分
回复

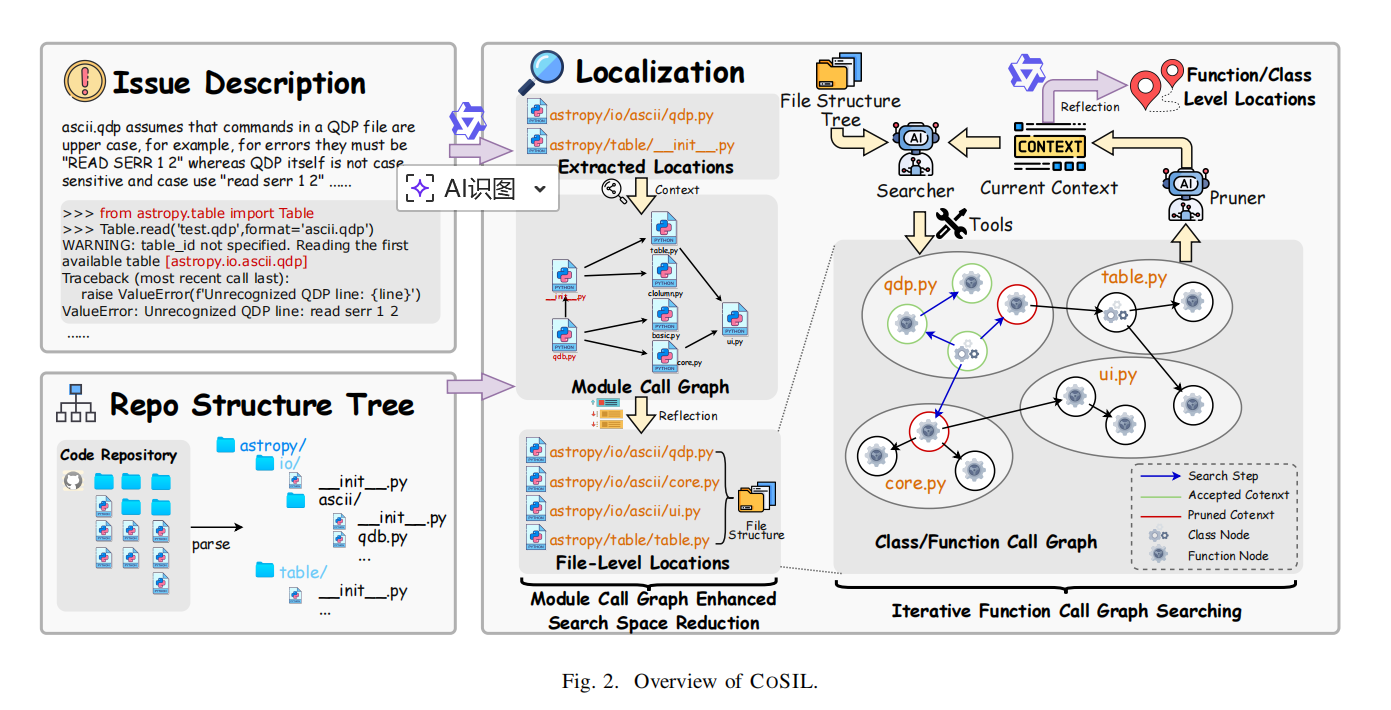
COSIL:基于 LLM 驱动的迭代式代码图搜索的函数级问题定位方法
——在 SWE-bench 上实现近 2 倍函数定位准确率提升
近期,浙江大学、重庆大学与蚂蚁集团合作发表了一篇题为《Issue Localization via LLM-Driven Iterative Code Graph Searching》的论文,提出了一种名为 COSIL(Code Graph-base
复制链接 扫一扫
分享
学习打卡

146
评分
回复

从神经科学到AI:人脑的“稀疏激活”如何启发下一代大模型?
在追求更大、更强的道路上,AI研究者们不约而同地将目光投向了终极的智能蓝本——人类大脑。近年来,一个来自神经科学的关键概念“稀疏激活”,正悄然改变着大模型的架构设计,引领着一条通往更高效、更强大AI的新路径。 一、人脑的高效秘诀:你不是在用“整个大脑
复制链接 扫一扫
分享
交流讨论

161
评分
回复
“Scaling Law”未死,但开源模型的“平民化”战争已经打响
过去两年,AI领域的叙事被“Scaling Law”(缩放定律)牢牢主导:更大规模的数据、更多的参数、更巨量的计算,带来模型能力的指数级提升。这条由OpenAI等巨头开创的“暴力美学”之路,似乎定义了通往AGI的唯一赛道。然而,就在最近,风向悄然转变
复制链接 扫一扫
分享
交流讨论

150
评分
回复
当检索增强生成遇见智能体,让模型学会“翻书”和“思考”
基础的RAG(检索增强生成)技术,如同给大模型配了一本“参考书”,有效缓解了幻觉问题。但当问题变复杂、知识库变庞大时,简单的“检索-生成”模式开始力不从心。本期,我们将探讨如何将智能体(Agent)思维融入RAG,打造一个能自主“翻书”、“思考”、最
复制链接 扫一扫
分享
交流讨论

164
评分
回复

把百亿模型塞进生产环境容易踩的五个大坑
从Jupyter Notebook里的惊艳Demo,到扛起线上真实流量的生产服务,这中间隔着一道名为“工程化”的鸿沟。我们的团队在部署一个130亿参数的开源模型时,几乎把能踩的坑都踩了一遍。现将这些血泪教训整理成文,希望能为你点亮前行的路。 坑一:显
复制链接 扫一扫
分享
交流讨论

146
评分
回复
Transformer七年后,我们为何仍在“注意力”里打转?《Attention Is All You Need》经典重读
2017年,谷歌的一篇题为《Attention Is All You Need》的论文,如同投下了一颗“技术核弹”。七年过去了,从BERT、GPT到今天的GPT-4、Llama、Sora,Transformer架构不仅一统NLP江湖,更成为AI大模型
复制链接 扫一扫
分享
交流讨论

179
评分
回复
零成本!用Google Colab+开源模型打造你的第一个AI助手
还在为没有顶级显卡而无法体验大模型发愁?本期教程将手把手带你,在完全免费的Google Colab环境中,15分钟内启动一个功能强大的开源大模型,打造专属AI助手。 一、环境准备:拥抱免费的云端算力 访问 Google Colab: 打开浏览器,访问
复制链接 扫一扫
分享
交流讨论

164
评分
回复
大模型“拼字游戏”:从下一个词预测到理解世界
你可能听说过,大语言模型本质上是一个“超级强大的单词预测器”。这个说法既正确,又不完全准确。今天,我们就用一个简单的类比,揭开大模型工作原理的神秘面纱。 一、从“完形填空”到“无限接龙” 想象你在玩一个高级版的完形填空游戏: 题目是:“今天天气很好,
复制链接 扫一扫
分享
交流讨论
167
评分
回复

国内大模型首次安全众测:281个漏洞揭示AI安全新挑战
2025年9月16日,国内首次大规模AI大模型安全众测结果正式发布,吸引了行业广泛关注。这次测试针对国内主流人工智能大模型产品进行了全面安全检测,揭示了当前AI系统面临的新型安全挑战。 一场规模空前的安全测试 本次实网众测由中央网信办网络安全协调局指
复制链接 扫一扫
分享
交流讨论

188
评分
回复
自动驾驶的“预言家”:世界模型如何塑造未来出行
自动驾驶技术近年来进展迅速,背后有一个关键技术功不可没:世界模型。它就像一个车辆的“大脑”,不仅能理解当前的驾驶环境,还能预测未来、规划行动,在复杂交通场景中做出安全、高效的决策。今天,我们将深入解读一篇题为《A Survey of World Mo
复制链接 扫一扫
分享
学习打卡
284
评分
回复
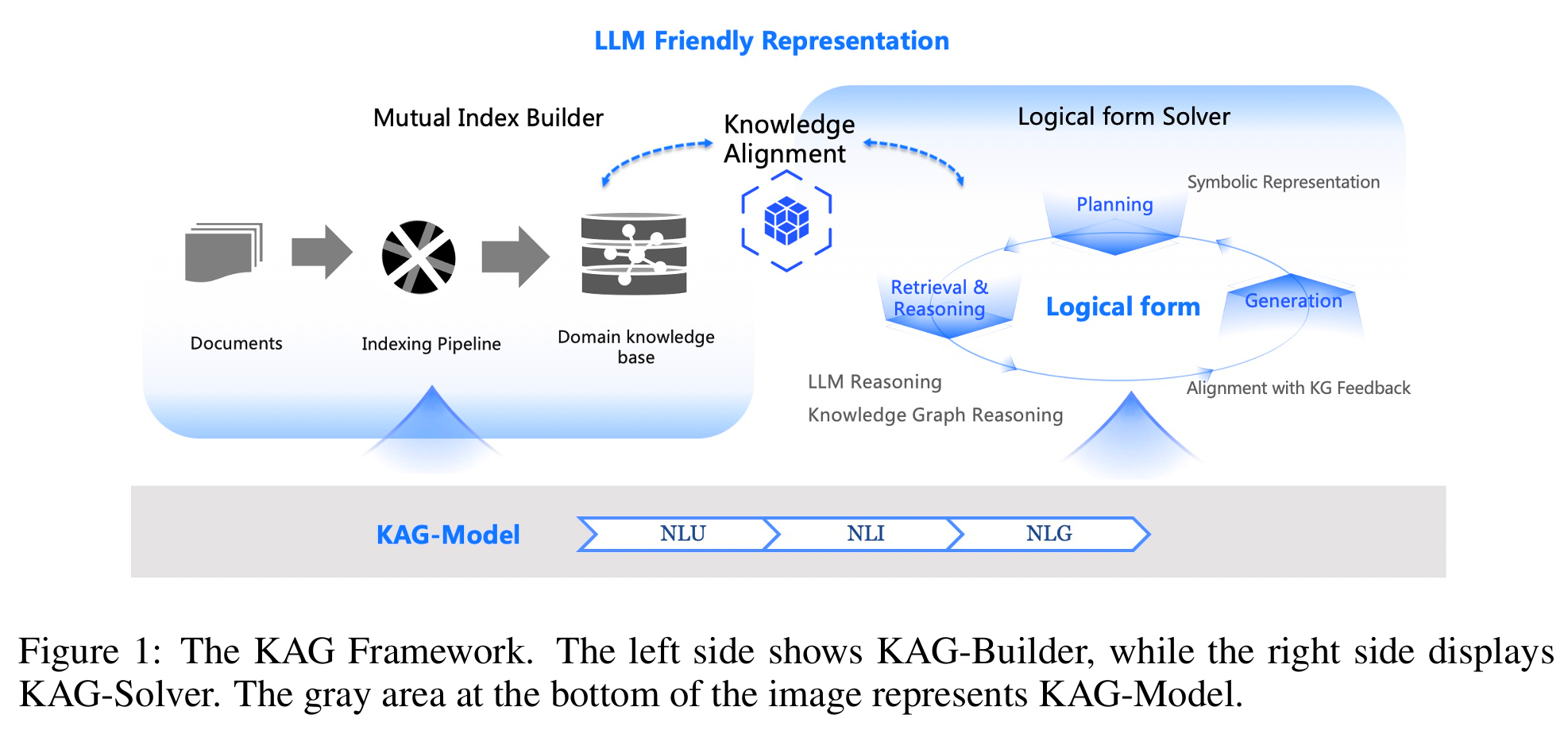
KAG:当知识图谱遇上大模型,专业领域问答的强力引擎
最近,检索增强生成(RAG)技术迅速崛起,成为让大模型获取领域知识、减少“幻觉”的主流方案。但在面对法律、医疗、政务等专业领域时,单纯基于向量相似度的检索往往显得“力不从心”——它难以捕捉知识之间的逻辑关联、数值关系与专家规则,导致生成的答案缺乏严谨
复制链接 扫一扫
分享
学习打卡
147
评分
回复
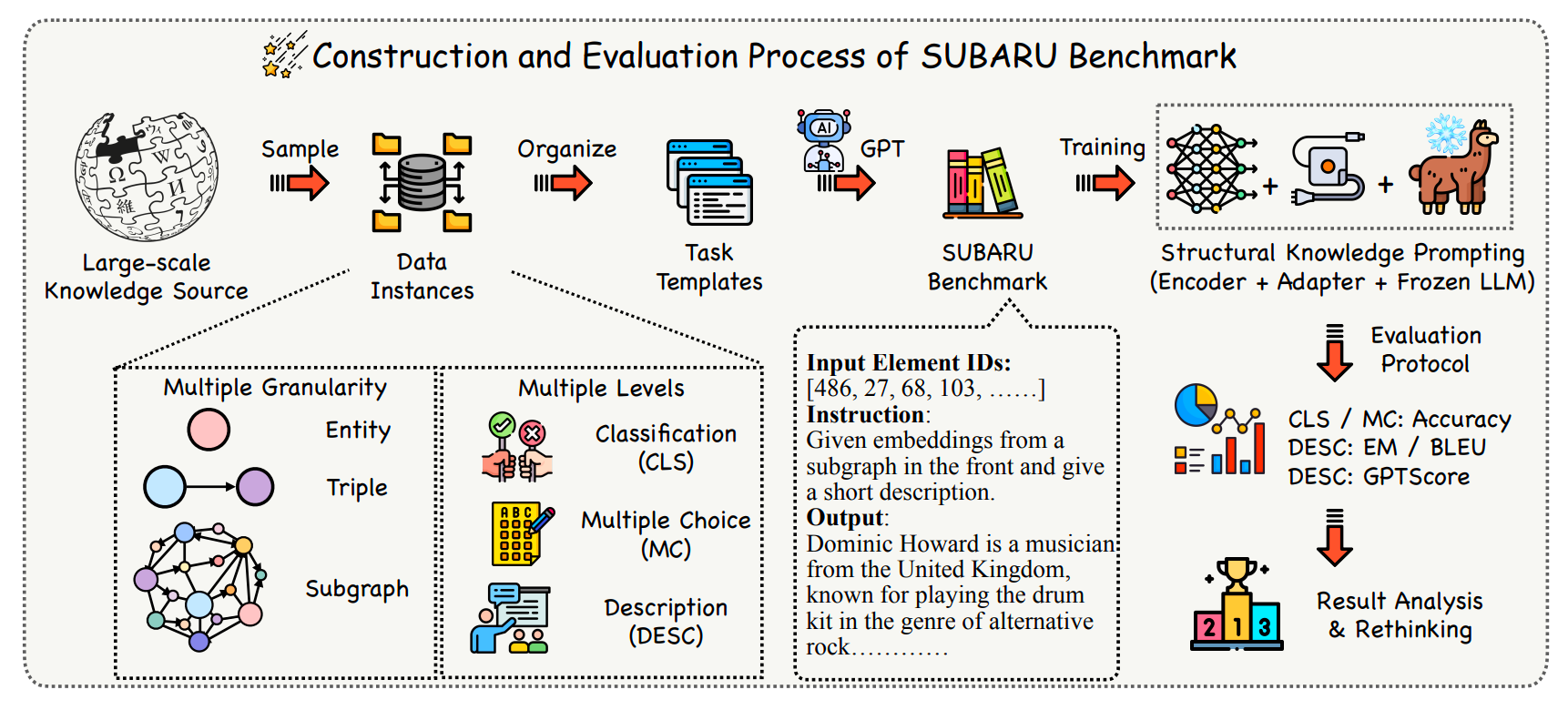
大模型结构化知识提示的泛化能力研究
当结构知识提示不再是黑箱,图表揭示了其真正的优势与短板。 大语言模型(LLM)的“幻觉”问题,就像一位知识渊博却时常记错细节的学者,限制了其在严肃场景下的应用。为了给这位学者配上可靠的“外部记忆”,研究者们引入了知识图谱,并发展出一种名为 结构知识
复制链接 扫一扫
分享
学习打卡
148
评分
回复
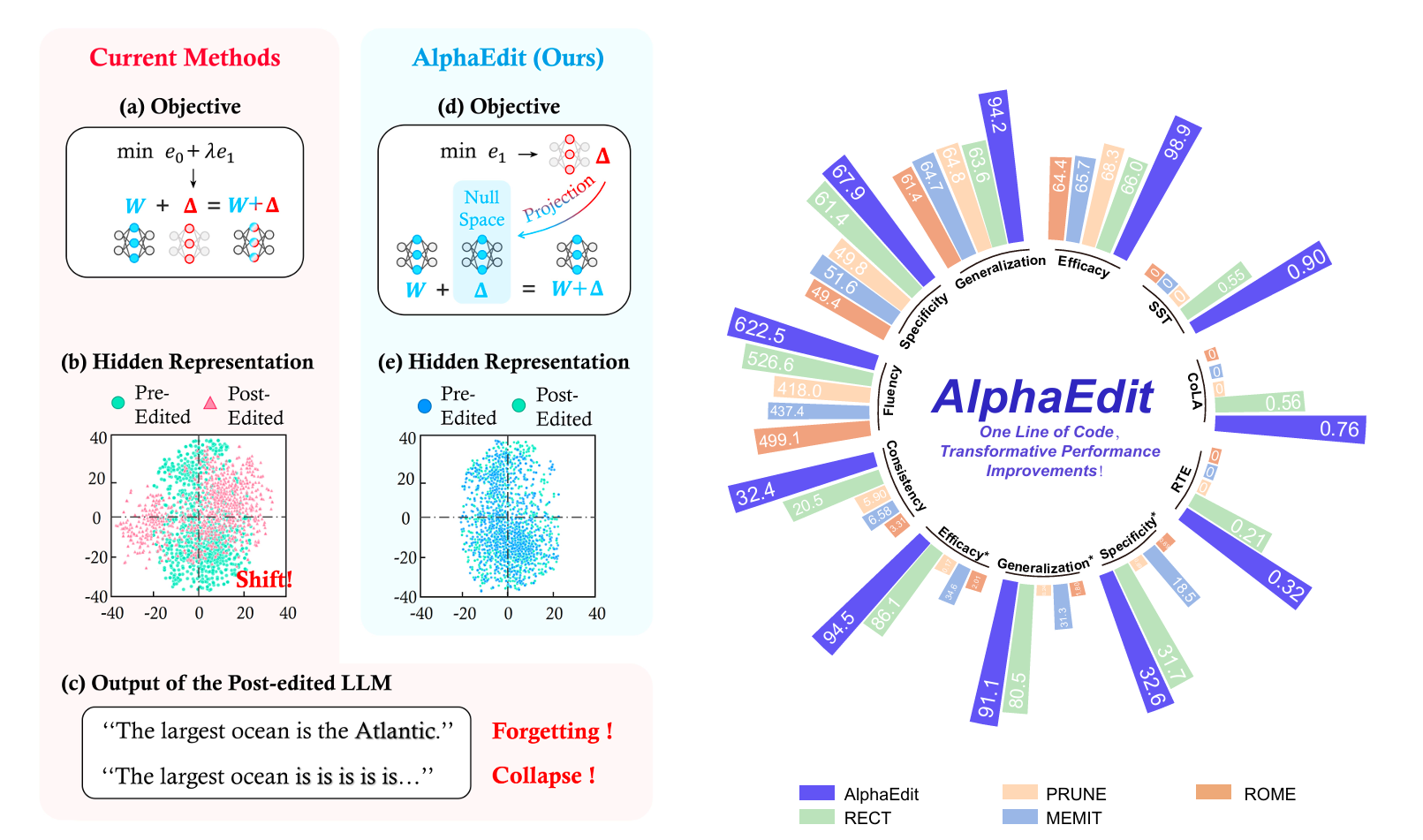
一行代码提升36.7%:AlphaEdit如何优雅地编辑大语言模型知识?
近年来,大语言模型(LLMs)如 GPT、LLaMA 等展现了强大的知识存储与推理能力,但它们也常出现“幻觉”——输出错误或过时的信息。传统方法如全量微调虽然能修正知识,但耗时耗力且容易导致模型遗忘已有能力。因此,知识编辑 成为研究热点,目标是精准修
复制链接 扫一扫
分享
学习打卡

198
评分
回复
LangExtract:告别信息“挖矿”,用AI将海量文本一键变“金矿”
面对堆积如山的病历、合同或报告,你是否也曾为手动查找和整理关键信息而头疼?现在,一个由谷歌开源的工具正在改变这一现状。 “患者每日服用阿莫西林胶囊0.5g,每日三次。”这是一条典型的临床记录,要从中提取药物、剂量和频次,传统的做法可能是编写复杂的正
复制链接 扫一扫
分享
交流讨论
为您搜索到以下结果:
109
社区成员
81
社区内容
 发帖
发帖 与我相关
与我相关 我的任务
我的任务 
通用语言大模型及知识协同技术
本社区由重庆大学与云从科技联合发起并共同运营,旨在打造一个开放、前沿、务实的知识共享与交流平台。
我们聚焦于两大前沿技术领域:通用语言大模型 (LLM)与知识协同技术。
复制链接 扫一扫
 分享
分享确定
社区描述
本社区由重庆大学与云从科技联合发起并共同运营,旨在打造一个开放、前沿、务实的知识共享与交流平台。
我们聚焦于两大前沿技术领域:通用语言大模型 (LLM)与知识协同技术。 软件工程 个人社区 重庆·沙坪坝区
社区管理员
加入社区
获取链接或二维码

- 近7日
- 近30日
- 至今
加载中
社区公告
暂无公告