



5,353
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享随着边缘智能技术的飞速发展,实时目标检测在安防监控、自动驾驶等场景的需求日益迫切,这对边缘设备的算力与能效提出了严苛要求。高通 QCS8550 作为物联网领域的高端处理器,凭借其集成的高性能 NPU(神经网络处理单元)和优化的边缘计算架构,成为支撑低延迟、高隐私性 AI 应用的核心硬件。
YOLO-NAS 作为新一代轻量级目标检测模型,在精度与速度的平衡上实现突破,其高效的网络设计为边缘部署提供了理想选择。本文聚焦于 QCS8550 平台部署 YOLO-NAS 模型的技术路径,通过模型转换、量化优化及推理测试,系统评估其在 NPU 加速下的性能表现(包括推理延迟、吞吐量及精度损失),旨在验证 QCS8550 处理实时视觉任务的硬件潜力,为边缘 AI 应用的算力选型与部署优化提供实践参考。
Qualcomm Dragonwing™ QCM8550 | Qualcomm
模型优化平台 (AIMO) 用户指南 | APLUX Doc Center
|
模型 尺寸640*640 |
CPU |
NPU QNN2.31 | NPU QNN2.31 | |||
| FP32 | FP16 | INT8 | ||||
| YOLO-NAS-s | 598.34 ms | 1.67 FPS | 7.01 ms | 142.65 FPS | 3.27 ms | 305.81 FPS |
| YOLO-NAS-m | 1442.25 ms | 0.69 FPS | 12.79 ms | 78.19 FPS | 4.76 ms | 210.08 FPS |
| YOLO-NAS-l | 1745.86 ms | 0.57 FPS | 16.71 ms | 59.84 FPS | 5.54 ms | 180.51 FPS |
点击链接可以下载YOLO-NAS系列模型的pt格式,其他模型尺寸可以通过AIMO转换模型,并修改下面参考代码中的model_size测试即可。
python3.10 -m pip install --upgrade pip
pip -V
aidlux@aidlux:~/aidcode$ pip -V
pip 25.1.1 from /home/aidlux/.local/lib/python3.10/site-packages/pip (python 3.10)
pip install ultralytics onnx
方法 1:临时添加环境变量(立即生效)
在终端中执行以下命令,将 ~/.local/bin 添加到当前会话的环境变量中
export PATH="$PATH:$HOME/.local/bin"
yolo --version,若输出版本号(如 0.0.2),则说明命令已生效。方法 2:永久添加环境变量(长期有效)
echo 'export PATH="$PATH:$HOME/.local/bin"' >> ~/.bashrc
source ~/.bashrc # 使修改立即生效
验证:执行 yolo --version,若输出版本号(如 0.0.2),则说明命令已生效。
测试环境中安装yolo版本为8.3.152
![]()
提示:如果遇到用户组权限问题,可以忽悠,因为yolo命令会另外构建临时文件,也可以执行下面命令更改用户组,执行后下面的警告会消失:
sudo chown -R aidlux:aidlux ~/.config/
sudo chown -R aidlux:aidlux ~/.config/Ultralytics
可能遇见的报错如下:
WARNING ⚠️ user config directory '/home/aidlux/.config/Ultralytics' is not writeable, defaulting to '/tmp' or CWD.Alternatively you can define a YOLO_CONFIG_DIR environment variable for this path.
新建一个python文件,命名自定义即可,用于模型转换以及导出:
from ultralytics import YOLO
# 加载同级目录下的.pt模型文件
model = YOLO('YOLO-NAS-n.pt') # 替换为实际模型文件名
# 导出ONNX配置参数
export_params = {
'format': 'onnx',
'opset': 12, # 推荐算子集版本
'simplify': True, # 启用模型简化
'dynamic': False, # 固定输入尺寸
'imgsz': 640, # 标准输入尺寸
'half': False # 保持FP32精度
}
# 执行转换并保存到同级目录
model.export(**export_params)
执行该程序完成将pt模型导出为onnx模型。
python convert_yolo_nas.py #这个python文件为上面所命名的py文件
提示:YOLO-NAS-l,YOLO-NAS-m替换代码中YOLO-NAS-s即可;
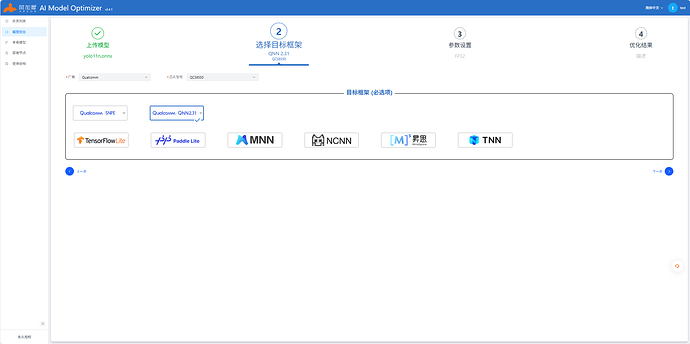

输入参数

参考上图中部分填写,其他不变,注意开启自动量化功能,AIMO更多操作查看使用说明或开发指南中的AIMO介绍。

检查aidlux环境中的aidlite版本是否与我们转换模型时选择的Qnn版本一致,终端执行:
sudo aid-pkg installed
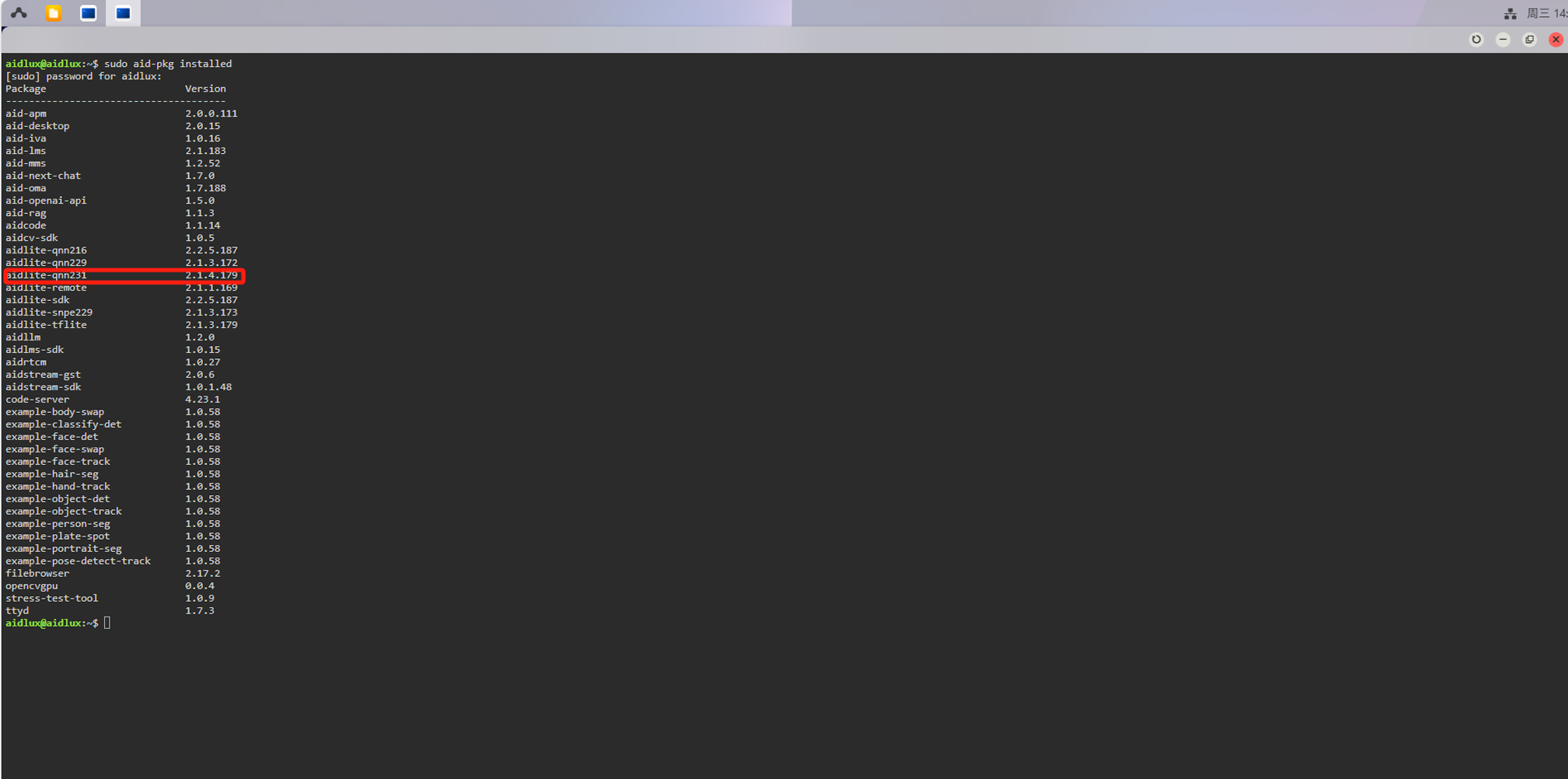
如果没有aidlite-qnn231,需要安装:
sudo aid-pkg update
sudo aid-pkg install aidlite-sdk
# Install the latest version of AidLite (latest QNN version)
sudo aid-pkg install aidlite
💡注意
Linux环境下,安装指定QNN版本的AidLite SDK:sudo aid-pkg install aidlite-{QNN Version}
例如:安装QNN2.31版本的AidLite SDK —— sudo aid-pkg install aidlite-qnn231
模型进行AI推理:
import sys
import time
import aidlite
import cv2
import numpy as np
import argparse
import onnxruntime
# 定义COCO数据集的类别名称
coco_class = ['person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus', 'train', 'truck', 'boat', 'traffic light',
'fire hydrant', 'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow',
'elephant', 'bear', 'zebra', 'giraffe', 'backpack', 'umbrella', 'handbag', 'tie', 'suitcase', 'frisbee',
'skis', 'snowboard', 'sports ball', 'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard',
'tennis racket', 'bottle', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple',
'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake', 'chair', 'couch',
'potted plant', 'bed', 'dining table', 'toilet', 'tv', 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone',
'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'book', 'clock', 'vase', 'scissors', 'teddy bear',
'hair drier', 'toothbrush']
# 为每个类别随机生成一种颜色,用于后续绘制检测框
colors = {name: [np.random.randint(0, 255) for _ in range(3)] for i, name in enumerate(coco_class)}
def img_process(img_path, size):
"""
对输入的图像进行处理,包括读取、等比缩放和归一化操作
:param img_path: 图像文件的路径
:param size: 缩放后的图像尺寸
:return: 原始图像、处理后的图像输入和缩放比例
"""
# 读取图像
frame = cv2.imread(img_path)
# 复制图像以避免修改原始图像
img_processed = np.copy(frame)
# 获取图像的高度、宽度
height, width, _ = img_processed.shape
# 计算图像的最长边
length = max(height, width)
# 计算缩放比例
scale = length / size
ratio = scale
# 创建一个全零的正方形图像,用于放置原始图像
image = np.zeros((length, length, 3), np.uint8)
# 将原始图像放置在正方形图像的左上角
image[0:height, 0:width] = img_processed
# 将图像从BGR颜色空间转换为RGB颜色空间
img_input = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# 对图像进行缩放
img_input = cv2.resize(img_input, (size, size))
# 保存缩放后的图像
cv2.imwrite("resize_football.jpg", img_input)
# 定义均值和标准差,用于归一化
mean_data = [0, 0, 0]
std_data = [255, 255, 255]
# 对图像进行归一化处理
img_input = (img_input - mean_data) / std_data # HWC
return frame, img_input, ratio
def out_process(data_local, data_conf, score_threshold, ratio):
"""
对模型的输出进行后处理,包括非极大值抑制(NMS)
:param data_local: 模型输出的边界框信息
:param data_conf: 模型输出的置信度信息
:param score_threshold: 置信度阈值
:param ratio: 缩放比例
:return: 经过后处理的检测结果
"""
# 最大预测框数量
max_predictions = 300
nms_result = []
# 将输入数据转换为PyTorch张量
data_local = torch.tensor(data_local)
data_conf = torch.tensor(data_conf)
for pred_bboxes, pred_scores in zip(data_local, data_conf):
# 找到置信度大于阈值的索引
i, j = (pred_scores > score_threshold).nonzero(as_tuple=False).T
# 根据索引筛选出边界框
pred_bboxes = pred_bboxes[i]
# 根据索引筛选出置信度
pred_cls_conf = pred_scores[i, j]
# 根据索引筛选出类别标签
pred_cls_label = j[:]
# 进行非极大值抑制(NMS)
idx_to_keep = torchvision.ops.boxes.batched_nms(boxes=pred_bboxes, scores=pred_cls_conf, idxs=pred_cls_label,
iou_threshold=score_threshold)
# 根据NMS结果筛选出置信度
pred_cls_conf = pred_cls_conf[idx_to_keep].unsqueeze(-1)
# 根据NMS结果筛选出类别标签
pred_cls_label = pred_cls_label[idx_to_keep].unsqueeze(-1)
# 根据NMS结果筛选出边界框
pred_bboxes = pred_bboxes[idx_to_keep, :]
# 将边界框、置信度和类别标签拼接在一起
final_boxes = torch.cat([pred_bboxes, pred_cls_conf, pred_cls_label], dim=1)
nms_result.append(final_boxes)
# 限制每个图像的最大预测框数量
nms_result[:] = [im[:max_predictions] if (im is not None and im.shape[0] > max_predictions) else im for im in
nms_result]
# 将结果转换为NumPy数组
detect = nms_result[0].numpy()
# 根据缩放比例调整边界框的坐标
detect[:, :4] = detect[:, :4] * ratio
return detect
def draw_res(img, boxes):
"""
在图像上绘制检测结果
:param img: 原始图像数组
:param boxes: 检测框信息,包括边界框坐标、置信度和类别标签
:return: 绘制检测结果后的图像
"""
# 将图像数组转换为无符号8位整数类型
img = img.astype(np.uint8)
# 打印检测到的目标数量
print(f"Detect {len(boxes)} targets:")
for i, [x, y, x2, y2, scores, class_ids] in enumerate(boxes):
# 将边界框坐标转换为整数类型
x = int(x)
y = int(y)
x2 = int(x2)
y2 = int(y2)
# 根据类别ID获取类别名称
name = coco_class[int(class_ids)]
# 打印检测结果信息
print(i + 1, [x, y, x2, y2], round(scores, 4), name)
# 定义标签信息,包括类别名称和置信度
label = f'{name} ({scores:.2f})'
# 获取标签的宽度和高度
W, H = cv2.getTextSize(label, 0, fontScale=1, thickness=2)[0]
# 获取类别对应的颜色
color = colors[name]
# 在图像上绘制边界框
cv2.rectangle(img, (x, y), (int(x2), int(y2)), color, thickness=2)
# 在边界框上方绘制标签背景矩形
cv2.rectangle(img, (x, int(y - H)), (int(x + W / 2), y), (0, 255,), -1, cv2.LINE_AA)
# 在标签背景矩形上绘制标签文本
cv2.putText(img, label, (x, int(y) - 6), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255, 0, 0), 1)
return img
def run(input_shapes, output_shapes, is_quant=True):
"""
运行模型推理过程,包括模型加载、推理和后处理
:param input_shapes: 模型输入的形状
:param output_shapes: 模型输出的形状
:param is_quant: 是否使用量化模型
"""
# 解析命令行参数
args = parser_args()
# 获取模型文件路径
model_path = args.target_model
# 获取输入图像文件路径
img_path = args.imgs
# 获取模型类型
model_type = args.model_type
# 获取推理次数
invoke_nums = int(args.invoke_nums)
# 创建模型实例
model = aidlite.Model.create_instance(model_path)
# 设置模型的输入和输出数据类型及形状
model.set_model_properties(input_shapes, aidlite.DataType.TYPE_FLOAT32,
output_shapes, aidlite.DataType.TYPE_FLOAT32)
# 创建配置实例
config = aidlite.Config.create_instance()
# 设置模型实现类型为本地
config.implement_type = aidlite.ImplementType.TYPE_LOCAL
if model_type.lower() == "qnn":
# 如果模型类型为QNN,设置框架类型为QNN,加速类型为DSP
config.framework_type = aidlite.FrameworkType.TYPE_QNN
config.accelerate_type = aidlite.AccelerateType.TYPE_DSP
elif model_type.lower() == "snpe2" or model_type.lower() == "snpe":
# 如果模型类型为SNPE或SNPE2,设置框架类型为SNPE2,加速类型为DSP
config.framework_type = aidlite.FrameworkType.TYPE_SNPE2
config.accelerate_type = aidlite.AccelerateType.TYPE_DSP
# 设置线程数量为4
config.number_of_threads = 4
if is_quant:
# 如果使用量化模型,设置量化标志为1
config.is_quantify_model = 1
# 根据模型和配置构建解释器
interpreter = aidlite.InterpreterBuilder.build_interpretper_from_model_and_config(model, config)
if interpreter is None:
# 如果解释器构建失败,打印错误信息
print("build_interpretper_from_model_and_config failed !")
# 初始化解释器
result = interpreter.init()
if result != 0:
# 如果解释器初始化失败,打印错误信息并返回
print(f"interpreter init failed !")
return False
# 加载模型
result = interpreter.load_model()
if result != 0:
# 如果模型加载失败,打印错误信息并返回
print("interpreter load model failed !")
return False
# 打印模型加载成功信息
print("detect model load success!")
# 定义图像缩放尺寸
size = 640
# 对输入图像进行处理
frame, img_input, ratio = img_process(img_path, size)
# 在图像输入数据上添加一个维度,以匹配模型输入要求
img_input = np.expand_dims(img_input, 0).astype(np.float32)
# 存储每次推理的时间
invoke_time = []
for i in range(invoke_nums):
# 设置解释器的输入张量
result = interpreter.set_input_tensor(0, img_input.data)
if result != 0:
# 如果设置输入张量失败,打印错误信息
print("interpreter set_input_tensor() failed")
# 记录推理开始时间
t1 = time.time()
# 执行推理
result = interpreter.invoke()
# 计算推理时间(毫秒)
cost_time = (time.time() - t1) * 1000
# 将推理时间添加到列表中
invoke_time.append(cost_time)
if result != 0:
# 如果推理失败,打印错误信息
print("interpreter set_input_tensor() failed")
# 获取模型的输出张量
qnn_conf = interpreter.get_output_tensor(0).reshape(*output_shapes[1])
qnn_local = interpreter.get_output_tensor(1).reshape(*output_shapes[0])
if qnn_local is None:
# 如果获取输出张量失败,打印错误信息
print("sample : interpreter->get_output_tensor() 0 failed !")
# 销毁解释器
result = interpreter.destory()
# 计算最大、最小、平均推理时间和推理时间的方差
max_invoke_time = max(invoke_time)
min_invoke_time = min(invoke_time)
mean_invoke_time = sum(invoke_time) / invoke_nums
var_invoketime = np.var(invoke_time)
# 打印推理时间信息
print("====================================")
print(f"QNN invoke time:\n --mean_invoke_time is {mean_invoke_time} \n --max_invoke_time is {max_invoke_time} \n --min_invoke_time is {min_invoke_time} \n --var_invoketime is {var_invoketime}")
print("====================================")
# 将模型的输出结果拼接在一起
results = np.concatenate((qnn_local, qnn_conf), axis=2)
results = results[0]
# 定义置信度阈值
score_threshold = 0.25
# 对模型输出进行后处理
detect = out_process(qnn_local, qnn_conf, score_threshold, ratio)
# 在原始图像上绘制检测结果
res_img = draw_res(frame, list(detect))
# 保存绘制检测结果后的图像
cv2.imwrite("python/results_img.jpg", res_img)
print("=======================================")
def parser_args():
"""
解析命令行参数
:return: 解析后的命令行参数
"""
# 创建参数解析器
parser = argparse.ArgumentParser(description="Run model benchmarks")
# 添加目标模型文件路径参数
parser.add_argument('--target_model', type=str, default='yolo_nas_s/yolo_nas_s_qcs8550_w8a8.qnn231.ctx.bin',
help="Inference model path")
# 添加输入图像文件路径参数
parser.add_argument('--imgs', type=str, default='bus.jpg', help="Predict images path")
# 添加推理次数参数
parser.add_argument('--invoke_nums', type=int, default=100, help="Inference nums")
# 添加模型类型参数
parser.add_argument('--model_type', type=str, default='QNN', help="Run backend")
# 解析命令行参数
args = parser.parse_args()
return args
if __name__ == "__main__":
# 定义模型输入的形状
input_shapes = [[1, 640, 640, 3]]
# 定义模型输出的形状
output_shapes = [[1, 8400, 4], [1, 8400, 80]]
# 运行模型推理过程
run(input_shapes, output_shapes)

