



5,353
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享在科技飞速发展的当下,边缘计算与人工智能的融合正在各个领域掀起创新的浪潮。在这一进程中,硬件平台的性能优劣起着举足轻重的作用。今天,我们将目光聚焦于一款实力强劲的硬件 —— 高通 QCS8550,并深入探索如何在该平台上部署热门的 YOLO11-pose 模型。
高通 QCS8550 采用先进的 4 纳米制程工艺,在提升性能的同时有效降低了功耗。其核心由八核 Kryo CPU 构成,具体包括一个主频高达 3.2GHz 的超大核,能轻松应对高强度任务;四个主频为 2.8GHz 的性能内核,兼顾性能与能效;还有三个主频 2.0GHz 的效率内核,负责日常轻负载操作,这种合理的内核配置实现了任务处理的高效与节能。在图形处理方面,集成的 Adreno 740 GPU 表现卓越,支持 4K@60Hz 的显示输出,为高清多媒体应用提供有力支撑。不仅如此,该平台在视频处理能力上也十分出色,支持 8K@30fps 的视频编码以及 8K@60fps 的视频解码,并且兼容 H.264 和 H.265 编码标准,能满足各类高品质视频应用的需求。而其最引人注目的,是高达 48TOPS 的 AI 算力,内部集成的高通 Hexagon 神经网络处理单元支持先进的 INT4 AI 精度格式,相比上一代产品,在持续 AI 推理方面实现了 60% 的能效提升,这使其在智能监控、机器人、自动驾驶辅助等对 AI 性能和能耗有严苛要求的长时间运行智能场景中表现出众。
YOLO11-pose 模型作为计算机视觉领域的重要成果,在姿态估计任务中发挥着关键作用。姿态估计旨在识别图像中特定点(即关键点)的位置,这些关键点可代表物体的各个部分,如关节、地标或其他显著特征 。通过输出一组代表图像中物体关键点的点及每个点的置信度分数,YOLO11-pose 模型能够助力我们理解物体的位置、姿势或运动状态,在体育分析、动物行为监测、机器人控制等众多场景中有着广泛应用 。
接下来,让我们一同深入探讨如何在高通 QCS8550 上成功部署 YOLO11-pose 模型,并对其性能展开全面测试,期望能为相关领域的研究与应用提供有价值的参考 。
Qualcomm Dragonwing™ QCM8550 | Qualcomm
模型优化平台 (AIMO) 用户指南 | APLUX Doc Center
|
模型 尺寸640*640 |
CPU |
NPU QNN2.31 | NPU QNN2.31 | |||
| FP32 | FP16 | INT8 | ||||
| YOLO11n-pose | 231.52 ms | 4.32 FPS | 4.77 ms | 209.64 FPS | 2.01 ms | 497.51 FPS |
| YOLO11s-pose | 510.9 ms | 1.96 FPS | 6.88 ms | 145.35 FPS | 2.89 ms | 346.02 FPS |
| YOLO11m-pose | 1247.41 ms | 0.80 FPS | 16.12 ms | 62.03 FPS | 5.32 ms | 187.97 FPS |
| YOLO11l-pose | 1589.24 ms | 0.63 FPS | 20.41 ms | 49.00 FPS | 6.83 ms | 146.41 FPS |
| YOLO11x-pose | 3062.26 ms | 0.33 FPS | 49.77 ms | 20.09 FPS | 13.4 ms | 74.63 FPS |
点击链接可以下载YOLO11-pose系列模型的pt格式,其他模型尺寸可以通过AIMO转换模型,并修改下面参考代码中的model_size测试即可
python3.10 -m pip install --upgrade pip
pip -V
aidlux@aidlux:~/aidcode$ pip -V
pip 25.1.1 from /home/aidlux/.local/lib/python3.10/site-packages/pip (python 3.10)
pip install ultralytics onnx
方法 1:临时添加环境变量(立即生效)
在终端中执行以下命令,将 ~/.local/bin 添加到当前会话的环境变量中
export PATH="$PATH:$HOME/.local/bin"
yolo --version,若输出版本号(如 0.0.2),则说明命令已生效。方法 2:永久添加环境变量(长期有效)
echo 'export PATH="$PATH:$HOME/.local/bin"' >> ~/.bashrc
source ~/.bashrc # 使修改立即生效
验证:执行 yolo --version,若输出版本号(如 0.0.2),则说明命令已生效。
测试环境中安装yolo版本为8.3.152
![]()
提示:如果遇到用户组权限问题,可以忽悠,因为yolo命令会另外构建临时文件,也可以执行下面命令更改用户组,执行后下面的警告会消失:
sudo chown -R aidlux:aidlux ~/.config/
sudo chown -R aidlux:aidlux ~/.config/Ultralytics
可能遇见的报错如下:
WARNING ⚠️ user config directory '/home/aidlux/.config/Ultralytics' is not writeable, defaulting to '/tmp' or CWD.Alternatively you can define a YOLO_CONFIG_DIR environment variable for this path.
新建一个python文件,命名自定义即可,用于模型转换以及导出:
from ultralytics import YOLO
# 加载同级目录下的.pt模型文件
model = YOLO('yolo11n-pose.pt') # 替换为实际模型文件名
# 导出ONNX配置参数
export_params = {
'format': 'onnx',
'opset': 12, # 推荐算子集版本
'simplify': True, # 启用模型简化
'dynamic': False, # 固定输入尺寸
'imgsz': 640, # 标准输入尺寸
'half': False # 保持FP32精度
}
# 执行转换并保存到同级目录
model.export(**export_params)
执行该程序完成将pt模型导出为onnx模型。
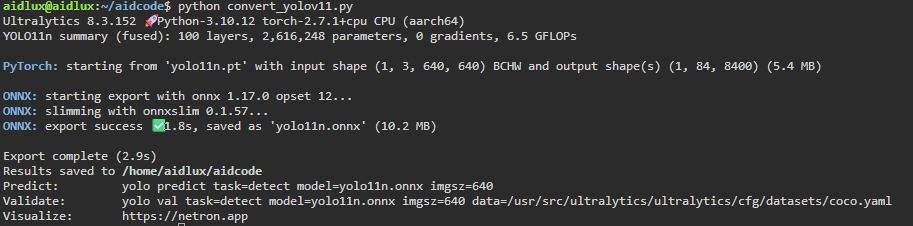
提示:Yolo11s-pose,Yolo11m-pose,Yolo11l-pose,Yolo11x-pose替换代码中Yolo11n即可;


使用Netron工具查看onnx模型结构,选择剪枝位置
/model.23/Mul_2_output_0
/model.23/Sigmoid_output_0
/model.23/Reshape_7_output_0

参考上图中红色框部分填写,其他不变,注意开启自动量化功能,AIMO更多操作查看使用说明或参考AIMO平台


检查aidlux环境中的aidlite版本是否与我们转换模型时选择的Qnn版本一致,终端执行:
sudo aid-pkg installed
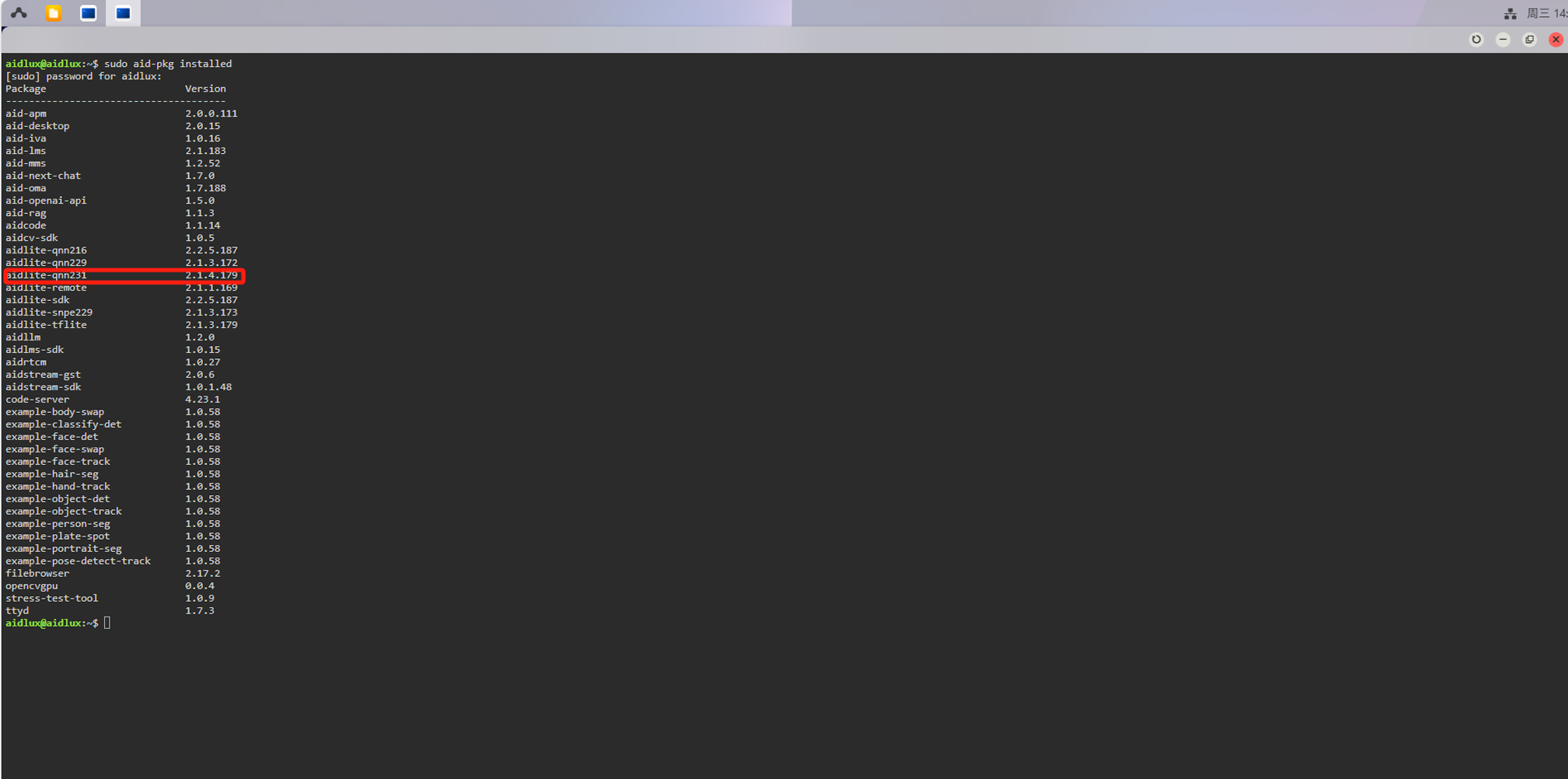
如果没有aidlite-qnn231,需要安装:
sudo aid-pkg update
sudo aid-pkg install aidlite-sdk
# Install the latest version of AidLite (latest QNN version)
sudo aid-pkg install aidlite
💡注意
Linux环境下,安装指定QNN版本的AidLite SDK:sudo aid-pkg install aidlite-{QNN Version}
例如:安装QNN2.31版本的AidLite SDK —— sudo aid-pkg install aidlite-qnn231
模型进行AI推理:
import time
import numpy as np
import cv2
import aidlite
import argparse
# --------------------- COCO‑17 骨架拓扑与颜色 ---------------------
# 定义COCO数据集的17个关键点连接关系,用于绘制骨架
SKELETON = [
(15, 13), (13, 11), (16, 14), (14, 12), (11, 12), # 下肢和躯干连接
(5, 11), (6, 12), (5, 6), (5, 7), (6, 8), # 躯干和上肢连接
(7, 9), (8, 10), (1, 2), (0, 1), (0, 2), # 头部和肩部连接
(1, 3), (2, 4), (3, 5), (4, 6) # 面部和四肢连接
]
# 定义可视化颜色方案:检测框、关键点和骨架连接线的颜色
COLORS = {
"bbox": (0, 255, 0), # 绿色框
"kpt": (0, 0, 255), # 红色点
"link": (255, 0, 0) # 蓝色骨架
}
# ----------------------------- 工具函数 -----------------------------
def iou_xyxy(box1, box2):
"""
计算两个边界框的交并比(Intersection over Union, IoU)
输入格式为[x1,y1,x2,y2],表示左上角和右下角坐标
"""
# 计算交集区域的左上角和右下角坐标
xa, ya = max(box1[0], box2[0]), max(box1[1], box2[1])
xb, yb = min(box1[2], box2[2]), min(box1[3], box2[3])
# 计算交集面积
inter = max(0, xb - xa) * max(0, yb - ya)
# 计算两个边界框的面积
area1 = (box1[2]-box1[0]) * (box1[3]-box1[1])
area2 = (box2[2]-box2[0]) * (box2[3]-box2[1])
# 计算IoU,添加小常数避免除零
return inter / (area1 + area2 - inter + 1e-6)
def nms(dets, confs, iou_thres):
"""
非极大值抑制(Non-Maximum Suppression, NMS)算法
过滤重叠的检测框,保留置信度最高且不重叠的框
返回保留的检测框索引
"""
# 按置信度降序排序
idxs = np.argsort(-confs)
keep = []
while idxs.size:
# 选择置信度最高的框
i = idxs[0]
keep.append(i)
if idxs.size == 1:
break
# 计算当前框与剩余框的IoU
ious = np.array([iou_xyxy(dets[i], dets[j]) for j in idxs[1:]])
# 保留IoU小于阈值的框
idxs = idxs[1:][ious < iou_thres]
return keep
def scale_coords(coords, ratio):
"""
将模型输出的0-640归一化坐标缩放回原图尺寸
ratio: 原图与模型输入尺寸的比例因子
"""
return coords * ratio
def draw_pose(img, bbox, kpts, kpt_thr=0.3):
"""
在原图上绘制检测框、关键点及骨架连接
img: 输入图像
bbox: 边界框坐标 [x1, y1, x2, y2]
kpts: 关键点数组,形状为[17, 3],每个关键点包含(x, y, 置信度)
kpt_thr: 关键点显示阈值,低于此值的关键点不显示
"""
# 绘制边界框
x1, y1, x2, y2 = map(int, bbox)
cv2.rectangle(img, (x1, y1), (x2, y2), COLORS["bbox"], 2)
# 绘制关键点
for x, y, s in kpts:
if s < kpt_thr: # 过滤低置信度关键点
continue
cv2.circle(img, (int(x), int(y)), 3, COLORS["kpt"], -1)
# 绘制骨架连接线
for a, b in SKELETON:
if kpts[a][2] < kpt_thr or kpts[b][2] < kpt_thr: # 过滤低置信度连接
continue
xa, ya = int(kpts[a][0]), int(kpts[a][1])
xb, yb = int(kpts[b][0]), int(kpts[b][1])
cv2.line(img, (xa, ya), (xb, yb), COLORS["link"], 2)
# ----------------------------- 主函数 -----------------------------
def main(args):
print("Start image inference ... ...")
size = 640 # 模型输入分辨率
# ---------- 1. 创建模型 & 解释器 ----------
# 初始化Aidlite配置实例
config = aidlite.Config.create_instance()
if config is None:
print("Create config failed !")
return False
# 设置模型实现类型为本地模型
config.implement_type = aidlite.ImplementType.TYPE_LOCAL
# 根据命令行参数设置模型框架类型
if args.model_type.lower() == "qnn":
config.framework_type = aidlite.FrameworkType.TYPE_QNN231
elif args.model_type.lower() in ("snpe2", "snpe"):
config.framework_type = aidlite.FrameworkType.TYPE_SNPE2
# 设置加速类型为DSP,并启用量化模型
config.accelerate_type = aidlite.AccelerateType.TYPE_DSP
config.is_quantify_model = 1
# 加载指定路径的模型
model = aidlite.Model.create_instance(args.target_model)
if model is None:
print("Create model failed !")
return False
# 设置模型输入输出形状和数据类型
input_shapes = [[1, size, size, 3]] # 输入: [批次, 高度, 宽度, 通道]
output_shapes = [[1, 51, 8400], [1, 1, 8400], [1, 4, 8400]] # 输出: [关键点, 置信度, 边界框]
model.set_model_properties(input_shapes, aidlite.DataType.TYPE_FLOAT32,
output_shapes, aidlite.DataType.TYPE_FLOAT32)
# 构建并初始化模型解释器
interpreter = aidlite.InterpreterBuilder.build_interpretper_from_model_and_config(model, config)
if interpreter is None or interpreter.init() != 0 or interpreter.load_model() != 0:
print("Interpreter init/load failed !")
return False
print("detect model load success!")
# ---------- 2. 读取并预处理图像 ----------
# 读取输入图像
img = cv2.imread(args.image_path)
if img is None:
print("Error: Could not open image file")
return False
# 获取原始图像尺寸并计算填充后的尺寸
h0, w0 = img.shape[:2]
length = max(h0, w0) # 取最大边作为填充后的尺寸
ratio = length / size # 计算缩放比例
# 创建填充画布并将图像居中放置
canvas = np.zeros((length, length, 3), np.uint8)
canvas[0:h0, 0:w0] = img
# 颜色空间转换、调整大小并归一化
img_in = cv2.cvtColor(canvas, cv2.COLOR_BGR2RGB)
img_in = cv2.resize(img_in, (size, size))
img_in = img_in.astype(np.float32) / 255.0 # 归一化到 0-1
# ---------- 3. 预热 ----------
# 进行3次推理预热,确保性能测试准确性
for _ in range(3):
interpreter.set_input_tensor(0, img_in.data)
interpreter.invoke()
# ---------- 4. 推理 ----------
# 性能测试:执行多次推理并记录时间
invoke_nums = 100
invoke_times = []
print(f"Running performance test with {invoke_nums} iterations...")
for i in range(invoke_nums):
interpreter.set_input_tensor(0, img_in.data)
t1 = time.time()
result = interpreter.invoke()
t2 = time.time()
if result != 0:
print("interpreter invoke() failed")
return False
invoke_time = (t2 - t1) * 1000 # 转换为毫秒
invoke_times.append(invoke_time)
# 每10次打印一次进度
if (i + 1) % 10 == 0:
print(f"Completed {i + 1}/{invoke_nums} iterations")
# 计算性能统计指标
mean_invoke_time = np.mean(invoke_times) # 平均推理时间
max_invoke_time = np.max(invoke_times) # 最大推理时间
min_invoke_time = np.min(invoke_times) # 最小推理时间
var_invoke_time = np.var(invoke_times) # 推理时间方差
fps = 1000 / mean_invoke_time # 计算FPS (每秒帧数)
# 打印性能测试结果
print(f"\nInference {invoke_nums} times:\n"
f"-- mean_invoke_time is {mean_invoke_time:.2f} ms\n"
f"-- max_invoke_time is {max_invoke_time:.2f} ms\n"
f"-- min_invoke_time is {min_invoke_time:.2f} ms\n"
f"-- var_invoke_time is {var_invoke_time:.2f}\n"
f"-- FPS: {fps:.2f}\n")
# ---------- 5. 取输出 ----------
# 获取模型输出并重塑形状
qnn_local = interpreter.get_output_tensor(0).reshape(1, 51, 8400) # 关键点输出
qnn_conf = interpreter.get_output_tensor(1).reshape(1, 1, 8400) # 置信度输出
qnn_bbox = interpreter.get_output_tensor(2).reshape(1, 4, 8400) # 边界框输出
# 合并输出并调整形状为 [检测数量, 56]
pred = np.concatenate((qnn_local, qnn_conf, qnn_bbox), axis=1) # (1,56,8400)
pred = pred.transpose(0, 2, 1)[0] # (8400,56)
# ---------- 6. 后处理 ----------
# 提取置信度并过滤低于阈值的预测
confs = pred[:, 51]
mask = confs > args.conf_thres
if not np.any(mask):
print("No objects found.")
interpreter.destory()
return True
# 应用掩码过滤预测结果
pred = pred[mask]
confs = confs[mask]
# 将边界框从中心点+宽高格式转换为左上角+右下角格式
b = pred[:, 52:56]
boxes_xyxy = np.empty_like(b)
boxes_xyxy[:, 0] = b[:, 0] - b[:, 2] / 2 # x1 = cx - w/2
boxes_xyxy[:, 1] = b[:, 1] - b[:, 3] / 2 # y1 = cy - h/2
boxes_xyxy[:, 2] = b[:, 0] + b[:, 2] / 2 # x2 = cx + w/2
boxes_xyxy[:, 3] = b[:, 1] + b[:, 3] / 2 # y2 = cy + h/2
# 应用非极大值抑制过滤重叠框
keep = nms(boxes_xyxy, confs, args.iou_thres)
boxes_xyxy = boxes_xyxy[keep]
kpts = pred[keep, :51].reshape(-1, 17, 3) # 重塑关键点数据为 [人数, 17关键点, 3坐标值]
# ---------- 7. 可视化 ----------
# 复制原图用于绘制结果
out_img = img.copy()
# 遍历每个检测结果并绘制
for box, kp in zip(boxes_xyxy, kpts):
# 将模型坐标缩放回原图尺寸
box_scaled = scale_coords(box, ratio)
kp_scaled = scale_coords(kp[:, :2], ratio)
# 合并坐标和置信度
kp_vis = np.concatenate([kp_scaled, kp[:, 2:3]], axis=1)
# 绘制人体姿态
draw_pose(out_img, box_scaled, kp_vis, kpt_thr=0.25)
# 保存结果图像
cv2.imwrite("result1111.jpg", out_img)
print("Result saved to result11.jpg")
# 释放资源
interpreter.destory()
return True
# --------------------------- 参数解析 ---------------------------
def parser_args():
"""解析命令行参数"""
parser = argparse.ArgumentParser(description="Run image inference with YOLOv11‑pose")
# 模型路径参数
parser.add_argument('--target_model', type=str,
default='yolov11n_pose/cutoff_yolo11n-pose_qcs8550_w8a8.qnn231.ctx.bin',
help="Path to model binary")
# 输入图像路径参数
parser.add_argument('--image_path', type=str, default='bus.jpg', help="Input image path")
# 模型后端类型参数
parser.add_argument('--model_type', type=str, default='QNN', help="Backend: QNN / SNPE2")
# 置信度阈值参数
parser.add_argument('--conf_thres', type=float, default=0.25, help="Confidence threshold")
# NMS IoU阈值参数
parser.add_argument('--iou_thres', type=float, default=0.45, help="NMS IoU threshold")
return parser.parse_args()
# ----------------------------- 入口 -----------------------------
if __name__ == "__main__":
# 解析命令行参数并执行主函数
args = parser_args()
main(args)


