



5,380
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享在计算机视觉技术持续突破的浪潮中,人体姿态估计技术正成为连接物理世界与数字智能的关键纽带,其精准度与实时性直接影响着智能系统对人类行为的理解与响应效率。而支撑这一技术落地的核心,既离不开先进的算法模型,更依赖于高性能硬件平台的强大算力支撑。
高通 QCS6490 平台作为面向边缘智能设备的处理器,其性能优势尤为突出。该平台采用异构计算架构,集成了高通 Kryo 660 CPU 核心与 Adreno 643 GPU,同时搭载专用的 Hexagon 698 DSP 及 SPECTRA 480 ISP,形成了多维度的计算能力矩阵。其中,Adreno GPU 支持 OpenGL ES 3.2、Vulkan 1.1 等先进图形接口,可提供每秒超过 1 万亿次的运算能力,为深度学习模型的并行计算提供了坚实基础;Hexagon DSP 则专注于低功耗场景下的 AI 推理加速,通过专用的张量加速器,能高效处理卷积、池化等神经网络核心运算,大幅降低模型运行时的能耗。这种 “CPU+GPU+DSP” 的协同计算模式,让 QCS6490 在兼顾高性能的同时,适配智能摄像头、AR 眼镜、运动手环等终端设备的功耗需求,成为边缘 AI 部署的理想选择。
与之相对,YOLOv11-pose 系列模型凭借 “单阶段检测 + 姿态估计” 的一体化设计,在众多实际场景中展现出不可替代的应用价值。在智能健身领域,它能实时捕捉用户的肢体关节点,精准分析动作标准度并提供即时反馈,如瑜伽姿势矫正、力量训练动作规范指导等;在工业安全生产中,模型可快速识别工人是否佩戴防护装备、是否处于危险操作姿态,通过联动警报系统预防事故发生;在新零售场景,它能分析顾客的肢体语言与停留区域,辅助商家优化货架布局与营销策略;而在无障碍交互领域,其对人体姿态的精准捕捉,可让残障人士通过手势、肢体动作控制智能设备,提升生活自主性。这些应用场景的共同需求 —— 高实时性(毫秒级响应)与高鲁棒性(抗光照变化、遮挡干扰),正是 YOLOv11-pose 的核心优势所在。
基于此,本次测试旨在深入挖掘 YOLOv11-pose 系列模型与 QCS6490 平台的适配潜力:通过量化分析不同输入分辨率、模型深度下的推理帧率、mAP(平均精度)、内存占用等指标,明确硬件算力与算法需求的匹配关系,为开发者提供从模型选型到参数优化的全流程参考。这不仅能推动 YOLOv11-pose 在边缘设备的规模化落地,更能为 QCS6490 平台在 AIoT 领域的应用拓展提供数据支撑,最终加速人体姿态估计技术从实验室走向产业实践。
|
模型 尺寸640*640
| CPU | NPU QNN2.31 | ||
| FP32 | INT8 | |||
| YOLO11n-pose | 262.1 FPS | 3.82 ms | 5.26 FPS | 190.11 ms |
| YOLO11s-pose | 538.18 FPS | 1.86 ms | 8.76 FPS | 114.16 ms |
| YOLO11m-pose | 1308 FPS | 0.76 ms | 20.99 FPS | 47.64 ms |
| YOLO11l-pose | 1665.97 FPS | 0.60 ms | 25.01 FPS | 39.98 ms |
| YOLO11x-pose | 3380.63 FPS | 0.30 ms | 65.3 FPS | 15.31 ms |
点击链接可以下载YOLOv11系列模型的pt格式,其他模型尺寸可以通过AIMO转换模型,并修改下面参考代码中的model_size测试即可。
python3.10 -m pip install --upgrade pip
pip -V
aidlux@aidlux:~/aidcode$ pip -V
pip 25.1.1 from /home/aidlux/.local/lib/python3.10/site-packages/pip (python 3.10)
pip install ultralytics onnx
方法 1:临时添加环境变量(立即生效)
在终端中执行以下命令,将 ~/.local/bin 添加到当前会话的环境变量中
export PATH="$PATH:$HOME/.local/bin"
yolo --version,若输出版本号(如 0.0.2),则说明命令已生效。方法 2:永久添加环境变量(长期有效)
echo 'export PATH="$PATH:$HOME/.local/bin"' >> ~/.bashrc
source ~/.bashrc # 使修改立即生效
验证:执行 yolo --version,若输出版本号(如 0.0.2),则说明命令已生效。
测试环境中安装yolo版本为8.3.152
![]()
提示:如果遇到用户组权限问题,可以忽悠,因为yolo命令会另外构建临时文件,也可以执行下面命令更改用户组,执行后下面的警告会消失:
sudo chown -R aidlux:aidlux ~/.config/
sudo chown -R aidlux:aidlux ~/.config/Ultralytics
可能遇见的报错如下:
WARNING ⚠️ user config directory '/home/aidlux/.config/Ultralytics' is not writeable, defaulting to '/tmp' or CWD.Alternatively you can define a YOLO_CONFIG_DIR environment variable for this path.
新建一个python文件,命名自定义即可,用于模型转换以及导出:
from ultralytics import YOLO
# 加载同级目录下的.pt模型文件
model = YOLO('yolo11n-pose.pt') # 替换为实际模型文件名
# 导出ONNX配置参数
export_params = {
'format': 'onnx',
'opset': 12, # 推荐算子集版本
'simplify': True, # 启用模型简化
'dynamic': False, # 固定输入尺寸
'imgsz': 640, # 标准输入尺寸
'half': False # 保持FP32精度
}
# 执行转换并保存到同级目录
model.export(**export_params)
执行该程序完成将pt模型导出为onnx模型。
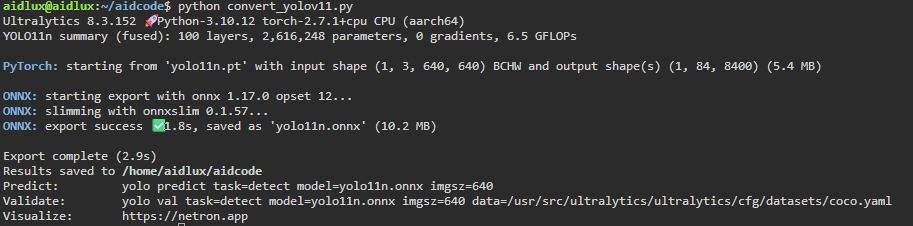
提示:Yolo11s-pose,Yolo11m-pose,Yolo11l-pose,Yolo11x-pose替换代码中Yolo11n-pose即可;

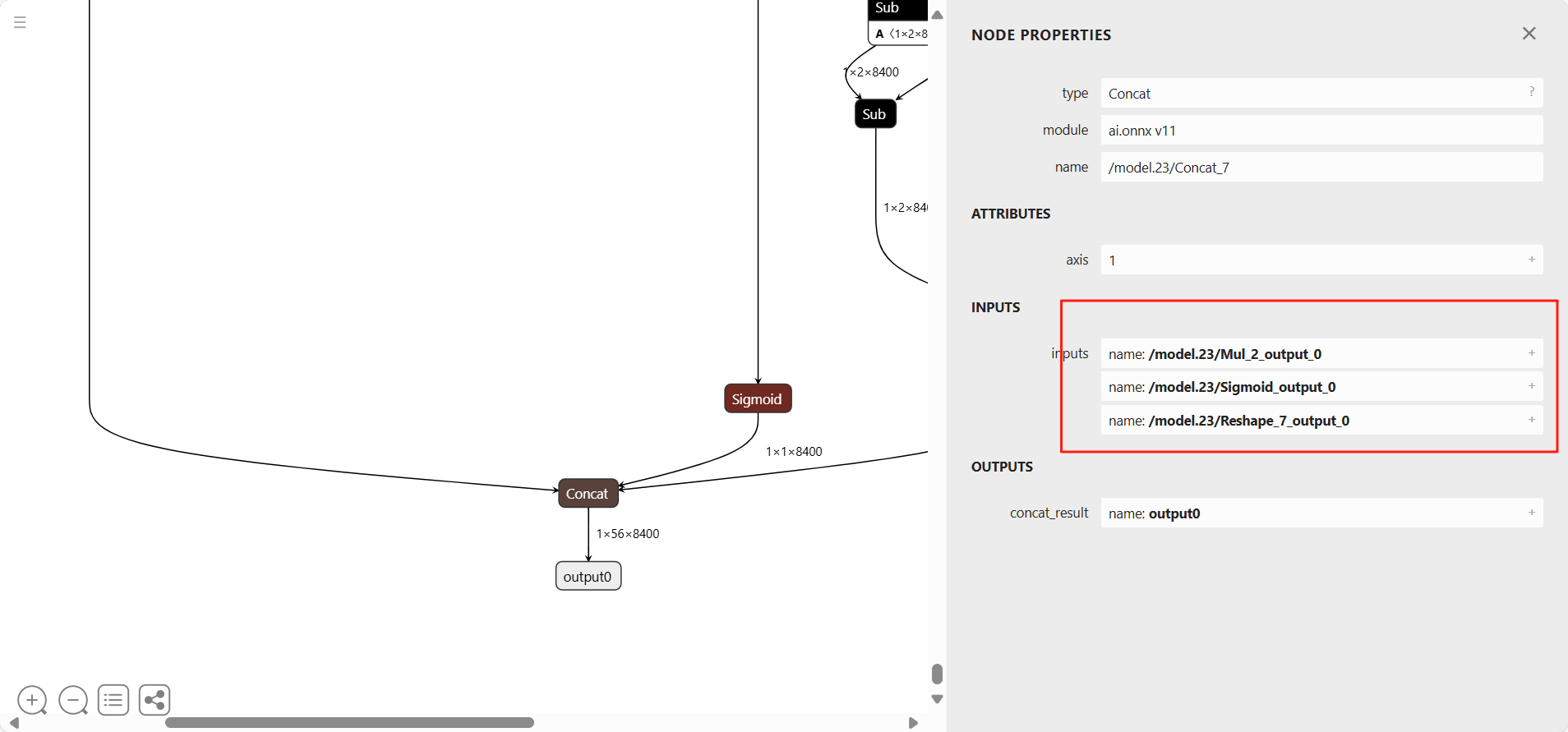
使用Netron工具查看onnx模型结构,选择剪枝位置
/model.23/Mul_2_output_0
/model.23/Sigmoid_output_0
/model.23/Reshape_7_output_0
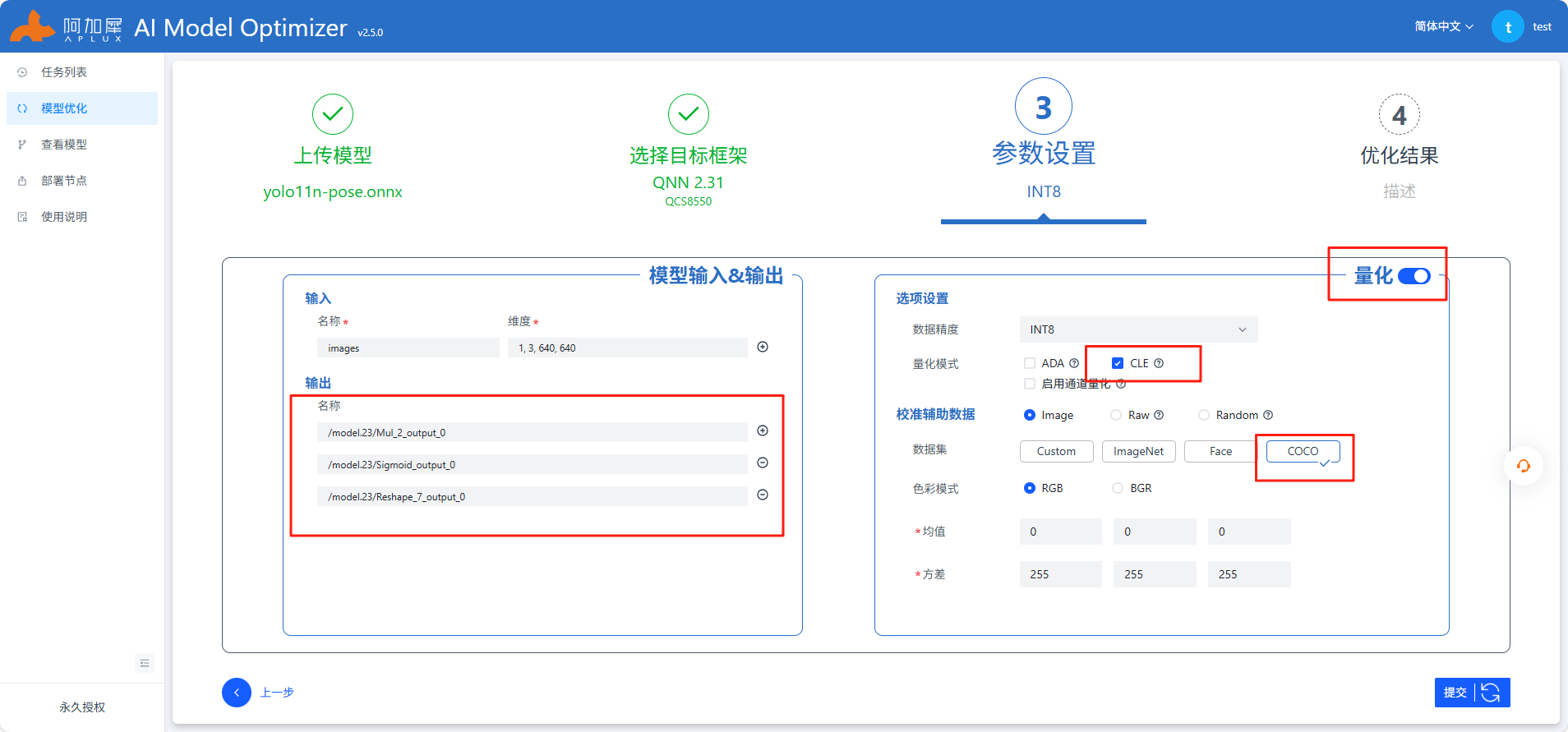
参考上图中红色框部分填写,其他不变,注意开启自动量化功能,AIMO更多操作查看使用说明或参考AIMO平台
# 导入必要的库
import time # 用于计时,评估推理性能
import numpy as np # 用于数值计算和数组操作
import cv2 # 用于图像处理和可视化
import aidlite # 用于模型加载和推理加速(特定硬件加速库)
import argparse # 用于解析命令行参数
# --------------------- COCO‑17 骨架拓扑与颜色配置 ---------------------
# COCO-17数据集的人体关键点连接关系,定义了17个关键点之间的骨架结构
SKELETON = [
(15, 13), (13, 11), (16, 14), (14, 12), (11, 12), # 腿部和胯部连接
(5, 11), (6, 12), (5, 6), (5, 7), (6, 8), # 躯干和肩部连接
(7, 9), (8, 10), (1, 2), (0, 1), (0, 2), # 手臂和头部连接
(1, 3), (2, 4), (3, 5), (4, 6) # 手部和身体连接
]
# 可视化元素的颜色配置(BGR格式,OpenCV默认使用BGR)
COLORS = {
"bbox": (0, 255, 0), # 检测框颜色:绿色
"kpt": (0, 0, 255), # 关键点颜色:红色
"link": (255, 0, 0) # 骨架连接线颜色:蓝色
}
# ----------------------------- 工具函数定义 -----------------------------
def iou_xyxy(box1, box2):
"""
计算两个边界框的交并比(IoU)
输入格式:两个边界框均为[x1, y1, x2, y2],其中(x1,y1)为左上角坐标,(x2,y2)为右下角坐标
返回值:IoU值(0-1之间)
"""
# 计算交集区域的左上角和右下角坐标
xa, ya = max(box1[0], box2[0]), max(box1[1], box2[1]) # 交集左上角
xb, yb = min(box1[2], box2[2]), min(box1[3], box2[3]) # 交集右下角
# 计算交集面积(如果交集区域无效则为0)
inter = max(0, xb - xa) * max(0, yb - ya)
# 计算两个边界框的面积
area1 = (box1[2] - box1[0]) * (box1[3] - box1[1]) # 第一个框面积
area2 = (box2[2] - box2[0]) * (box2[3] - box2[1]) # 第二个框面积
# 计算IoU = 交集面积 / (两个框面积之和 - 交集面积),加1e-6避免除零
return inter / (area1 + area2 - inter + 1e-6)
def nms(dets, confs, iou_thres):
"""
非极大值抑制(NMS)算法,用于去除重叠度过高的检测框
参数:
dets: 边界框列表,格式为[[x1,y1,x2,y2], ...]
confs: 每个边界框对应的置信度列表
iou_thres: IoU阈值,超过此阈值的框会被抑制
返回值:保留的边界框索引列表
"""
# 按置信度从高到低排序,获取排序后的索引
idxs = np.argsort(-confs)
keep = [] # 用于存储保留的框索引
while idxs.size > 0:
# 保留当前置信度最高的框
i = idxs[0]
keep.append(i)
# 如果只剩一个框,直接退出循环
if idxs.size == 1:
break
# 计算当前框与其他所有框的IoU
ious = np.array([iou_xyxy(dets[i], dets[j]) for j in idxs[1:]])
# 只保留IoU小于阈值的框的索引
idxs = idxs[1:][ious < iou_thres]
return keep
def scale_coords(coords, ratio):
"""
将模型输出的归一化坐标(0-640范围)缩放回原始图像尺寸
参数:
coords: 需要缩放的坐标(可以是边界框或关键点坐标)
ratio: 缩放比例(原始图像最长边 / 640)
返回值:缩放后的坐标
"""
return coords * ratio
def draw_pose(img, bbox, kpts, kpt_thr=0.3):
"""
在图像上绘制检测框、关键点和骨架连接线
参数:
img: 原始图像(用于绘制的画布)
bbox: 边界框坐标,格式为[x1,y1,x2,y2]
kpts: 关键点坐标及置信度,格式为[[x1,y1,s1], [x2,y2,s2], ...]
其中s为关键点的置信度分数
kpt_thr: 关键点置信度阈值,低于此值的关键点不绘制
"""
# 绘制边界框
x1, y1, x2, y2 = map(int, bbox) # 将坐标转换为整数
cv2.rectangle(img, (x1, y1), (x2, y2), COLORS["bbox"], 2) # 绘制矩形框
# 绘制关键点
for x, y, s in kpts:
if s < kpt_thr: # 跳过置信度低的关键点
continue
# 绘制红色圆点(半径3,填充)
cv2.circle(img, (int(x), int(y)), 3, COLORS["kpt"], -1)
# 绘制骨架连接线
for a, b in SKELETON:
# 检查两个关键点的置信度是否都高于阈值
if kpts[a][2] < kpt_thr or kpts[b][2] < kpt_thr:
continue
# 获取两个关键点的坐标
xa, ya = int(kpts[a][0]), int(kpts[a][1])
xb, yb = int(kpts[b][0]), int(kpts[b][1])
# 绘制蓝色连接线
cv2.line(img, (xa, ya), (xb, yb), COLORS["link"], 2)
# ----------------------------- 主函数 -----------------------------
def main(args):
"""
主函数:加载模型、处理图像、执行推理、后处理并可视化结果
参数:args为命令行解析得到的参数对象
"""
print("Start image inference ... ...")
size = 640 # 模型输入图像的固定分辨率(宽度和高度均为640)
# ---------- 1. 创建模型配置 & 解释器 ----------
# 创建aidlite配置实例
config = aidlite.Config.create_instance()
if config is None:
print("Create config failed !")
return False
# 配置模型运行参数
config.implement_type = aidlite.ImplementType.TYPE_LOCAL # 本地运行模式
# 根据模型类型选择框架(QNN或SNPE2)
if args.model_type.lower() == "qnn":
config.framework_type = aidlite.FrameworkType.TYPE_QNN231
elif args.model_type.lower() in ("snpe2", "snpe"):
config.framework_type = aidlite.FrameworkType.TYPE_SNPE2
config.accelerate_type = aidlite.AccelerateType.TYPE_DSP # 使用DSP加速
config.is_quantify_model = 1 # 标记为量化模型
# 加载模型文件
model = aidlite.Model.create_instance(args.target_model)
if model is None:
print("Create model failed !")
return False
# 设置模型输入输出形状
input_shapes = [[1, size, size, 3]] # 输入形状:[批次大小, 高度, 宽度, 通道数]
# 输出形状:分别对应关键点、置信度、边界框
output_shapes = [[1, 51, 8400], [1, 1, 8400], [1, 4, 8400]]
model.set_model_properties(
input_shapes,
aidlite.DataType.TYPE_FLOAT32, # 输入数据类型:32位浮点数
output_shapes,
aidlite.DataType.TYPE_FLOAT32 # 输出数据类型:32位浮点数
)
# 创建并初始化解释器
interpreter = aidlite.InterpreterBuilder.build_interpretper_from_model_and_config(model, config)
# 检查解释器初始化和模型加载是否成功
if interpreter is None or interpreter.init() != 0 or interpreter.load_model() != 0:
print("Interpreter init/load failed !")
return False
print("detect model load success!")
# ---------- 2. 读取并预处理图像 ----------
# 读取输入图像
img = cv2.imread(args.image_path)
if img is None:
print("Error: Could not open image file")
return False
h0, w0 = img.shape[:2] # 获取原始图像的高度和宽度
length = max(h0, w0) # 取高度和宽度中的最大值(用于保持宽高比)
ratio = length / size # 计算缩放比例(用于后续将模型输出映射回原图)
# 创建正方形画布(避免拉伸图像),将原图放置在画布左上角
canvas = np.zeros((length, length, 3), np.uint8) # 黑色背景画布
canvas[0:h0, 0:w0] = img # 将原图复制到画布
# 图像预处理:转换颜色空间、调整大小、归一化
img_in = cv2.cvtColor(canvas, cv2.COLOR_BGR2RGB) # BGR转RGB(模型输入要求)
img_in = cv2.resize(img_in, (size, size)) # 调整为模型输入尺寸640x640
img_in = img_in.astype(np.float32) / 255.0 # 归一化到0-1范围
# ---------- 3. 模型预热 ----------
# 执行3次推理预热,避免首次推理耗时过长影响性能评估
for _ in range(3):
interpreter.set_input_tensor(0, img_in.data) # 设置输入张量
interpreter.invoke() # 执行推理
# ---------- 4. 推理性能测试 ----------
invoke_nums = 100 # 测试迭代次数
invoke_times = [] # 存储每次推理耗时(毫秒)
print(f"Running performance test with {invoke_nums} iterations...")
for i in range(invoke_nums):
# 设置输入张量
interpreter.set_input_tensor(0, img_in.data)
# 记录推理开始时间
t1 = time.time()
# 执行推理
result = interpreter.invoke()
# 记录推理结束时间
t2 = time.time()
# 检查推理是否成功
if result != 0:
print("interpreter invoke() failed")
return False
# 计算推理耗时(转换为毫秒)并存储
invoke_time = (t2 - t1) * 1000
invoke_times.append(invoke_time)
# 每10次迭代打印一次进度
if (i + 1) % 10 == 0:
print(f"Completed {i + 1}/{invoke_nums} iterations")
# 计算性能统计指标
mean_invoke_time = np.mean(invoke_times) # 平均耗时
max_invoke_time = np.max(invoke_times) # 最大耗时
min_invoke_time = np.min(invoke_times) # 最小耗时
var_invoke_time = np.var(invoke_times) # 方差(反映耗时稳定性)
fps = 1000 / mean_invoke_time # 计算每秒帧率(FPS)
# 打印性能测试结果
print(f"\nInference {invoke_nums} times:\n"
f"-- mean_invoke_time is {mean_invoke_time:.2f} ms\n"
f"-- max_invoke_time is {max_invoke_time:.2f} ms\n"
f"-- min_invoke_time is {min_invoke_time:.2f} ms\n"
f"-- var_invoke_time is {var_invoke_time:.2f}\n"
f"-- FPS: {fps:.2f}\n")
# ---------- 5. 获取模型输出 ----------
# 提取输出张量并调整形状
# 关键点输出:17个关键点×3(x,y,置信度)=51,共8400个检测框
qnn_local = interpreter.get_output_tensor(0).reshape(1, 51, 8400)
# 置信度输出:每个检测框的置信度,共8400个
qnn_conf = interpreter.get_output_tensor(1).reshape(1, 1, 8400)
# 边界框输出:每个框的4个坐标值(cx,cy,w,h),共8400个
qnn_bbox = interpreter.get_output_tensor(2).reshape(1, 4, 8400)
# 合并输出:将关键点、置信度、边界框合并为一个数组
pred = np.concatenate((qnn_local, qnn_conf, qnn_bbox), axis=1) # 形状变为(1,56,8400)
pred = pred.transpose(0, 2, 1)[0] # 调整为(8400,56),即8400个检测框,每个56维特征
# ---------- 6. 后处理(过滤和筛选有效检测结果) ----------
# 提取每个检测框的置信度(第51列)
confs = pred[:, 51]
# 根据置信度阈值过滤检测框(只保留置信度高于阈值的)
mask = confs > args.conf_thres
if not np.any(mask): # 如果没有符合条件的检测框
print("No objects found.")
interpreter.destory() # 销毁解释器释放资源
return True
# 应用过滤 mask
pred = pred[mask] # 过滤后的检测框特征
confs = confs[mask] # 过滤后的置信度
# 将边界框格式从[cx, cy, w, h]转换为[x1, y1, x2, y2]
b = pred[:, 52:56] # 提取边界框参数(cx, cy, w, h)
boxes_xyxy = np.empty_like(b) # 创建相同形状的数组存储转换后的坐标
boxes_xyxy[:, 0] = b[:, 0] - b[:, 2] / 2 # 计算左上角x
boxes_xyxy[:, 1] = b[:, 1] - b[:, 3] / 2 # 计算左上角y
boxes_xyxy[:, 2] = b[:, 0] + b[:, 2] / 2 # 计算右下角x
boxes_xyxy[:, 3] = b[:, 1] + b[:, 3] / 2 # 计算右下角y
# 应用非极大值抑制(NMS)去除重叠框
keep = nms(boxes_xyxy, confs, args.iou_thres)
boxes_xyxy = boxes_xyxy[keep] # 保留的边界框
# 提取并调整关键点形状:[-1, 51] → [-1, 17, 3](17个关键点,每个含x,y,置信度)
kpts = pred[keep, :51].reshape(-1, 17, 3)
# ---------- 7. 可视化结果 ----------
out_img = img.copy() # 复制原图用于绘制(避免修改原图)
# 遍历每个保留的检测结果,绘制到图像上
for box, kp in zip(boxes_xyxy, kpts):
# 将边界框和关键点坐标缩放回原始图像尺寸
box_scaled = scale_coords(box, ratio)
kp_scaled = scale_coords(kp[:, :2], ratio) # 只缩放x,y坐标
# 合并缩放后的坐标和原始置信度
kp_vis = np.concatenate([kp_scaled, kp[:, 2:3]], axis=1)
# 绘制检测框、关键点和骨架
draw_pose(out_img, box_scaled, kp_vis, kpt_thr=0.25)
# 保存结果图像(注释了显示图像的代码,适合服务器环境)
# cv2.imshow("YOLOv11‑pose Result", out_img)
cv2.imwrite("result1111.jpg", out_img)
print("Result saved to result11.jpg")
# cv2.waitKey(0)
# 销毁解释器,释放资源
interpreter.destory()
return True
# --------------------------- 命令行参数解析 ---------------------------
def parser_args():
"""
解析命令行参数
返回值:解析后的参数对象
"""
parser = argparse.ArgumentParser(description="Run image inference with YOLOv11‑pose")
# 模型文件路径
parser.add_argument('--target_model', type=str,
default='yolov11n_pose/cutoff_yolo11n-pose_qcs8550_w8a8.qnn231.ctx.bin',
help="Path to model binary")
# 输入图像路径
parser.add_argument('--image_path', type=str, default='bus.jpg', help="Input image path")
# 模型框架类型(QNN或SNPE2)
parser.add_argument('--model_type', type=str, default='QNN', help="Backend: QNN / SNPE2")
# 置信度阈值
parser.add_argument('--conf_thres', type=float, default=0.25, help="Confidence threshold")
# NMS的IoU阈值
parser.add_argument('--iou_thres', type=float, default=0.45, help="NMS IoU threshold")
return parser.parse_args()
# ----------------------------- 程序入口 -----------------------------
if __name__ == "__main__":
# 解析命令行参数
args = parser_args()
# 执行主函数
main(args)


