



4,662
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享在物联网与人工智能飞速发展的当下,边缘计算设备需具备强大的计算能力与高效的算法处理能力,以满足实时性、准确性的应用需求。高通 QCS6490 处理器专为高性能边缘计算打造,性能卓越。它集成多达 8 核的高通 Kryo 670 CPU,包含性能强劲、最高频率可达 2.7GHz 的 Cortex-A78 核心,以及运行频率约 1.9GHz 的 Cortex-A55 核心,大小核组合可依据工作负载动态调配资源,实现出色的性能功耗比。其搭载的第 6 代高通 AI Engine,融合高通 Hexagon 处理器与融合 AI 加速器,能在低功耗下实现高达 12 TOPS 的 AI 性能,在 AI 推理任务中表现出色 。同时,QCS6490 支持企业级 Wi-Fi 6 和 Wi-Fi 6E(6GHz 频段),具备多千兆位速度与低延迟特性,满足实时应用的高速数据传输需求 。在视频与图形处理上,集成的 Adreno GPU643 可支持 4K 视频录制与流媒体传输(30/60fps),为高分辨率视频处理提供保障 。
而 YOLOv7 系列模型作为目标检测领域的佼佼者,在 5 FPS 到 160 FPS 的速度区间内,其速度和精度超越众多已知目标检测器 。该系列模型应用广泛,在视频监控领域,可实时检测与跟踪人员、车辆等目标,保障公共安全;在自动驾驶场景里,助力车辆环境感知系统,精准检测行人、车辆与交通标志,为安全驾驶提供支撑;于工业自动化范畴,能够识别产品缺陷、定位组件,提升生产效率;在零售分析方面,可用于跟踪顾客行为、管理货品 。
鉴于高通 QCS6490 平台强大的性能以及 YOLOv7 系列模型广泛的应用前景,对两者结合的性能测试显得尤为必要。本次测试旨在深入探究在高通 QCS6490 平台上运行 YOLOv7 系列模型时,模型的检测精度、推理速度等关键性能指标,期望为相关领域的开发者与企业提供有价值的参考,助力其在边缘设备上更好地部署与优化基于 YOLOv7 的应用,充分发挥两者优势,推动相关行业智能化发展 。
|
模型 尺寸640*640
| CPU | NPU QNN2.31 | ||
| FP32 | INT8 | |||
| YOLOv7 | 1970.48 ms | 0.51 FPS | 22.92 ms | 43.63 FPS |
| YOLOv7x | 3516.18 ms | 0.28 FPS | 42.91 ms | 23.30 FPS |
点击链接可以下载YOLOv7系列模型的pt格式,其他模型尺寸可以通过AIMO转换模型,并修改下面参考代码中的model_size测试即可。
原模型文件下载链接:
https://github.com/WongKinYiu/yolov7
python3.10 -m pip install --upgrade pip
pip -V
aidlux@aidlux:~/aidcode$ pip -V
pip 25.1.1 from /home/aidlux/.local/lib/python3.10/site-packages/pip (python 3.10)
pip install ultralytics onnx
方法 1:临时添加环境变量(立即生效)
在终端中执行以下命令,将 ~/.local/bin 添加到当前会话的环境变量中
export PATH="$PATH:$HOME/.local/bin"
yolo --version,若输出版本号(如 0.0.2),则说明命令已生效。方法 2:永久添加环境变量(长期有效)
echo 'export PATH="$PATH:$HOME/.local/bin"' >> ~/.bashrc
source ~/.bashrc # 使修改立即生效
验证:执行 yolo --version,若输出版本号(如 0.0.2),则说明命令已生效。
测试环境中安装yolo版本为8.3.152
![]()
提示:如果遇到用户组权限问题,可以忽悠,因为yolo命令会另外构建临时文件,也可以执行下面命令更改用户组,执行后下面的警告会消失:
sudo chown -R aidlux:aidlux ~/.config/
sudo chown -R aidlux:aidlux ~/.config/Ultralytics
可能遇见的报错如下:
WARNING ⚠️ user config directory '/home/aidlux/.config/Ultralytics' is not writeable, defaulting to '/tmp' or CWD.Alternatively you can define a YOLO_CONFIG_DIR environment variable for this path.
新建一个python文件,命名自定义即可,用于模型转换以及导出:
from ultralytics import YOLO
# 加载同级目录下的.pt模型文件
model = YOLO('yolov7.pt') # 替换为实际模型文件名
# 导出ONNX配置参数
export_params = {
'format': 'onnx',
'opset': 12, # 推荐算子集版本
'simplify': True, # 启用模型简化
'dynamic': False, # 固定输入尺寸
'imgsz': 640, # 标准输入尺寸
'half': False # 保持FP32精度
}
# 执行转换并保存到同级目录
model.export(**export_params)
执行该程序完成将pt模型导出为onnx模型。
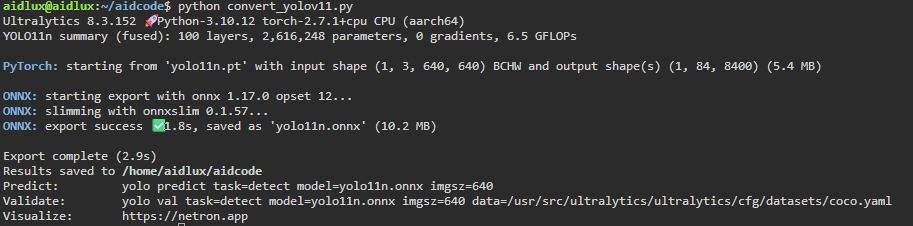
提示:Yolo7x替换代码中Yolov7即可;

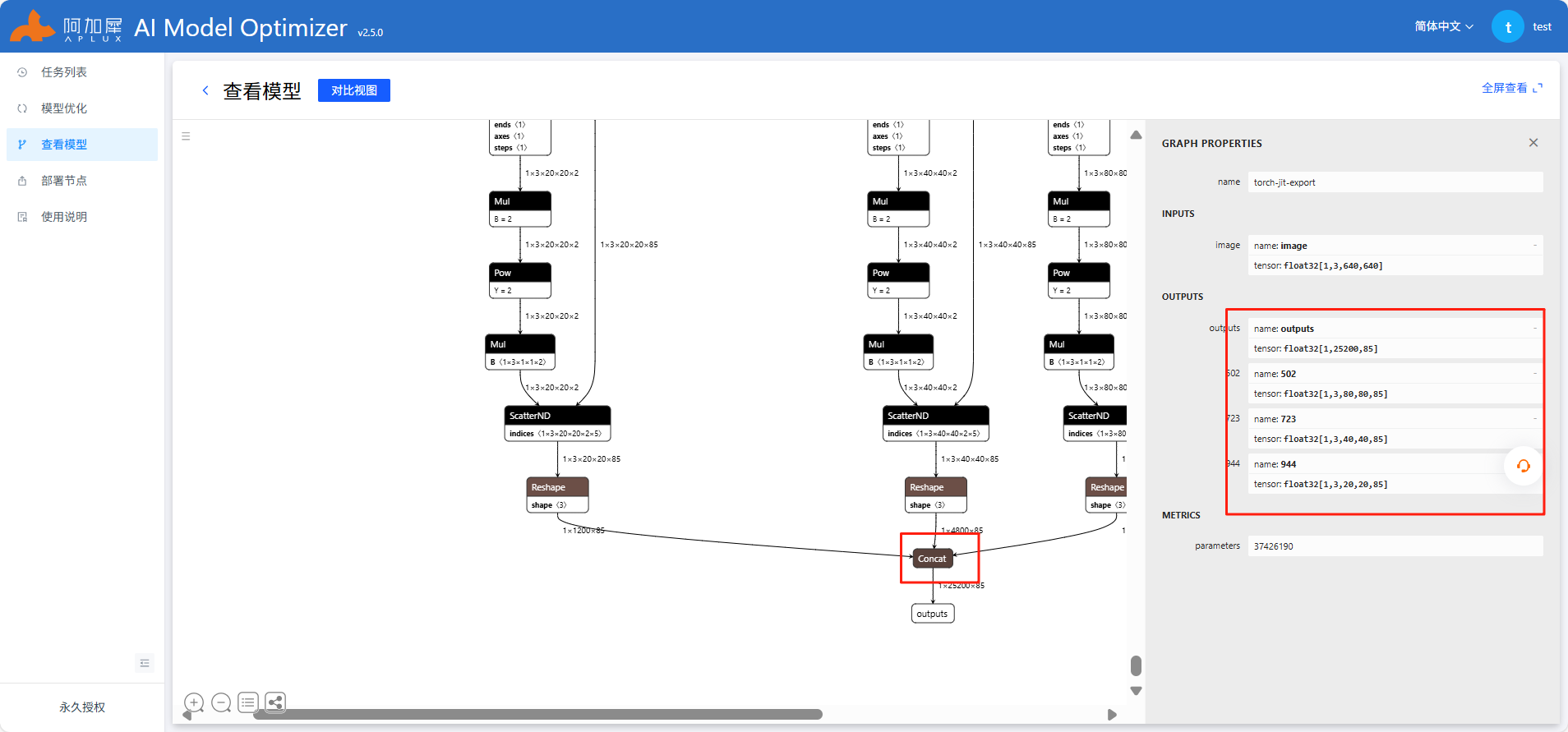
使用Netron工具查看onnx模型结构,选择剪枝位置
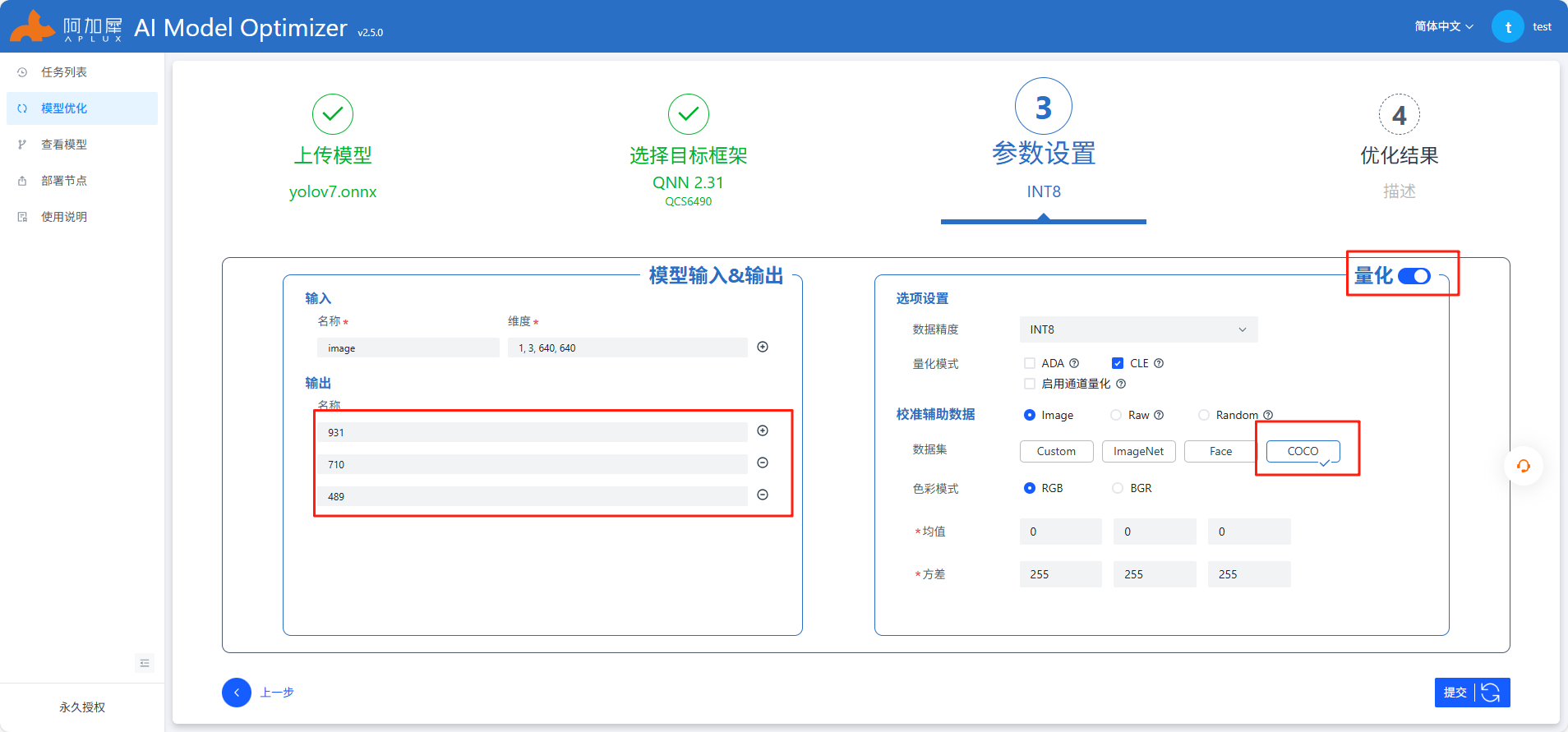
参考上图中红色框部分填写,其他不变,注意开启自动量化功能,AIMO更多操作查看使用说明或参考AIMO平台
import time
import numpy as np
import cv2
from utils import * # 导入工具函数(包含图像预处理、后处理等)
import os
import aidlite # 导入aidlite推理框架库
import argparse # 用于解析命令行参数
import onnxruntime
from yolov7_head import Detect # 导入YOLOv7的检测头处理类
def main(args):
print("Start main ... ...")
# 初始化配置
# aidlite.set_log_level(aidlite.LogLevel.INFO) # 设置日志级别为INFO(注释未启用)
# aidlite.log_to_stderr() # 日志输出到标准错误流(注释未启用)
# 打印库版本信息(注释未启用)
# print(f"Aidlite library version : {aidlite.get_library_version()}")
# print(f"Aidlite python library version : {aidlite.get_py_library_version()}")
# 创建aidlite配置实例
config = aidlite.Config.create_instance()
if config is None:
print("Create config failed !")
return False
# 配置运行模式为本地模式
config.implement_type = aidlite.ImplementType.TYPE_LOCAL
# 根据模型类型设置框架类型
if args.model_type.lower()=="qnn":
config.framework_type = aidlite.FrameworkType.TYPE_QNN # QNN框架
elif args.model_type.lower()=="snpe2" or args.model_type.lower()=="snpe":
config.framework_type = aidlite.FrameworkType.TYPE_SNPE2 # SNPE框架
# 配置加速类型为DSP(数字信号处理器)
config.accelerate_type = aidlite.AccelerateType.TYPE_DSP
# 标记为量化模型
config.is_quantify_model = 1
# 创建模型实例,加载目标模型
model = aidlite.Model.create_instance(args.target_model)
if model is None:
print("Create model failed !")
return False
# 模型输入尺寸(YOLOv7常用640x640)
size = 640
# 定义输入输出形状
# 输入:[批次大小, 高, 宽, 通道数]
input_shapes = [[1, size, size, 3]]
# 输出:3个尺度的特征图(分别对应8x、16x、32x下采样)
# 每个输出形状为[批次, 特征图高, 特征图宽, (类别数+5)*3],其中5为x,y,w,h,confidence
output_shapes = [
[1, int(size/8), int(size/8), (args.cls_num+5)*3],
[1, int(size/16), int(size/16), (args.cls_num+5)*3],
[1, int(size/32), int(size/32), (args.cls_num+5)*3]
]
# YOLOv7的锚点框(anchors),每个尺度3个锚点
anchors = [
[12,16, 19,36, 40,28], # 小目标锚点(8x下采样)
[36,75, 76,55, 72,146], # 中目标锚点(16x下采样)
[142,110, 192,243, 459,401] # 大目标锚点(32x下采样)
]
# 下采样步长
stride = [8, 16, 32]
# 初始化YOLOv7检测头
yolov7_head = Detect(args.cls_num, anchors, stride, size)
# 设置模型输入输出属性:输入输出形状和数据类型(float32)
model.set_model_properties(
input_shapes,
aidlite.DataType.TYPE_FLOAT32,
output_shapes,
aidlite.DataType.TYPE_FLOAT32
)
# 根据模型和配置构建解释器(推理执行器)
interpreter = aidlite.InterpreterBuilder.build_interpretper_from_model_and_config(model, config)
if interpreter is None:
print("build_interpretper_from_model_and_config failed !")
return None
# 初始化解释器
result = interpreter.init()
if result != 0:
print(f"interpreter init failed !")
return False
# 加载模型到解释器
result = interpreter.load_model()
if result != 0:
print("interpreter load model failed !")
return False
print("detect model load success!")
# 图像预处理
frame = cv2.imread(args.imgs) # 读取输入图像
# 图像等比缩放至目标尺寸(640x640),并进行归一化(除以255)
img_input = preprocess_img(
frame,
target_shape=(size, size),
div_num=255,
means=None,
stds=None
)
# 推理性能测试(多次调用取统计值)
invoke_time = [] # 存储每次推理耗时
for i in range(args.invoke_nums):
# 设置输入张量(第0个输入)
result = interpreter.set_input_tensor(0, img_input.data)
if result != 0:
print("interpreter set_input_tensor() failed")
# 记录推理开始时间
t1 = time.time()
# 执行推理
result = interpreter.invoke()
# 计算推理耗时(毫秒)并记录
cost_time = (time.time() - t1) * 1000
invoke_time.append(cost_time)
if result != 0:
print("interpreter invoke() failed")
# 获取三个尺度的输出张量
stride8 = interpreter.get_output_tensor(0) # 8x下采样输出
stride16 = interpreter.get_output_tensor(1) # 16x下采样输出
stride32 = interpreter.get_output_tensor(2) # 32x下采样输出
# 销毁解释器,释放资源
result = interpreter.destory()
# 统计推理时间
max_invoke_time = max(invoke_time) # 最大耗时
min_invoke_time = min(invoke_time) # 最小耗时
mean_invoke_time = sum(invoke_time) / args.invoke_nums # 平均耗时
var_invoketime = np.var(invoke_time) # 方差(反映耗时稳定性)
print("=======================================")
print(f"QNN inference {args.invoke_nums} times :\n"
f" --mean_invoke_time is {mean_invoke_time} \n"
f" --max_invoke_time is {max_invoke_time} \n"
f" --min_invoke_time is {min_invoke_time} \n"
f" --var_invoketime is {var_invoketime}")
print("=======================================")
# 后处理:解析模型输出得到检测结果
# 调整输出形状并转置(适应YOLOv7_head处理格式)
validCount0 = stride8.reshape(*output_shapes[0]).transpose(0, 3, 1, 2)
validCount1 = stride16.reshape(*output_shapes[1]).transpose(0, 3, 1, 2)
validCount2 = stride32.reshape(*output_shapes[2]).transpose(0, 3, 1, 2)
# 通过YOLOv7检测头处理输出,得到预测结果
pred = yolov7_head([validCount0, validCount1, validCount2])
# 检测结果后处理:坐标转换(从640x640恢复到原图尺寸)、置信度过滤、NMS(非极大值抑制)
det_pred = detect_postprocess(
pred,
frame.shape,
[size, size, 3],
conf_thres=0.5, # 置信度阈值
iou_thres=0.45 # IOU阈值(用于NMS)
)
# 在原图上绘制检测结果(边界框、类别、置信度)
res_img = draw_detect_res(frame, det_pred)
# 保存绘制结果的图像
cv2.imwrite("./python/bus_result.jpg", res_img)
print("=======================================")
def parser_args():
"""解析命令行参数"""
parser = argparse.ArgumentParser(description="Run model benchmarks")
parser.add_argument(
'--target_model',
type=str,
default='./models/cutoff_yolov7_w8a16.qnn216.ctx.bin',
help="inference model path" # 推理模型路径
)
parser.add_argument(
'--imgs',
type=str,
default='./python/bus.jpg',
help="Predict images path" # 待预测图像路径
)
parser.add_argument(
'--cls_num',
type=int,
default=80,
help="The number of targets detected" # 检测目标的类别数量
)
parser.add_argument(
'--invoke_nums',
type=int,
default=10,
help="Inference nums" # 推理次数(用于性能统计)
)
parser.add_argument(
'--model_type',
type=str,
default='QNN',
help="run backend (QNN/SNPE)" # 运行后端框架类型
)
args = parser.parse_args()
return args
if __name__ == "__main__":
# 解析命令行参数
args = parser_args()
# 执行主函数
main(args)
'''
YOLOV7 Detect 层:负责对模型输出的特征图进行解码,生成最终的检测框坐标和类别概率
author: xiaohe
'''
import numpy as np
class Detect():
# YOLOv5 Detect head for detection models(YOLOv7与YOLOv5检测头结构相似)
def __init__(self, nc=80, anchors=(), stride=[], image_size=640): # detection layer
super().__init__()
self.nc = nc # 类别数量(默认COCO数据集80类)
self.no = nc + 5 # 每个锚点的输出维度:类别数 + 5(x,y,w,h,置信度)
self.stride = stride # 下采样步长列表(如[8,16,32])
self.nl = len(anchors) # 检测层数(与下采样步长数量一致)
self.na = len(anchors[0]) // 2 # 每层的锚点数量(每个锚点由两个值组成,故除以2)
self.grid, self.anchor_grid = [0]*self.nl, [0]*self.nl # 网格坐标和锚点网格
# 将锚点转换为numpy数组并重塑形状:[层数, 锚点数, 2]
self.anchors = np.array(anchors, dtype=np.float32).reshape(self.nl, -1, 2)
# 计算基础尺度(以8倍下采样的特征图尺寸为基准)
base_scale = image_size // 8
# 为每个检测层生成网格坐标和锚点网格
for i in range(self.nl):
# 特征图尺寸随下采样倍数增加而减半(8x→16x→32x)
self.grid[i], self.anchor_grid[i] = self._make_grid(
base_scale // (2**i),
base_scale // (2**i),
i
)
def _make_grid(self, nx=20, ny=20, i=0):
"""
生成特征图的网格坐标和锚点网格
nx, ny: 特征图的宽和高(网格数量)
i: 检测层索引
"""
# 生成0到nx-1、0到ny-1的坐标数组
y, x = np.arange(ny, dtype=np.float32), np.arange(nx, dtype=np.float32)
# 生成网格坐标(xv为x方向网格,yv为y方向网格)
yv, xv = np.meshgrid(y, x)
yv, xv = yv.T, xv.T # 转置以匹配特征图形状
# 堆叠x和y坐标,形成网格坐标矩阵 [ny, nx, 2]
grid = np.stack((xv, yv), 2)
# 扩展维度以匹配锚点数量:[1, 锚点数, ny, nx, 2],并偏移-0.5(调整坐标原点)
grid = grid[np.newaxis, np.newaxis, ...]
grid = np.repeat(grid, self.na, axis=1) - 0.5
# 生成锚点网格:将当前层的锚点扩展到与特征图网格匹配的形状
anchor_grid = self.anchors[i].reshape((1, self.na, 1, 1, 2)) # [1, 锚点数, 1, 1, 2]
anchor_grid = np.repeat(anchor_grid, repeats=ny, axis=2) # 沿y方向扩展
anchor_grid = np.repeat(anchor_grid, repeats=nx, axis=3) # 沿x方向扩展
return grid, anchor_grid
def sigmoid(self, arr):
"""sigmoid激活函数:将输出映射到0-1范围(用于置信度和类别概率)"""
return 1 / (1 + np.exp(-arr))
def __call__(self, x):
"""
对模型输出的特征图进行解码
x: 模型输出的特征图列表,每个元素对应一个检测层的输出
return: 解码后的检测结果,形状为[批次, 总锚点数, 5+类别数]
"""
z = [] # 存储所有检测层的解码结果
for i in range(self.nl):
bs, _, ny, nx = x[i].shape # 解析特征图形状:[批次, 通道, 高, 宽]
# 重塑特征图形状并转置:[批次, 锚点数, 高, 宽, 输出维度]
x[i] = x[i].reshape(bs, self.na, self.no, ny, nx).transpose(0, 1, 3, 4, 2)
# 对输出进行sigmoid激活(将所有值映射到0-1)
y = self.sigmoid(x[i])
# 计算边界框中心坐标(x,y):
# 公式:(sigmoid输出 * 2 + 网格坐标) * 下采样步长
y[..., 0:2] = (y[..., 0:2] * 2. + self.grid[i]) * self.stride[i]
# 计算边界框宽高(w,h):
# 公式:(sigmoid输出 * 2)^2 * 锚点网格
y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i]
# 将当前层的所有锚点结果展平并添加到列表
z.append(y.reshape(bs, self.na * nx * ny, self.no))
# 拼接所有检测层的结果,得到最终检测输出
return np.concatenate(z, 1)

