



4,662
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享在当今智能化时代,边缘设备的性能与应用拓展备受关注。高通 QCS6490 处理器专为高性能边缘计算打造,成为行业焦点。它集成多达 8 核的高通 Kryo 670 CPU,其中 4 个高性能 Cortex - A78 核心最高频率达 2.7GHz,4 个 Cortex - A55 核心维持高效能与低功耗平衡,可根据负载动态分配资源,实现卓越的性能功耗比。第 6 代高通 AI Engine 赋予其强大 AI 处理能力,融合 Hexagon 处理器与 AI 加速器,最高可达 12 TOPS 的运算性能,能在低功耗下高效完成各类 AI 推理任务。
与此同时,YOLOv11 - cls 系列模型在计算机视觉领域表现卓越,在无人机与机器人应用场景中优势显著。在无人机领域,其针对航拍场景优化,多尺度特征融合增强小目标检测能力,角度自适应机制提升不同拍摄角度的识别准确率,轻量化设计缩小模型体积、提升推理速度,更适合无人机边缘设备部署。在智慧城市管理中,可用于交通流量监控与分析、违章建筑识别;农业监测方面,能实现作物长势评估、病虫害早期识别。对于机器人,YOLOv11 - cls 助力其更好地感知和导航环境,在工业巡检中,可用于电力线路巡查、油气管道监测,提升机器人自主作业能力。
本次针对高通 QCS6490 平台上 YOLOv11 - cls 系列模型的性能测试,为相关领域的技术优化与应用拓展提供有力依据 。
|
模型 尺寸640*640
| CPU | NPU QNN2.31 | ||
| FP32 | INT8 | |||
| YOLO11n-cls | 538.82 ms | 1.86 FPS | 6.03 ms | 165.84 FPS |
| YOLO11s-cls | 343.45 ms | 2.91 FPS | 8.26 ms | 121.07 FPS |
| YOLO11m-cls | 741.52 ms | 1.35 FPS | 23.97 ms | 41.72 FPS |
| YOLO11l-cls | 925.53 ms | 1.08 FPS | 27.74 ms | 36.05 FPS |
| YOLO11x-cls | 1818.27 ms | 0.55 FPS | 54.33 ms | 18.41 FPS |
点击链接可以下载YOLOv11系列模型的pt格式,其他模型尺寸可以通过AIMO转换模型,并修改下面参考代码中的model_size测试即可。
python3.10 -m pip install --upgrade pip
pip -V
aidlux@aidlux:~/aidcode$ pip -V
pip 25.1.1 from /home/aidlux/.local/lib/python3.10/site-packages/pip (python 3.10)
pip install ultralytics onnx
方法 1:临时添加环境变量(立即生效)
在终端中执行以下命令,将 ~/.local/bin 添加到当前会话的环境变量中
export PATH="$PATH:$HOME/.local/bin"
yolo --version,若输出版本号(如 0.0.2),则说明命令已生效。方法 2:永久添加环境变量(长期有效)
echo 'export PATH="$PATH:$HOME/.local/bin"' >> ~/.bashrc
source ~/.bashrc # 使修改立即生效
验证:执行 yolo --version,若输出版本号(如 0.0.2),则说明命令已生效。
测试环境中安装yolo版本为8.3.152
![]()
提示:如果遇到用户组权限问题,可以忽悠,因为yolo命令会另外构建临时文件,也可以执行下面命令更改用户组,执行后下面的警告会消失:
sudo chown -R aidlux:aidlux ~/.config/
sudo chown -R aidlux:aidlux ~/.config/Ultralytics
可能遇见的报错如下:
WARNING ⚠️ user config directory '/home/aidlux/.config/Ultralytics' is not writeable, defaulting to '/tmp' or CWD.Alternatively you can define a YOLO_CONFIG_DIR environment variable for this path.
新建一个python文件,命名自定义即可,用于模型转换以及导出:
from ultralytics import YOLO
# 加载同级目录下的.pt模型文件
model = YOLO('yolo11n-cls.pt') # 替换为实际模型文件名
# 导出ONNX配置参数
export_params = {
'format': 'onnx',
'opset': 12, # 推荐算子集版本
'simplify': True, # 启用模型简化
'dynamic': False, # 固定输入尺寸
'imgsz': 640, # 标准输入尺寸
'half': False # 保持FP32精度
}
# 执行转换并保存到同级目录
model.export(**export_params)
执行该程序完成将pt模型导出为onnx模型。
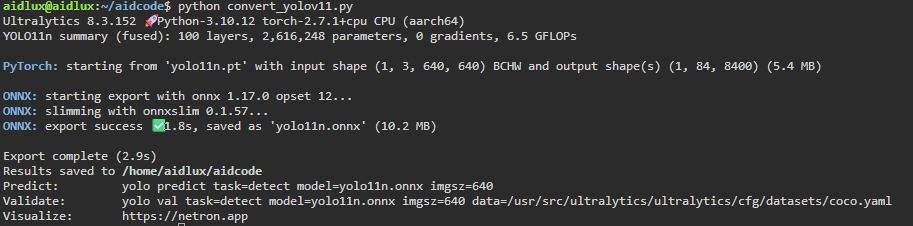
提示:Yolo11s-cls,Yolo11m-cls,Yolo11l-cls,Yolo11x-cls替换代码中Yolo11n-cls即可;

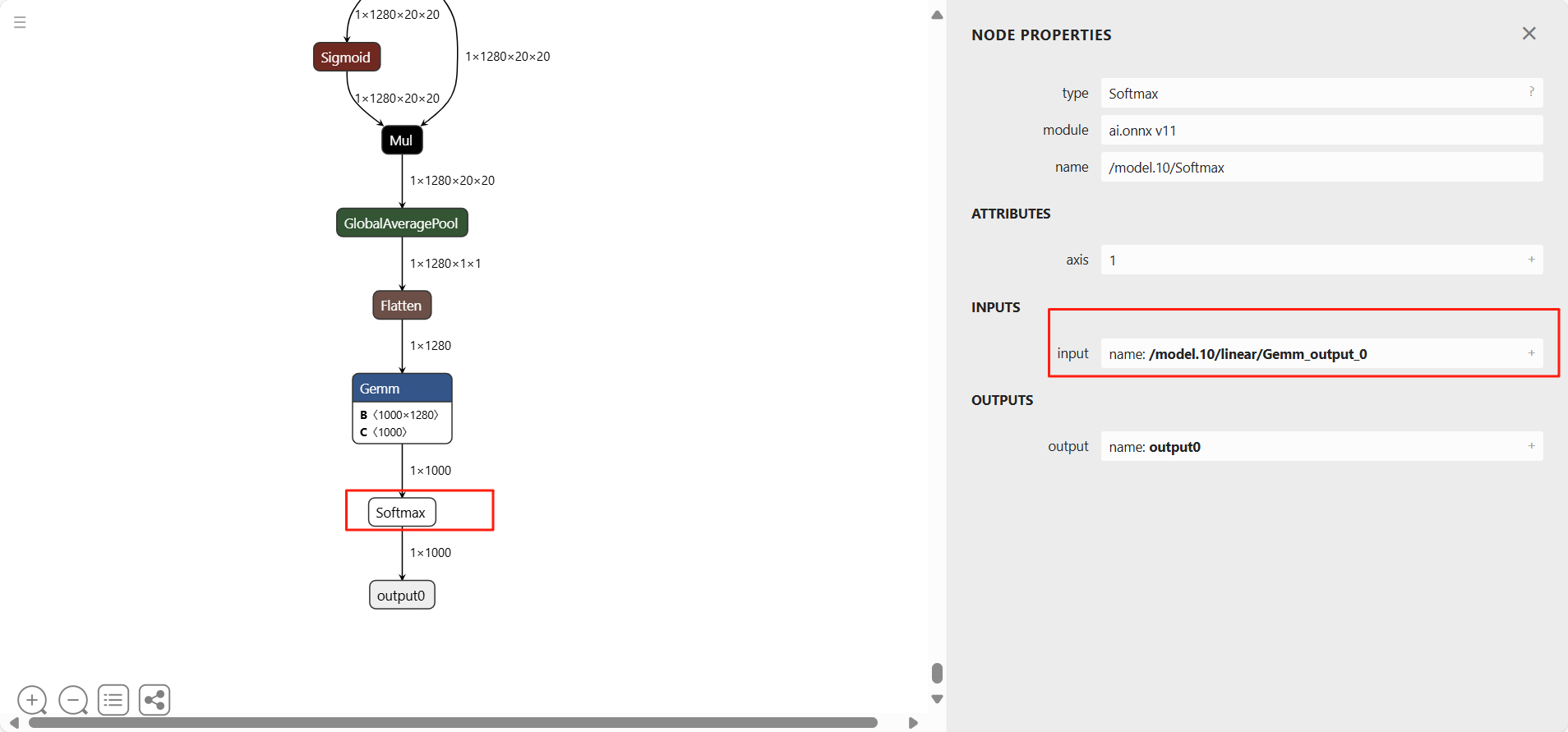
使用Netron工具查看onnx模型结构,选择剪枝位置
/model.10/linear/Gemm_output_0
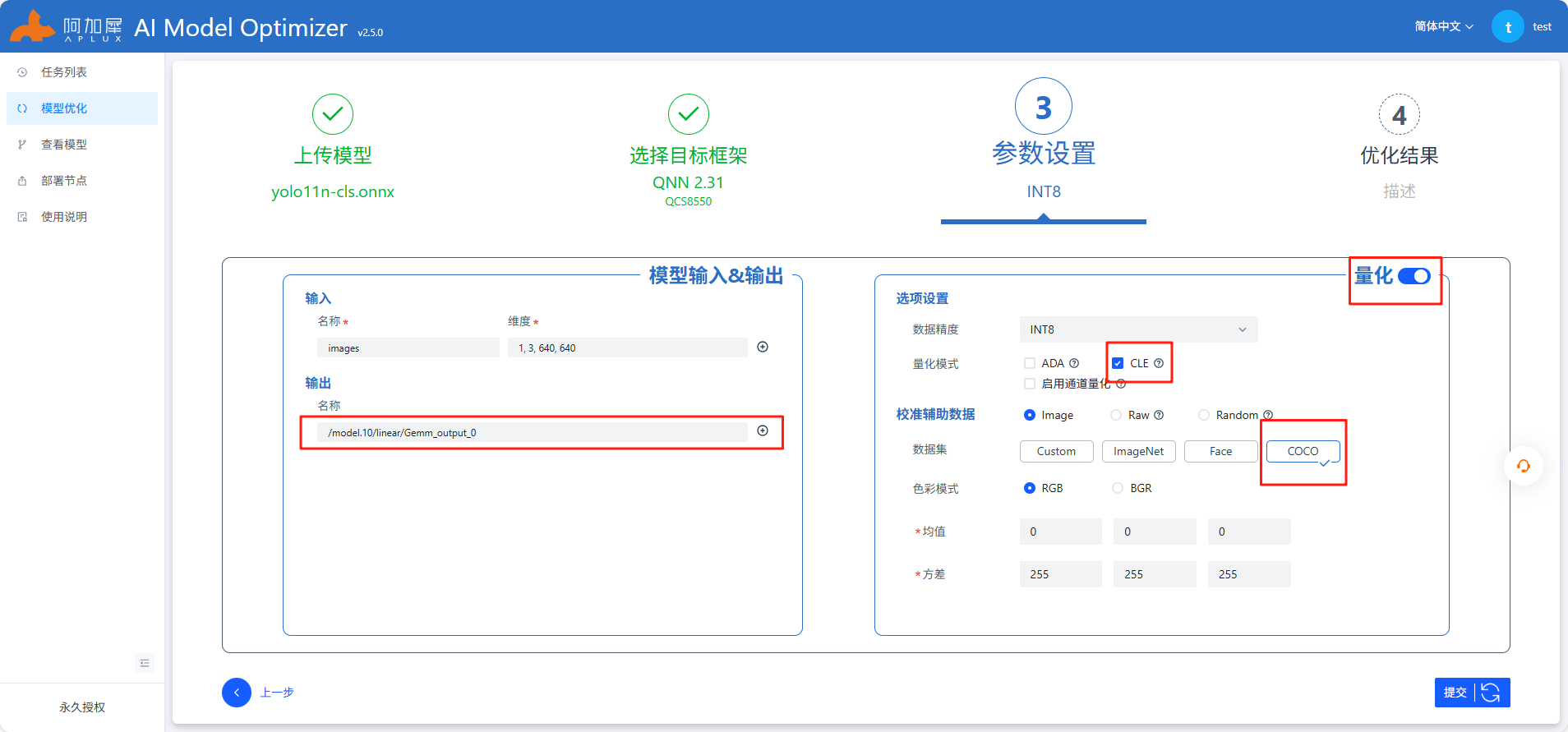
参考上图中红色框部分填写,其他不变,注意开启自动量化功能,AIMO更多操作查看使用说明或参考AIMO平台
import time
import numpy as np
import cv2
import os
import aidlite
import argparse
from pathlib import Path
# ---------- 新增辅助函数 ----------
def load_class_names(names_path: str):
"""
从 txt 文件或逗号分隔字符串载入类别名称
参数:
names_path: 类别名称文件路径或逗号分隔字符串
返回:
类别名称列表
"""
if not names_path:
# 默认返回 1000 个占位类别名
return [f"class_{i}" for i in range(1000)]
if os.path.isfile(names_path):
# 从文件读取类别名
with open(names_path, 'r', encoding='utf-8') as f:
names = [l.strip() for l in f.readlines() if l.strip()]
else: # 支持直接传逗号分隔字符串
names = [x.strip() for x in names_path.split(',') if x.strip()]
return names
def visualize_and_save(image_bgr, label, score, save_path):
"""
在图片左上角绘制分类结果并写入文件
参数:
image_bgr: BGR格式图像数据
label: 预测类别标签
score: 预测置信度分数
save_path: 保存路径
"""
# 格式化显示文本,保留一位小数
txt = f"{label}: {score*100:.1f}%"
# 设置字体
font = cv2.FONT_HERSHEY_SIMPLEX
# 在图像上绘制文本:位置(10,30),绿色,线宽2,抗锯齿
cv2.putText(image_bgr, txt, (10, 30), font, 1.0, (0, 255, 0), 2, cv2.LINE_AA)
# 保存图像并打印提示
cv2.imwrite(str(save_path), image_bgr)
print(f"预测结果已保存到: {save_path}")
# ---------- 主函数 ----------
def main(args):
'''
主处理流程:
1. 初始化模型和配置
2. 读取和预处理图像
3. 执行模型推理
4. 可视化并保存结果
'''
print("Start image inference ... ...")
size = 640 # 模型输入尺寸
# ---------- 1. 初始化模型 ----------
# 创建配置实例
config = aidlite.Config.create_instance()
if config is None:
print("Create config failed !")
return False
# 设置实现类型为本地实现
config.implement_type = aidlite.ImplementType.TYPE_LOCAL
# 根据命令行参数设置框架类型
if args.model_type.lower() == "qnn":
config.framework_type = aidlite.FrameworkType.TYPE_QNN231
elif args.model_type.lower() in ("snpe2", "snpe"):
config.framework_type = aidlite.FrameworkType.TYPE_SNPE2
# 设置加速类型为DSP
config.accelerate_type = aidlite.AccelerateType.TYPE_DSP
# 设置为量化模型
config.is_quantify_model = 1
# 创建模型实例
model = aidlite.Model.create_instance(args.target_model)
if model is None:
print("Create model failed !")
return False
# 定义输入输出张量形状
input_shapes = [[1, size, size, 3]] # 输入: [批次, 高度, 宽度, 通道]
output_shapes = [[1, args.num_classes]] # 输出: [批次, 类别数]
# 设置模型属性:输入输出形状和数据类型
model.set_model_properties(
input_shapes, aidlite.DataType.TYPE_FLOAT32,
output_shapes, aidlite.DataType.TYPE_FLOAT32)
# 构建解释器并初始化模型
interpreter = aidlite.InterpreterBuilder.build_interpretper_from_model_and_config(model, config)
if interpreter is None or interpreter.init() != 0 or interpreter.load_model() != 0:
print("Interpreter build/init/load 失败")
return False
print("Model loaded successfully ✔")
# ---------- 2. 读取 & 预处理 ----------
# 读取图像
img_bgr = cv2.imread(args.image_path)
if img_bgr is None:
print("Error: Could not open image file")
return False
# 获取图像尺寸
h, w, _ = img_bgr.shape
# 计算最长边,用于等比例缩放
length = max(h, w)
# 计算缩放比例
scale = length / size
# 创建一个正方形画布,用于保持图像比例
canvas = np.zeros((length, length, 3), dtype=np.uint8)
# 将图像放置在画布左上角
canvas[0:h, 0:w] = img_bgr
# BGR转RGB(模型通常需要RGB输入)
img_rgb = cv2.cvtColor(canvas, cv2.COLOR_BGR2RGB)
# 调整大小为模型输入尺寸
img_rgb = cv2.resize(img_rgb, (size, size))
# 归一化处理:将像素值从0-255缩放到0-1
img_norm = (img_rgb.astype(np.float32) - 0) / 255.0 # 归一化到 0~1
img_input = img_norm # HWC格式
# ---------- 3. 推理 & 性能测试 ----------
# 预热:消除首次运行的额外开销
warmup_iters = 5
for _ in range(warmup_iters):
interpreter.set_input_tensor(0, img_input.data)
interpreter.invoke()
# 正式测试:多次推理计算性能指标
invoke_nums, invoke_times = 20, []
for i in range(invoke_nums):
t1 = time.time()
interpreter.set_input_tensor(0, img_input.data)
interpreter.invoke()
t2 = time.time()
invoke_times.append((t2 - t1) * 1000) # 转换为毫秒
# 计算统计指标
mean_invoke_time = np.mean(invoke_times) # 平均推理时间
max_invoke_time = np.max(invoke_times) # 最大推理时间
min_invoke_time = np.min(invoke_times) # 最小推理时间
var_invoke_time = np.var(invoke_times) # 推理时间方差
fps = 1000 / mean_invoke_time # 计算FPS(每秒帧数)
# 打印性能结果
print(f"\nInference {invoke_nums} times:\n"
f"-- mean_invoke_time is {mean_invoke_time:.2f} ms\n"
f"-- max_invoke_time is {max_invoke_time:.2f} ms\n"
f"-- min_invoke_time is {min_invoke_time:.2f} ms\n"
f"-- var_invoke_time is {var_invoke_time:.2f}\n"
f"-- FPS: {fps:.2f}\n")
# 获取最后一次输出并调整形状
logits = interpreter.get_output_tensor(0).reshape(*output_shapes) # (1, num_classes)
probs = logits[0] # (num_classes,)
# ---------- 4. 结果后处理 ----------
# 获取置信度最高的前5个类别索引(按降序排列)
top5_idx = probs.argsort()[-5:][::-1]
# 加载类别名称
class_names = load_class_names(args.class_names)
# 获取置信度最高的类别
top1 = top5_idx[0]
# 打印Top-5预测结果
print("\nTop‑5 结果:")
for rank, idx in enumerate(top5_idx, 1):
print(f"{rank}. {class_names[idx]} {probs[idx]*100:.2f}%")
# ---------- 5. 可视化并保存 ----------
# 创建保存目录
save_dir = Path(args.save_dir)
save_dir.mkdir(parents=True, exist_ok=True)
# 生成保存文件名
save_path = save_dir / f"pred_{Path(args.image_path).stem}.jpg"
# 在原图上绘制预测结果并保存
visualize_and_save(img_bgr, class_names[top1], probs[top1], save_path)
# ---------- 6. 资源释放 ----------
interpreter.destory()
# ---------- 命令行参数 ----------
def parser_args():
"""解析命令行参数"""
parser = argparse.ArgumentParser(description="AidLite image classification demo")
parser.add_argument('--target_model', type=str, default='yolov11n_cls/cutoff_yolo11n-cls_qcs8550_fp16.qnn231.ctx.bin',
help="模型文件路径")
parser.add_argument('--image_path', type=str, default='bus.jpg', help="待预测图片路径")
parser.add_argument('--model_type', type=str, default='QNN', help="后端类型: QNN / SNPE2")
parser.add_argument('--num_classes', type=int, default=1000, help="模型输出类别数")
parser.add_argument('--class_names', type=str, default='', help="类别名称 txt 路径或逗号分隔字符串")
parser.add_argument('--save_dir', type=str, default='results', help="预测图片输出目录")
return parser.parse_args()
if __name__ == "__main__":
# 解析命令行参数并执行主函数
args = parser_args()
main(args)

