




396,169
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享大家好,我是猫头虎。最近我们团队正在推进 AI 应用平台的开发,尝试将各类大模型能力集成到现有业务系统中。作为项目的技术选型负责人,我深刻体会到一个现实:MaaS 模型选型的难度,远比想象中大得多。
市面上涌现出越来越多的大模型服务商,国内外加起来轻松就有上百家。每一家都声称自己的模型“性能最优、价格最低、延迟最短”,但真正落地测试时,往往与宣传有着明显差距。面对这些参差不齐的信息,我和团队一度陷入了“选择困难症”,既担心错过优质方案,又害怕被营销数据“带偏”。
转机出现在9月13日的 杭州 GOSIM 大会。会上,我了解到由 清华大学和中国软件评测中心 联合发布的 ==《2025 大模型服务性能排行榜》==,而支撑这份榜单的技术平台,正是 AI Ping。抱着试一试的心态,我体验了 AI Ping 的服务,结果让我眼前一亮:它提供的客观评测和详实数据,确实能够为大模型选型提供科学依据,也让我对整个行业的选型方式有了全新的认知。
下图展示的是榜单的部分数据,完整榜单可点击链接前往官网查看:
👉 https://aiping.cn/?utm_source=cs&utm_content=k

==日常开发遇见网络不通怎么办?ping一下,那么AI大模型延迟高,是不是也可以AI ping一下?==
AI Ping 是一个面向大模型使用者,提供全面、客观、真实的大模型服务评测平台。平台聚焦于为企业和开发者提供客观、中立、持续的大模型服务性能对比数据,帮助用户科学选型,避免“盲人摸象”式的决策。进入首页可以看到页面整体简洁,直观,就连色彩也十分清爽。
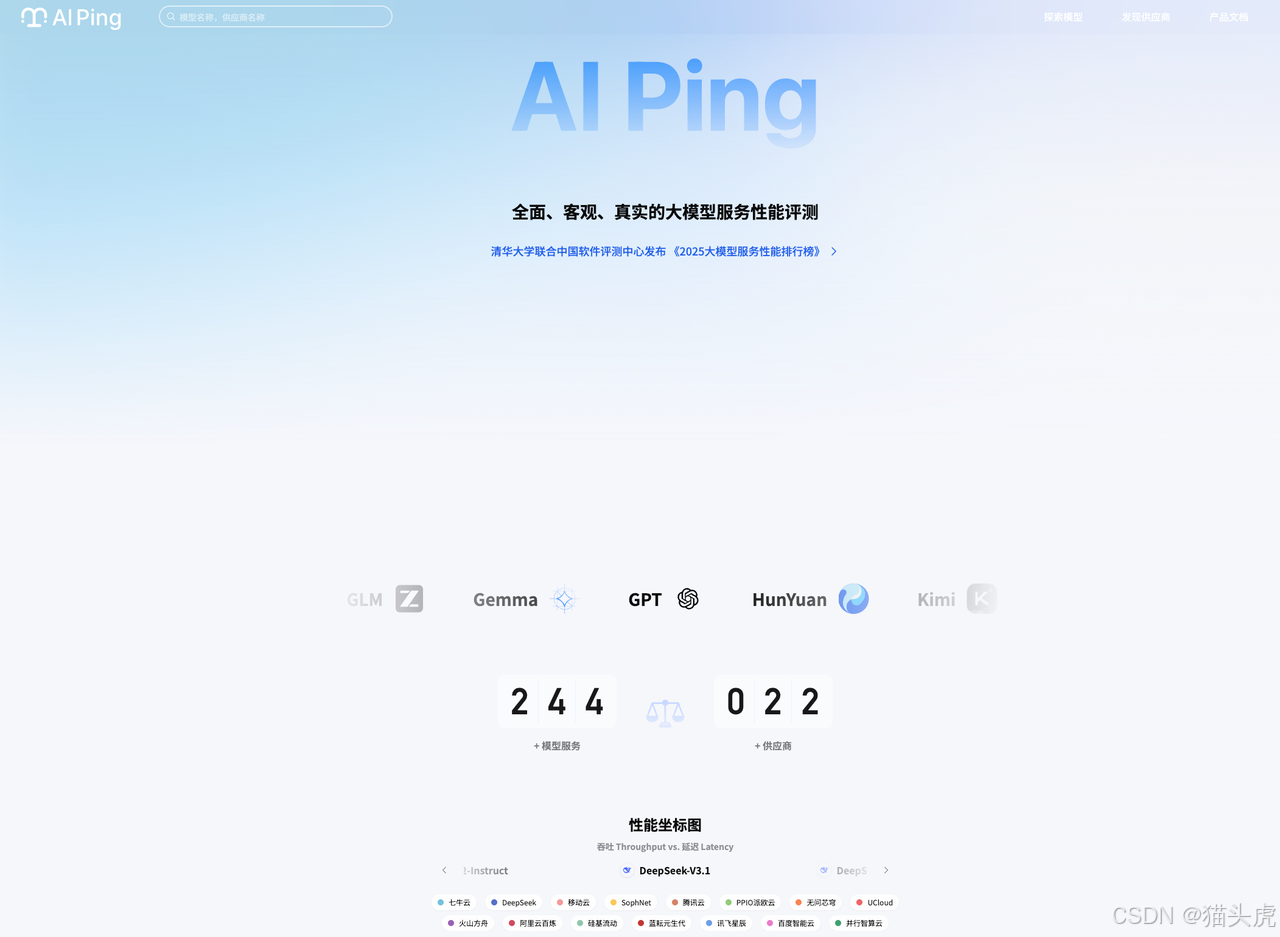
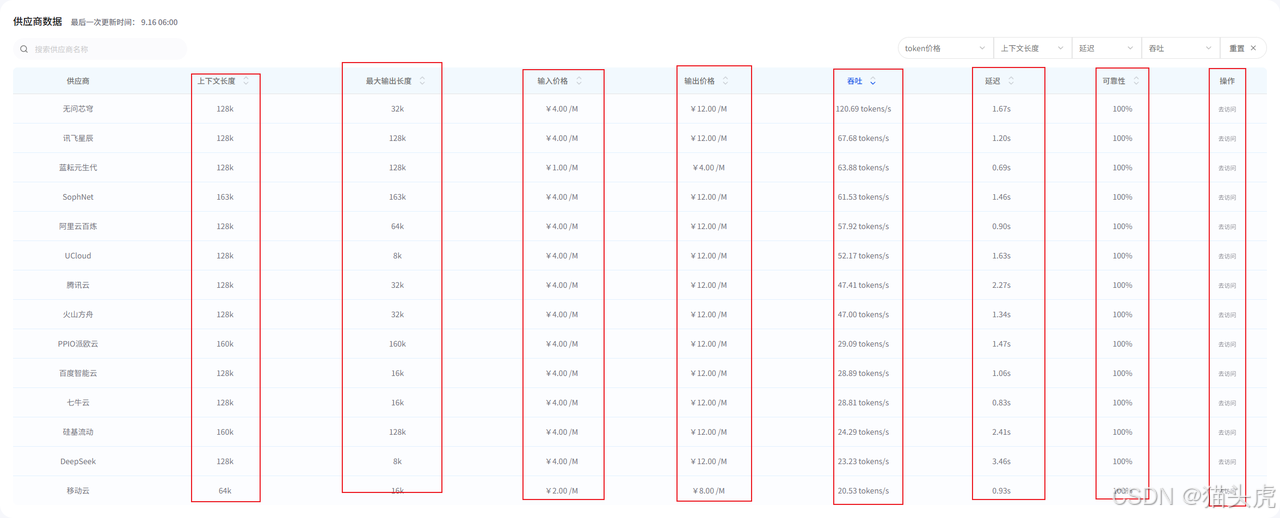
AI Ping平台围绕延迟、吞吐、可靠性、价格、上下文长度、最大输出长度等六大核心指标,构建了全方位的评测体系。平台通过自动化脚本,定时对接各大主流MaaS平台API,采集真实调用数据,确保评测结果的客观性和可复现性。同时在每个供应商的最后还提供了访问接口。
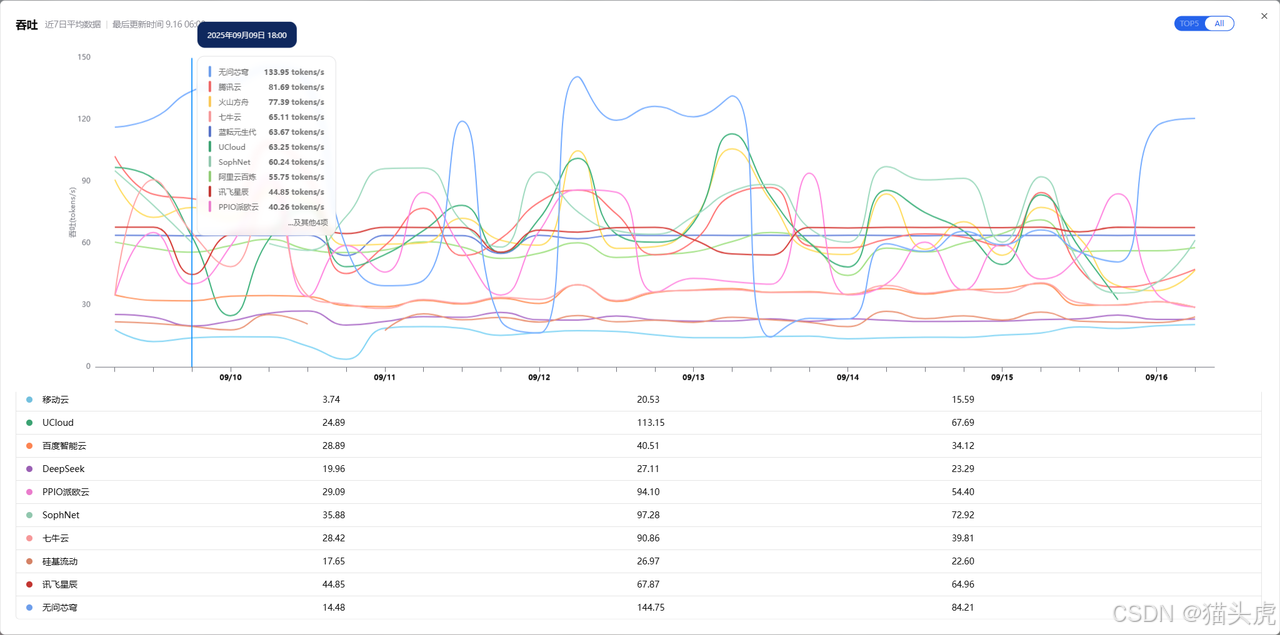
平台不仅提供最新的大模型服务性能排行榜,还支持历史数据回溯和趋势分析。用户可以直观查看各家服务商在不同时间段的表现,避免只看“某一时刻”的偶然数据,真正做到用数据说话。
AI Ping平台已集成了国内外主流的21家MaaS供应商,涵盖了绝大多数市场主流模型服务。用户无需再分别访问各家官网、查阅文档,只需在AI Ping平台即可一站式浏览和对比所有主流供应商的模型性能、价格和服务能力,大大提升了选型效率。
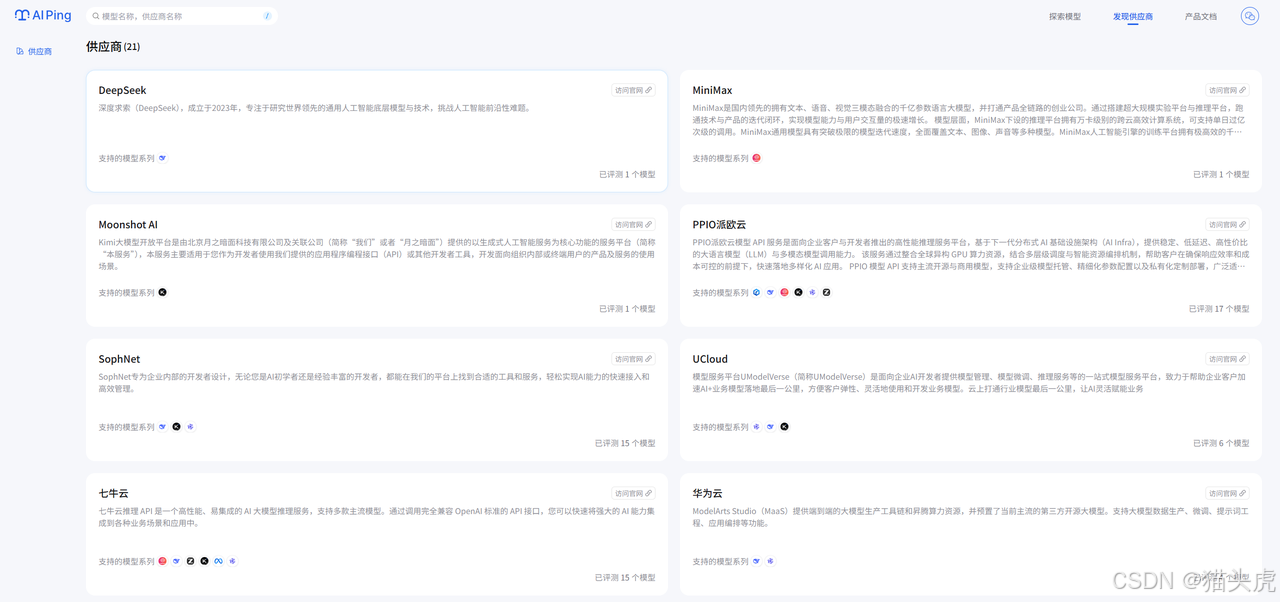
平台目前已收录了不同类型的模型服务,覆盖对话、摘要、代码生成等多种业务场景。无论是通用大模型还是垂直领域模型,用户都能在平台上找到适合自身业务需求的模型,极大丰富了选型空间。
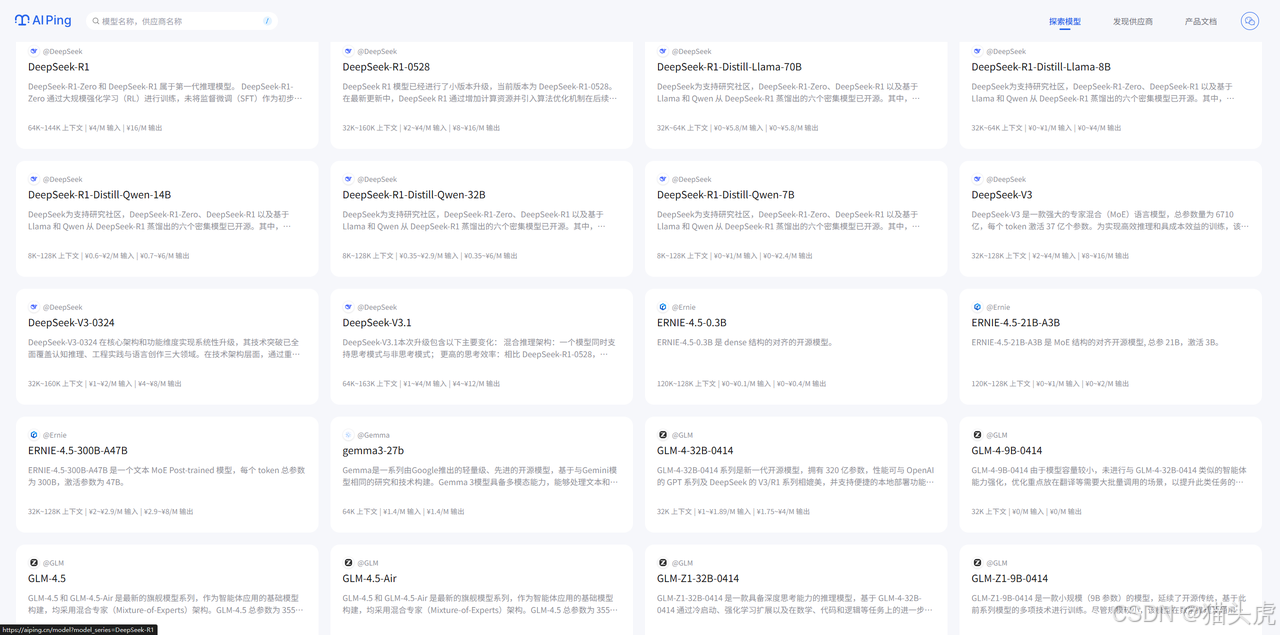
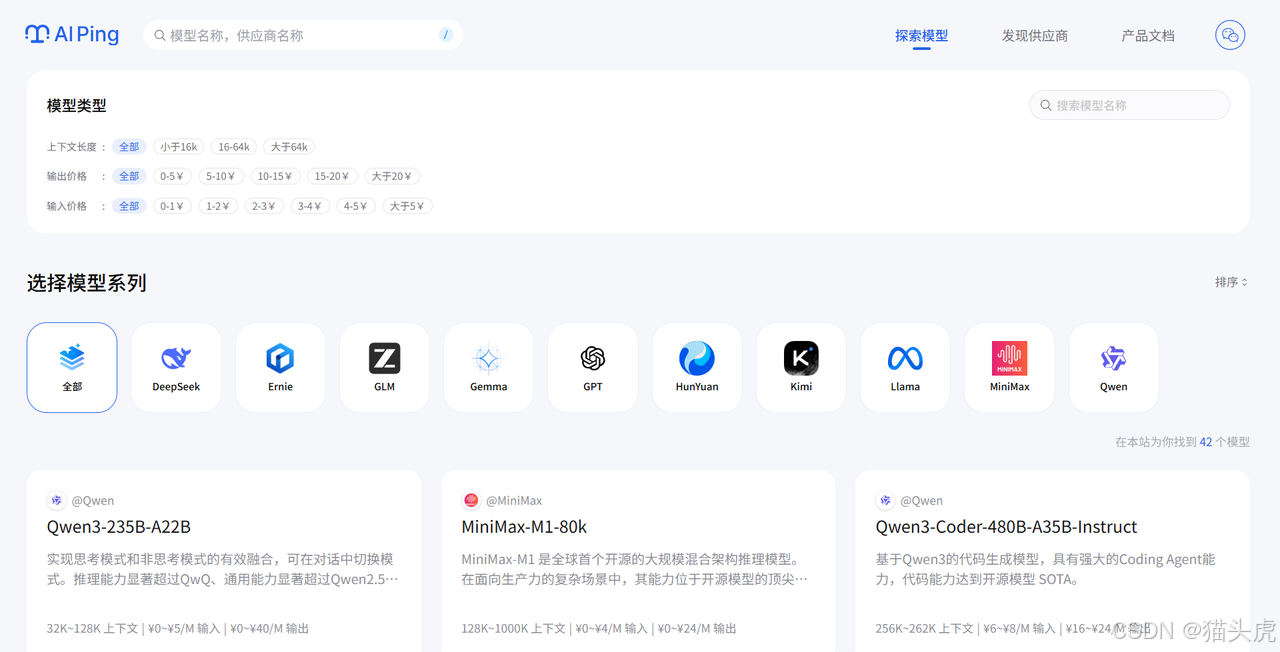
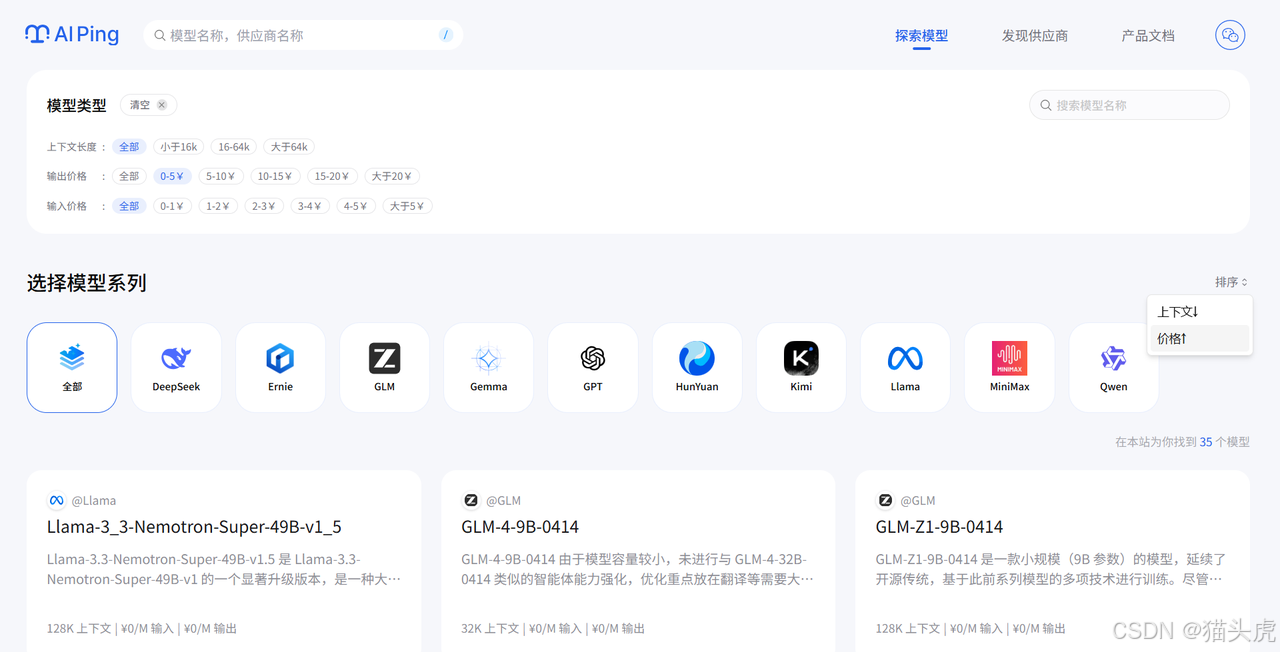
AI Ping支持多维度的模型筛选功能。用户可以根据上下文长度、输入价格、输出价格、最大输出长度等关键指标进行灵活过滤,快速定位最符合自身业务场景和预算要求的模型服务。无论是追求高性价比,还是关注性能极致,都能通过平台的筛选工具高效完成决策。
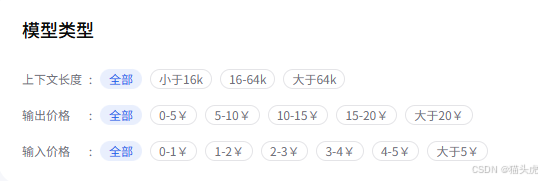
选择一款匹配自己的大模型,一般情况下从六大核心角度去评判,
延迟:指模型响应的速度,直接影响用户体验和业务实时性。比如在做智能客服时,如果模型延迟高,用户每问一句都要等很久,体验会非常差。

吞吐:指模型每秒能处理的请求数量,决定了系统在高并发场景下的表现。比如在电商大促期间,批量生成商品文案,如果模型吞吐低,任务就会堆积,影响上线效率。

可靠性:指服务的稳定性和可用性,保障模型持续、正常运行。比如有一次我们凌晨跑批量审核,模型服务突然中断,导致整个业务流程卡住,影响了交付。

输入/输出价格:指按Token计费的成本,影响整体预算。比如做大批量文档摘要时,有的平台虽然单价低,但输出Token多,实际花费反而更高。
上下文长度:指模型一次能处理的最大输入Token数,决定了能支持多长的文本或多轮对话。比如做法律文书分析时,遇到上下文长度不够的模型,长文档只能拆开处理,分析效果会变差。
最大输出长度:指模型单次生成内容的最大Token数,影响生成文本的完整性。比如自动生成行业报告时,输出长度有限,内容经常被截断,不得不多次拼接补全。
如果你想开发一个工具,可以一键分析用户上传的冗长的技术文档、研究报告或者是会议记录(通常篇幅超过5万字),并要求生成摘要和关键点。这种情况下,你面临最大的挑战就是普通模型无法一次性输入这么长的文本,导致对想要分析的文档分析不完整,或者需要进行复杂的分段处理。
访问AI Ping官网:https://aiping.cn/?utm_source=cs&utm_content=k,点击顶部的探索模型,这里提供了模型的筛选功能。
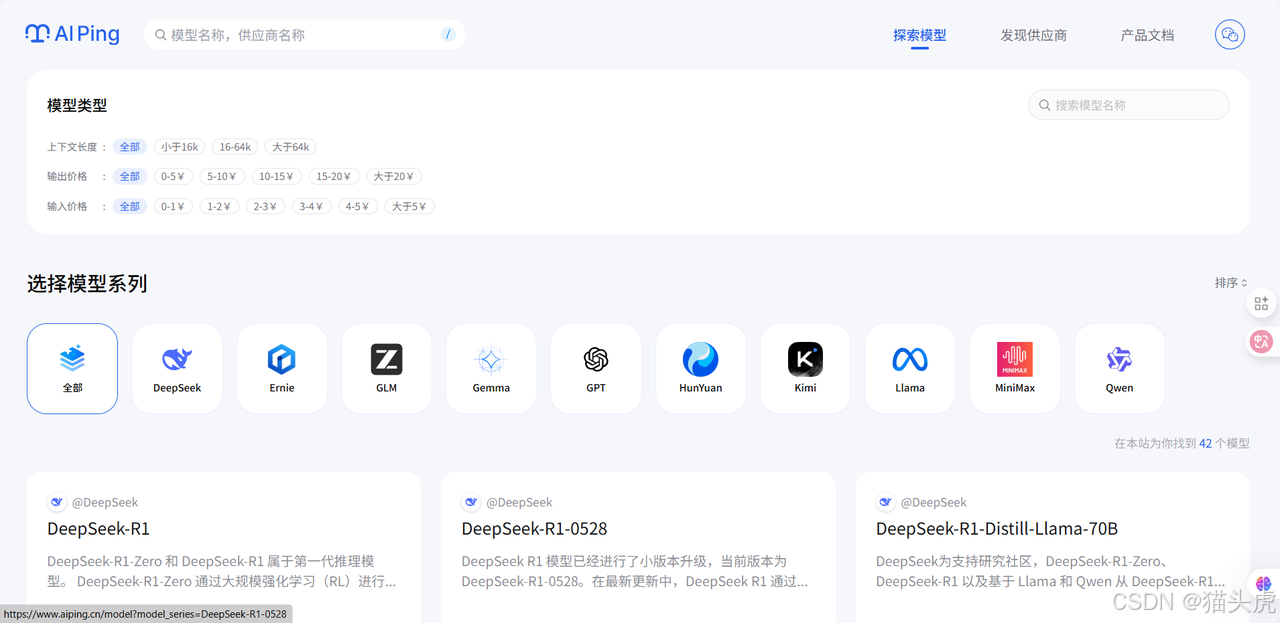
在上面的模型类型中,找到上下文长度。
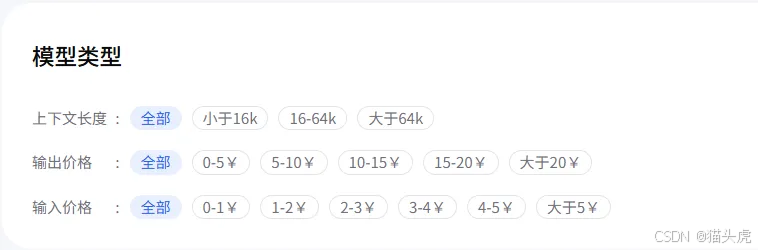
直接选择最长的选项,如选择大于64k,页面将会自动刷新,只显示支持超文本的模型。
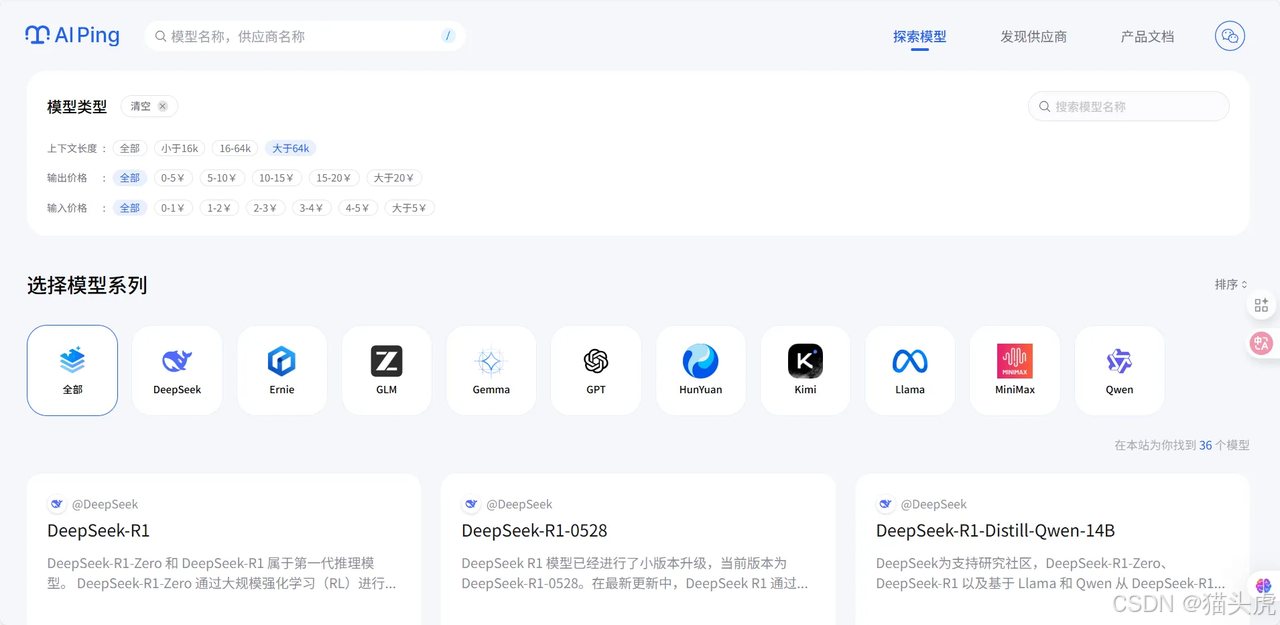
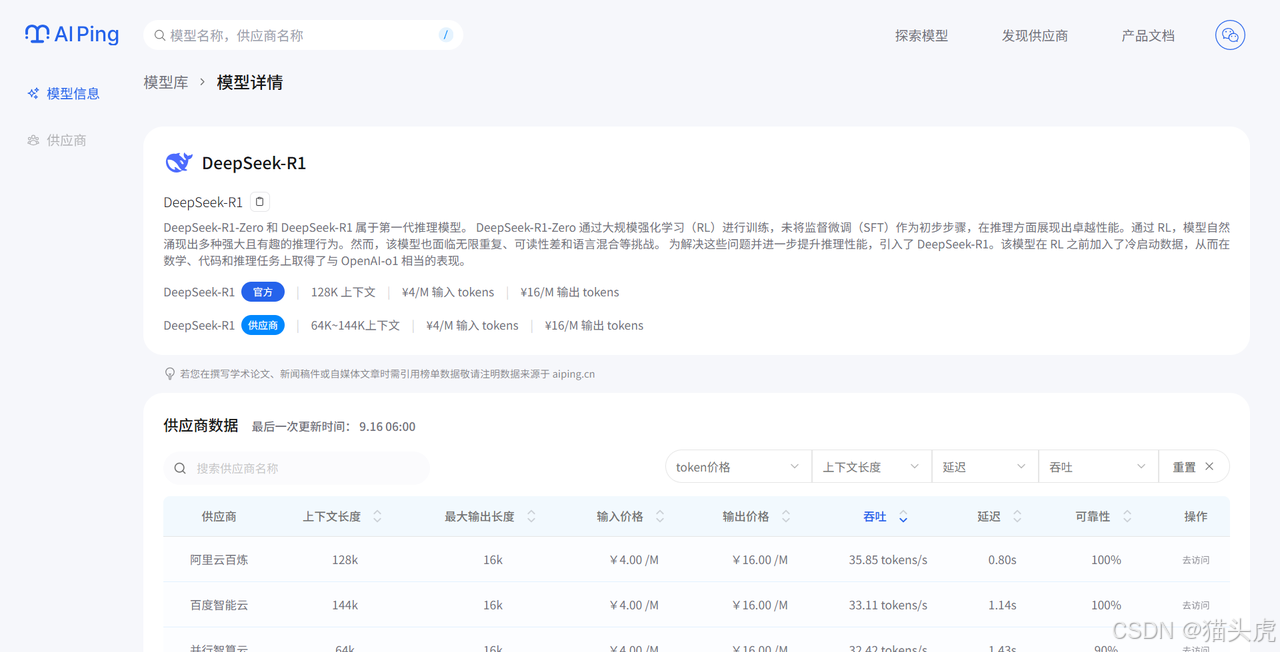
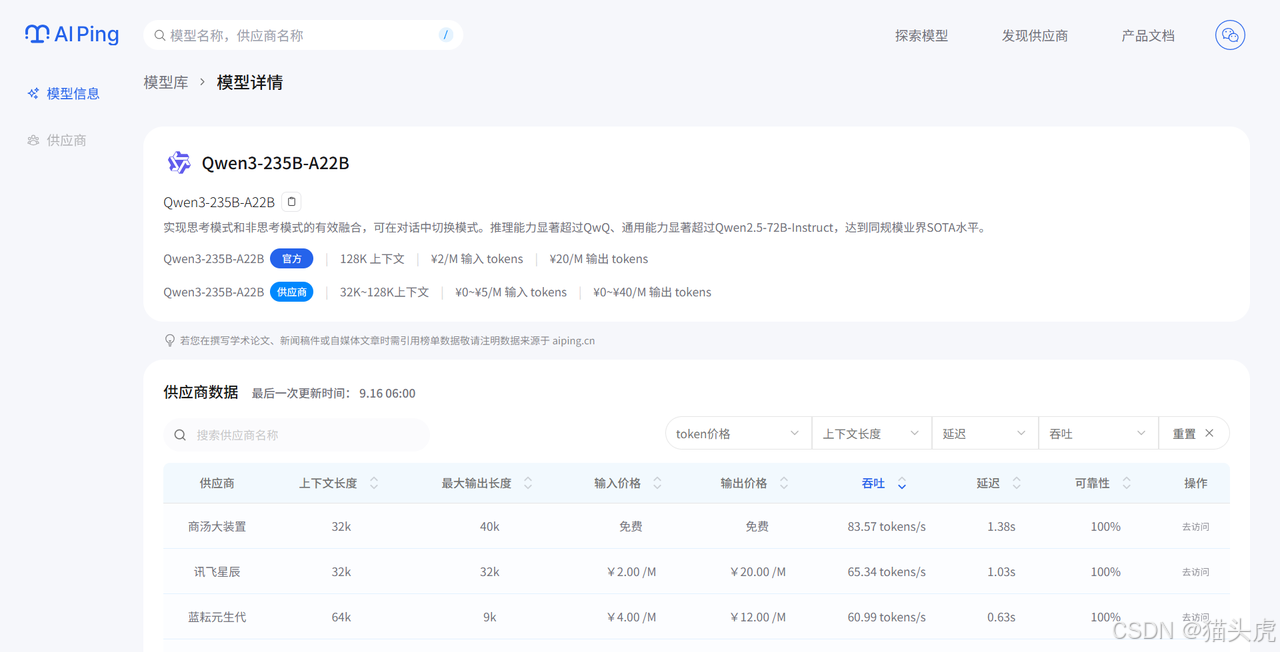
现在列表中剩下的都是处理你任务的候选模型。你可以通过模型详情快速了解它们的特点,比如DeepSeek-R1,进入DeepSeek-R1的模型详情页面,可以了解该模型的特点、供应商数据以及吞吐。
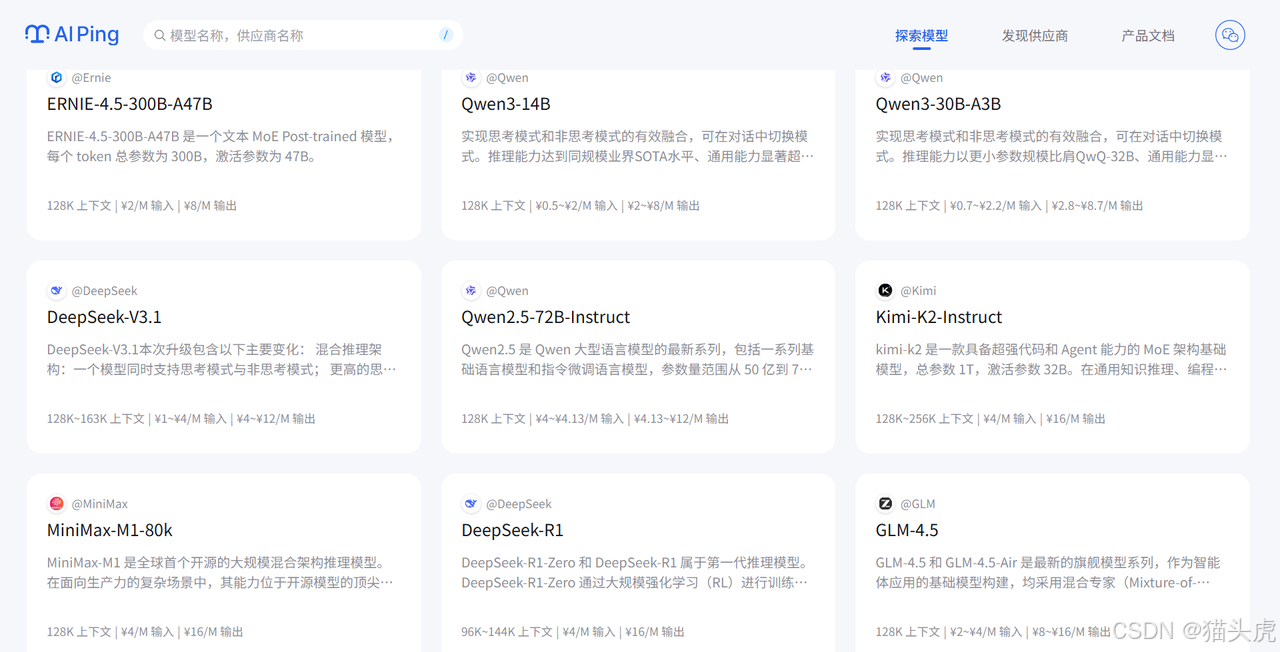
筛选了符合的模型之后,你可以按照“价格”进行排序,从这些长文本模型中找出性价比最高的选项。比如,DeepSeek-V3.1支持128k上下文且价格也可以接受。
点击你选定的DeepSeek-V3.1模型,进入该模型的详情页。
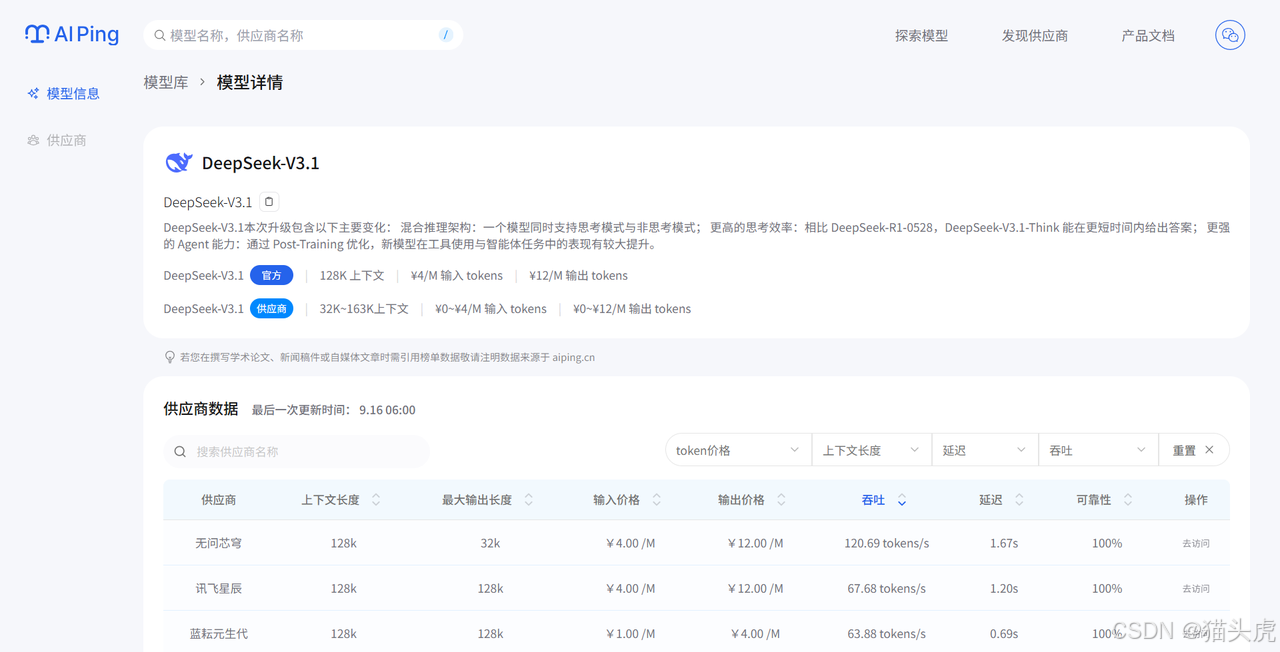
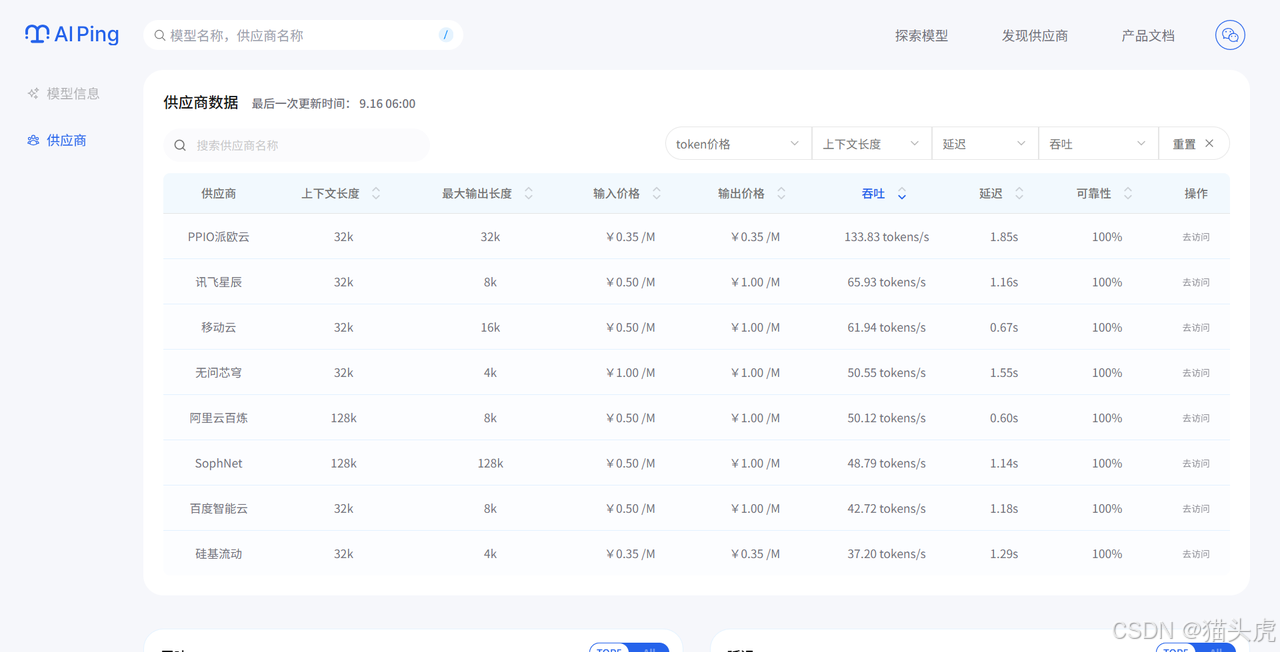
查看下方的供应商表格,对于长文本任务,吞吐量(Tokens/s) 变得很重要,因为它直接影响处理速度。对比不同供应商提供的 “吞吐量” 和 “价格”,选择一个处理速度快且稳定的供应商。
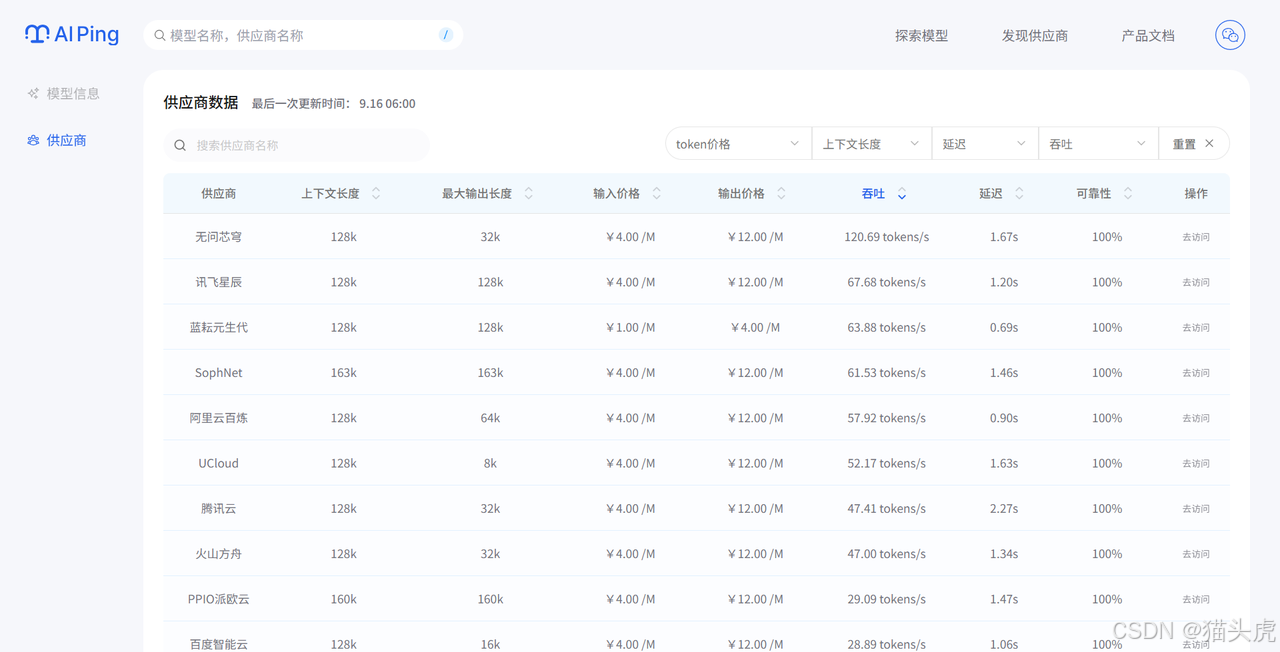
搞定!你的最终选择是:【DeepSeek-V3.1】模型 + 【无问芯穹】服务。
现在,你可以自信地让用户上传整本手册或长篇报告,模型都能一次性完整阅读并进行分析
你需要一个模型来为大量新闻文章自动生成摘要。摘要质量要求不高,能概括大意即可,但由于处理量巨大,成本是你的首要考虑因素。
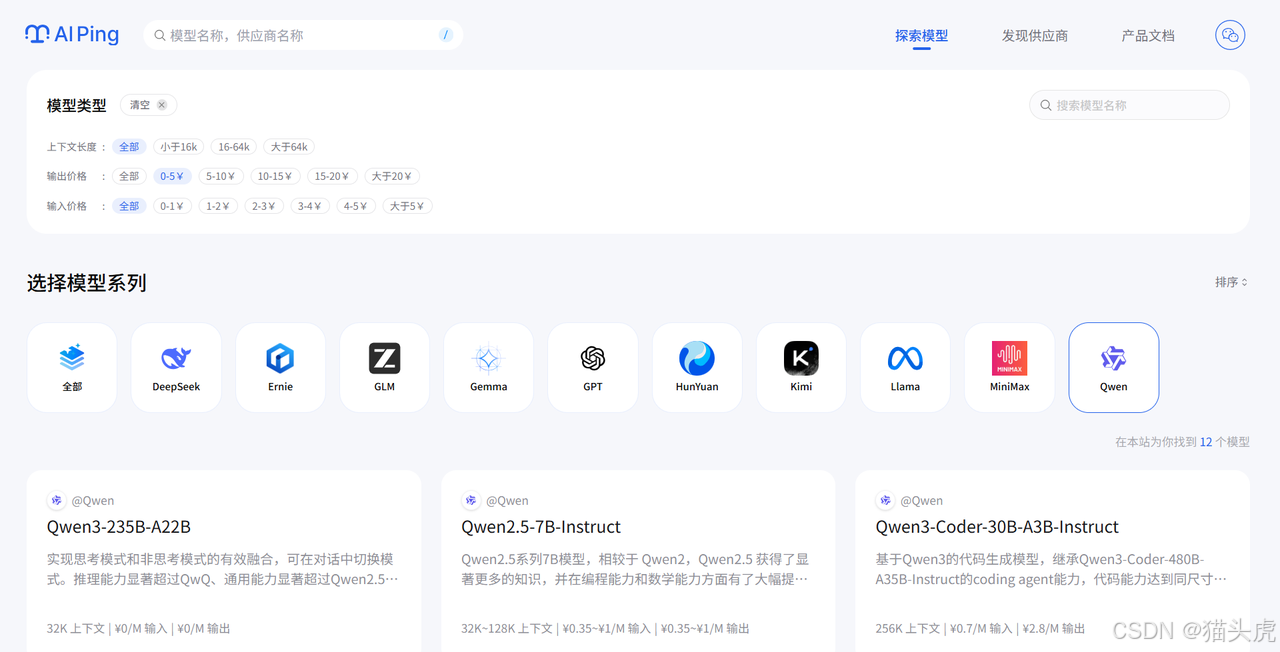
亮点:
建议:
作为一名一线的AI开发者,我深刻体会到,AI Ping让大模型服务的选择变得有据可依。无论是实时的性能监测,还是多维度的客观评测数据,都极大提升了选型的效率和准确性。选型不再是“拍脑袋”,而是“看数据”,这对于团队的技术决策和项目落地都有着非常积极的意义。
更重要的是,AI Ping作为一个第三方平台,不仅推动了行业的健康发展,也为每一位开发者点亮了前行的灯塔。如果你也在为大模型选型而苦恼,不妨亲自体验一下AI Ping。让数据说话,让决策更科学,让AI应用开发之路走得更加稳健和高效。
PC 端前往AI Ping官网👀:https://aiping.cn/?utm_source=cs&utm_content=k
移动手机📱端扫描下方二维码 立即查看最新厂商评测排行榜:




