



108
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享| 项目 | 内容 |
|---|---|
| 这个作业属于哪个课程 | 202501 福大-软件工程实践-w 班 |
| 这个作业要求在哪里 | 软件工程实践——大模型评测作业 |
| 这个作业的目标 | 1.调研,评测两个大模型 2.分析大模型的优缺点以及市场 |
(DeepSeek-V3.2-Exp)
开发背景与定位
DeepSeek是由深度求索公司开发的大型语言模型,旨在打造具有国际竞争力的国产自研大模型。其定位是"全能型AI助手",通过先进的AI技术为普通用户、开发者和企业提供高效、智能的文本生成、知识问答、代码编程及逻辑推理服务,坚持免费服务以降低AI使用门槛。
核心功能概述
智能对话与问答:支持多轮、上下文关联的对话
文本生成与创作:撰写文章、报告、邮件、脚本等
代码编程助手:支持多种编程语言的代码生成、解释、调试和优化
逻辑推理与分析:数学运算、逻辑推理、数据分析和信息总结
文件处理能力:支持上传图像、TXT、PDF、PPT、Word、Excel等文件
联网搜索:手动开启,获取并整合最新网络信息
适用场景分析
学生:辅助论文写作、查找资料、解答疑问
创作者:撰写报告、邮件、策划方案、翻译
程序员:编程助手,提高代码编写和调试效率
普通用户:日常生活的智能搜索引擎和聊天伴侣
注册流程说明
(1)通过官方应用商店下载"DeepSeek"App或访问网页版
(2)支持手机号验证码注册或第三方账号授权登录
(3)注册后无需复杂设置,立即开始使用
主要功能使用演示
(1)基础对话:直接输入问题,如"请用Python写一个快速排序算法"文件上传:点击附件按钮上传文件,请求总结或分析
(2)联网搜索:手动开启联网搜索,获取最新信息
多轮对话:基于上下文进行连续提问
(3)软件界面特点介绍
设计风格:简洁清新,以白色和品牌蓝色为主色调
交互设计:对话流清晰,提供复制、重新生成、分享功能
功能布局:主要功能入口明确,操作直观
实际应用场景测试
场景一(工作报告撰写):生成结构完整、逻辑清晰的大纲
场景二(代码调试):准确指出错误原因并提供修正方案
场景三(知识问答):回复内容准确,涵盖定义和挑战分析
任务完成效果评估
在通用任务上表现出色,尤其在结构化写作、代码生成和逻辑推理方面完成度高。对于高度专业化或极强创造性任务,表现中规中矩,需要人工引导。
(1)数据量方面
优点:训练数据覆盖范围广,在通用知识和编程领域基础能力强
缺点:知识时效性存在局限,核心知识库有截止日期
(2)界面方面
优点:界面设计简洁明了,学习成本低,交互流程顺畅
缺点:缺乏高级自定义设置,对话历史管理功能简单
(3)功能方面
优点:功能完整性高,128K上下文长度是特色,完全免费
缺点:缺乏语音交互、多模态图像生成与识别,联网搜索需手动开启
(4)准确度方面
优点:常见任务完成准确率高,编程和数理逻辑领域答案可靠
缺点:专业领域可能产生不准确信息,创造性写作有时模式化
(1)学习成本:几乎为零,开箱即用
(2)使用过程中的痛点:
知识时效性依赖手动联网
创造性局限,输出结果可能同质化
(3)深度专业领域的不确定性
(4)功能局限性:无语音功能,无法直接生成或编辑图像
(1)功能优化建议
增加"回复风格"和"创造性水平"调节功能
(2)体验改善方案
增强对话历史的管理功能
对事实性陈述标注可信度或提供来源提示
(3)未来发展建议
探索集成多模态能力
建立面向企业和开发者的API生态
受访者A(应某):21岁,福大软工23级学生
应某遇到的问题:报告模板化,需要个性化修改;未开启联网时获得过时信息
应某的使用亮点:写邮件初稿和会议纪要大纲节省时间,效率提升50%
应某遇到的问题:复杂工程性问题解决方案不够全面
受访者B(郑某):21岁,福大软工23级学生
郑某遇到的问题:api用量不够,ai的理解能力有误,赛博鬼打墙。
郑某的使用亮点:使用api来接入程序辅助工作
(1)用户直接建议:增加"模仿某某风格写作"功能,优化联网搜索智能度
(2)问题根源分析:模板化问题源于模型缺乏个人经验;工程性问题源于缺乏系统性项目上下文
(3)针对性改进方案:引入"风格学习"功能,增强复杂系统问题理解能力
整体评价总结
DeepSeek是一款综合能力强大、用户体验出色且免费的大型语言模型。在文本处理、代码编程和逻辑推理等核心领域表现优异,满足绝大多数个人用户需求。尽管存在知识时效性和创造性局限,但其卓越的性价比使其成为最具竞争力的AI工具之一。
适用人群建议
强烈推荐:学生、办公室职员、内容创作者、程序员及普通用户
谨慎参考:前沿科学研究学者、金融从业者、艺术创作者
发展前景展望
DeepSeek有望在模型能力、多模态功能和生态建设上取得突破。免费商业模式可能吸引亿级用户,未来可能从对话工具演进为核心智能生产力平台。
使用建议
(1)善用其长:用于结构化写作、代码辅助、学习新知
(2)认清其短:对关键事实交叉验证,对创造性输出抱有"初稿"心态
(3)掌握技巧:编写清晰指令,使用文件上传功能,需要最新信息时开启联网搜索
通义千问-Plus是阿里云通义实验室推出的通义千问系列大模型中的一个重要版本。作为一款能力均衡的模型,它在推理效果、成本和速度方面介于通义千问Max和通义千问Flash之间,特别适合处理中等复杂度的任务。
根据阿里云官方资料,通义千问-Plus具备以下核心功能:
• 多轮对话:能够理解上下文并进行连贯的多轮交互
• 文案创作:可撰写故事、公文、邮件、剧本、诗歌等多种文本
• 逻辑推理:处理复杂逻辑问题,提供结构化解决方案
• 编程辅助:编写、解释和优化代码,支持多种编程语言
• 多语言支持:支持119种语言,满足国际化需求
• 文本处理:包括文本润色、摘要提取、翻译等功能
• 数据可视化:协助进行图表制作和数据呈现
通义千问-Plus特别适合企业级应用场景,如办公自动化、智能客服、内容创作等领域。在软件工程领域,它能够为开发者提供代码生成、错误排查、文档编写等支持。
注册过程:
1.访问阿里云官网(http://www.aliyun.xn--com),""-zb4kb370fbub872dicaw013b3u7ez2aea9664ajjexrm/
2.选择"通义app"或"通义实验室"进行注册
3.使用手机号完成验证,设置账号密码
4.登录后可选择免费试用或开通付费服务
主要功能使用:
1.基础对话功能:在主界面输入自然语言问题,模型会生成相应回答
2.代码辅助功能:输入"请帮我写一个快速排序算法"等指令,模型会生成相应代码
3.文档生成:输入"生成一份软件需求规格说明书模板",模型会输出结构化文档
4.错误排查:将出错代码粘贴到对话框,询问"这段代码有什么问题",模型会分析并提供解决方案
软件界面特点:
• 界面简洁美观,一问一答形式清晰
• 提供历史对话记录,方便回溯
• 支持文件上传功能,可分析文档内容
使用软件截图:
处理自然语言问题
web界面
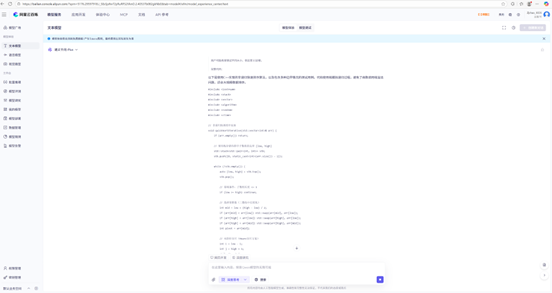
编写非递归快速排序算法
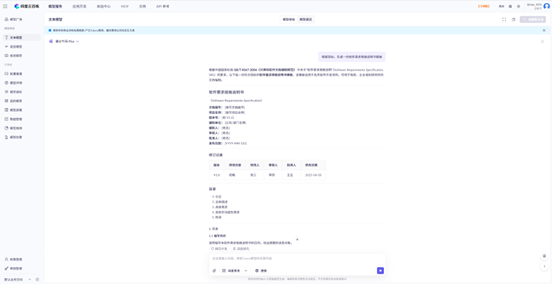
生成一份软件需求规格说明书模板
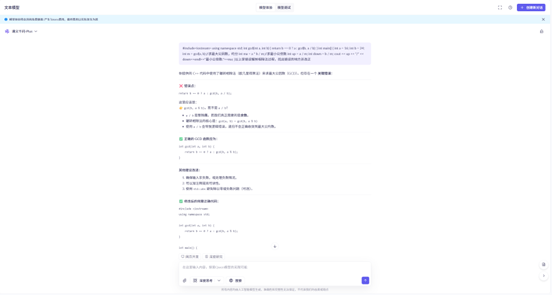
提供错误的代码,让大模型纠错
在使用过程中,我主要将通义千问-Plus应用于软件工程相关的任务,包括代码编写、算法设计、文档撰写等方面。总体而言,该模型在解决日常开发问题上表现出色,特别是在代码生成和文档撰写方面,显著提高了工作效率。
数据量方面
优点:
• 训练数据量庞大,覆盖广泛的知识领域
• 能够处理较长的上下文(最高可达32768 token),适合复杂文档处理
• 在常见编程语言和算法知识方面数据丰富
缺点:
• 对于2025年之后的最新技术动态覆盖不足
• 某些高度专业化的领域知识可能不够深入
• 在处理对数据精确性要求极高的领域时,有时会提供过时或不准确的信息
界面方面
优点:
• 页面设计简洁美观,一问一答形式清晰直观
• 响应迅速,能够即时响应用户问题并在短时间内提供答案
• 历史对话记录功能便于回溯和参考
缺点:
• 缺少针对不同场景的界面定制选项
• web端不支持代码高亮显示功能
• 没有提供详细的使用指南和功能说明
功能方面
优点:
• 功能全面,涵盖文字创作、编程辅助、翻译服务等多个领域
• 指令遵循能力强,可通过提示词工程精准控制输出格式
• 多语言支持完善,满足国际化需求
• 支持多轮对话,能够理解上下文并给出连贯回复
缺点:
• 在处理特别复杂的推理任务时表现不够稳定,会产生幻觉
准确度方面
优点:
• 常见编程问题和算法问题解决准确率高
• 逻辑推理能力较强,能够处理中等复杂度的问题
• 在中文场景下表现尤为出色,理解准确
缺点:
• 对于涉及复杂情感或主观判断的问题,回答不够灵活和富有人情味
• 在处理需要精确数据的任务时,偶尔会出现数值错误
• 依赖训练数据,对于训练数据中未充分覆盖的问题可能无法正确回答
在使用过程中,我发现以下用户体验方面的问题:
1.学习曲线:虽然基本对话功能简单易用,但要充分发挥其潜力,需要掌握有效的提示词工程技巧,这对新手不够友好。
2.结果不确定性:同一问题多次询问可能会得到不同答案,缺乏一致性。
3.错误处理机制:当模型无法提供准确答案时,缺乏明确的提示,有时会生成看似合理但实际错误的内容。
4.上下文管理:长对话中,模型有时会"忘记"早期对话内容,影响多轮交互的连贯性。
基于使用体验,我提出以下改进建议:
1.增强错误提示机制:当模型不确定答案时,应明确告知用户,而不是提供可能错误的信息。
2.提供提示词模板库:为不同场景提供优化的提示词模板,降低使用门槛。
3.改进上下文管理:增强长对话中的上下文记忆能力,提高多轮交互质量。
4.增加领域定制选项:允许用户针对特定领域进行临时定制,提高专业问题的解决能力。
采访对象:黄某,福建农林大学某计算机科学与技术专业大一学生
背景介绍:
• 年龄:19岁
• 专业:计算机科学与技术
• 年级:大一
• 编程经验:半年,主要学习C++和Python基础
• 竞赛经历:首次参加蓝桥杯竞赛,正在学习算法部分
选择原因: 选择黄某作为采访对象主要基于以下考虑:
1.作为大一新生,他对AI工具的使用经验有限,能够代表初级编程学习者视角
2.正在准备蓝桥杯竞赛,有明确的算法学习需求
3.作为计算机相关专业学生,他的使用体验对同类用户有参考价值
4.初学者视角能帮助发现产品中资深用户可能忽略的问题
需求分析: 黄某的主要需求是:
• 快速理解基础算法概念
• 获取算法实现示例
• 纠正代码错误
• 获得针对蓝桥杯竞赛的针对性练习建议
• 理解算法题目的解题思路
在30分钟的使用过程中,黄某主要使用了以下功能栏目:
1.代码纠错功能:将自己编写的算法题解代码粘贴到对话框,询问"这段代码有什么问题?"
2.算法解释功能:输入"请解释快速排序算法的原理和实现步骤"
3.题目解析功能:上传蓝桥杯往届真题,询问"这道题的解题思路是什么?"
4.代码生成功能:要求"生成一个用C++实现的二分查找算法"
5.学习建议功能:询问"针对蓝桥杯算法竞赛,我应该如何准备?"
遇到的问题:
1.术语理解障碍:当模型使用"时间复杂度"、"空间复杂度"等专业术语时,黄某表示不太理解,需要额外查询这些概念。
2.代码示例复杂度不匹配:模型有时生成的代码示例对大一学生来说过于复杂,包含了一些尚未学习的高级特性。
3.不支持代码语法高亮:模型生成的代码统一是黑色的,阅读困难。
采访过程:
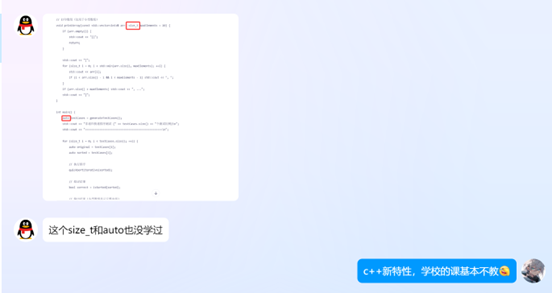
亮点体验:
1.即时反馈:黄某特别赞赏模型能够立即响应,大大提高了学习效率。
2.多种解法展示:对于同一问题,模型能提供多种解法并比较优劣,帮助他拓展思路。

根据采访,黄某提出了以下用户体验改进建议:
1.难度分级功能:希望模型能根据用户水平(如大一、大二等)自动调整回答的复杂度和专业术语使用程度。
2.学习进度跟踪:建议添加学习进度记录功能,让模型能根据用户已掌握的知识点提供更有针对性的建议。
3.错误高亮显示:希望模型能够像IDE一样,在代码中直接高亮显示错误位置,而不仅仅是文字描述。
4.概念解释功能:当检测到用户可能不理解某个术语时,自动提供简明易懂的解释,或者询问是否需要进一步解释。

开发团队为何未意识到这些问题:
我认为开发团队可能没有充分意识到这些问题,原因如下:
1.目标用户定位偏差:通义千问-Plus可能更多面向有一定经验的开发者,而非编程初学者,因此对新手友好性考虑不足。
2.内部测试局限性:团队内部测试可能主要由经验丰富的工程师进行,他们对专业术语和复杂概念已经习以为常,难以察觉初学者的困难。
3.缺乏教育领域专业知识:开发团队可能缺乏教育学和认知科学的专业知识,不了解初学者的学习障碍和认知特点。
4.用户反馈机制不完善:可能没有建立针对不同用户群体(如学生、教育者)的专门反馈渠道,导致初学者的问题难以被发现。
5.过度关注技术指标:开发团队可能更关注模型的技术指标(如参数量、响应速度),而忽视了用户体验细节。
建议开发团队可以:
• 增加针对教育场景的专门测试环节
• 与高校合作,收集更多学生用户的反馈
• 设计针对不同知识水平的自适应交互模式
• 建立用户能力评估机制,动态调整回答复杂度
结论
通过对通义千问-Plus的深入使用和用户调研,我发现该模型在软件工程领域具有显著价值,尤其在代码辅助和文档生成方面表现突出。然而,对于编程初学者如准备蓝桥杯竞赛的大一学生,仍存在一些用户体验上的挑战。
未来,随着大模型技术的不断发展和针对性优化,通义千问-Plus有望在教育领域发挥更大作用。建议开发团队更加关注不同用户群体的特定需求,特别是针对学生和初学者的使用场景进行优化,使AI工具真正成为学习和开发的得力助手。
对于软件工程专业学生而言,合理利用通义千问-Plus等AI工具可以显著提高学习和开发效率,但同时也要保持批判性思维,不盲目依赖AI生成的内容,特别是在处理关键代码和算法问题时。
大模型购车推荐多轮对话评价
随着大模型在垂直领域(如购车决策)的应用普及,需通过量化评价区分不同模型的推荐能力。本次选取 qwen-plus 与 deepseek-chat 两款模型,基于 “20 万元预算、城市通勤为主、注重空间舒适与安全性” 的用户需求,通过半自动评价(Excel 表格评分 + 人工校准),对比两者在购车推荐场景中的综合表现。
评价范围:覆盖两款模型的 3 轮对话记录,聚焦 “需求匹配、信息有效性、逻辑清晰度、交互自然度、场景延展性、数据时效性”6 个核心维度。
评价工具:Microsoft Excel(用于评分录入、权重计算与数据可视化);权威数据源(汽车之家、品牌官网)用于人工校准信息准确性。
本次评价新增 “场景延展性”“数据时效性” 维度,并设置权重以强化区分度,具体维度定义、评分标准及权重如下表所示:

1.初步评分:对照模型 3 轮对话记录,按上述标准在 Excel 中逐维度打分(1 分钟 / 轮,重点标记 “信息有效性” 存疑点)。
2.人工校准:针对 “信息有效性” 存疑点,通过权威渠道验证(如比亚迪官网核查 “海豹 DM-i 质保政策”、汽车之家验证 “CR-V 保值率”),修正评分并补充校准说明。
3.总分计算:采用加权平均公式自动计算总分,Excel 公式为:=需求匹配度0.25+信息有效性0.25+逻辑清晰度0.15+交互自然度0.15+场景延展性0.1+数据时效性0.1。
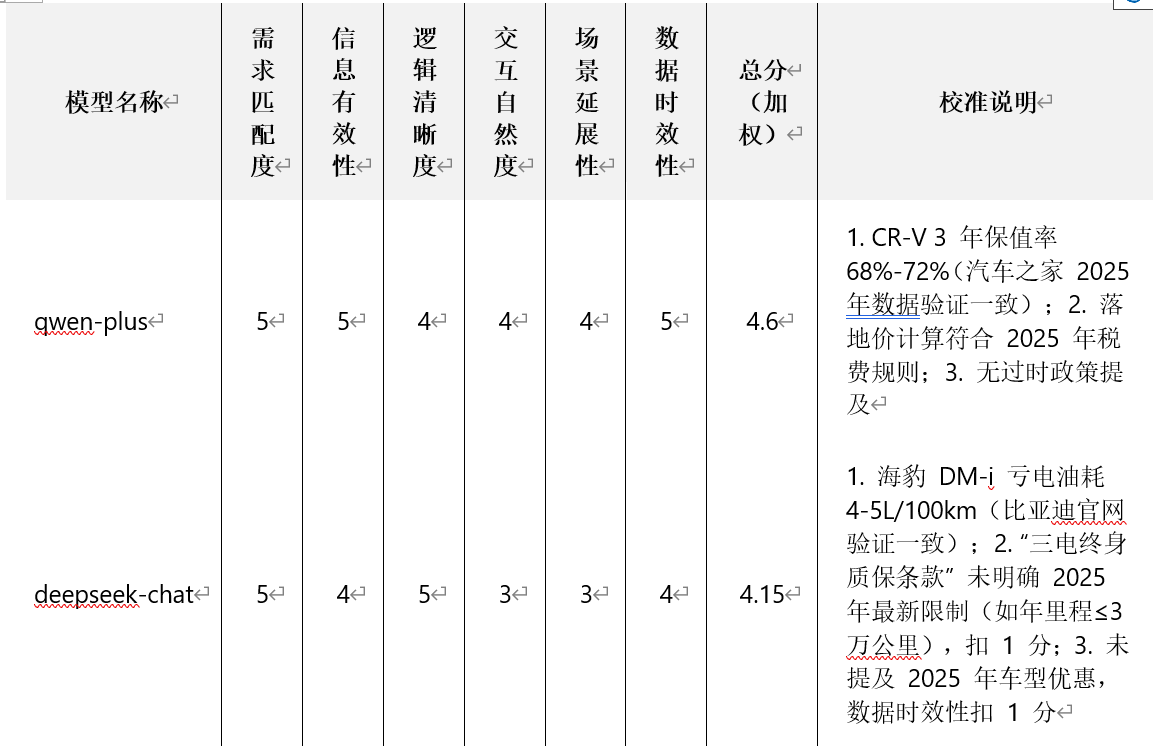
总分柱状图结论:qwen-plus 总分(4.6)高于 deepseek-chat(4.15),综合表现更优,优势主要来自 “信息有效性”“数据时效性” 与 “场景延展性”。

维度雷达图结论:
qwen-plus 各维度更均衡,尤其 “信息有效性”“数据时效性” 达满分,无明显短板;
deepseek-chat 仅 “逻辑清晰度” 达满分,“交互自然度”“场景延展性” 表现较弱,存在明显维度差距。
qwen-plus 核心优势与适用场景:
优势:信息精准度高(数据经权威验证无错误)、数据时效性强(覆盖 2025 年最新优惠与政策)、场景拓展主动(如提及 “通勤 + 周末自驾” 双场景),且交互自然度适中,能贴合用户决策中的潜在需求。
适用场景:适合 “理性决策型用户”,尤其关注 “最新市场数据、具体落地成本、多场景适配” 的购车需求,可直接基于推荐信息推进试驾或比价。
deepseek-chat 核心短板与适用场景:
短板:交互偏书面化(缺乏口语化引导)、场景延展性弱(仅聚焦城市通勤,未拓展其他用途)、数据时效性不足(部分政策未更新至 2025 年),虽逻辑推导完整,但实用性与信息完整性有待提升。
适用场景:适合 “关注推理过程的用户”,如希望深入了解 “车型技术差异(如纯电 vs 混动)” 的用户,但需补充最新市场数据后,才能辅助最终决策。
针对 deepseek-chat 的优化方向:
补充 “数据时效性校验” 模块,确保提及的质保、优惠等政策为当前最新;
增强场景延展性,在推荐时主动关联 “通勤外的家庭出行、长途自驾” 等潜在需求;
优化交互语言,减少书面化表述,增加 “建议您试驾时重点感受拥堵路段平顺性” 等引导性语句。
通用优化建议:
两款模型均需强化 “本地化数据”(如不同城市的优惠差异、试驾门店信息),进一步提升推荐的落地性;
可新增 “用户画像适配” 维度(如 “家庭用户 vs 单身用户” 推荐差异),细化推荐颗粒度。
| 分析维度 | DeepSeek | 通义千问 |
|---|---|---|
| 模型架构 | 采用 混合专家(MoE)架构,通过“专家并行”技术动态分配计算资源(仅激活部分专家处理任务,降低算力消耗);结合强化学习(RLHF) 微调对话策略,提升交互自然度。 | 基于 Transformer 改进架构,强化长文本理解(扩展上下文窗口技术,支持万字级文本连贯处理)与多轮对话一致性(记忆机制优化,减少信息丢失);探索多模态能力(图文生成、跨模态理解,拓展“文本+”场景)。 |
| 数据处理逻辑 | 训练数据覆盖 多语言通用知识、代码、垂直领域文本(如金融、医疗),通过数据清洗、去噪、增强技术保障数据质量;针对代码生成场景,构建“代码-注释-功能描述”三元组数据集优化序列建模。 | 整合 阿里生态全域数据(电商交易、物流履约、云计算服务文本),结合公开学术数据集构建多领域语料库;通过联邦学习平衡“数据规模扩张”与“隐私合规”(如金融、政务敏感数据处理)。 |
| 核心技术创新点 | 1. MoE 架构的“能效比”优化(相同算力下处理更复杂任务);2. RLHF 微调的“对话策略分层训练”(区分通用对话、专业问答、创意生成等场景)。 | 1. 长文本窗口技术的“上下文压缩-解压”机制(高效保留长文本关键信息);2. 多模态能力的“跨模态对齐预训练”(图文特征空间统一建模)。 |
| 分析维度 | DeepSeek | 通义千问 |
|---|---|---|
| 服务形态 | 1. 提供 标准化 API 接口(覆盖文本生成、代码辅助、逻辑推理等场景);2. 开源部分模型权重(如 DeepSeek-R1 系列),支持开发者本地部署;3. 企业级定制服务(私有化部署、专属模型训练、行业解决方案联合开发)。 | 1. 深度绑定 阿里云“模型即服务(MaaS)”,提供“训练-部署-推理”一站式平台;2. 嵌入阿里系生态产品(钉钉会议纪要自动生成、夸克智能问答、淘宝商品文案生成),实现“场景化原生落地”;3. 行业解决方案定制(如金融合规报告生成、零售智能客服、工业质检报告辅助)。 |
| 技术文档与工具 | 1. 发布《DeepSeek 技术白皮书》《API 开发指南》;2. 开源代码库(GitHub)包含模型训练/推理脚本、示例工程;3. 搭建开发者社区(论坛、技术交流群),提供“问题悬赏+技术答疑”支持。 | 1. 输出《通义千问 企业应用开发手册》《多模态能力接入指南》;2. 内置阿里云控制台的“可视化模型调优工具”(如Prompt 工程模板、性能监控面板);3. 举办“通义开发者大赛”“生态伙伴计划”,联合高校/科研机构发布技术验证报告(如大模型推理效率优化)。 |
| 生态协作机制 | 1. 与高校(如清华、复旦)合作开展“大模型推理效率”课题研究;2. 联合垂直领域 ISV(独立软件开发商)打造行业插件(如法律合同生成插件、医疗报告辅助插件);3. 开源社区驱动的“模型迭代”(开发者可提交代码补丁、数据增强方案)。 | 1. 内部协同阿里云(云计算算力)、达摩院(多模态技术)等技术团队;2. 外部联动 ISV 构建“行业解决方案联盟”(如零售领域联合有赞、金融领域联合恒生电子);3. 钉钉/夸克等产品的“用户反馈-模型迭代”闭环(企业用户需求直连算法团队)。 |
| 分析维度 | DeepSeek | 通义千问 |
|---|---|---|
| 变现模式 | 1. ToB 技术服务:按 API 调用量、定制化项目收费(如金融机构专属模型训练);2. 开源生态变现:通过“开源模型+付费企业级支持”(如技术运维、合规咨询)盈利;3. 行业解决方案订阅:针对法律、医疗等领域推出“预训练模型+行业数据包”订阅制。 | 1. 云服务生态内增值:阿里云客户按“模型调用时长+算力资源”订阅 MaaS 服务;2. 行业解决方案项目制:为金融、政务等客户提供“定制化训练+私有化部署”全链路服务(单项目百万级客单价);3. 生态流量变现:钉钉/夸克等产品的“智能功能付费”(如高级会议纪要、专属智能客服)。 |
| 核心竞争壁垒 | 1. 技术创新壁垒:MoE 架构的“能效比优势”(同等算力下任务处理效率领先)+ RLHF 微调的“对话体验优势”(自然度、专业性行业领先);2. 垂直场景壁垒:在代码生成、法律/医疗垂直领域沉淀“行业数据包+专属模型”,形成差异化替代难度。 | 1. 生态壁垒:阿里系场景的“天然数据+需求闭环”(如电商客服场景的千万级日活对话数据,反哺模型迭代);2. 合规壁垒:深度符合国内数据安全法规(如《生成式AI服务管理暂行办法》),服务政企客户无合规顾虑;3. 多模态先发优势:图文生成、跨模态理解能力在“内容创作、营销设计”等场景快速落地,抢占市场空白。 |
| 分析 | 内容 |
|---|---|
| N(Need,需求) | 核心需求 :开发者在编写代码时,有强烈的需求确保代码质量,但缺乏即时、专业、深入的代码评审资源。尤其是学生和中小团队,难以配备专门的架构师进行频繁的 Code Review。 隐性需求 :提升个人编程技能、降低项目维护成本、培养良好的工程习惯。 |
| A(Approach,做法) | 开发一个 IDE 插件(如 VSCode、JetBrains 全家桶插件)。插件会索引整个项目代码,建立上下文图谱。利用微调后的强代码模型(如 DeepSeek)实时分析代码变更。在代码编辑器和问题面板中,以不同等级(提示、警告、错误)展示智能建议。为每个建议提供详细解释和“一键重构”的代码差异对比视图。 |
| B(Benefit,好处) | 对用户 :代码质量显著提升,个人技能快速成长,开发过程更安心。 对我们(产品方):能吸引大量对代码质量有要求的开发者(尤其是学生和专业开发者),建立技术口碑,形成付费转化点(如高级重构策略、企业级代码规范定制等)。 |
| C(Competitors,竞争) | 直接竞争 :SonarQube 等静态代码分析工具。但它们是“事后”扫描,不实时;交互性差,建议较为机械。GitHub Copilot 的聊天功能需要用户主动提问,不具备“主动性”。 我们的优势 : 实时性、交互性、智能化程度更高。将静态分析的能力与 AI 的上下文理解和代码生成能力结合,体验更流畅。 |
| D(Delivery,推广) | 初期 :在开发者社区(如 GitHub, V2EX, 知乎)发布免费或具有慷慨免费额度的版本,吸引种子用户。 中期 :与高校计算机课程合作,作为教学辅助工具推广给学生。 后期 :推出团队版和企业版,提供更复杂的项目分析、自定义规则集、与 CI/CD 流水线集成等功能,实现商业化。 |

附录:
代码地址

你们设计的评价维度是基于哪些用户购车场景和技术痛点提出的?现在设计的评价维度能实现这个目的吗

1.请给出如何使用谷歌AI工具来自动调用两个LLM完成购车场景的评测,给出设计方案。
2.“20 万元预算、城市通勤为主、注重空间舒适与安全性”这个购车场景可以变更吗?会如何影响你的自动化测试代码?


