



271
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享主函数MainClass只负责解析输入,其内容存入inputInfo之后传递给commandOperation.class进行识别和处理。
对于工程中涉及的诸多类而言,其大致可以被归类为adventurer,bottle,equipment和spell,这是在第三次作业建立起来的基本架构,后期迭代并未修改而是基于这三者进行增补统合。
adventurer是这个游戏的核心,应当和其它三类物品分开讨论。
adventurer几乎囊括了所有信息,一个人物的属性,其背包,物品栏,雇佣关系全都集成在此,并且设置了多种检索方法以面对不同的情况,几乎可以肯定有赘余,但不敢轻易重构。
人物属性,包括name/hitpoint/def/mana/money/death。
背包,包括bottles/equipments/spells。
物品栏,包括bottlesTaken/equipmentsTaken/armoursTaken,以及物品栏数量bonum/wpnum/amnum,以及物品栏的数量上限。
雇佣关系,包括staffs/boss。
其中后三者通过容器来实现。
在项目早期,人物的每个属性都有一个独立的方法用于读取。但是这存在两个问题,一个是代码冗余,一个是在实际运用的过程中可能需要根据情况的不同而调用不同的方法,相比于在外部的诸多位置添加选择语句,不如把选择语句放到adventurer内部。于是我们有了getData。基于同样的理由,对于属性数值变动的方法,我也进行了汇总。
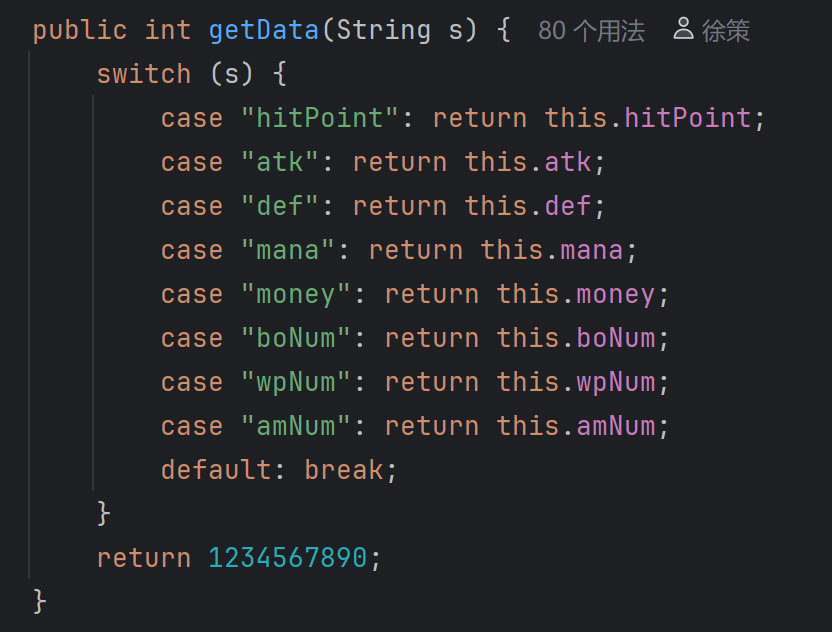
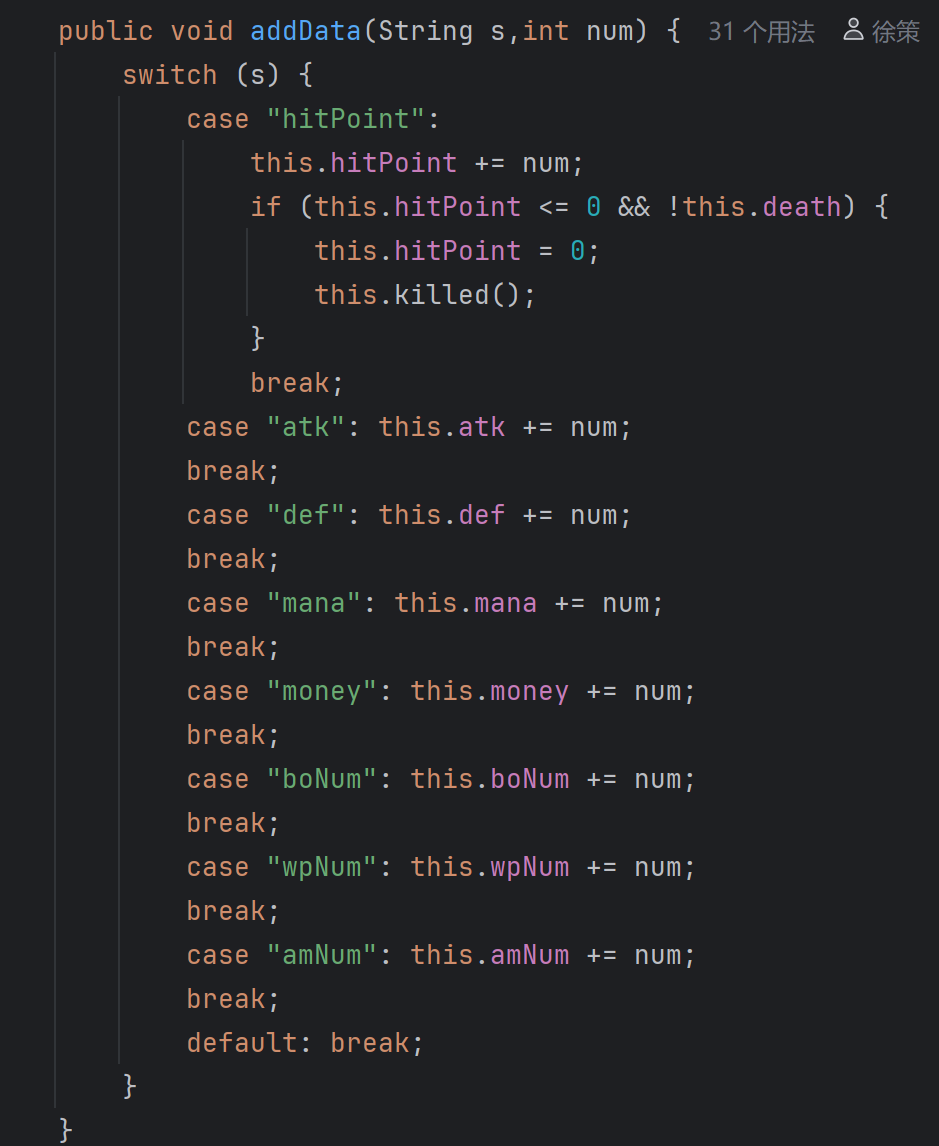
游戏过程每条指令都涉及人物的信息变化,因此,实际上几乎所有的操作最终都要通过adventurer中的方法来实现。包括但不限于添加物品/学习法术/购买物品/雇佣下属/使用usable。只有fight指令被单独设置在commandOperation下,因为其涉及的人物略多,而且这意味着需要在方法中大量传递容器,管理起来比较麻烦。
adventurer当中有一个缺点——其高度依赖检索。在所有的方法中,我们很少见到直接传递class类型参数,更多的是以字符串形式传递id和type,然后再adventurer内部进行检索和匹配。(多数情况下是在指定容器内,少数时候得把若干个容器全都检索一遍。)
这种方法对时间效率有严重影响,但好消息是它符合作业要求的逻辑,因为名字在我们的作业中具备唯一性,非常重要。这样做虽然笨拙,但的确可以避免出错。
同样笨拙的地方还在于大量的选择语句。譬如在物品购买的相关过程中,我并未使用工厂模式,而是依照大的分类通过枚举方式简单地设置了分支。
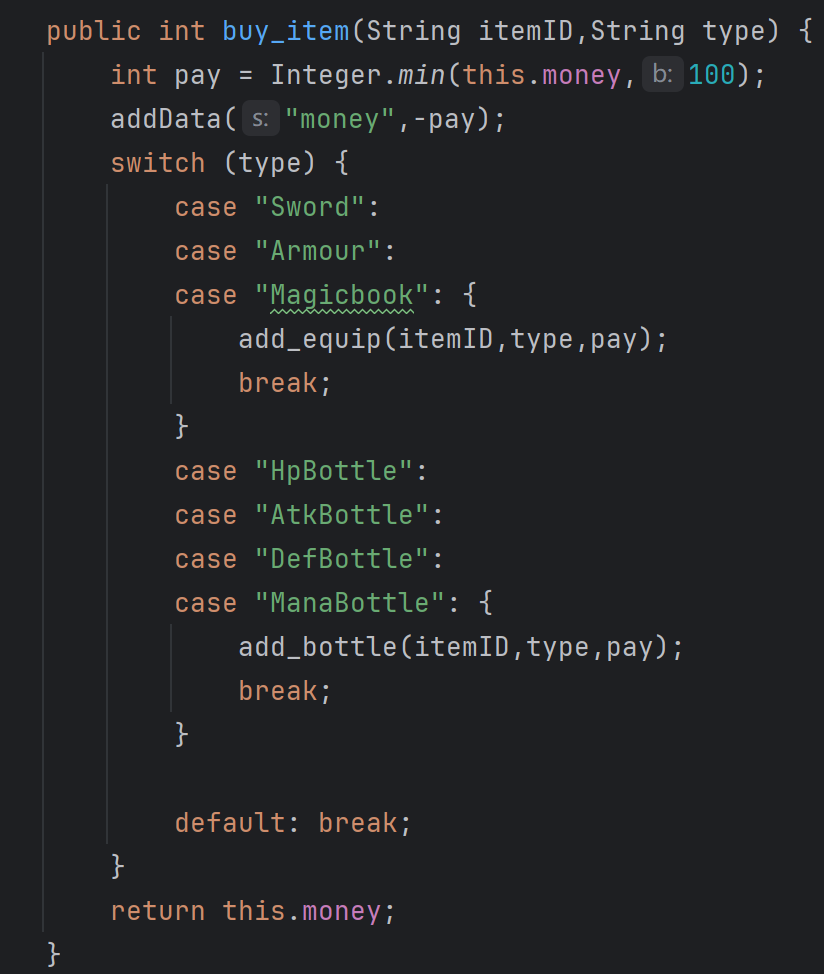
主要原因是在添加物品的时候已经使用了选择语句作为区分,在此基础上编写购买并没有进一步的障碍。
倘若物品的类别大幅增多,使得枚举法手敲type敲不过来,我或许会不得不将代码重构为工厂模式。
雇佣关系是值得一提的部分。我们知道雇佣关系可以用一棵树来描述,但是在fight和use的指令中我们只关注双方是否为ally,深度、子树、遍历等信息都不重要,树的结构也很少发生改变。因此这棵树实际上是单向的,而且是子向母。换言之,冒险者知道boss是谁,但不知道自己的下属是谁。因此,方法也只能判定一个人物是否为自己的直系上级。如果想要判断是否为ally的话,只需要双方都进行一次判断就可以了,同盟关系决定了二人必然有一人是另一人的直系上级。
当然,我确实加入了staff容器列表,但实际上它唯一的作用是,在该人物死亡使得它的每个雇佣者都清空自己的boss,这个功能完全可以通过遍历所有冒险者来实现。加入容器只算是空间换时间,没有进一步的作用。
在物品的部分当中,我使用了继承和接口。
bottle和equipment被设置为抽象类,其中equipment又分为weapon和armour,weapon也是抽象类。四种bottle继承了bottle的属性并且可以被统一add和remove,equipment的情况类似。
item是接口,因为一些情况下bottle和equipment具备共性。usable则是因为在use指令时bottle和spell具备共性。二者分开使用是因为是分开学的,现在想想,或许接口也可以用来统合四种bottle。
这一段的代码写的比较屎山。战斗分为useSpell和fight。其中useSpell的方法在spell这个类下面,相当于在commandOperation下我需要调用一个spell的方法,而不是像别的指令那样调用adventurer的方法。
而对于fight,可以说全部处理操作全都塞到了commandOperation下面,因为这个放到adventurer下面不合适,但是fight指令又只与人有关。导致本来一一对应干净整洁的commandOperation多了一整套方法,从物理攻击到魔法攻击,这当中还需要为无武器的情况做个特判。
assist也集成在这里,操作复杂而且不能像死亡判定那样自动执行。
总之感觉优化空间很大。
繁琐但有用。
编写junit确实可以有效地找出bug,但是编写junit的过程十分折磨,需要反复初始化,思考该如何断言,尽可能地去覆盖分支。如果有分支没有考虑到的话,可能连带着会有bug也没法发现。
推测,正确的用法可能是程序一边写,junit一边写。这样的话看着刚刚写完的方法,你最明白该怎么用,可能有哪些分支,junit好写。有bug也可以当场发现,不然等中测的时候出了bug就难找了。
面向对象和面向过程可以说是两种截然不同的编程思路。前者像是集中式地统一调控,后者则是分布式的各行其是。
感觉面向对象更适合维护和迭代,而且好消息是上手还是比较快的。
重构是个大问题,因为在class里面你的视角是微观的,如果你心里没有一个俯瞰的视角,你就很难知道该做什么,做的事情又会影响到什么。
我感觉有些学的东西没有用上,而是用原始的低级的方法去替代,比如工厂和观察者就知道但不会用。不知道有没有办法促进学生对所学知识的应用?

