



271
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
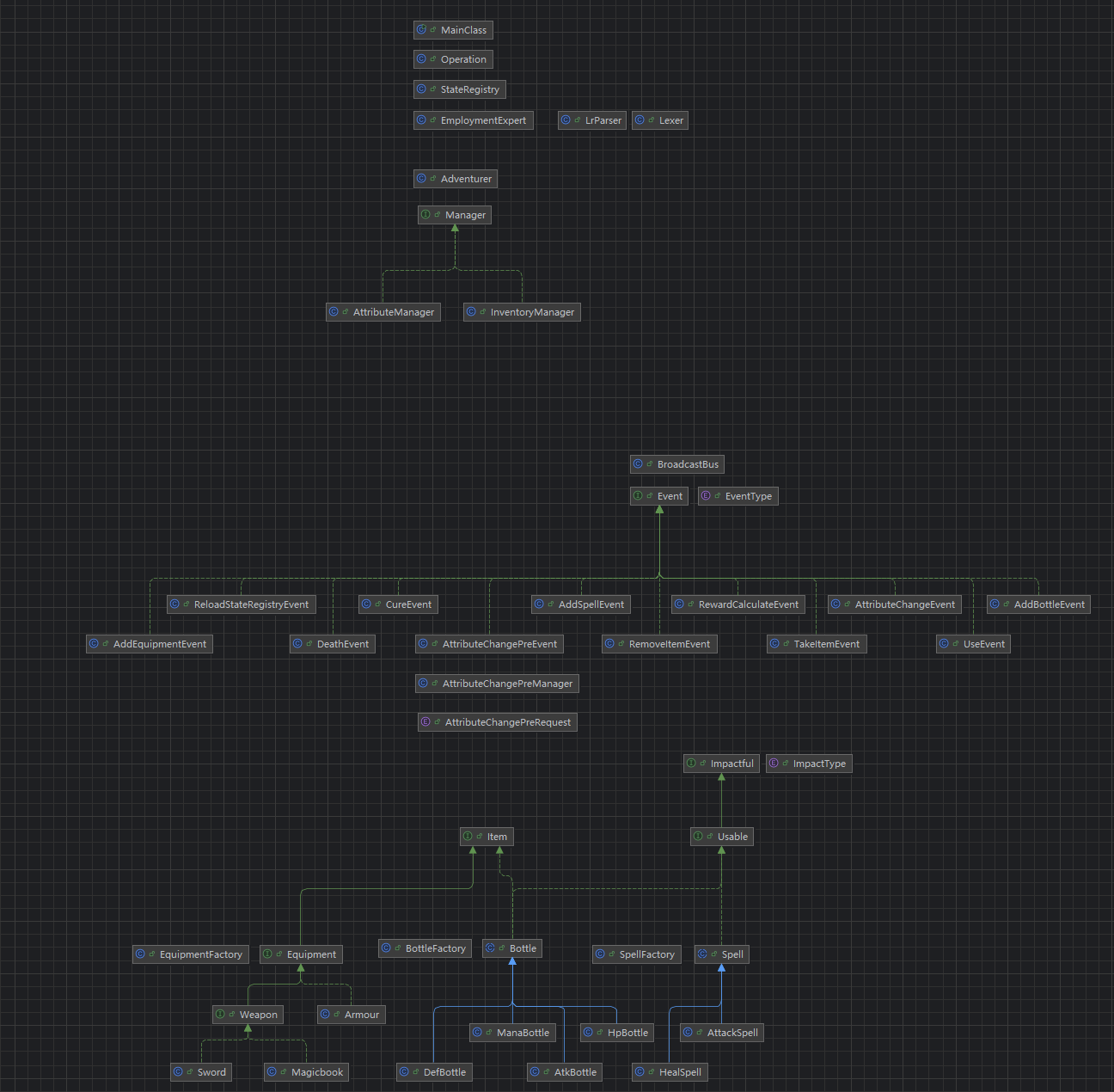
所有指令在按行拆分成二维字符串容器之后交给Operator(指令处理器)类进行处理,不让main入口过于臃肿
全局维护一个StateRegistry单例作为属性注册表,所有冒险者的属性在变化后都重新注册自己的属性信息,具体实现使用HashMap<String, HashMap<String, Object>>,使用*"项目.冒险者id"*的格式进行查询,好处是所有冒险者之于同一项目的全部信息在同一哈希表中,可以比较快速地比较所有冒险者的属性(例如只需遍历即可找出生命最多的冒险者,虽然并没有用到)
定义一个EmploymentExpert单例作为管理雇佣关系的工具类,用两个哈希表维护雇主和雇员信息,可以分别以冒险者id作为键值获取雇主/雇员集合
LrParser和Lexer类是第七次作业中使用递归下降法处理lr指令用到的工具类
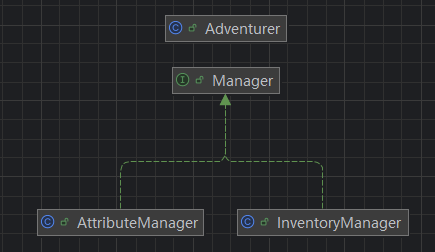
冒险者(Adventurer)类的实例代表了一个冒险者对象,比较特别的是,这个类只组合了两个实现了Manager接口的属性管理者和仓库管理者,而并没有过多的具体方法,这让冒险者物品和属性管理解耦,也避免了冒险者类成为一个方法过多的上帝类,更符合单一职责原则
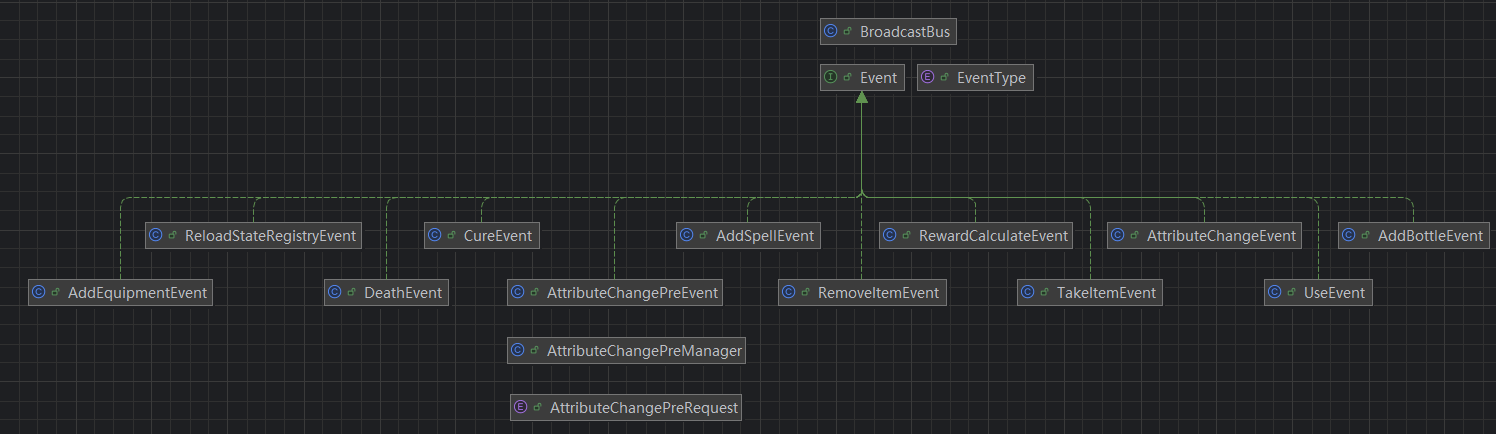
单例BroadcastBus是全局公告总线,用于不同类之间的沟通解耦合,采用观察者模式,在发布事件时向所有订阅了该事件的Manager传递Event,例如AttributeManager作为属性管理者就应该订阅属性变化事件和死亡事件,这样的好处是无论在哪个类中的方法,当需要特定冒险者做特定事情(例如使用药水时需要使用者丢弃这个药水瓶,目标对象发生属性变化)时不需要经历“找到冒险者→调用他的特定方法”的过程,减轻类之间的依赖关系
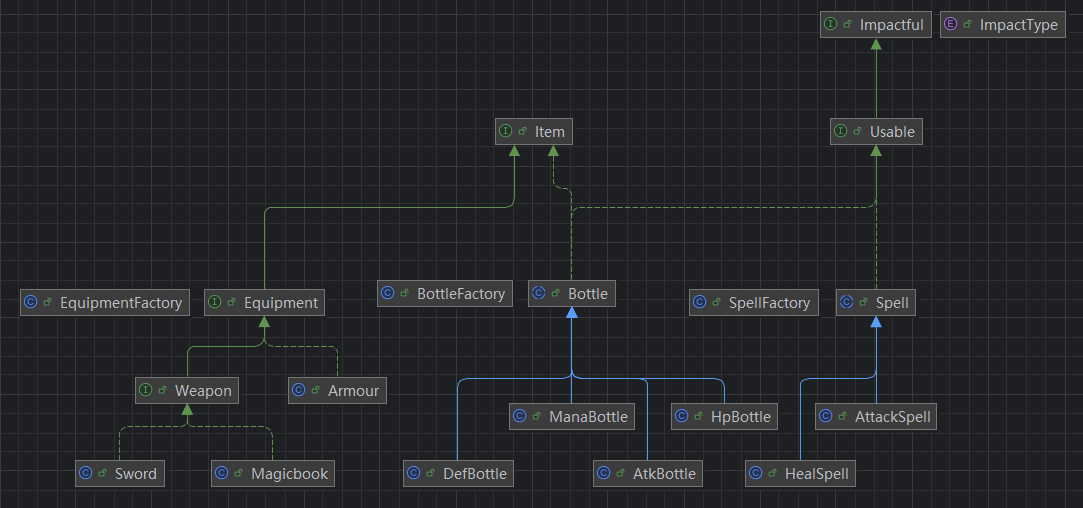
所有物品类,按照作业要求分层,注意所有的基类(即可被继承的类)都不应该能够被实例化,在一个良好的架构中,它们必须被声明为抽象类或接口,从而强制使用具体的子类来实现
在我的项目架构中,每个最常被提到的大类都使用工厂模式给出了构造方法(例如addBottle的指令或事件中会提到Bottle,而非其具体类,所以我将"实例化哪个具体类,以及怎么实例化"的工作交给工厂来决定)
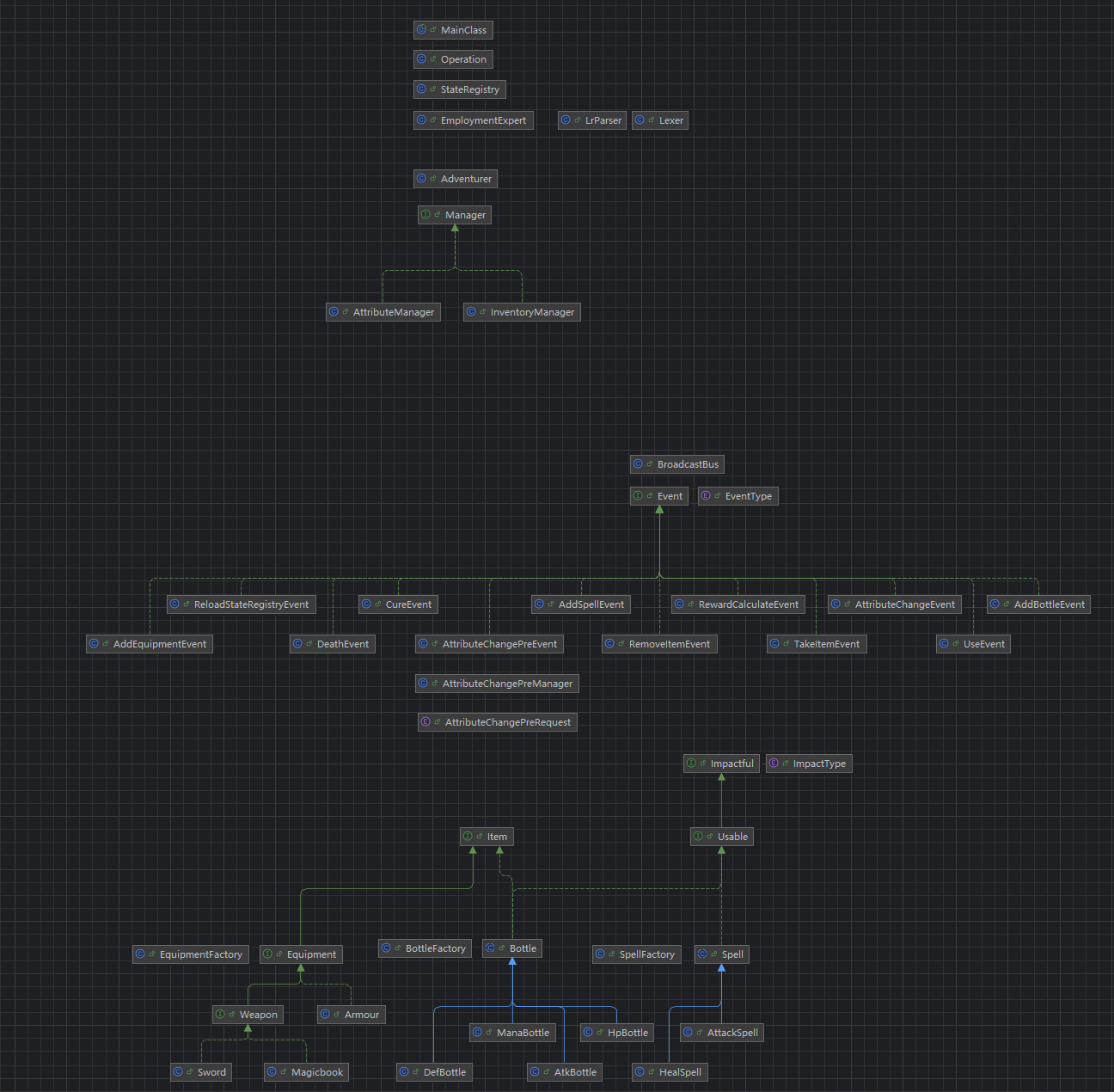
在第一次迭代(第二周作业)中,我采用的架构比较直白,包含需求中的四个类,Adventurer类管理自己的所有物品和属性,MainClass负责处理所有指令的操作
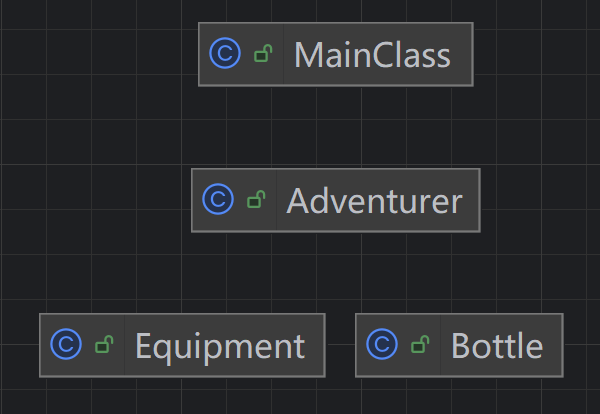
在第二次迭代(第三周作业)中,我按照作业要求增加了对于物品的分类,将Bottle设成抽象之后创建了具体实现类,创建Spell抽象类和具体实现类,同时根据Spell和Bottle类的use指令提取了Usable接口,定义了use方法并在具体类中实现,根据不同具体类重写了不同的实现方法,例如Spell的use方法是减少使用者的魔力值并对使用对象的属性值造成影响,而Bottle的则是调用使用者丢弃药水瓶的方法并对于使用对象的属性值造成影响
此外,我将对于指令进行分析的功能从主类里面拆分到Operation了,Operation接受一个传入的代表了拆分后的指令的二维字符串容器,并在类内维护一个冒险者列表(此时使用ArrayList实现,后面的迭代中为了查找效率改用了哈希表HashMap)
这样拆分是在这门课程中推荐的架构,主要原因其一是在我们作业的评测中需要测试测试代码的覆盖率,但是主类不会计入覆盖率计算中,即主类的覆盖率将始终是0%,这导致一个很长的MainClass很可能降低我们的总覆盖率,导致达不到课程对Junit覆盖率的要求;其二,即使在一个真实的项目场景中,主类也不应该承担过多任务,在一个理想的架构中,主类应该只承担代码入口的功能,所有其他工程需求的实现都应该在对应的工具类里面完成
顺便一说,我的Operation类目前的架构其实仍然不是很理想,而在之后的迭代中我也没有对此进行优化,这些问题我会在后面统一反思
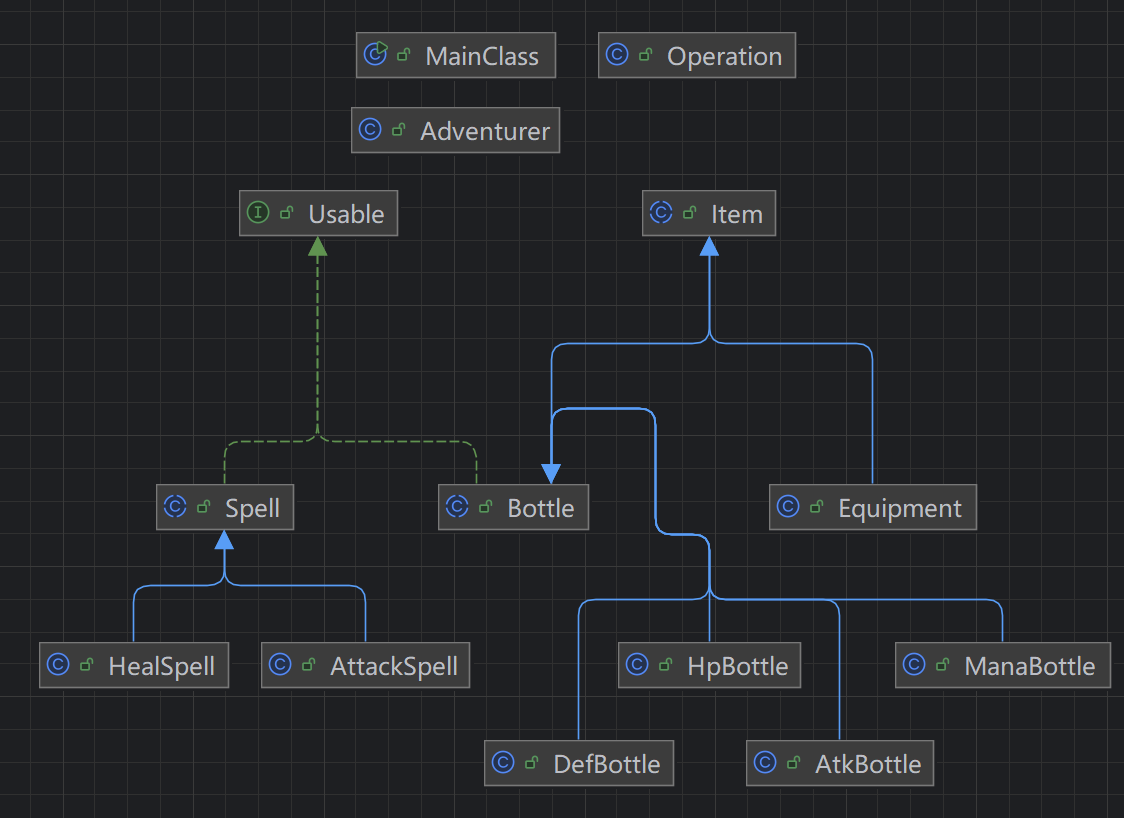
在第三次迭代(第五次作业)中,指导书讲解了工厂模式的实现,并建议我们自行学习设计模式,这激发了我的兴趣。我查找了很多博客和视频资料,使用了一些prompt工程搭建了专用的agent来帮我解答问题,最终基本了解了面向对象编程的SOLID原则和相当一部分设计模式的使用方法(这个part只会简单介绍一下我项目中的内容,我会在后面专门介绍我对于设计模式的学习内容,看不懂的同学们可以先看后面)。利用这些知识,我迫不及待地重构了我的代码,采用了一些比较复杂的技巧,力求实现完美的解耦和扩展性
具体来说,我首先采用了两个Manager类解耦了冒险者的属性和物品管理,并通过组合模式将其加入冒险者属性中,这样避免了冒险者类成为一个实现了所有方法的上帝类
我采用总线模式(Bus模式,即单例模式+观察者模式)实现了发布和响应事件,以BroadcastBus作为总线发布者,这里的Manager接口就是观察者模式中的订阅者,定义的各种Event的实现类持有特定的EventType,并且储存着各个管理者处理这个事件时需要知道的所有信息,这样,当任何一个类需要某个冒险者进行属性变化或者物品变化时,它不找到那个冒险者而是编辑一个对应的事件(内容类似"冒险者a,使你的HitPoint属性改变x")并发布到总线,总线则将这个事件交给所有关心这个类型的事件的管理者去处理*(例如前述事件就会交给属性管理者AttributeManager)*
一个冒险者类的实例化过程比较复杂,我利用建造者模式来处理,并在建造过程中就让Manager各自订阅自己关注的事件
我采用状态注册表(单例模式静态哈希表)来实现全局信息共享,主要考量是:1.使用法术的场合需要判断法力值是否足够,但是法术管理在InventoryManager中,而法力值信息在AttributeManager中,信息交流很不方便;2.战斗事件中需要知道计算了装备加成之后的攻击力和防御力数值,但是基础属性和装备加成的信息分别在两种管理者中,查找起来也不是很方便,更别说如果对象是复数,还需要逐个查找并比较;3.指令结束经常需要打印属性值,放在注册表中查找很方便
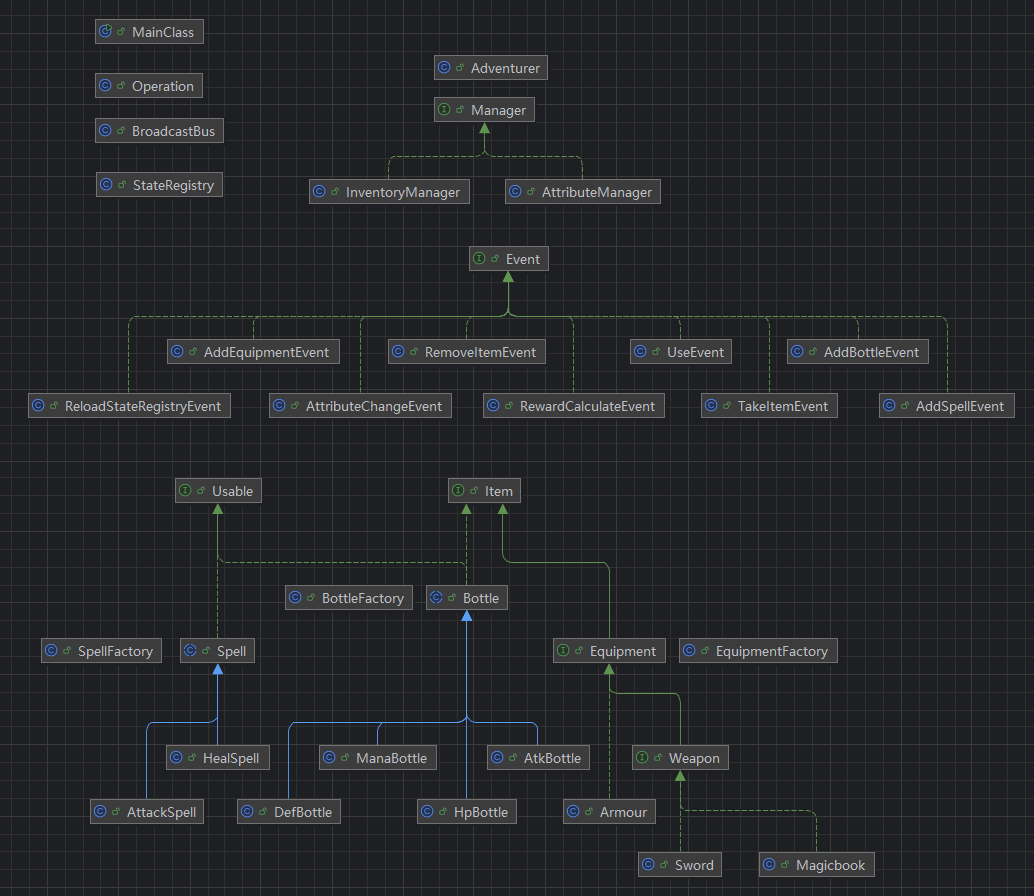
事实上,我的方法虽然的确优化了架构,解决了一部分问题。但是由于是初学设计模式一拍脑袋写出来的,这些问题解决得并不够理想,对于各种模式的使用也有点刻意,我在后面会探讨更加简洁有效的优化方式;更重要的是,这次重构几乎耗费了我四天无休的全部时间,并在最后证明虽然功能扩展变简单了,但是debug工作以及写测试代码的工作变得相当困难,并没有像预期中一样明显简化我的后续迭代工作
所以各位切记不要陷入过优化漩涡,
适度优化益脑,沉迷优化伤身
第四次迭代(第六次作业)的需求中要求实现建立冒险者之间的雇佣关系,并定义了上下级和盟友关系(上级:直接雇主或者雇主的上级;下级:直接雇员或者雇员的下级;盟友:上级,下级,以及自己);设置了雇佣关系约束为“有益的效果只能对盟友施放,有害的效果(包括战斗)不能对上级施放”;并定义了援助事件为“一个冒险者在一条指令中生命值下降为开始时的一半时触发,所有他的下级尝试对他释放当前拥有的power最高的治疗法术”;最后要求死亡的冒险者的节点会从雇佣关系图中被移除
雇佣关系的实现比较简单,我创建了一个雇佣专家(EmploymentExpert)工具类,使用单例模式,包含两个哈希表HashMap<String, String> checkEmployer和HashMap<String, HashSet<String>> checkEmployee,在添加一个雇佣关系时,只需要将雇主的id添加到checkEmployer的雇员id键下,并将雇员id添加到checkEmploee的雇主id为键的雇员集合里;在移除一个雇佣关系时,也只需要对称地移除雇主对雇员的雇佣关系和雇员对雇主的被雇佣关系即可;最后,在冒险者死亡时移除节点的操作中,假设这个冒险者id为A,我们访问checkEmployer的A位置,找到该冒险者的雇主,不仅移除这个键值对,并且移除该雇主在checkEmployee中的雇员列表中的A的信息,然后访问checkEmployee,找到A的全部雇员移除关系,并且对称地在checkEmployer里面移除这些雇员的雇主信息,如此一来通过对称的操作,我们很轻易就删除了A节点,而无需遍历整个哈希表,删除所有键或值为A的键值对(我发现很多同学都是这种思路,会不太优雅)
雇佣关系约束也比较简单,我首先让所有能够造成效果的类Impactful接口,并在接口中定义了getImpactType方法,返回值为ImpactType枚举类型(positive或者negative中的一个,我还定义了一个neutral,没有用上);雇佣专家类里面实现了验证某一冒险者是否为另一冒险者上级/下级/盟友的方法(定义为isSuperior(String base, String target)类似的形式),通过栈实现(这里注意,由于上级和下级都不包含冒险者自己,所以我们在检查上级(下级)关系时先将base冒险者的全部上级(下级)压进栈,然后执行“弹栈→判断是不是target→将该冒险者的上级(下级)压进栈”的循环,循环条件是栈非空);最后在雇佣专家里面提供一个统一的验证效果是否符合雇佣约束的方法,根据传入的ImpactType类型,如果是positive则返回isAlly(base, target)的结果,如果是negative则返回!isSuperior(base, target)的结果
最后是援助事件的实现,鉴于“所有的伤害事件都应该有概率触发援助”,我重构了属性变化事件的实现,增加了一个属性变化预处理器和一个属性变化预处理事件,为属性变化事件增加了传入参数为预处理事件的构造函数,预处理器中执行一个预处理事件的过程为:处理预处理过程的行为(preprocess)→发布一个对应的属性变化事件并处理变化阶段的行为(change process)→处理后处理阶段的行为(postprocess),最早对于预处理器按需处理,我使用的是装饰器模式+工厂模式,想法是在预处理事件AttributeChangePreEvent中传递一个预处理需求列表,包含“进行死亡检测”“进行援助检测”等需要在这次属性变化事件中处理的业务,这部分略抽象,而且我的代码中已经重构掉了,各位可以看看我下面给出的代码示意:
//这是基类和装饰器共用的接口
//定义成private因为这是AttributePreManager的内部接口/内部类
private interface Processor {
AttributeChangePreEvent getEvent(); //这是要处理的事件
Map<String, Object> getInfoBoard(); //这是处理器中的共享信息
void process(); //处理的入口方法
void preprocess(); //预处理阶段的行为
void changeProcess(); //属性变化阶段的行为
void postprocess(); //后处理阶段的行为
}
//这是基类,定义了没有额外需求时的预处理行为
private static class SimpleProcessor implements Processor {
private final AttributeChangePreEvent event;
private final Map<String, Object> info;
private SimpleProcessor(AttributeChangePreEvent event) {
this.event = event;
this.info = new HashMap<>();
}
@Override
public AttributeChangePreEvent getEvent() {
return event;
}
@Override
public Map<String, Object> getInfoBoard() {
return info;
}
@Override
public void process() {
preprocess();
changeProcess();
postprocess();
}
//预处理没有行为
@Override
public void preprocess() {}
//发布属性变化事件
@Override
public void changeProcess() {
BroadcastBus.publish(new AttributeChangeEvent(event));
}
//后处理没有行为
@Override
public void postprocess() {}
}
//装饰器抽象类
private abstract static class Decorator implements Processor {
private final Processor wrapped;
public Decorator(Processor processor) {
this.wrapped = processor;
}
protected Processor getWrapped() {
return wrapped;
}
public AttributeChangePreEvent getEvent() {
return wrapped.getEvent();
}
public Map<String, Object> getInfoBoard() {
return wrapped.getInfoBoard();
}
@Override
public void process() {
preprocess();
changeProcess();
postprocess();
}
@Override
public void preprocess() {
wrapped.preprocess();
}
@Override
public void changeProcess() {
wrapped.changeProcess();
}
@Override
public void postprocess() {
wrapped.postprocess();
}
}
//对于某一需求的装饰器实现类
private static class SpecializedDecorator extends Decorator {
public SevereDamageDecorator(Processor processor) {
super(processor);
}
@Override
public void preprocess() {
super.preprocess();
//这个装饰器应该在预处理阶段干的事情,注意在super后面,所以越外层的装饰器的执行顺序越靠后
}
//如果没有应该在某一阶段干的事情,就不重写,例如这里就没有重写change process
@Override
public void postprocess() {
super.postprocess();
//这个装饰器应该在后处理阶段干的事情
}
}
//工厂类
private static class ProcessorFactory {
private static create(AttributeChangePreEvent event) {
Processor processor = new SimpleProcessor(event);
//结合前面说的装饰器执行顺序,可以注意到,在requests列表中靠前的需求会被优先执行
for (AttributePreRequest request : event.getRequests()) {
switch (request) {
case /*requestType*/ : {
processor = new /*SpecializedDecorator for this request*/ (processor);
break;
}
//其他的case
default:
}
}
return processor;
}
}
这个架构其实还是不错的,最重要的是能够以一种非常优雅的方式完成整个援助事件中最令人头疼的问题:“如何判断属性变化后的生命值是否降到了变化前的一半?”,在最简单的架构中,我们可能会直接更改所有涉及属性变化的指令,包括use和fight,在指令开始时使用临时变量暂存一个初始Hp,然后在指令结束之后再次获取Hp信息并判断是否触发援助。这样的架构需要我们手动修改多个指令的实现方法,并且在可能的,添加新指令的后续扩展中,我们仍然需要为是否进行援助提供判断和执行代码;此外,这样的代码解耦很差,即使尝试将援助的逻辑封装成一个方法,以此来进行代码复用,我们仍然需要在指令开始时获取生命值信息并在指令结束时作为参数传入援助的方法中,类似这样:
private void use() {
initialHp = getHp(target); //获取hp逻辑伪代码
use; //use逻辑伪代码
rescueTrigger(initialHp, target); //援助事件触发器
}
private void rescureTrigger(int initialHp, String target) {
finalHp = getHp(target);
if (finalHp > 0 && finalHp <= initialHp/2)
{
rescure(target); //援助伪代码
}
}
也就是说采取这种架构,我们不能很好地将所有指令的所有有关援助事件的逻辑封装在同一个方法中。相比之下,使用预处理器的思路,我们只需要修改援助相关的装饰器(我这里叫severeDamage,重伤事件),使其在预处理阶段(preprocess)将初始生命值存入上下文信息中(这里是infoBoard),并在后处理阶段将其取出并与当前生命进行比较即可,这样所有援助相关的逻辑就全部被封装在同一个装饰器类里面了,如果想要修改援助逻辑,我们只需要修改一处地方即可
最后讨论冒险者死亡,我们在前面已经提到了如何处理从雇佣关系图中移除一个节点的操作,现在的问题就是如何在每个属性变化之后判断一个冒险者是不是死亡了。在我们的架构中,这个处理可谓是非常简单,我们只需要在预处理器中增加一个对于deathCheck的需求,并创建一个专门装饰器,使其在后处理阶段检查对象Hp是否等于0,并视情况委托雇佣专家删除对象的节点即可。另外,我尝试发布一个死亡事件,对于这个事件的处理会让隶属于已死亡的冒险者的AttributeManager和InventoryManager取消在总线上的所有订阅,但是我debug的过程中发现,这样的事件会使总线在尚且在发布一个事件的过程中(此时正在用for循环遍历subscribers),非迭代器地修改总线的subscribers列表,导致**ConcurrentModificationException** (这是在使用增强for循环时修改集合会导致的常见报错,大家千万不要以为是个只会出现在多线程里面的错误,我当时刚看到都懵了www),虽然我后来做了在遍历之前提取subscribers快照的修改,但是好像仍然有不知名bug,所以最后还是注释掉了,等待有缘再改吧,毕竟除了能稍微优化一下内存以外并没有什么用处
至此我们的架构已经讨论完毕了,听起来解决得十分完美对吧?然而理想很丰满现实很骨感,首先是我这样的架构没有考虑到fight指令对于同时处理多个属性变化事件的需求,导致如果维持原有逻辑,即将第四次迭代之前的,“对于所有的战斗对象挨个发布属性变化事件”的逻辑简单修改成“对于所有战斗对象挨个向预处理器发布带有援助和死亡检测的属性变化预处理事件”,会导致一次fight中即将死亡但尚未被处理到的冒险者仍然能够援助位于前面的冒险者,这与预期是不符的;其次就是我一开始并没有看到“援助事件的信息应当在原指令后输出“的要求,所以想当然地直接开始写了,由于我采用的预处理器逻辑对于一次属性变化事件的处理中将嵌套完成援助,而指令结果的打印又在属性变化事件之后,所以我实际上打印的信息正好相反,援助信息会最先被打印
对于上述问题的处理,首先我尝试将打印信息的任务作为一个request重构进预处理器里面处理,这样只需要保证打印信息的执行优先级高于援助,就可以先打印指令中需要打印的信息,再进行援助的处理。但是这样一修改,fight指令对于多个目标的输出就会变成“*[a的生命]* [空格] [a的援助信息] [换行] *[b的生命]*…”这样的,跟我想要的“统一输出所有剩余生命值,再统一输出所有援助信息”不符,所以我利用多态重载了预处理器的处理方法,加入了对于一个事件集合的批处理能力并在fight指令的处理中采用了批处理模式,在批处理中,我们不再使用processor定义的直接入口方法process(),而是分层处理,在处理完所有processor的预处理阶段之后再处理变化阶段,以此类推。最后,为了修正前述的“一次fight中即将死亡但尚未被处理到的冒险者仍然能够援助位于前面的冒险者”的bug,我在分析了项目要求后理解到这应该是一个完全的“AOP”(面向切面编程),也就是说不同的request应该被作为不同的切面来水平处理,而非像现在这样垂直处理,我不得不将装饰器模式重构为插件(plugin)架构,将所有的额外处理功能通过功能插件组合到处理器中,这样在批处理中,我就可以通过指定某一插件类型,平行处理所有处理器中同类插件的功能,具体实现大家可以阅读一下我的代码,不再赘述
我不得不承认,这次作业是我所有迭代中完成的最差的一次,我不仅没能实现全部我想要的功能,还留下了相当多的bug,导致我中测提交次数超过了10次,强测也因为一个隐蔽的问题没有拿到满分,很大程度上应该归咎于我读题不认真,并且跳过了代码重构之前的分析步骤。首先是前述的对于
fight的处理失当,其次是我不得不将所有属性变化相关的打印任务重构进预处理器中,变动很大,而且我被迫写了一个printHpWhenPost和一个printAttributesWhenPost的预处理需求,由于其他非属性变化的指令的打印仍然在Operation类中,而且从项目架构来说,所有指令的打印任务确实还是应该由Operation负责,即所有对于一个指令应该干什么的解读都应该由Operation类来管理,所以这样的架构职责混乱,可以说是非常非常不优雅(sad

第五次迭代(第七次作业)只要求我们实现lr这一个新指令,并且讲解了递归下降法的思路,我其实只加入了Lexer和LrParser两个新的类,写起来非常轻松(就花了不到两个小时,还有一部分时间用于找出了一个第六次作业中遗留的bug)
先让我来把题目摆在这里:题目中运用了一个语法树来描述雇佣关系,在一条关于雇佣关系的指令中,我们需要做的是分析指令所构建的语法树关系,并依照语义增加雇佣关系,其中语法关系是:已知冒险者id为a,b,c,d…,a(b,c)的格式代表a雇佣了冒险者b和c,即小括号之前的冒险者将分别雇佣括号中的(用逗号隔开),对于括号中的冒险者,这个语法可以嵌套,例如a(b(c,d),e)代表a雇佣b和e,b雇佣c和d
相比于递归下降法的经典实现中构造语法树+针对语法树进行处理的方式,我这里使用了一些偷懒的方法:由于lr指令的处理需要的上下文信息极为有限,所以我直接将语法分析与指令处理一起在parser里面处理了。具体来说,我在Lrparser定义了四个方法,其中一个是入口方法parse(),一个是isIdentifier(token),是用于识别一个字符串是否符合冒险者id的格式的,一个是对于一个图的处理的parseGraph(emplyer),一个是对于一个冒险者列表进行处理的parseList(employer),我们定义一个图和列表的格式是:
<graph> → <identifier> ['(' <list> ')'];
<list> → <graph> {',' <graph>};
<identifier> → (字母 | 数字 | '_'){字母 | 数字 | '_'};
这里看不懂的话可以自行搜索“扩展巴科斯范式”(EBNF)或者“巴科斯范式”(BNF),即使不去搜索,你知道箭头表示定义,|表示或,中括号表示内部的内容可以重复0-1次,大括号表示内部的内容可以重复0-任意多次,也足以理解了
这样分析下来就简单很多了,我们可以看到,在我构建的语法体系中,graph承担了代表一个冒险者和代表一个雇佣图的双重功能,设图读到的第一个冒险者为a,当a后面没有小括号时,parseGraph(employer)所要做的全部工作就是建立入参employer与a的雇佣关系,即employ(employer, a),当存在小括号时,它还应该进行“读入左括号→调用parseList分析一个list并将a作为冒险者列表的雇主传入→读入右括号”;对于一个冒险者列表的分析,parseList(employer)的全部工作就是在分析一个图并将employer传入之后反复尝试读入一个逗号并分析冒险者列表中的下一个图;对于入口方法的处理,我们只需要调用parseGraph并传入空指针(或者空对象)即可
当然,我已经说过,这是一个偷懒的方法,主要问题是递归下降过程没有建立语法树,也就是语法分析跟语义分析在同时完成,这样的耦合关系在面对需求增加、语法变化等情况下很可能需要很大的重构开销,建议各位在实际需求中谨慎使用(而正是由于我们已经没有迭代作业了,我才放心大胆地将两个耦合起来了www)
在一个严格的递归下降过程中,我们应该先建立语法树,再对语法树进行语义分析,这里我简单给出思路:
构建树结构:定义冒险者节点(AdventurerNode),子节点是其雇佣者的集合,也是冒险者节点
给出语法分析:
<adventurer> → <identifier> ['(' <list> ')'];
<list> → <adventurer> {',' <adventurer>};
<identifier> → (字母 | 数字 | '_'){字母 | 数字 | '_'};
给出构建过程:
AdventurerNode parseAdventurer()读取identifier并建立对应的冒险者节点,如果读到括号,将冒险者节点的子节点集合(ArrayList<AdventurerNode>形式)传入对于list的处理,返回值是该冒险者节点void parseList(ArrayList<AdventurerNode> employees)调用parseAdventrer并将返回的节点加入employees中,如果读到逗号,重复这一操作给出语法树解析过程:遍历语法树,建立所有子节点与其父节点的雇佣关系
在这个部分中,我将简要讲解我在OOpre课程的学习和相关的自学过程中学习到的知识,包括具体内容与我的使用心得
仅供学习时参考,限于笔者水平,可能会有疏漏和误区,欢迎指出勘误
从面向过程程序设计过渡到面向对象程序设计,我们不仅应当学习新的术语,更应当转变思考方式。我接下来就将从这两方面简述面向对象程序设计的入门路径
public)权限,所有类都能调用;受保护的(protected)权限代表只有这个类和其子类能够调用;私有(private)权限代表只有这个类自己可以调用。而对于一个类,如果其是一个外部类,我们一般定义为公有,进一步的关于内部类的知识比较复杂,我们在设计模式部分的前言来讲从面向过程进入到面向对象编程,我们应该具备更加强大的抽象能力。在面对一个任务时,我们的思路应该从线性地关注流程与步骤转变为关心主体与责任。我们在面对一个数据或一个行为时,应当进一步思考“它属于谁?谁应该负责它?谁又关心它?”;在面对一个业务时,应当进一步想“有几个主体?它们各负责什么?怎么协作?”等等
这里的介绍只是对于面向对象思考方式的概述,更进一步的诸多思路与技巧我会在接下来的讲解中详述
SOLID 原则是面向对象设计的五大核心原则,由 Robert C. Martin 提出,旨在提高代码的可维护性、可扩展性和可读性。这些原则包括单一职责原则、开闭原则、里氏替换原则、接口隔离原则和依赖倒置原则
单一职责原则 (SRP) 强调每个类只应负责一个功能或职责,每个类也只有一个因为软件定义的改变而变化的潜在原因。这样可以降低类的复杂性,减少修改时的影响范围
开闭原则 (OCP) 要求软件实体应对扩展开放,对修改关闭。通过使用接口和抽象类,可以在不修改现有代码的情况下添加新功能。例如,通过定义一个抽象接口来处理不同类型的支付方式,而不是直接修改原有代码
里氏替换原则 (LSP) 指出子类必须能够替换其父类而不影响程序的正确性。子类应遵循父类的行为约定,避免引入不兼容的行为。例如,正方形类不应继承矩形类,因为它们的行为特性不同(正方形的边长改变将约束所有边的变化,而矩形只约束对边,二者的行为不兼容)
接口隔离原则 (ISP) 强调接口应尽可能小,避免强迫类实现不必要的方法。例如,对于一个食物来说,“可食用”和“可购买”作为两种不同的功能应当写在不同的接口中,反之如果我们定义了一个商品接口同时定义了两种功能,当我们再试图加入一个不可食用的商品时,它不但需要被迫实现一个永远不可能用到的“食用”方法,而且可能导致bug的产生
依赖倒置原则 (DIP) 提倡高层次的模块不应该依赖低层次的模块,而都应该依赖于抽象;抽象不应该依赖于具体实现,具体实现应该依赖于抽象。通过面向接口编程,可以实现模块之间的松耦合。例如,司机类依赖于车辆接口,而不是具体的车辆实现
正确理解和遵循SOLID原则是一个良好的面向对象程序设计的必经之路,可以优化我们的代码风格,培养代码习惯,提升我们代码的可阅读性、易测试性、可扩展性
SOLID原则不是铁律,代码优化应该在与项目大小与代码能力适配的范围内进行
关于SOLID原则的详细内容可以参考面向对象编程的 SOLID 原则学习
写在前面:一些基础知识
想搞明白某些设计模式,必须要熟悉静态(static)的使用和行为,嵌套类(与内部类)的使用和行为,读者可以自行搜索学习,这里给出简要的讲解:
静态:如果一个类的属性和方法声明为静态(static),这个属性或者方法将不再属于这个类的实例,而是属于这个类本身,例如我们声明了一个小狗类,拥有属性age和一个对应的getter:
public class Dog { private int age; public Dog() { this.age = DEFAULT_AGE;} public int getAge() { return age;} }这里的age不是静态的,我们只能通过实例化一个小狗才能访问它的age
Dog dog = new Dog(); int age = dog.getAge();而如果我们使用的是一个静态属性或者方法:
public class Dog { private static int DEFAULT_AGE = 2; public static int getDefaultAge() { return DEFAULT_AGE;} }我们不是通过实例,而是直接通过类来使用它:
int defaultAge = Dog.getDefaultAge()嵌套类:嵌套类是指在一个类的内部定义的另一个类。嵌套类可以分为静态嵌套类和非静态嵌套类(内部类)。嵌套类的主要优点包括提高封装性、可读性和可维护性
静态嵌套类是使用static关键字声明的嵌套类。它可以直接访问外部类的静态成员,但不能访问外部类的非静态成员。静态嵌套类的实例化不需要外部类的实例
非静态嵌套类也称为内部类,它可以访问外部类的所有成员,包括私有成员。内部类的实例化需要先实例化外部类
注意:同一个.java文件中只允许存在一个public的顶级类,并且.java文件名必须与其类名保持一致,该文件中其他类必须定义为它的嵌套类;一个不是嵌套类的private类是没有任何意义的,一般不被编译器允许
全部设计模式知识可以在设计模式|菜鸟教程自行学习
也可以直接阅读祖师爷GoF(Gang of Four)的《Design Patterns: Elements of Reusable Object-Oriented Software》来学习
单例模式(Singleton pattern)是一种创建型设计模式,其特点是确保一个类只有一个实例,并提供了一个全局访问点来访问该实例
单例模式有多种实现方式,这里只介绍最常见的懒汉式和饿汉式方法
懒汉式:
public class LazySingleton {
private static LazySingleton instance; //类持有唯一实例
private LazySingleton() {}
//提供访问方法,并在第一次访问时实例化
public LazySingleton getInstance() {
if (instance == null) {
instance = new LazySingleton();
}
return instance;
}
}
饿汉式:
public class EagerSingleton {
private static EagerSingleton instance = new EagerSingleton(); //在类加载时即实例化唯一实例
private EagerSingleton() {}
public EagerSingleton getInstance() {
return instance;
}
}
懒汉式实现方法在第一次调用getInstance时实例化唯一实例,而饿汉式实现方法的单例在类初始化时即完成实例化,在实际使用的过程中,单例模式需要注意实例化时机
由于懒汉式的实例化在第一次调用getInstance时进行,所以建议将所有其他与这个唯一实例相关的方法写成非静态方法,并使用getInstance()./*方法名*/调用,如果写成静态方法,会需要在方法开始时检查单例实例是否存在,或者在项目入口使用getInstance显式实例化(这样就被饿汉式完爆了),非常不建议,代码参考如下:
假设这个类的作用是全局唯一的计数器,这里计数方法是非静态的:
public class LazySingleton {
private static LazySingleton instance;
private int counter; //将计数器作为单例实例的属性
private LazySingleton() {
counter = 0;
}
public EagerSingleton getInstance() {
if (instance == null) {
instance = new LazySingleton();
}
return instance;
}
//计数方法如果是非静态方法,则需要先调用唯一实例,再调用方法
public void count() {
counter++;
}
public int getCounter() {
return counter;
}
}
调用方法:
LazySingleton.getInstance.count();
int cnt = LazySingleton.getInstance.getCounter();
如果计数方法是静态的,则需要确保唯一实例存在:
public class LazySingleton {
private static LazySingleton instance;
private int counter;
private LazySingleton() {
counter = 0;
}
public EagerSingleton getInstance() {
if (instance == null) {
instance = new LazySingleton();
}
return instance;
}
//计数方法如果是静态方法,则不能保证调用时单例一定已经被实例化
public static void count() {
//非常不建议这么写,因为所有方法都面临单例可能没有被实例化的问题,需要考虑不应该属于其功能的任务
if (instance == null) {
instance = new LazySingleton();
}
counter++;
}
public static int getCounter() {
if (instance == null) {
instance = new LazySingleton();
}
return counter;
}
}
另外,懒汉式单例由于通过静态方法来实现初始实例化,所以在多线程中线程不安全,需要在getInstance方法中加锁来保证不会在多线程同时调用它时实例化多个实例(但是由于绝大多数情况下不会出现这种情况,加锁有明显性能浪费)
前面已经提到,饿汉式单例的实例化在类初始化时完成,但是类初始化是什么?这其实是一个值得一提的问题
一个类初始化的时机是“当它首次被主动使用时,它会被JVM初始化”,这里的主动使用常见的情况包括但不限于:
- 使用new实例化一个类的实例
- 访问类的静态变量
- 访问类的静态方法
- 反射
- 访问子类时,父类若未初始化
- 虚拟机启动时,会初始化定义了
main方法的类类初始化时,首先加载静态变量和静态初始化块;然后,如果正在创建类的实例,加载实例变量和非静态初始化块,并最后调用构造函数
可以看到,饿汉式单例也并非是程序执行的一开始就已经实例化了,但是当我们第一次主动使用这个单例类,类会首先初始化,单例就已经存在了,所以多数情况下,实例化时机不会对我们造成困扰,我们也不必要将getInstance以外的方法设成非静态,但是如果你在写代码时不清楚类初始化这个知识点,仍然有可能出现意想不到的bug。例如我在作业中曾经尝试过创建一个单例管理者,并在构造函数中向总线订阅自己感兴趣的事件,类似下面的代码:
//一个实现了Manager接口的单例,Manager接口就是总线的订阅者
public class SingletonManager implements Manager {
private static SingletonManager instance = new SingletonManager();
private SingletonManager() {
Bus.subscribe(/*event type*/, this); //向总线的订阅伪代码
}
public SingletonManager getInstance() {
return instance;
}
@Override
public void manage(Event event) {
//事件处理方法
}
}
由于我们还没有讲到观察者模式,我们先理解总线(Bus)的作用就是在某一种由event type标记的事件被向总线发布之后,遍历关于event type的订阅者(subscriber)并通知他们,我遭遇的困境就是直到这个SingletonManager被第一次主动使用为止,所有的事件都没有正确地通知它。现在我们掌握了类初始化的知识,我们可以很轻易找到病因:*SingletonManager被第一次主动使用以前,类尚未初始化,此时instance尚没有实例化,构造函数中的订阅方法从没有被调用。*解决方法也很简单:我们只需要在main方法中调用getInstance,即可在程序入口显式完成单例类的初始化
由于类初始化不同于普通方法的调用,天然具有互斥性,即类似class loader有一个类初始化锁来限制同步问题(这也很好理解,JVM不会允许我们在多线程场景下同时加载两个同样的类),故饿汉式单例天然线程安全,在一般工程场景中,我们一般使用饿汉式实现(除非我们有绝对不能出现未被使用就被加载的垃圾实例的要求)
注册表:维护一个全局统一的注册表,可以用于对象的统一记录和管理,在我的代码中,一个状态注册表只用于记录所有公开的信息,但是在真正的工程中,注册表往往统一提供实例化对象和访问对象的方法,可以负责管理对象、防止冗余创建和控制对象生命周期,具体可搜索注册模式学习
总线:全局统一的单例观察者模式发布者,所有类都可以调用它的方法来发布信息,并使关心该类信息的对象收到通知,具体实现可以结合后面的观察者模式学习(好像在工程中不是很常用,性能开销比较大,慎重学我)
日志工具:当我们尝试在不同类中打印日志时,日志写入工具最好使用单例,可以防止并发情况下多个Logger同时写入日志,导致错误
资源池:资源池是指系统中的一组可共享和可重复使用的资源集合,这些资源可以被多个应用程序或者进程同时使用,从而提高资源的利用率和效率。资源池包括数据库连接池、线程池、对象池等,以数据库连接池为例,当应用程序需要连接数据库时,可以从数据库连接池中获取一个已经创建好的数据库连接,使用完毕后将连接返回给连接池,而不是每次都重新创建和销毁数据库连接。由于这种池化资源是一种昂贵的、需要复用的资源,由单例管理比较合适
统一的ID生成器,以及类似工具:当我们需要生成全局唯一的ID或者类似的全局唯一的标识时,使用单例来管理是比较合适的,因为在同一个单例里面很容易判断生成的对象有没有重复的,反之如果一个工具类能被实例化多个,就难以协调了
任务列表:使用单例可以避免同一个任务被多个任务列表实例记录,导致被执行多次
静态工具类(可以作为一种简化写法):功能类似单例模式,但是这个类在全局没有任何一个实例,通过静态属性和静态方法提供某种全局服务,当我们有向全局提供不依赖实例状态的通用方法的需求时,可以尝试采取这种写法来代替稍冗长的单例模式,尤其是跟饿汉式单例实现效果类似(我的代码中没有使用,单纯是因为我当时没有意识到可以这样写)。参考代码如下:
//仍然以全局计数器为例
public class Counter {
private static int counter;
private Counter() {}
public static int getCounter() {
return counter;
}
public static void count() {
counter++;
}
}
工厂模式(Factory Pattern)是一种创建型设计模式,是Java 中最常用的设计模式之一。它提供了一种创建对象的方式,使得创建对象的过程与使用对象的过程分离。工厂模式的最大价值是将实例化一个对象的工作委托给专门工厂类来进行,尤其是当我们的需求是抽象而非具体类时,委托人很可能只需要持有对于某个抽象的引用,就能直接获得工厂模式提供的实例,而非自己来决定如何实例化,这很好地体现了单一职责原则
工厂模式一般有三种实现模式:简单工厂模式、工厂方法模式和抽象工厂模式,在GoF的书中,简单工厂模式并没有作为23种设计模式的其中之一而被提到,可以认为是工厂方法模式的一种简化;而工厂方法模式和抽象工厂模式则是作为两个不同的设计模式被介绍。事实上,这后两种实现模式虽然名字中都带有“工厂”两字(Factory),但在使用场景和实现上的确有较大的差异,这可能也是GoF将其作为两种设计模式来介绍的考量。尽管如此,考虑到其思路和设计内核是相通的,我们仍采用在教程中常用的写法,将三者都作为工厂模式的不同实现来介绍,读者可以思考这三种实现分别都体现了什么特殊的设计思维
简单工厂模式:
简单工厂模式定义一个工厂类,根据不同的参数返回不同的产品实例,这些产品一般具有相同的父类(或接口)
简单工厂模式的工厂往往没有自己的私有属性,所以常常作为一个工具类来出现,在这种情况下,简单工厂一般声明了私有的构造函数和静态的生产方法,类似前面介绍过的静态工具类,因此简单工厂模式也被称为静态工厂模式
示例代码如下:
//食物接口
public interface Food {
void eat();
}
//食物实现类
public class Apple implements Food {
public Apple() {}
@Override
public void eat() {
System.out.println("An apple is eaten"); //重写食用方法
}
}
public class Banana implements Food {
public Banana() {}
@Override
public void eat() {
System.out.println("A banana is eaten");
}
}
//食物接口的简单工厂类
public class FoodFactory {
private FoodFactory() {} //私有构造函数,防止工具类被实例化
//静态生产方法
public static Food getFood(String index) {
switch (index) {
case "Apple": {
return new Apple();
break;
}
case "Banana": {
return new Banana();
break;
}
default: {
return null;
}
}
}
}
使用方法:
Food food = FoodFactory.getFood("Apple"); //不再关心对象具体如何被实例化的
food.eat();
此外,这里的index不限于String类型,如果种类比较复杂 ,尤其是在容易误写的情况下(例如大小写,同义词,短语等容易混淆的情况),建议定义一个枚举(enum)来规范,类似下面的
public enum FoodType {
Apple,
Banana
}
这样,当我们输入了错误的参数,例如FoodFactory.getFood(FoodType.apple)(大小写错误),编译器会直接报出静态编译错误,而非像使用字符串参数时一样被认定为未定义行为而返回信息量很少的null(当然,我们也可以直接在default分支使用throw抛出异常,或者在日志文件中打印未定义行为的警告信息,这样在调试过程中也可以发现问题,但是定位不够准确,而且在覆盖率不够高的测试用例中,这个问题并不一定会暴露)
工厂方法模式:
工厂方法模式(Factory Method)在GoF给出的定义中是“定义一个创建产品的接口,但是让子类去决定实例化什么类”,也就是说,定义一个工厂接口和针对不同具体产品的工厂实现类,每个工厂实现类都负责一种特定产品类的实例化。从这种角度来说,GoF提到的工厂方法的别名“Virtual Constructor”(虚拟构造器)可能更好地描述了这种模式,也更不容易与其他“工厂模式”引起混淆,即,针对每种产品类创建构造器类,并将这种构造器抽象成一个接口
示例代码如下:
//仍然采用食物工厂的例子
public interface Food {
void eat();
}
public class Apple implements Food {
public Apple() {}
@Override
public void eat() {
System.out.println("An apple is eaten");
}
}
public class Banana implements Food {
public Banana() {}
@Override
public void eat() {
System.out.println("A banana is eaten");
}
}
//工厂接口
public interface FoodFactory {
Food create();
}
//工厂实现类,实际上就是Food具体类的构造器
public class AppleFactory implements FoodFactory {
public AppleFactory() {}
@Override
public Food create() {
return new Apple();
}
}
public class BananaFactory implements FoodFactory {
public BananaFactory() {}
@Override
public Food create() {
return new Banana();
}
}
使用方法:
FoodFactory factory = new AppleFactory(); //持有对抽象的引用,而非具体类
Food food = factory.create(); //客户端在使用时无需知道自己具体持有了谁的构造器
food.eat;
factory = new BananaFactory();
food = factory.create();
food.eat;
抽象工厂模式:
抽象工厂模式(Abstract Factory)在GoF的定义中是“提供一个能够创建相关或者相互依赖的对象族的接口,而无需指定具体实现类”。实际上,我们可以将抽象工厂模式理解成一个对于工厂的抽象,一个超级工厂。抽象工厂模式的一般架构是:
我们可以看到,抽象工厂模式中对于产品的划分是二维的,不仅指定了这个产品的种类,还需要考虑这个产品所属的族,当我们指定了某个具体的工厂类,我们就指定了这个产品的族。事实上,我们仍然可以拿出GoF对于抽象工厂模式定义的别名——“Kit”(工具箱)来辅助理解:在我们拿出一个工具箱(即实例化一个抽象工厂)时,工具箱里面的每一个工具(即工厂的所有方法)都分别能够帮助我们完成一个特定的产品的构造任务;而一旦我们被要求转而生产符合另一套标准的产品时,例如要求所有工件的接口大小都调大时,由于同族产品之间存在依赖关系(就如同插口调大,插孔就要相应做出变化),我们直接换用能够生产新标准下全套产品的另一个工具箱,而非挨个调整工具的参数
一般对于抽象工厂模式非常常用的例子是不同品牌的汽车工厂,即每一个工厂都能生产轮胎,发动机等部件,但是不同品牌的部件不能混用所以我们生产宝马车时就应该选用宝马工厂,产品为宝马轮胎和宝马发动机;而生产奔驰时就应该使用奔驰工厂,产品为奔驰的轮胎和发动机。但是我觉得这个例子并没有很直观地说明选用抽象工厂模式来管理产品族的精髓,对于我们在实际工程中的使用缺乏指导价值
GoF使用的是widget factory的例子,但是感觉这个使用场景有点生僻,我甚至不知道应该怎么翻译
所以我思考了一个数据处理的场景,希望能够帮助大家更好地理解
示例代码如下:
/*
假设我们正在开发一个数据交换工具,它需要处理JSON和XML两种数据格式,对于每种格式,我们都需要完成两个核心操作:解析和序列化
解析和序列化的目的是使用JSON或者XML格式,将不能直接传输的对象信息转化为字符串来传输
在客户端中,显然,我们处理数据时必须采用相同的数据格式规范,不同格式的解析和序列化器不能混用
*/
// 1. 抽象产品: 解析器
public interface Parser {
//将字符串数据解析为数据模型,传入参数为字符串,返回参数为解析后的数据模型
DataModel parse(String data);
}
// 2. 抽象产品: 序列化器
public interface Serializer {
//将数据模型序列化为字符串,传入参数为数据模型,返回字符串
String serialize(DataModel model);
}
// 3. 具体产品: JSON解析器
public class JsonParser implements Parser {
@Override
public DataModel parse(String data) {
//使用Jackson/Gson等库解析JSON
return new DataModel(); //返回解析后的数据模型
}
}
// 4. 具体产品: JSON序列化器
public class JsonSerializer implements Serializer {
@Override
public String serialize(DataModel model) {
//将数据模型转换为JSON字符串
return "{\"result\": \"json_data\"}";
}
}
// 5. 具体产品: XML解析器
public class XmlParser implements Parser {
@Override
public DataModel parse(String data) {
//使用DOM/SAX解析XML
return new DataModel(); //返回解析后的数据模型
}
}
// 6. 具体产品: XML序列化器
public class XmlSerializer implements Serializer {
@Override
public String serialize(DataModel model) {
//将数据模型转换为XML字符串
return "<result>xml_data</result>";
}
}
// 7. 抽象工厂: 数据格式工厂
public interface DataFormatFactory {
//创建解析器实例
Parser createParser();
//创建序列化器实例
Serializer createSerializer();
}
// 8. 具体工厂: JSON格式工厂
public class JsonFormatFactory implements DataFormatFactory {
@Override
public Parser createParser() {
return new JsonParser(); // 返回JSON解析器
}
@Override
public Serializer createSerializer() {
return new JsonSerializer(); // 返回JSON序列化器
}
}
// 9. 具体工厂: XML格式工厂
public class XmlFormatFactory implements DataFormatFactory {
@Override
public Parser createParser() {
return new XmlParser(); // 返回XML解析器
}
@Override
public Serializer createSerializer() {
return new XmlSerializer(); // 返回XML序列化器
}
}
// 10. 数据模型类
public class DataModel {
// 实际项目中这里会有具体的业务数据字段
}
使用方法:
// 这个服务类依赖于抽象工厂,完全不知道具体格式
public class DataTransformer {
private final DataFormatFactory factory;
public DataTransformer(DataFormatFactory factory) {
this.factory = factory; // 注入一个具体的工厂,比如JsonFormatFactory
}
public String convert(String inputData) {
// 使用来自同一个工厂的解析器和序列化器
Parser parser = factory.createParser();
Serializer serializer = factory.createSerializer();
// 用注入的格式解析输入数据
DataModel model = parser.parse(inputData);
// 这里可以做一些数据清洗或转换
// 用同一种格式序列化输出
return serializer.serialize(model);
}
}
这样,采用了抽象工厂模式之后,在我们需要处理不同的数据格式时,只需要更改注入的具体工厂即可。这就是抽象工厂模式适用的一种典型场景,希望读者能够借此更好地体会到产品族的意义,这是抽象工厂在工程选择时的精髓,GoF将其描述为“一个相互关联的产品族被设计为一起使用,而且你需要强制保证这个约束”*("a family of related product objects is designed to be used together, and you need to enforce this constraint")*
此外,GoF讲到,抽象工厂模式中,对于某一产品族的工厂方法很可能是没有私有参数的,因此在这种情况下可以是一个单例
我认为菜鸟教程中将抽象工厂模式描述成“工厂的工厂”多有误导,因为抽象工厂模式并没有承担对于任何工厂具体类的实例化责任,也就无从谈起“工厂的工厂”,所以我坚持把它描述成“对于工厂的抽象”
除此以外
网上的教程大部分都对工厂模式的三种实现讲得晦暗不明,对于工厂方法模式和简单工厂模式多有混淆,而对于抽象工厂模式的具体所指又含混不清,我越查阅资料越疑惑,最后在直接阅读GoF的原著后得到了解答,下面我来直接聚焦若干重点问题,试图讲清楚我对于工厂模式的理解
- 当我们想根据某种上下文创建不同实例但只持有对于抽象的引用时,我们应当使用的是简单工厂模式,而非工厂方法模式。工厂方法模式不应该作为简单工厂模式的优化版本来看待。简单工厂的核心是封装对象创建逻辑并提供一个统一入口,是一个工具方法。工厂方法的核心是通过子类化来延迟创建决策,它体现了依赖倒置原则。它们不是替代关系,而是解决不同问题的工具
- 工厂方法模式从表现上看并没有简单工厂模式灵活,它对于每个产品都创建了一个工厂类作为构造器,这意味着我们在一般使用简单工厂模式的情境下使用它,会引入大量冗余的类文件并实例化相当多不必要的实例。工厂方法模式的工程精髓体现在依赖注入。在GoF的例子中,一个对于文件的操作器定义了创建文件、打开文件等方法,当我们的文件抽象类有很多不同实现类时,创建文件的方法需要对具体实例化哪个文件具体类做出抉择。此时,我们可以应用工厂方法模式,对于每种文件具体类创建一个工厂类,这些工厂类实现了一个文件工厂的抽象接口,然后我们将工厂具体类使用组合模式注入到文件操作器中,这让文件操作器的创建文件的方法从“亲自决定实例化什么文件具体类”变成了“调用注入的这个工厂的方法”,当我们尝试修改一个文件操作器的创建文件的方法让它创建另一种文件时,我们只需要修改注入的工厂具体类即可
- 抽象工厂模式是中“对于工厂的抽象”其实更接近于简单工厂的抽象,而与工厂方法模式有着更本质的不同;或者反过来说,简单工厂模式更类似于抽象工厂模式的退化,而不是工厂方法模式的。GoF在对于抽象工厂模式相关问题的探讨中提到,如果采用硬编码的架构(即我在前面作为抽象工厂模式范例介绍的架构,对于不同产品的生产,在抽象工厂接口中声明一个对应的方法),如果希望加入一个新的产品,我们不仅仅需要增加抽象工厂接口的方法,还需要修改每一个工厂实现类;对此GoF给出的一个“更灵活但不够安全”的解决方法就是在生产的方法中加入一个参数来区分要生产的产品种类,并将若干生产方法合并成一个,这就与我们在简单工厂模式中介绍的使用“参数+
switch-case语句”来控制实例化的产品的方法完全一致了。事实上,采取这样的方法后,抽象工厂的每一个实现类都是一个简单工厂- 我在第3点中使用“抽象工厂模式‘更接近于’简单工厂的抽象”,而非“就是”,是因为GoF还提到,抽象工厂有基于类或者基于原型的两种实现方法。前者的每一个工厂实现类是简单工厂模式;而后者的每一个工厂实现类是原型模式(Prototype Pattern)
装饰器模式(Decorator Pattern)是一种结构型设计模式,它允许动态地向一个对象添加新的功能,同时又不改变其结构。这种模式创建了一个装饰类,用来包装原有的类,并在保持类方法签名完整性的前提下,提供了额外的功能
示例代码:
/*
我们使用咖啡作为例子,咖啡对象拥有获取价格和获取味道两种方法,装饰器模式能够让我们组合得到不同的咖啡
咖啡基底可以选择普通咖啡或者浓缩咖啡
咖啡可以添加牛奶或者糖
*/
//定义被装饰对象的接口
public interface Coffee {
String getDescription();
double getCost();
}
//定义基础对象,实现Coffee接口
public class SimpleCoffee implements Coffee {
public SimpleCoffee() {}
@Override
public String getDescription() {
return "普通咖啡";
}
@Override
public double getCost() {
return 5.0; //基础价格5元
}
}
//另一个基础对象
public class Espresso implements Coffee {
public Espresso() {}
@Override
public String getDescription() {
return "浓缩咖啡";
}
@Override
public double getCost() {
return 6.0; //浓缩咖啡基础价格6元
}
}
//装饰器抽象类,实现组件接口,并持有被装饰组件的引用
public abstract class CoffeeDecorator implements Coffee {
protected Coffee decoratedCoffee;
public CoffeeDecorator(Coffee coffee) {
this.decoratedCoffee = coffee;
}
@Override
public String getDescription() {
return decoratedCoffee.getDescription();
}
@Override
public double getCost() {
return decoratedCoffee.getCost();
}
}
//具体牛奶装饰器
public class MilkDecorator extends CoffeeDecorator {
public MilkDecorator(Coffee coffee) {
super(coffee);
}
@Override
public String getDescription() {
return decoratedCoffee.getDescription() + " + 牛奶";
}
@Override
public double getCost() {
return decoratedCoffee.getCost() + 2.0; //牛奶加2元
}
}
//具体加糖装饰器
public class SugarDecorator extends CoffeeDecorator {
public SugarDecorator(Coffee coffee) {
super(coffee);
}
@Override
public String getDescription() {
return decoratedCoffee.getDescription() + " + 糖";
}
@Override
public double getCost() {
return decoratedCoffee.getCost() + 1.0; //糖加1元
}
}
使用方法:
Coffee myCoffee = new MilkDecorator(new SugarDecorator(new Espresso())); //构造一个加糖加奶的浓缩咖啡
System.out.println("咖啡描述:" + myCoffee.getDescription()); //打印结果:“咖啡描述:浓缩咖啡 + 糖 + 牛奶”
System.out.println("咖啡价格:¥" + myCoffee.getCost()); //打印结果:“咖啡价格:¥9.0”
装饰器模式的核心优点:1.动态添加功能,具有良好的扩展性;2.使用装饰器实现的功能添加可以自由组合;3.由于装饰和被装饰对象实现了同样的接口,故对于客户端(client)来说是透明的(装饰前后的对象对于客户端没有区别);4.装饰器添加的功能可以撤销
一个令人悲伤的消息:装饰器在绝大部分场景下不如组合,或者更进一步,使用依赖注入方法实现的动态功能添加。这部分可以参考我在第四次迭代中使用插件模式对于预处理器的改动,我也会在后面讲到“组合优于继承”原则时再次提到并详述
我们在什么情况下仍应该使用装饰器?
观察者模式(Observer Pattern)是一种行为型设计模式,它定义了一种一对多的依赖关系,当一个对象的状态发生改变时,其所有依赖者都会收到通知并自动更新
// 观察者抽象
public interface Observer {
void update();
}
// 主题抽象,如果主题只有一个也可以不使用抽象
public interface Subject {
void attach(Observer observer);
void detach(Observer observer);
void notify(); // 视需求可以不对外暴露
int getState();
void setState(int state);
}
// 观察者实现类
public class ConcreteObserver implements Observer {
private Subject subject; // 当观察者需要获取主题的状态或者调用其方法时,可以持有对观察的主题的引用
public ConcreteObserver(Subject subject) {
this.subject = subject;
this.subject.attach(this); // 订阅逻辑,在构造函数中即订阅主题,视需求可以改动的
// 如果订阅逻辑比较复杂,建议采取建造者或者工厂模式作为构造器,并将订阅放在构造器中
}
@Override
public void update() {
// 对于主题的状态变化做出某种反应
System.out.println("Subject's state has changed to " + subject.getState());
}
}
// 主题实现类
public class ConcreteSubject implements Subject {
private List<Observer> observers;
int state;
public ConcreteSubject(int state) {
this.observers = new ArrayList<Observer>();
this.state = state;
}
@Override
public void attach(Observer observer) {
observers.add(observer);
}
@Override
public void detach(Observer observer) {
observers.remove(observer);
}
@Override
public void notify() {
for (Observer observer : observers) {
observer.update();
}
}
@Override
public int getState() {
return state;
}
@Override
public void setState(int state) {
this.state = state;
notify();
}
}
前7个点都是GoF在观察者模式的Implementation中提到的,我翻译整合并按照自己的理解做了解释
一个交换时间和空间效率的方法:如果我们有大量的主题但是却没有相当数量的观察者,如果主题仍然试图将全部观察者存储在主题实例内,这些空的观察者列表可能带来大量的空间开销。一个可行的方法是维护一个映射表(例如哈希表)这样一个没有观察者的主题自然的不会有空间开销,但是相对应的,查找观察者时的时间开销会增加
同一个观察者需要观察不同主题时:观察者将难以分辨是哪个主题调用了自己的update方法,这时应该修改update方法使其传入能够标识主题类型的参数
何时触发update:有两种策略,其一是主题在自己的setter方法结束时来通知;另一种是交给客户端(client)决定,在主题的状态变化后的适当时间调用主题的notify方法来通知。后者的优势是客户端可以轻易更改通知的时间逻辑,例如在一批主题的状态变化结束之后再统一通知;而劣势是这样会让客户端要做的事情变得复杂且易错
删除主题:涉及到观察者和主题对象的生命周期不一致时的问题。观察者模式中对于观察者的删除较为简单,只需要在删除对象的同时向主题detach即可,但是删除主题可能会导致观察者持有对于主题的悬空引用,可能导致访问未定义的内存,需要慎重。GoF给出的选择是可以让观察者实现一个删除或者改变持有的主题的方法,主题在销毁时调用所有观察者的这个方法。由于GoF在写书时主要考虑c++,而在c++中对于对象的销毁需要由析构函数手动处理,所以这种情况是必须在析构函数中被考虑的。但是现代语言框架下,这个问题并不明显,也可以采用更好的方法来解决,例如让观察者持有对主题的弱引用(即调用主题的方法之前先判断主题是否为空,为空则取消调用并修改对主题的引用)
状态一致性问题:使用观察者模式时需要保证主题向观察者通知时所有状态改变已经完全完成,而非正在处于某次状态改变的半成品。GoF使用了一种模观察者模式和继承结合时出现的常见错误来说明,翻译成java后类似下面的代码:
//子类在重写父类的状态变化方法时直接调用了父类的方法,但是没有正确处理通知时机
public class Superclass {
private int value;
//构造函数,观察者与通知方法等省略
//状态变化方法
public void operation(int value) {
this.value = value;
notify();
}
}
public class Subclass extends Superclass {
//子类重写了父类的状态变化方法
@Override
public void operation(int value) {
super.operation(value); // 调用父类的状态改变方法,但是父类的方法过早发布了通知
//子类的某种改变了状态的业务逻辑,但是已经晚了
}
}
/*
此外,我查询了继承时为什么一定要采用先调用父类方法再执行子类业务逻辑,而非将二者顺序颠倒
这样看似可以保证父类方法控制的通知一定在状态变化的最后
我得到的答案是:一般面向对象的程序设计中一般将父类的方法放在子类之前
这体现了模板方法中“父类控制流程,子类填充实现细节”的思路
父类的方法中通常包括重要的前置检查以及基础状态的设置,所以不宜在子类的方法之后进行
*/
拓展这个情景进行思考,容易出现类似的通知过早的问题的情景还包括:1.嵌套的状态改变方法;2.对于一些状态存在相互关联的对象的批处理;3.一系列事务性操作的中间状态;4.状态改变的连锁反应等等
可行的解决方法包括:1.GoF提到的解决方案,将通知交给子类进行;2.延迟通知逻辑,使用“脏标记”(即使用一个dirty来标记未通知的状态变化)或者事务性通知(try-finally语句)等方法,将通知统一延后到一段完整的状态改变过程结束后进行;3.将同一批次的状态变化写入缓冲区,在这段完整的状态改变末尾实现这些变化并通知等等
更新协议问题:更新协议指的是观察者模式中定义的,被观察者(主题)在状态变化后向观察者传递变更信息的方式的约定。GoF介绍了两种更新协议的模式:推协议和拉协议。前者指被观察者在状态变化的通知中将全部详细变更信息都传递给观察者,不管观察者需要什么;后者指被观察者在状态变化后仅向观察者发送最小化的通知(即仅告诉观察者有变化发生),当观察者需要详细变化信息时,它自行从被观察者获取。推协议的问题是被观察者对于观察者做出了假设,这导致不彻底的解耦和更差的扩展性;而拉协议的问题是观察者需要在没有被观察者的帮助的情况下对于被观察者的变化做出查明,并向被观察者做出获取信息的请求,这带来了效率劣势。总的来说,更新协议应遵循迪米特法则,尽可能降低观察者与被观察者对彼此的了解,同时避免“特定于观察者的更新协议”
观察者的兴趣:当一个主题有多种状态变化的原因,但是观察者只对其中的某些感兴趣时,一个可选的优化方法是观察者在attach方法中向主题注册自己的兴趣,主题在某个特定状态变化(或者某种特定原因引起的状态变化)时只通知特定兴趣的观察者。这里类似我在总线模式中做的,在主题中维护一个表示事件类型到观察者集合的映射的哈希表
以下的这些点是我的观点与思考
GoF的观察模式强调了什么:GoF在观察者模式中反复强调被观察者的状态属性,想要通过观察者模式达成的是观察者与主题的状态一致性(consistent),例如在我们希望一个对象的某个参数能够与另一个对象的参数完全同步时,我们应该使用观察者模式来协调。但是我们在活用时其实并不一定需要让观察者也维持一个持续的状态属性,有时只需关心变化发生的时刻即可;甚至就如同“publish-subscribe”的形式一样,主题也不一定要维持一个持续的状态属性,而是只有一个触发变化的时机即可
总线模式:总线模式旨在提供一个集中式的通信通道,系统的各个组件可以通过这个通道交换数据而无需直接连接,从而促进松散耦合,并增强可扩展性和可维护性。总线模式的一般实现采用类似观察者模式的“订阅-发布”模式,并使用推模式的更新协议,但是目的并不是维持发布者和订阅者的状态一致,而是类似一个公告板,通过统一的总线工具类提供的发布方法来向所有关心某种信息的订阅者发布信息。架构一般包括:1.一个总线工具类(即Bus),一般定义成单例模式或者静态工具类,提供一个全局的发布事件的工具方法(类似观察者模式中的notify方法,但是不在总线内部调用,而是对外暴露);2.一个代表着被传输的信息的类型的抽象及其全部实现类(在我的代码中是Event,用于在总线中传输某事件的全部上下文,如果是一个特定的数据类型,例如字符串,可以不为其专门定义抽象与实现类);3.一个观察者抽象,向总线中订阅并注册兴趣,暴露处理信息的方法供总线调用;4.当客户端希望利用总线向某个观察者传递信息时,它创建一个这个观察者感兴趣的事件,注入全部事件上下文并向总线发布
鉴于我代码中的总线模式其实已经比较典型了,我就不提供代码示例了,可以参考我的代码来理解
总线模式的主要弊端在于系统复杂性高、通信延时较大、追踪数据流困难,在较为简单的项目中引入不很必要
迪米特法则(Law of Demeter),又称最少知识原则(Least Knowledge Principle),强调一个对象应对其他对象尽可能少的了解,以降低类之间的耦合度
狭义的迪米特法则要求实现两点:1.只和直接的朋友交流;2.减少对朋友的了解。其中直接的朋友包括成员变量与方法的输入输出参数;而减少对朋友的了解要求一个类尽可能少地对外暴露它的方法。前者往往通过门面模式或中介模式来实现,但是也存在容易创建过多没有实际业务的中介类的问题
相比狭义迪米特法则而言,迪米特法则的思想则更具有价值,它阐述了一种面向对象设计中的重要原则:通过减少类对外暴露的方法,降低类对其他类的结构和方法依赖,并最小化访问权限来实现类间的解耦合
在理解“组合优于继承”原则之前,我们先了解组合是如何工作的:
组合是指在面向对象设计时,通过在一个对象中利用组合(composition)+委托(delegation)方法,组合多种不同功能的对象来实现复杂的功能的策略。如果说继承是“is-a”关系,组合就是“has-a”关系,即继承表达了严格的种属关系,而组合则聚焦了对象“具有某种性质”
组合的核心实现方法是接口+实现类,通过定义接口与针对该接口的专门实现类,再将实现类注入一个特定的类中,即可使后者实现这个接口,下面我将展示继承和组合分别是如何实现这个功能的:
采用继承:
// 创建一个继承了食物父类的苹果
// 食物父类
public abstract class Food {
// 忽略其他属性和方法
void eat(); // 食物定义了食用方法
}
//食物实现类
public class Apple extends Food {
public Apple() {}
@Override
public void eat() {
System.out.println("An apple is eaten"); // 重写食用方法
}
}
采用组合:
// 食物接口
public interface Food {
void eat();
}
// 食物接口的实现类
public class AppleEatAbility implements Food {
public AppleEatAbility() {}
@Override
public void eat() {
System.out.println("An apple is eaten"); // 在实现类中重写食用方法
}
}
// 食物实现类
public class Apple implements Food {
private AppleEatAbility appleEatAbility;
public Apple(AppleEatAbility appleEatAbility) {
this.appleEatAbility = appleEatAbility; // 注入食物实现类
}
@Override
public void eat() {
appleEatAblity.eat(); // 直接委托实现类来完成
}
}
看到上面的代码后,你很可能仍然不解:采用组合的代码看起来完全不如继承的简洁啊?那我们再考虑更加复杂的情况:如果我希望Apple类现在获得一个新的父类“商品(Goods)”,并相应地实现buy方法,应该如何做?如果采用继承,由于java中只允许一个子类继承自一个父类,我们的代码将无法设计,而采用组合,我们只需要创建Goods接口与相应方法的实现类,再通过组合注入到Apple类中即可(顺便一提,java只允许一个子类有一个父类是为了防止“菱形缺陷”,即一个接口或父类A的两个子类BC都重写了A的某个方法,而D同时继承BC,就会导致D的该方法无法确定继承了哪个父类的)
仍然觉得不够有说服力?我们考虑更广义的“继承”关系——对接口的实现。由于一个子类可以实现多个接口,我们在实现前述需求时可以不采用父类,而将Food和Goods定义为接口,分别定义eat和buy方法的签名,而在Apple子类中,我们不采用方法注入,而是直接重写这两个方法以实现两个接口,是否就跟组合的能力一样强大了?
答案仍然是否定的,考虑下面场景:如果我们希望一个苹果作为商品,能够在客户端做出对于支付方式的决定时变化buy方法的行为,如果采用组合,我们可以对Goods接口针对不同支付方式创建多种实现类,并在客户端中采取依赖注入方式动态替换苹果实例的buy方法;而采用继承,我们可能得在苹果类的buy方法中用一个复杂的switch-case语句切换支付方式,并在所有对于购买方法的调用中都传入标记着支付方式的参数。显然,组合的方案无论在灵活性、解耦程度还是扩展性上都远优于继承
此外,组合在代码复用上相较于继承也有显著优势。例如我们添加一个GoldenApple类,其eat方法与Apple完全相同,但是buy方法不同,我们就可以直接为其设计特殊的商品接口实现类,而直接注入与Apple相同的食物实现类;这样,当我们需要修改二者的eat方法时,我们也只需要改动这一个实现类即可,无需对Apple和GoldenApple类做出任何改动
最后,继承本身具有一系列劣势,例如继承层次可能过深、过复杂;父类硬编码的属性和方法可能逼迫子类获得无意义的属性或者实现不必要的方法;基类的微小改动都可能在没改动子类的情况下就对子类的行为造成破坏;继承中必要的子类对于父类protected成员的依赖也破坏了父类的封装性
如果你是从装饰器模式看过来的,可以思考装饰器模式相对于组合的劣势,我给出几个参考:
- 装饰器模式由于采用了继承,可能逼迫本应专注于对特定方法的功能进行拓展的装饰器实现不必要的方法
- 装饰器在嵌套了多层以后,指定其中一层删除的算法较为复杂
- 装饰器的重新排序比插件模式(使用组合方法,但是注入的实现类可以是个集合)复杂很多
- 脆弱的基类以及子类对于父类封装性的破坏
java的抽象一般有两种方法,接口和抽象类。前者定义了一系列方法的签名,一个接口只有方法的特征没有方法的实现,因此这些方法可以在不同的地方被不同的类实现,而这些实现可以具有不同的行为;后者通过将某些子类的共同属性和方法提取为父类,并将父类声明为抽象,就可以为这一种子类提供一个统一的模板,其中可以通过非抽象方法定义方法的默认实现,也可以通过抽象方法仅定义一个方法的签名
由此可见,抽象类与接口的最大区别在于是否具有属性以及能否定义方法的实现,这看似让抽象类比接口拥有了更强大的能力,但是在两个方面的考量上,我们提倡优先使用接口而非抽象类:
Bird抽象类,定义飞行、觅食、繁衍(fly,forage,breed)等方法,此时如果我们需要新加入一个鸵鸟实现类,就必须实现其本不应该实现的fly方法;而如果采用接口,我们就完全可以将三个方法都定义为接口Flyer,Forager,Breeder,而鸵鸟只需要实现后两个接口,不实现Flyer即可);功能组合的自由度更高(例如:鸟类定义了飞行方法,但其他类如哺乳动物类中的蝙蝠也能定义飞行方法,当我们在某个客户端需求中只关心能否飞行而不关心是否为鸟类时,抽象类就不能很好地完成分类工作,而利用Flyer接口就能够很优雅地实现)思路转变:抽象不等于代码复用!虽然我们常常在抽象的过程中将若干子类的共性代码提取为父类,或者提取为接口+实现类,但是抽象的意义远远不止代码复用。抽象的精髓在于多态,当我们定义了一个方法,无论是在抽象类的子类中将其重写,还是在接口的实现类中将其实现,对这个方法的引用方法仍然没有改变。当客户端从抽象而非具体类来引用这个方法时,我们只知道这个方法能够达成什么效果,而对于具体如何达成,我们不关心,而是信任并委托给子类进行。利用抽象实现多态的这种思路比代码复用更重要,这也是接口在代码复用上做得更差但是我们仍然建议优先使用的原因
接口的应用实践:前面已经提到,抽象类与接口的最大区别在于是否具有属性以及能否定义方法的实现,这两个差距其实在使用接口时是可以通过一些实践技巧弥补的。例如对于前者,我们虽然不能在接口中定义其子类应该具有某种属性,但是我们可以定义这个属性的getter方法,在子类中,我们只需要定义对应的属性,然后实现这个方法让这个属性暴露即可(另外,如果这个属性不应该对外暴露,即不是public的且不应该有getter,我们也没有任何定义抽象父类并声明这个属性的必要性,读者可以澄清这个问题);对于后者带来的代码复用问题,采取接口+实现类即可解决,前面在组合优于继承中已经讲过,不再赘述
使用JUnit进行测试是OOpre课程中的重要环节,一个好的测试不但能够帮我们评估代码正确性,找出bug,还应该易于扩展,甚至有助于我们反思自己的代码架构
课程要求我们保证测试的覆盖率,这其中包含三个指标:行覆盖率、方法覆盖率和分支覆盖率。行覆盖率代表对于代码行的覆盖情况,如果一行代码没有被覆盖到,说明这段代码没有在任何测试代码中被调用,此外,空行和注释不会影响行覆盖率,在同一个方法调用中换行不会影响行覆盖率。方法覆盖率代表代码对于全部声明的方法的覆盖情况,如果一个方法没有被覆盖到,说明这个方法在测试代码中从来没有被调用,对于public方法,我们可以在单元测试中直接调用并测试其行为;对于一些private的方法,我们可以采取间接调用的方法来测试,例如测试一个能够调用这个私有方法的公有方法在调用这个私有方法的情况下是否符合预期。分支覆盖率代表对于所有判断的不同分支的覆盖情况,例如代码中的一个if-else语句,我们需要满足其if条件为真和为假各一次,才能保证分支覆盖率
此外,MainClass类(或者带有main方法的类)是不会参与覆盖率测试的,它的覆盖率会被永远记作0%,所以请注意不要将主类写得过长,以免影响测试覆盖率
精心设计的测试数据是揭示代码潜藏缺陷的关键,优秀的测试不仅要覆盖代表正常业务的“阳光路径”,更要系统性地设计各种边界情况和异常场景,包括空值、极值、非法输入和无效状态,因为真正的软件健壮性正体现在对这些看似边缘实则致命情况的处理能力上。一个好的数据选择可以帮助我们测试出代码的能力边界,往往能够发现仅从代码逻辑上不容易找到的隐藏的bug
单元测试是对软件中最小可测试单元(如函数、方法或类)进行验证的过程,旨在确保其行为符合预期,一般遵循AAA原则,即Arrange:设置测试条件,Act:执行被测逻辑,Assert:验证测试结果。单元测试旨在通过隔离外部环境,聚焦单一对象、单一业务的行为,评估单元的正确性,并有利于快速定位缺陷
测试代码的核心原则是测试行为而非实现,这意味着我们的测试代码并不关心测试对象对于方法的实现细节,而是遵照被测试的方法的公开契约,测试其行为是否符合预期,即,给定的环境和参数下,是否返回了期望的值,或者产生了期望的副作用(Side Effect)。例如,测试一个注册表是否成功注册时,我们不获取注册表中的Map对象并判断键值是否存在;而是利用注册表公开的查询方法,断言其查询结果,因为前者暴露了注册表的内部结构。这样的测试思路有利于提高代码的扩展性,让我们在对于一个方法的实现进行修改后不影响测试代码的适用能力
单元测试的目的并不只是对于现成的代码测试bug,而还应该能够驱动和验证代码设计
当你写下测试时,你会被迫思考:
我该如何构造这个对象?如果构造很复杂,说明构造函数承担了太多
我该如何模拟它的依赖? 如果依赖难以模拟,说明耦合度太高
我该如何验证它的输出和行为? 如果难以断言,说明方法的职责不单一
如果一个代码难以单元测试,那么它的设计很可能是糟糕的。在编写单元测试的过程中,我们将对于依赖注入,工具类的使用,类的封装等技巧的价值产生更深的理解
Operation类承担了本不应该由它承担的冒险者管理的职责,违背单一职责原则。对于冒险者的管理应当交由专门的工具类来实现
各个指令可以分别交给专门的工具类进行处理,随着指令的增加,Operation类逐渐承担了过多的功能,这个问题并不是很大
冒险者类没有任何实际信息,只是组合了属性和物品的管理者,而两个管理者类在每个冒险者中都各创建了一个实例,这层嵌套其实是毫无意义的。应该直接删除冒险者类并将属性和物品的管理者各写成一个按冒险者id为键值管理冒险者信息的工具类。此外,由于总线模式的作用完全在于沟通属性和物品管理者,注册表的作用也在于让冒险者的某些信息对外公开,在舍弃冒险者类的无意义嵌套,采用这样架构之后,只需要为属性和物品管理者各自定义访问和沟通方法,就可以完全舍弃时间开销极大的总线和注册表了
我在第三次迭代中将援助事件写进属性变化预处理器中是完全不符合题目要求的,题目要求的是在涉及属性变化的指令完全结束之后触发援助事件,而我现在的逻辑是在属性变化事件的处理逻辑中加入援助事件触发。虽然如今已经进行了一定的修改,但是假设接下来对这个项目还有迭代,并加入了会执行一个不定长度的属性变化链的指令,并要求它也实现援助事件触发,这个架构的致命问题还会再次暴露
更合理的架构应该是给指令而非属性变化事件写一个处理器(模板模式),在预处理阶段缓存对于冒险者属性的快照,并在后处理阶段(此时一个指令已经完整地执行完了)调用快照比较是否触发援助;对于死亡的检测也写在指令处理器里面比较好,一条指令完整地执行完以后再处理所有死亡的冒险者是很合逻辑的,而这样一个延缓的触发时机也可以很好地保证工作流程干净,不在任何事件流的内部进行死亡处理,避免例如我在发布DeathEvent时遇见的并发修改异常等问题
希望能够在迭代的最初就讲清楚面向对象程序设计的基本思路,希望在课程中更详细地介绍面向对象的重要设计原则,帮助培养面向对象程序设计思维,减少学生们“误入歧途”的精力浪费,祝OOpre课程越来越好

