


13,215
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享昇思MindSpore开源实习模型论文解读任务已顺利完成,共收到模型论文解读稿件10+篇。欢迎开发者积极参与昇思MindSpore开源实习活动,开源实习暑期活动已开启,更多新任务等你来挑战!

开源实习官网
Segment Anything Model(SAM)在许多计算机视觉任务中取得了令人印象深刻的性能。然而,作为一种大规模模型,其巨大的内存和计算成本限制了其实际部署。该论文针对SAM量化中固有的瓶颈问题,提出了一种针对SAM的后训练量化(PTQ)框架,命名为PTQ4SAM。该框架在各种视觉任务(实例分割、语义分割和目标检测)、数据集和模型变体上的广泛实验结果表明了PTQ4SAM的优越性。
1、post-key-linear的双峰分布现象影响了模型量化后的表现
在 SAM(Segment Anything Model) 这样的视觉大模型中,Post-Key-Linear 这一术语通常与 Transformer 架构中的注意力机制(Attention Mechanism) 相关。具体来说,它指的是在计算注意力机制中的 Key 矩阵 后,经过一个线性变换(Linear Layer)的输出。SAM模型的Post-Key-Linear输出呈现双峰分布(如下图1(a)所示),这极大影响了量化的效果。
解决方法:双峰集成策略。文章通过per-tensor和per-channel两个角度分析了双峰分布,并认为这是量化的主要障碍,并将双峰分布转换为正态分布来解决这一瓶颈。
2、复杂的 post Softmax 分布
由于注意力机制的种类多种多样,与 VIT 相比,SAM 表现出更复杂的 post Softmax 分布。文章中举了image-to-token和token-to-image两个位置的post-Softmax的不同分布说明这一点,并且指出先前的工作并未意识到这一点,导致了固有信息的潜在丢失。
解决方法:自适应粒度量化(AGQ)
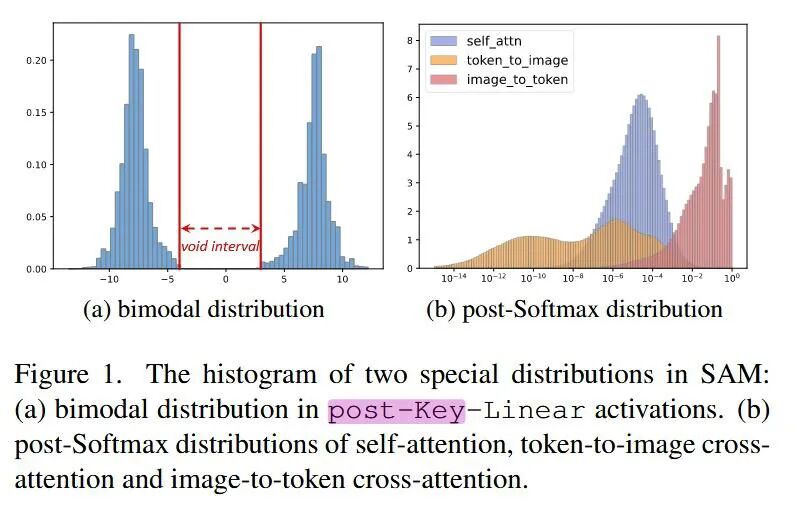
图1 SAM特征值分布(摘自论文)
1、双峰集成策略
从per-tensor角度来看激活值双峰分布,如图1(a)所示。从per-channel角度来看,每个通道的激活值在一个固定值附近,每个通道之间有很大区别,如图2所示。
由于每一个channel中所有tensor的激活值都分布在一个固定值附近,而这一系列固定值呈现以0为中心的双峰分布。因此,论文中采用一个参数γ来将双峰分布转换为正常分布,其取值为-1或1。对于channel的激活值平均值为正的,γ为1,channel激活值不发生变化;对于平均值为负的,γ为-1,将负值映射为正值,同时为query linear也乘上-1,保持输出值不变。由于query linear是关于0对称的标准正态分布,乘以-1后分布不变。这样,q和k的linear激活值都保持了标准分布。
代码的实现主要分为三步骤:①判断tensor是否属于双峰分布②计算γ③进行等效转换(bimodal discovery, γ computation and equivalent transformation)。
2、自适应粒度量化(AGQ)
对post softmax的量化,用的是改进的log2量化,一种自适应粒度量化方法。通过搜索最优的2的幂次基底τ,为不同的Softmax后分布提供合适的量化粒度。通过建立一个LUT(对不同的τ和移位的乘积进行查找),就可以通过非常小的空间代价(4KB)实现对于不同post softmax的不同粒度的量化。这个空间代价是用所有的τ的取值乘以所有的移位可能。对于8bit的精度来说,τ的取值有2^2种可能性,aq有2^n(n取8)种可能,-aq/τ总共需要4byte来存(包含第一部分的aq%τ和第二部分的[aq/τ],所以一共是4KB。
移位操作:通过移位来快速实现2的幂次方的乘除法计算。
选定τ的方法:通常来说是直接衡量attention矩阵A的损失,文中采用了AV的乘积损失作为目标函数,这样能够直接衡量在模型整体性能上的量化损失,单独衡量A的损失和整个注意力块的损失并不一致。通过在Calibration Set上实验,对不同的softmax层选择不同的τ数值。同时论文发现,τ取值较小的时候能够对低注意力分数更好的量化,而τ增大后,对更大的注意力分数的量化性能更好。
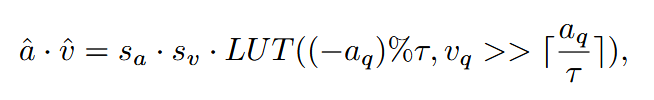
公式1 量化后的a、v乘积计算公式
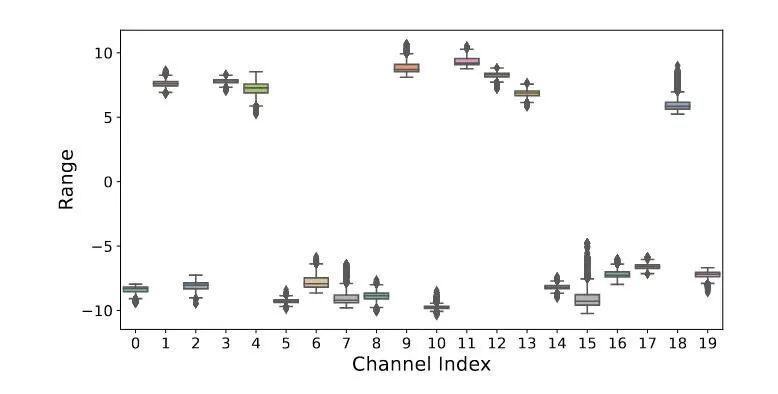
图2 per-channel的激活值分布(摘自论文)
3、预训练编码器和解码器权重共享的,**这种方法不仅能提高模型性能,还能显著降低模型的内存占用。共享权重的方式在大多数任务中都表现出了良好的效果,尤其在计算资源有限的情况下尤为重要。
1、实验设置
任务和数据集:实验涵盖了实例分割(MS-COCO数据集)、语义分割(ADE20K数据集)和目标检测(DOTA-v1.0数据集)等任务。
模型:使用了SAM-B、SAM-L和SAM-H三种模型变体。
量化设置:实验中使用了不同的量化比特宽度(W6A6和W4A4),分别表示权重和激活的比特数。
2、实验结果
实例分割:在MS-COCO数据集上,PTQ4SAM方法在不同的检测器中始终优于其他方法。同时,我们的 PTQ4SAML 令人鼓舞地实现了无损精度,如下图3,在 W6A6 设置下,我们的 PTQ4SAM-L 在 SAM-L 上应用 YOLOX 和 H-Deformable-DETR 时分别达到 40.3% 和 41.2%,与全精度型号相比,性能仅下降 0.1% 和 0.3%。
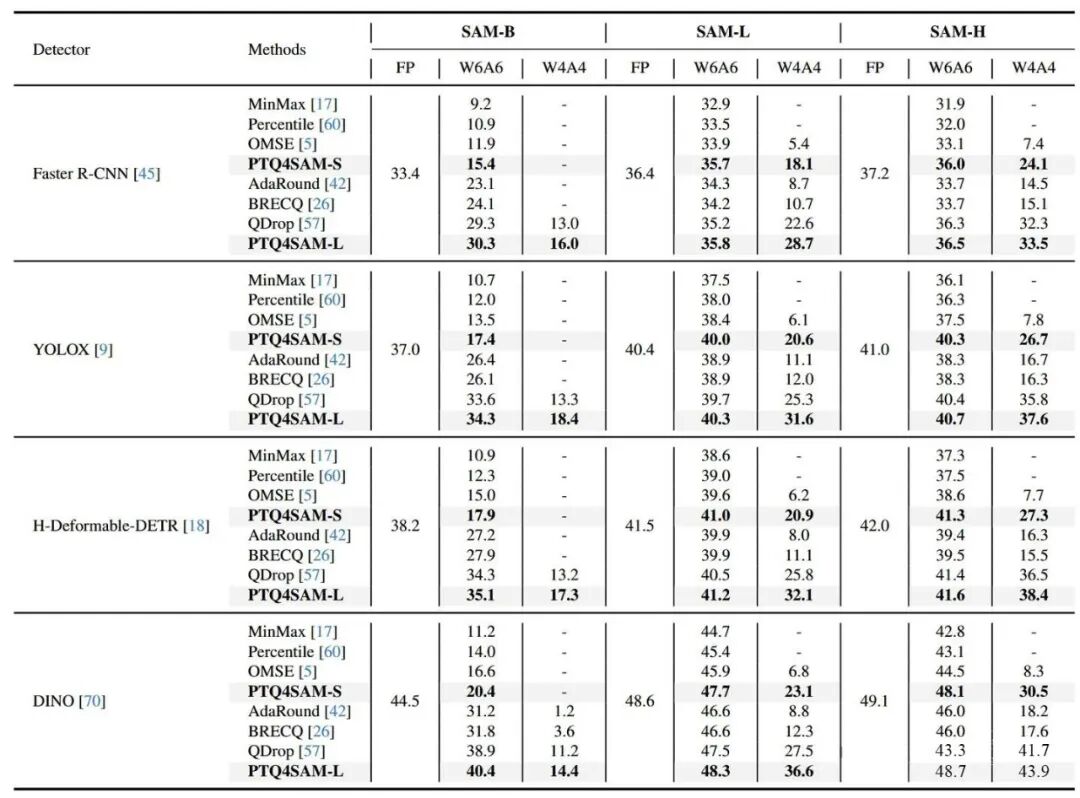
图3 实例分割任务实验结果
语义分割:在ADE20K数据集上,PTQ4SAM在W6A6量化时甚至超过了全精度模型的性能。如下图4,SAM-L模型在W6A6量化时达到了33.66%的mIOU,比全精度模型高出0.05%。
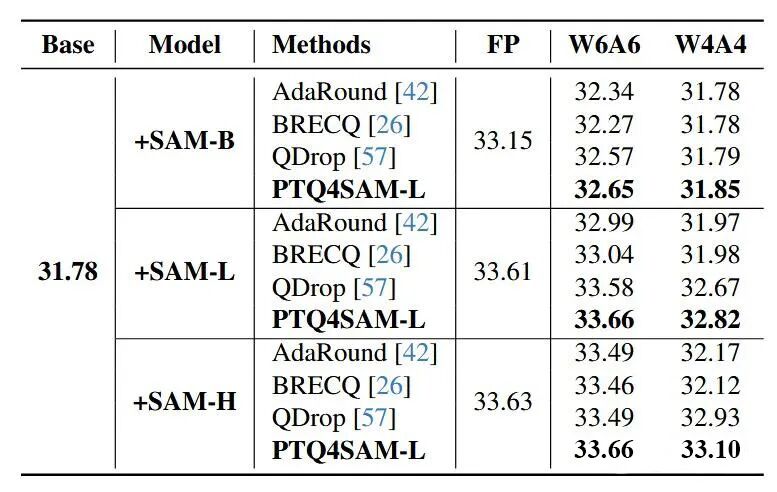
图4 语义分割任务实验结果
目标检测:在DOTA-v1.0数据集上D 定向目标检测中,我们的方法始终优于其他基于学习的 PTQ 方法。PTQ4SAM在SAM-L和SAM-H上进行W6A6量化时仅比全精度模型下降了0.3%,而在W4A4时,仍然能够保持较高的性能。
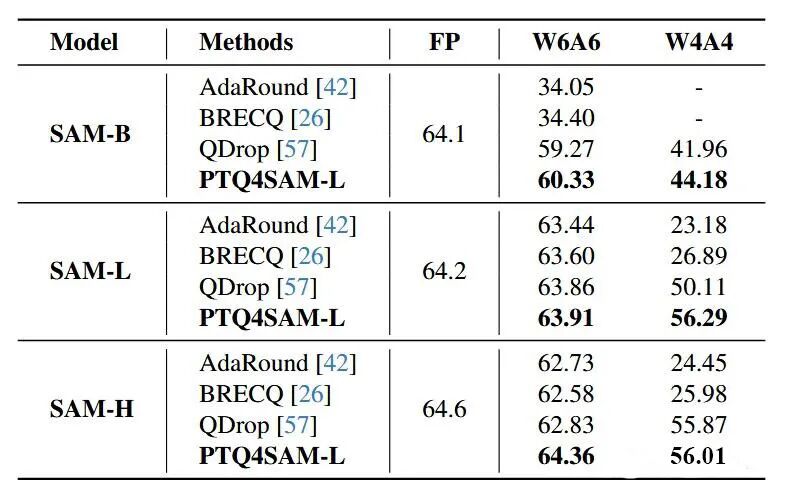
图5 目标检测任务实验结果
3、主要贡献
1)第一个针对SAM的PTQ策略。
2)提出了针对双峰分布的双峰集成策略。
3)提出了AGQ方法。
4)通过实验证明,我们的方法是一个即插即用的PTQ方法,大大超过了之前最先进的方法。
首先,复现论文代码得到sam_b的量化模型。
然后,通过mindspore加载COCO数据集,下面是实例分割数据集的定义,每次迭代会返回"img_id", "image_path", "image", "bboxes", "labels", "masks"。文件命名dataset.py。
import os
import numpy as np
import cv2
from pycocotools.coco import COCO
import mindspore.dataset as ds
import mindspore as ms
import pycocotools.mask as mask_util
from pycocotools.coco import COCO
from pycocotools.cocoeval import COCOeval
class COCOInstanceSegmentationGenerator:
def __init__(self, root_dir, annotation_file):
"""
初始化COCO实例分割数据集生成器
:param root_dir: 图像文件所在的根目录
:param annotation_file: COCO标注文件路径
"""
self.root_dir = root_dir
self.coco = COCO(annotation_file)
self.image_ids = self.coco.getImgIds()
categories = self.coco.loadCats(self.coco.getCatIds())
self.class_names = [cat['name'] for cat in categories]
定义推理代码。为了实现实例分割,需要加载yolox作为检测头,然后把yolox检测出的boxes作为SAM模型的提示,输出目标掩码。首先,借助mindyolo库实现yolox目标检测mindyolo_test.py:
import math
import os
import time
import cv2
import numpy as np
from mindyolo.utils.config import load_config, Config
import mindspore as ms
from mindspore import Tensor, nn
from mindyolo.data import COCO80_TO_COCO91_CLASS
from mindyolo.models import create_model
from mindyolo.utils import logger
from mindyolo.utils.metrics import non_max_suppression, scale_coords, xyxy2xywh
from mindyolo.utils.utils import draw_result
然后实现推理代码。为了评估,输出需要规范化为COCO格式,存入json中。
import torch
from mindyolo.utils.config import load_config
import numpy as np
import os
from mindyolo.utils.config import load_config, Config
from mindyolo.models.model_factory import create_model
from segment_anything import sam_model_registry
from segment_anything import SamPredictor
import mindspore
import json
from pycocotools.cocoeval import COCOeval
import mindspore.dataset as ds
import pycocotools.mask as mask_util
from pycocotools.coco import COCO
from tqdm import tqdm
import matplotlib.pyplot as plt
from mindyolo_test import detect
from dataset import COCOInstanceSegmentationGenerator
调用COCO工具评估准确率:
import os
from pycocotools.cocoeval import COCOeval
from pycocotools.coco import COCO
if __name__ == "__main__":
root_dir = "./val2017/val2017/"
annotation_file = "./annotations_trainval2017/annotations/instances_val2017.json"
save_dir = './inference_results'
# 加载预测结果
coco_gt = COCO(annotation_file)
coco_dt = coco_gt.loadRes(os.path.join(save_dir, 'predictions.json'))
# 初始化评估工具
coco_eval = COCOeval(coco_gt, coco_dt, 'segm')
# 评估指标
coco_eval.evaluate()
coco_eval.accumulate()
coco_eval.summarize()
测试结果:

可视化展示

图6 实例分割效果可视化
PTQ4SAM是首个专门针对SAM模型的后训练量化解决方案,通过BIG和AGQ策略,有效解决了SAM模型量化中的双峰分布和多样的Softmax后分布问题。在多种视觉任务和不同模型变体上,PTQ4SAM均表现出优越的性能,能够在低比特量化下保持较高的精度,并实现显著的计算和存储节省。
尽管PTQ4SAM在量化SAM模型方面取得了显著成果,但论文也指出,SAM模型中双峰分布的成因尚不清楚,这将是未来研究的一个潜在方向。

