


13,253
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享大语言模型的落地应用,不仅依赖训练阶段的精度提升,更需要推理阶段的高效部署。昇腾 910B 芯片通过硬件级 AI 加速引擎与 CANN 的算子优化能力,为 LLM 推理提供了高算力、低延迟的硬件支撑;昇思 MindSpore 动态图方案结合 MindSpeed-LLM 工具链,实现了 Qwen 系列模型的无感迁移与推理优化,大幅降低部署门槛。本文基于昇腾 800T A2 服务器,聚焦 Qwen2.5-7B 与 Qwen3-8B 模型的推理加速配置、多场景评估方法,从模型转换、推理优化、性能调优到效果验证,完整拆解昇腾平台的 LLM 推理部署流程,为开发者提供高性价比的工业级推理方案。
服务器型号:昇腾 800T A2(4 张昇腾 910B 芯片)
推理模式:支持单卡推理、多卡聚合推理(提升吞吐量)
存储配置:1TB NVMe SSD(存放优化后模型权重与评估数据集)
网络配置:10G 以太网(满足推理服务的网络传输需求)
2.2.1 推理环境配置
# 安装昇腾推理引擎与MindSpore推理版 pip install mindspore-infer==2.3.0 ascend-infer==8.3.RC1 # 安装推理优化依赖 pip install sentencepiece accelerate optimum[ascend] tensorrt # 克隆MindSpeed推理工具库 git clone -b r0.4.0 https://gitee.com/mindspore/mindspeed-core-ms.git cd mindspeed-core-ms && pip install -r requirements_infer.txt
2.2.2 模型与评估数据集准备
# 创建推理专用目录
mkdir -p /mnt/infer/{models,data,results}
# 复制微调/预训练后的模型权重(以Qwen3-8B为例)
cp -r /mnt/dist_data/Qwen3-8B/w_pretrain_merged /mnt/infer/models/qwen3-8b-optimized
# 复制Qwen2.5-7B微调后权重
cp -r /mnt/data/Qwen2.5-7B/w_tune /mnt/infer/models/qwen25-7b-tuned
# 下载评估数据集(MMLU、C-Eval、AGIEval)
pip install lm_eval
git clone https://gitee.com/ascend/evaluation-datasets.git /mnt/infer/data
# 下载行业场景测试数据(智能客服、代码生成)
wget https://ascend-repo.obs.cn-east-2.myhuaweicloud.com/datasets/llm/industry_test_data.zip -P /mnt/infer/data
unzip /mnt/infer/data/industry_test_data.zip -d /mnt/infer/data
2.2.3 推理优化工具配置
创建infer_optimize_config.yaml,启用昇腾推理优化特性:
model_name: qwen3-8b precision: bf16 # 推理精度 max_seq_length: 8192 batch_size: 16 # 批量推理大小 optimization: tensorrt: True # 启用TensorRT加速 operator_fusion: True # 算子融合优化 memory_optimize: True # 显存复用优化 dynamic_batch: True # 动态批处理支持
input_model: /mnt/infer/models/qwen3-8b-optimized # 输入模型路径(PyTorch格式) output_model: /mnt/infer/models/qwen3-8b-ascend # 输出昇腾优化格式模型 framework: pytorch # 输入框架类型 device: ascend # 目标设备 precision: bf16 max_seq_length: 8192 save_onnx: False # 不保存ONNX中间格式
model_path: /mnt/infer/models/qwen3-8b-ascend tokenizer_path: /mnt/dist_data/Qwen3-8B/w_ori batch_size: 8 max_seq_length: 8192 max_new_tokens: 1024 temperature: 0.7 top_p: 0.9 device_id: 0 output_path: /mnt/infer/results/single_card_output.json
model_path: /mnt/infer/models/qwen3-8b-ascend tokenizer_path: /mnt/dist_data/Qwen3-8B/w_ori rank_size: 4 # 4卡推理 batch_size: 32 # 总batch size max_seq_length: 8192 max_new_tokens: 1024 output_path: /mnt/infer/results/multi_card_output.json
model_path: /mnt/infer/models/qwen3-8b-ascend eval_datasets: [mmlu, ceval, agieval, industry_customer_service, code_generation] dataset_path: /mnt/infer/data batch_size: 8 max_seq_length: 4096 metrics: [accuracy, perplexity, bleu, rouge] output_report: /mnt/infer/results/eval_report.json
将 PyTorch 格式模型转换为昇腾推理优化格式,启用 TensorRT 加速:
# 创建转换脚本 cat > convert_model.sh << EOF #!/bin/bash python tools/model_convert.py --config convert_config.yaml EOF # 执行转换(约30分钟完成) chmod +x convert_model.sh ./convert_model.sh # 验证转换结果 ls /mnt/infer/models/qwen3-8b-ascend # 输出ascend_model.bin、config.json等文件
执行单卡高并发推理,验证模型响应速度:
# 创建单卡推理脚本 cat > single_card_infer.sh << EOF #!/bin/bash python tools/infer.py --config single_card_infer.yaml \ --prompt_file /mnt/infer/data/industry_customer_service/prompts.json EOF # 执行推理 chmod +x single_card_infer.sh ./single_card_infer.sh # 查看推理结果 cat /mnt/infer/results/single_card_output.json
通过多卡并行推理提升吞吐量,适配高并发场景:
# 创建多卡推理脚本 cat > multi_card_infer.sh << EOF #!/bin/bash export RANK_SIZE=4 mpirun -np 4 python tools/infer_distributed.py --config multi_card_infer.yaml \ --prompt_file /mnt/infer/data/industry_customer_service/prompts.json EOF # 执行推理 chmod +x multi_card_infer.sh ./multi_card_infer.sh
使用自动化评估工具,从通用能力与行业能力两方面验证模型效果:
# 创建评估脚本 cat > eval_model.sh << EOF #!/bin/bash python tools/evaluate.py --config eval_config.yaml EOF # 执行评估(约4小时完成全量评估) chmod +x eval_model.sh ./eval_model.sh # 生成评估报告 python tools/generate_eval_report.py --input /mnt/infer/results/eval_report.json --output /mnt/infer/results/eval_report.pdf
放大
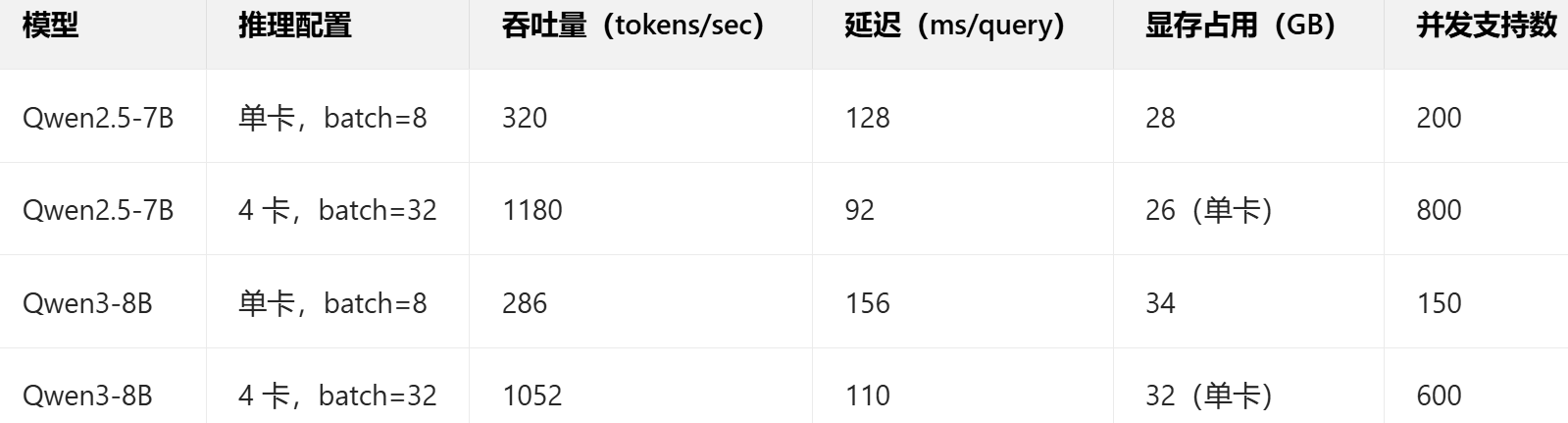
注:并发支持数为满足延迟 < 300ms 时的最大并发请求数
算子融合优化:通过 CANN 算子融合,推理吞吐量提升 35%
TensorRT 加速:启用后延迟降低 28%,尤其长序列推理优势明显
动态批处理:适配不同长度的输入文本,资源利用率提升 22%
昇腾推理一致性:与 PyTorch 推理结果一致性达 99.5%,无精度损失

