


109
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享最近,检索增强生成(RAG)技术迅速崛起,成为让大模型获取领域知识、减少“幻觉”的主流方案。但在面对法律、医疗、政务等专业领域时,单纯基于向量相似度的检索往往显得“力不从心”——它难以捕捉知识之间的逻辑关联、数值关系与专家规则,导致生成的答案缺乏严谨性与专业性。
为了解决这一问题,蚂蚁集团知识图谱团队与浙江大学合作,提出了一种全新的专业领域知识服务框架——知识增强生成(Knowledge Augmented Generation, KAG)。KAG 并非简单地将图谱结构融入检索流程,而是深度融合知识图谱的符号推理能力与大模型的语义理解能力,构建了一个双向增强、逻辑严谨、可解释性强的新一代问答系统。
论文标题:KAG: Boosting LLMs in Professional Domains via Knowledge Augmented Generation
论文链接:https://arxiv.org/abs/2409.13731
开源代码:https://github.com/OpenSPG/KAG
传统 RAG 的核心是通过向量检索找到与问题相似的文本片段,然后交给大模型生成答案。这种方式存在两个根本瓶颈:
知识图谱(KG)以其显式的语义关系和强大的符号推理能力,恰好能补足这些短板。但传统 KG 构建成本高、覆盖面有限,且与大模型的结合往往停留在“检索后拼接”层面,未能实现深度融合。
KAG 框架包含三个主要部分:KAG-Builder(离线构建)、KAG-Solver(在线求解)和 KAG-Model(模型增强),并通过以下五个关键技术实现突破:
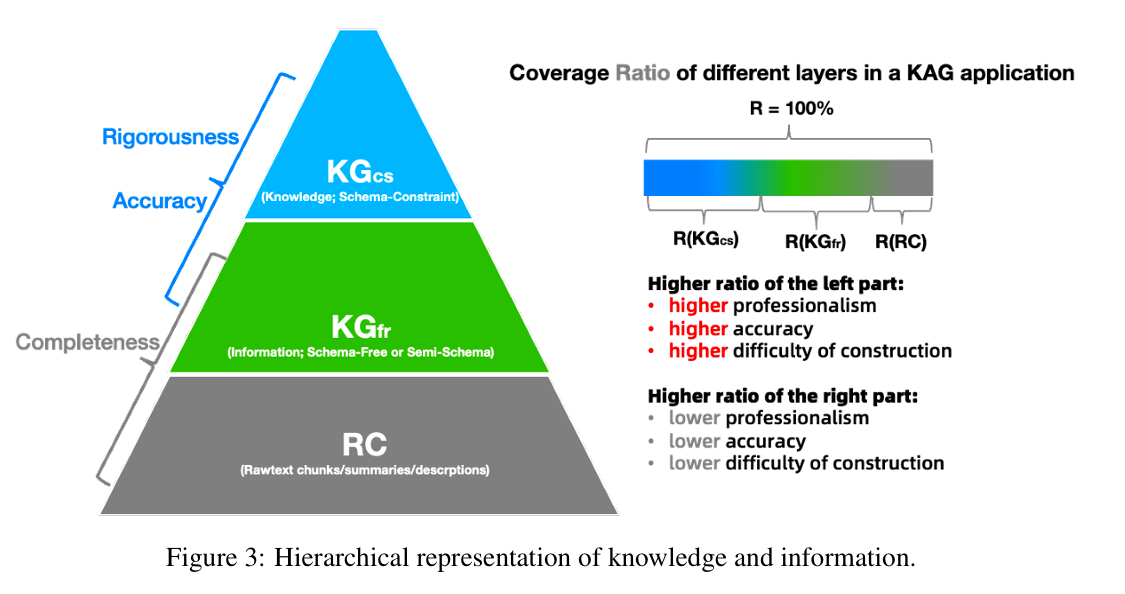
为了让知识既适合机器推理又便于大模型理解,KAG 提出了 LLMFriSPG 知识表示框架。它将知识分为三个层次:
图1:KAG 整体框架,包含 KAG-Builder、KAG-Solver 和 KAG-Model。
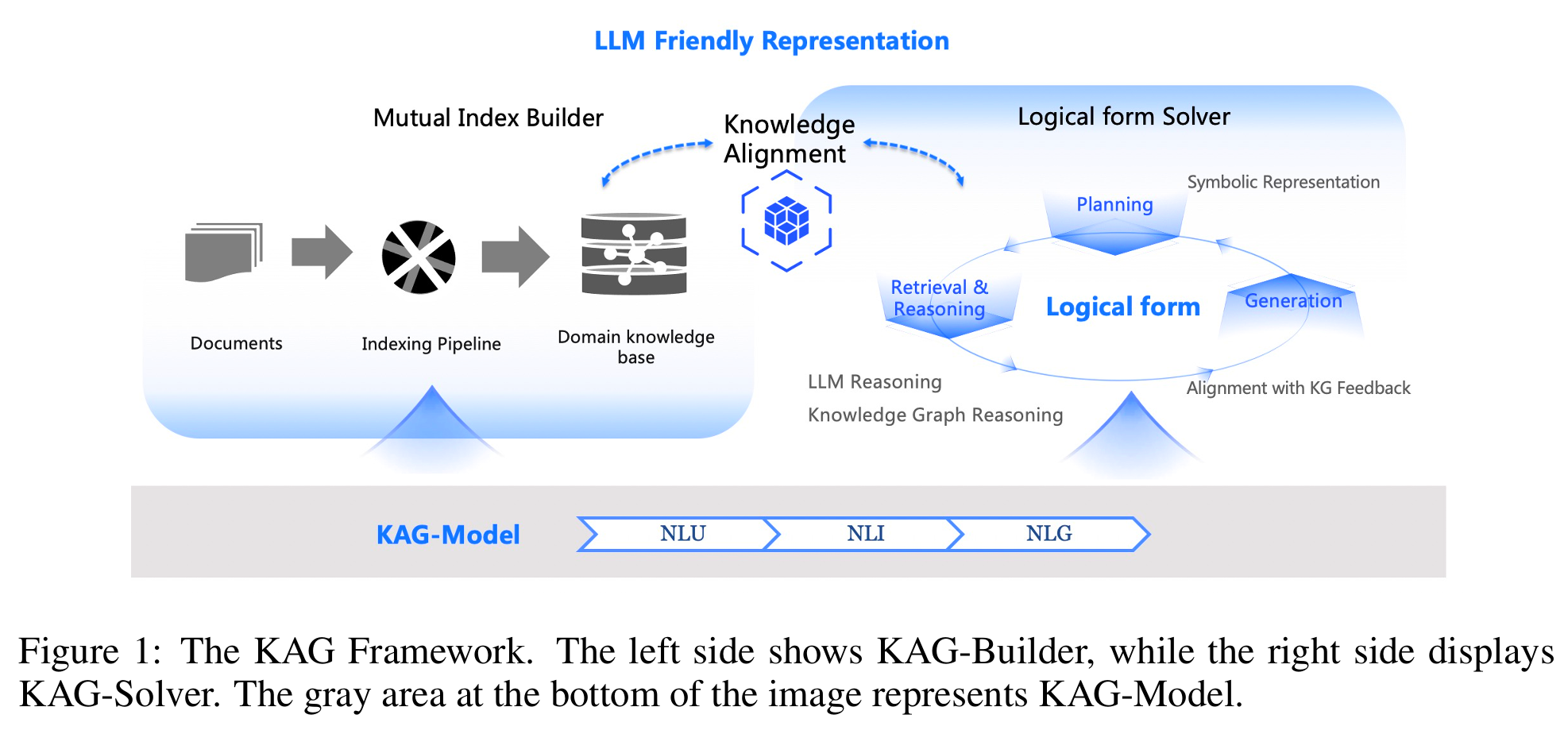
这种分层设计既保证了知识的准确性,又通过“支持块”索引实现了图谱与原文的互相关联,为后续的混合检索与推理奠定了基础。
KAG 在构建阶段就建立了图谱节点与文本块之间的双向索引。每个实体、事件都会关联到原文中出现的所有文本块,反之每个文本块也会指向其中出现的知识节点。这种结构不仅增强了知识的可解释性,也为后续的图引导检索提供了可能。
这是 KAG 的“大脑”。它定义了一套逻辑形式语言,将自然语言问题转化为包含检索、排序、计算、推理等多个步骤的可执行计划。
例如,对于问题:“C罗在 2011 年效力的球队中,哪一支成立时间最晚?”,逻辑形式可以分解为:
检索 C罗在 2011 年效力的球队;
检索这些球队的成立年份;
按成立年份排序,取最晚的一支。
图2:LLMFriSPG 知识表示框架。
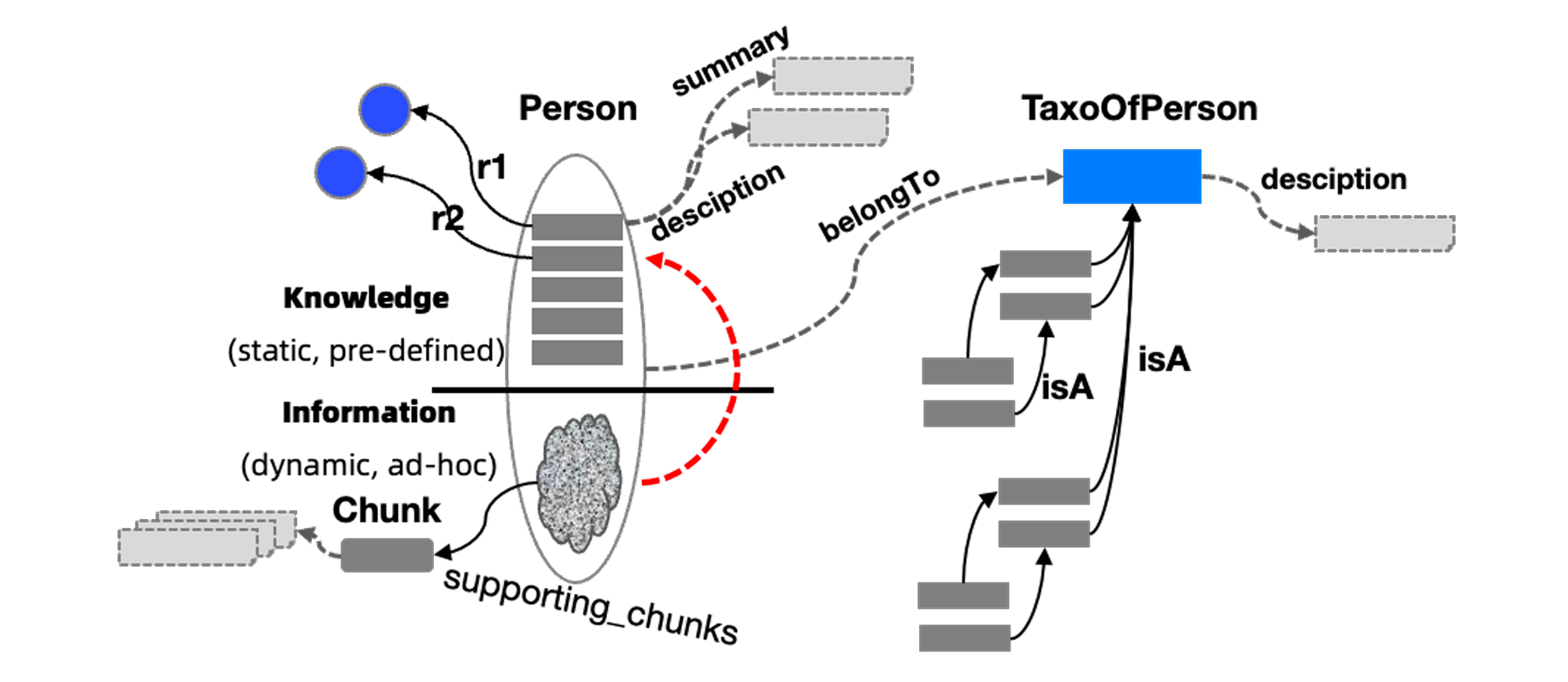
为了提升知识的连贯性与检索准确性,KAG 在构建与检索阶段都引入了语义关系推理,如同义、上下位、包含、因果等关系。例如,“白内障患者”可对齐到“视障人士”,即使用户未明确提及后者,系统也能通过语义关联找到相关文档。
KAG 还对底层大模型进行了针对性增强,通过指令微调提升其在自然语言理解、推理与生成三个核心任务上的表现。实验显示,经过 KAG 微调的模型在多项理解与推理基准上均有显著提升。
论文在三个经典的多跳问答数据集上进行了测试:
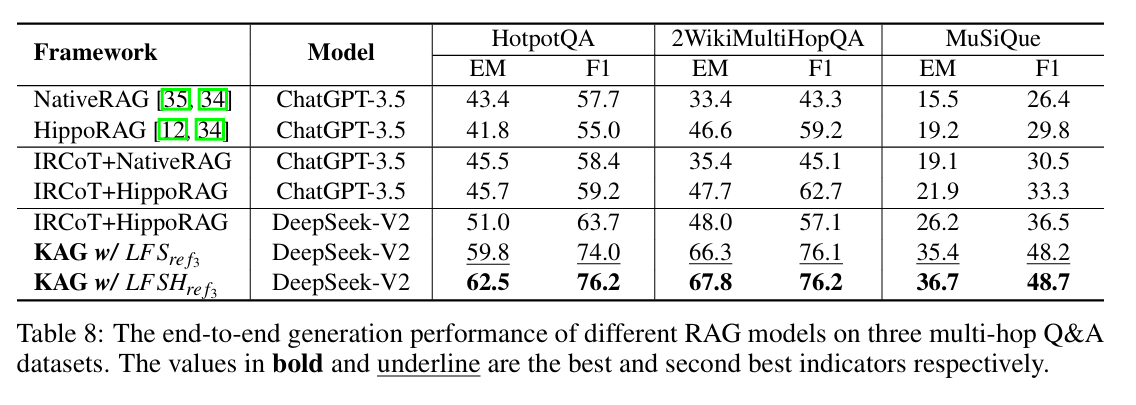
与当前最强的 RAG 方法 HippoRAG 相比,KAG 在 F1 分数上分别提升了 **19.6%、33.5% 和 12.5%**,检索召回率也有显著提高。
表1:KAG 在多项指标上显著优于现有方法(对应论文表8)。
消融实验进一步验证了各个模块的有效性:知识对齐增强明显提升了图谱的连通性与检索效果;逻辑形式推理在保证答案准确性的同时,也大幅提升了复杂问题的求解能力。
图3:知识与信息的分层表示。
KAG 已在蚂蚁集团的实际业务中落地,覆盖政务与健康两大领域:
基于 1.1 万份政务服务文档,KAG 能够准确回答用户关于办事流程、所需材料、办理地点等问题。通过语义关联,系统还能识别同义事项(如“社保卡换领”与“社保卡挂失补办”),提升召回率。实验显示,KAG 在政务问答中的准确率达 **91.6%**,显著高于传统 RAG。
在医疗场景中,KAG 依托高质量的医疗知识图谱,支持疾病科普、指标解读、医保政策查询等任务。系统还能触发预定义的医学规则(如血压分级判断),实现精准的指标推理与解释。在真实线上问答测试中,KAG 在科普类意图的准确率超过 **94%**,指标解读准确率超过 **93%**。
KAG 目前已在开源知识图谱引擎 OpenSPG 中原生支持,开发者可基于该框架快速构建专业领域的知识服务系统。未来,团队将继续优化知识提取与对齐技术、提升复杂问题规划能力,并探索基于 OneGraph 的大规模知识融合。
无论是构建严谨的知识决策系统,还是便捷的信息检索服务,KAG 都提供了一个融合符号与神经、兼顾准确性与覆盖度的新一代框架。
在专业领域智能化服务的道路上,单纯依赖大模型或传统知识图谱都显得捉襟见肘。KAG 通过知识增强生成的设计理念,真正实现了 LLM 与 KG 的双向赋能:知识图谱为大模型提供精准、可推理的符号知识,大模型则为知识图谱提供语义理解与灵活生成能力。
这种“神经 + 符号”的融合,或许正是下一代专业 AI 系统的正确打开方式。

