


109
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享近年来,基于大语言模型(LLM)的多智能体代码生成框架(如 MapCoder、AgentCoder)在 HumanEval 等基准上取得了显著进展。然而,现有工作几乎全部围绕 ChatGPT 系列闭源模型(如 GPT-4)进行设计与验证,其在开源 LLM 上的泛化能力(generalizability)尚缺乏系统研究。
来自重庆大学与浙江大学的研究团队在最新论文《AdaCoder: An Adaptive Planning and Multi-Agent Framework for Function-Level Code Generation》中首次系统评估了四种 SOTA 多智能体框架(AgentCoder、MapCoder、INTERVENOR、Self-Collaboration)在六种开源 LLM(CodeLlama-Python 7B/13B/34B、DeepSeek-Coder 1.3B/6.7B/33B)上的表现,并发现:
🔴 现有框架泛化性极不稳定:AgentCoder 与 Self-Collaboration 在多数开源模型上性能反而下降;MapCoder 虽表现最佳,但推理成本极高(平均 token 消耗 ↑23×,推理时间 ↑15.7×)。
基于此,作者提出 AdaCoder —— 一种自适应规划(Adaptive Planning)的多智能体框架。AdaCoder 通过动态选择是否启用规划机制,在保持高泛化性的同时显著降低计算开销。实验表明:
作者首先对四个 SOTA 多智能体框架在 HumanEval 上进行系统评估(见 Table I),揭示两大核心问题:
多数框架依赖 LLM 进行多轮“生成 → 测试 → 修复”循环。然而在开源模型上,这种迭代几乎无效:
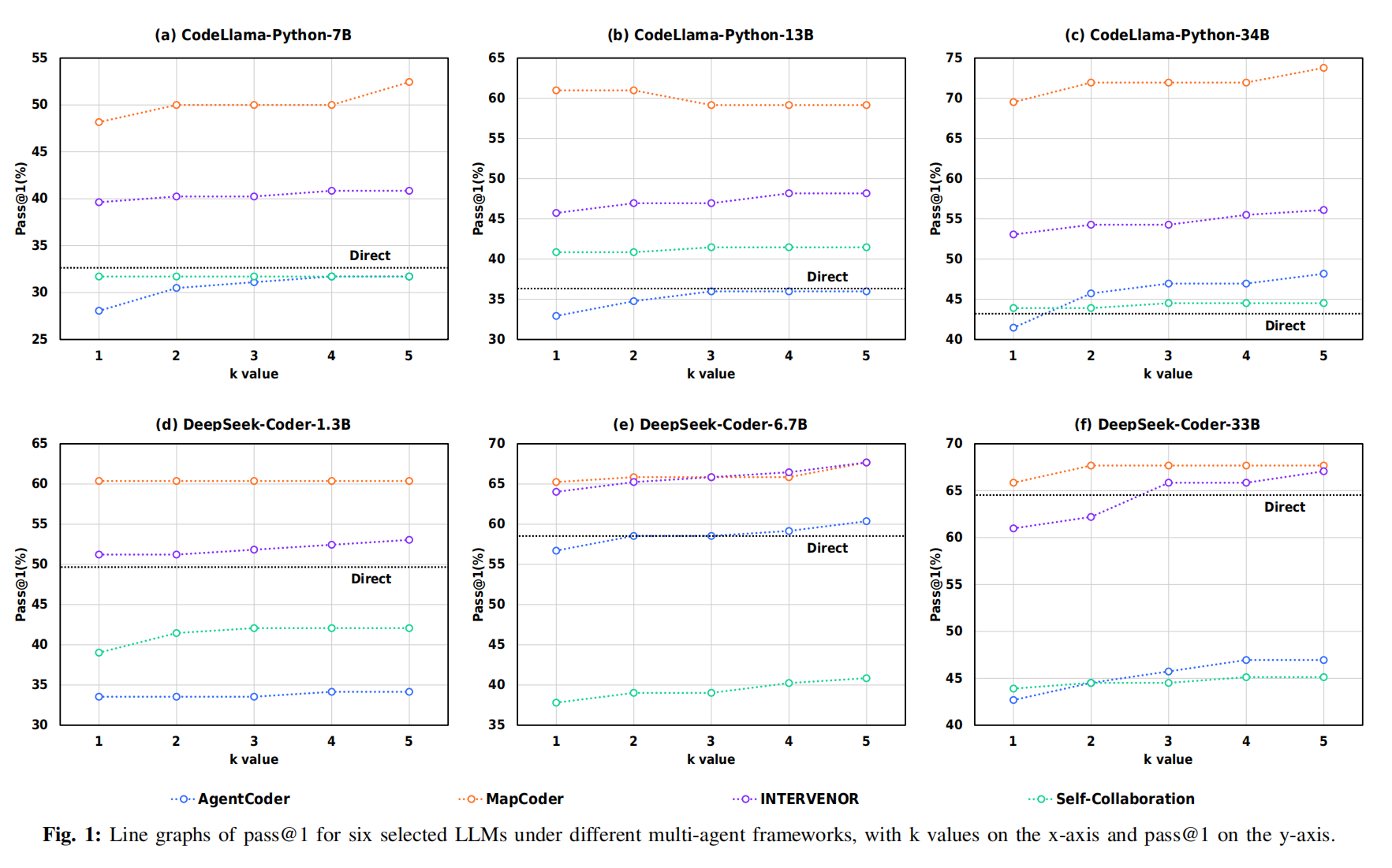
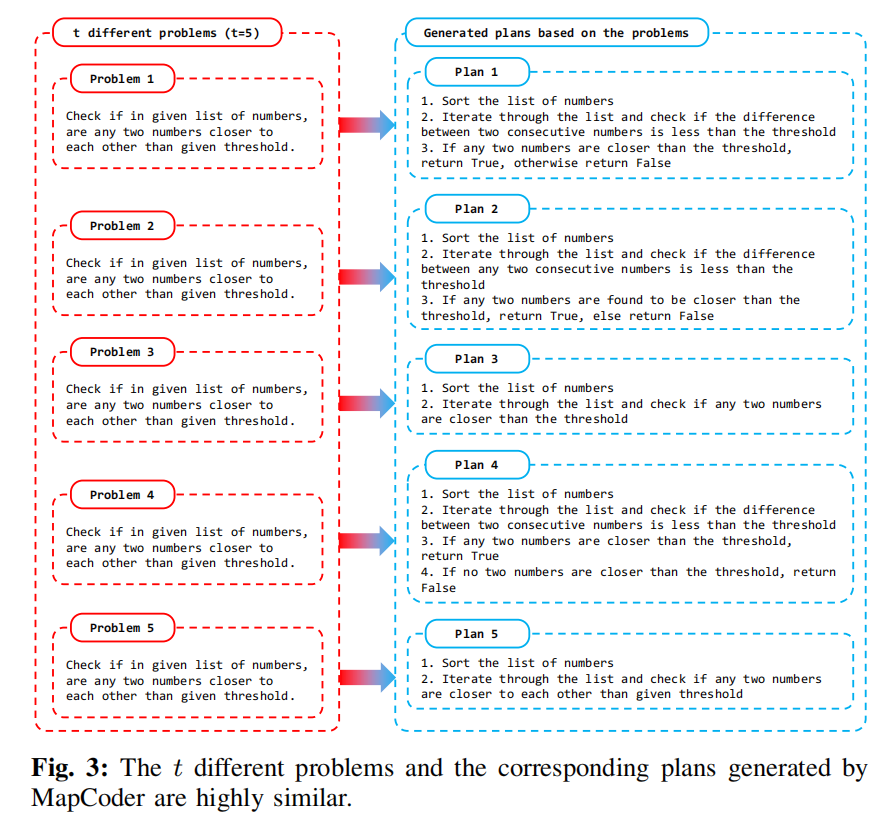
MapCoder 之所以表现最好,因其采用 Multi-Plan Coding:先生成多个相似子任务,再为每个子任务生成执行计划。但该机制存在严重缺陷:
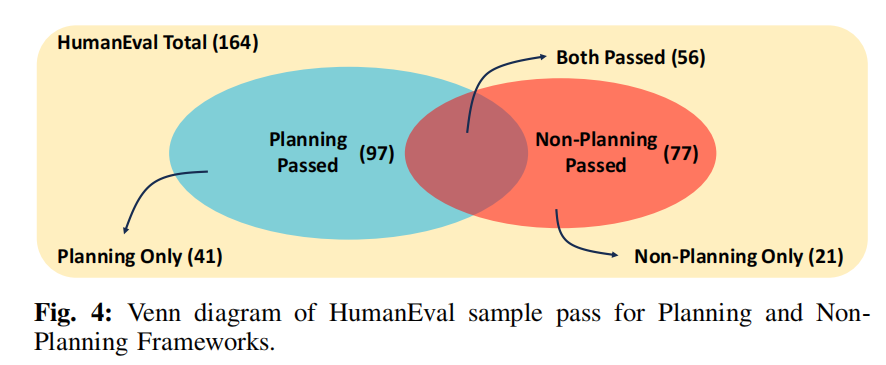
更关键的是,作者发现:规划与非规划机制具有互补性(见 Figure 4 的 Venn 图):
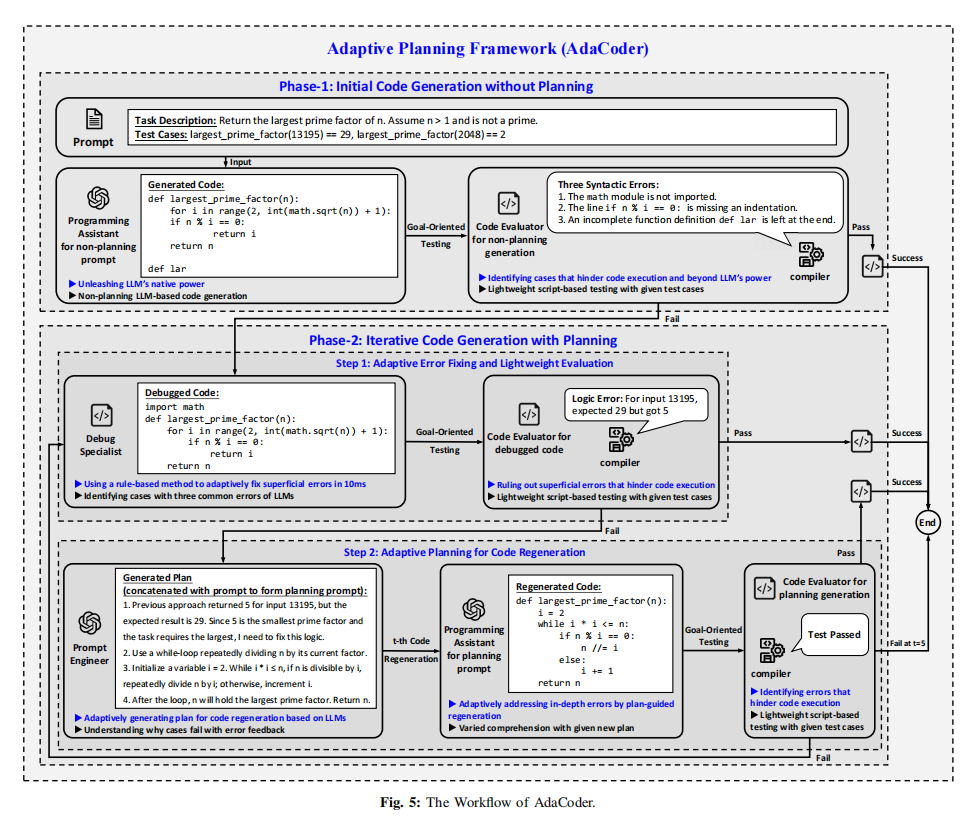
AdaCoder 的核心思想是:仅在必要时启用规划机制,并用规则式调试替代 LLM 修复以降低成本。其包含四个智能体(见 Figure 5):
⚠️ 关键设计:避免 LLM 生成测试用例,防止“用错误测试引导错误修复”。
在 HumanEval + MBPP 上,AdaCoder vs 基线(Table V, VI):
|
框架 |
HumanEval Avg Pass@1 |
MBPP Avg Pass@1 |
总提升 |
|---|---|---|---|
|
Direct(无框架) |
51.0% |
56.0% |
— |
|
MapCoder |
73.5% |
61.3% |
+32.2% |
|
AdaCoder |
78.9% |
81.4% |
+50.0% ✅ |
|
框架 |
Token 消耗(vs Direct) |
推理时间(vs Direct) |
|---|---|---|
|
MapCoder |
↑26.8× |
↑16.0× |
|
AdaCoder |
↑2.2× |
↑1.0× ✅ |
🚀 AdaCoder 比 MapCoder 快 16 倍,token 少用 12 倍!
移除任一组件均导致性能显著下降:
证明 AdaCoder 的自适应规划与规则调试均不可或缺。

