


109
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享近期,浙江大学、重庆大学与蚂蚁集团合作发表了一篇题为《Issue Localization via LLM-Driven Iterative Code Graph Searching》的论文,提出了一种名为 COSIL(Code Graph-based Issue Localization)的新型问题定位框架。该方法在无需训练、无需预建索引的前提下,在 SWE-bench Verified 与 Lite 上分别实现了 44.6% 与 43.3% 的函数级 Top-1 定位准确率,平均超越当前 SOTA 方法达 96.04%,并显著提升下游自动修复系统的成功率。
本文对 COSIL 的核心思想、技术架构和实验结果进行系统性解读。
在 LLM 驱动的软件工程自动化(如 GitHub Issue 自动修复)中,问题定位(Issue Localization)是关键前置步骤——目标是从大型代码库中精准识别出需要修改的具体函数。然而,该任务极具挑战:
这些问题严重制约了 LLM 在真实软件仓库中的定位效能。
COSIL 提出一种 两阶段图驱动的迭代搜索策略,结合剪枝机制与反射对齐,在不训练、不建索引的前提下实现高精度定位。
import 关系扩展搜索范围,纳入间接依赖模块(如 django/forms/models.py)。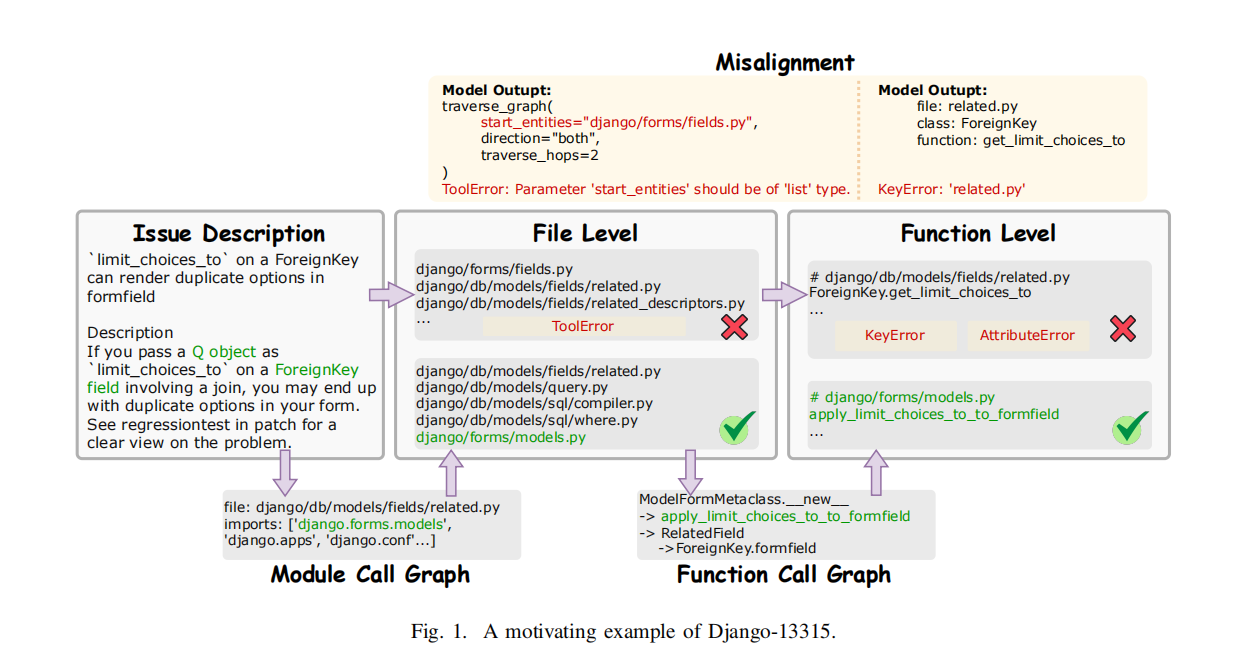
该策略既避免了“仅看 Issue 提及文件”的视野局限,又防止了“全仓库漫游”的噪声爆炸。
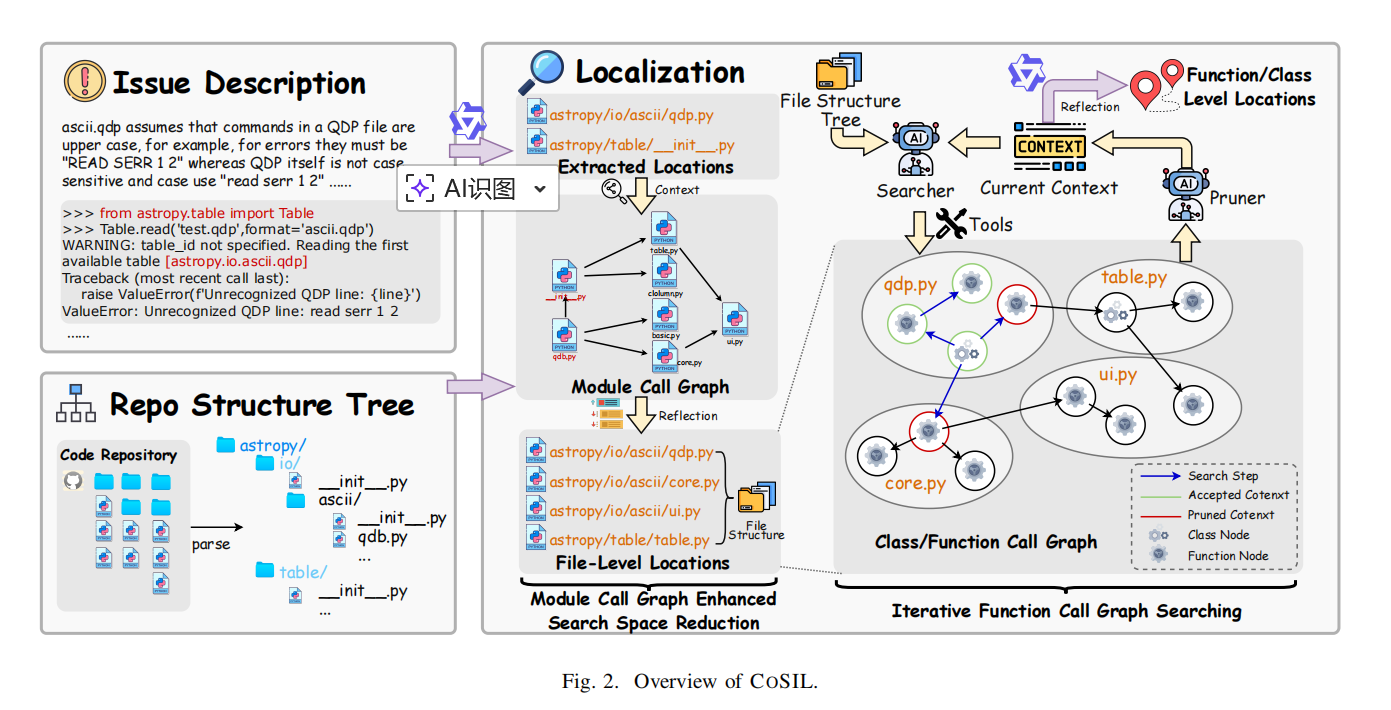
在每次 LLM 选择一个目标节点后,COSIL 引入一个轻量级判断器(同样是 LLM),根据节点代码片段与 Issue 的语义相关性,输出布尔值决定是否:
实验证明,剪枝机制有效抑制了无关路径的探索,提升上下文信息密度。
借鉴 Reflexion 思想,COSIL 在每个阶段结束时,使用一个独立的短上下文查询,要求 LLM 对当前输出结果进行重排与格式化校正。

COSIL 利用 LLM 解析代码中的 import 与函数调用关系,按需生成局部子图(见论文 Algorithm 1),避免了预建全仓库图的存储与维护开销。
在 SWE-bench Lite / Verified 上,使用 Qwen2.5-Coder-32B:
|
方法 |
Function-level Top-1 |
|---|---|
|
Agentless-FL |
24.7% |
|
OrcaLoca |
21.7% |
|
LocAgent |
10.3% |
|
COSIL |
43.3% / 44.6% ✅ |
移除各组件后性能下降显著:

应用价值(RQ3)
将 COSIL 集成到 Agentless 修复流程中:
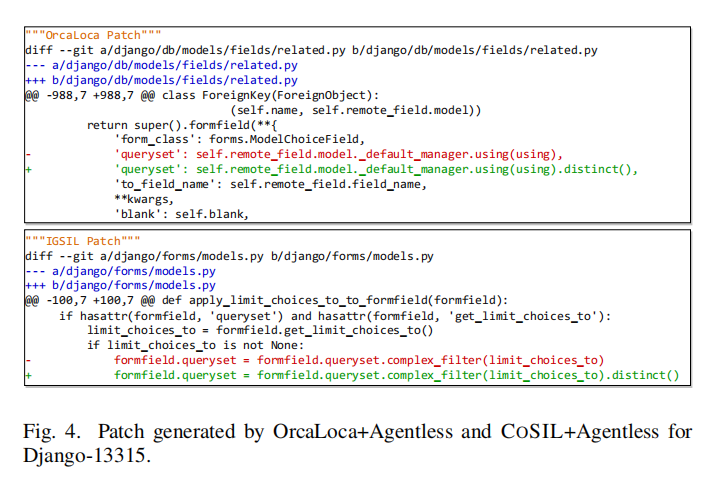
在 DeepSeek-v3 与 GPT-4o 上均保持领先,且成本可控:
COSIL 通过 “图扩展 + 迭代探索 + 剪枝控制 + 反射校正” 的组合策略,有效解决了 LLM 在代码库中“找不准、走偏路、说不清”的三大痛点。其在函数级定位上的突破,不仅推动了 Issue Localization 任务的发展,也为构建更可靠的 LLM-based 软件工程智能体提供了新范式。
引用:
Jiang, Z., Ren, X., Yan, M., et al. (2025). Issue Localization via LLM-Driven Iterative Code Graph Searching. arXiv:2503.22424.

