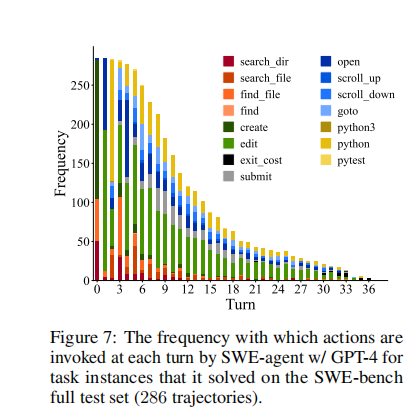
109
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享在仓库级软件修复(Repository-level Software Repair)任务中,如何让大语言模型(LLM)?现有方法多直接复用人类交互界面(如 Linux Shell、VSCode),但 LLM 与人类在认知能力、上下文处理、错误恢复等方面存在本质差异,导致性能受限。
来自普林斯顿大学的研究团队在 NeurIPS 2024 发表的 SWE-agent 论文首次提出 代理-计算机接口(Agent-Computer Interface, ACI)这一新范式,并构建了一个面向软件工程任务的专用 ACI。在 SWE-bench 上,SWE-agent 使用 GPT-4 Turbo 实现 12.47% 的修复成功率(pass@1),远超此前 SOTA 的 3.8%;在 HumanEvalFix 上更是达到 87.7%,验证了其在函数级修复中的强大能力。
更重要的是,SWE-agent 揭示了一个核心设计原则:为 LLM 代理量身定制的交互接口,比直接复用人类 UI 更有效。
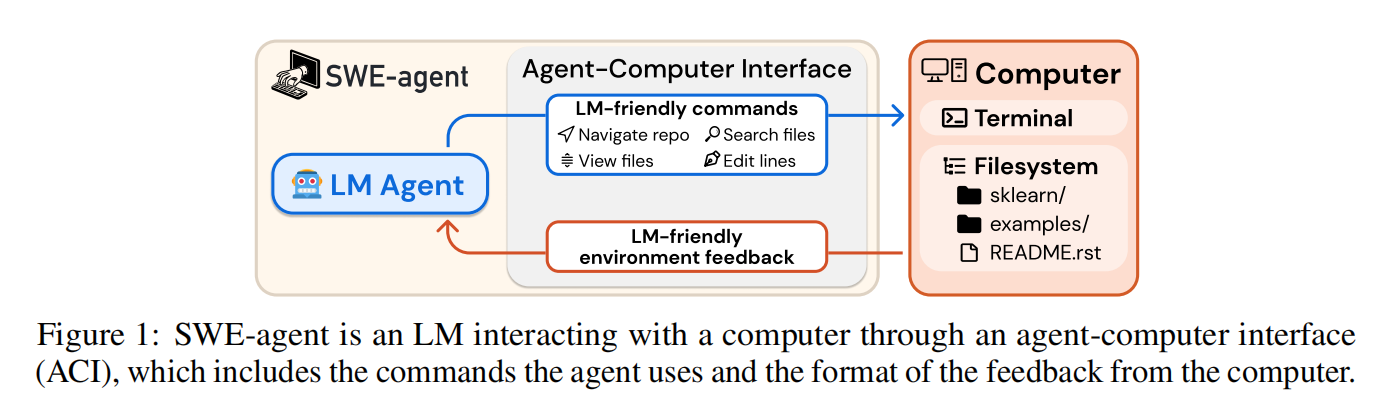
论文指出,当前 LLM 代理(如 AutoCodeRover、SWE-Agent 原型)多在 Linux Shell 中操作,但 Shell 存在三大问题:
sed、grep 等命令选项繁多,LLM 难以准确使用,常因参数错误导致编辑失败。rm file.py),LLM 无法确认操作是否生效,易重复执行或误判状态。
SWE-agent 围绕 “面向 LLM 优化” 提出四大设计原则,并据此构建 ACI:
find_file、search_file、search_dir 替代 ls+cd+grep 组合;edit start:end replacement_text 一步完成多行替换;open + goto/scroll 支持高效导航,避免 cat 淹没上下文。
rm),主动返回 "Your command ran successfully...";edit 后运行 flake8 检查语法,若出错则:
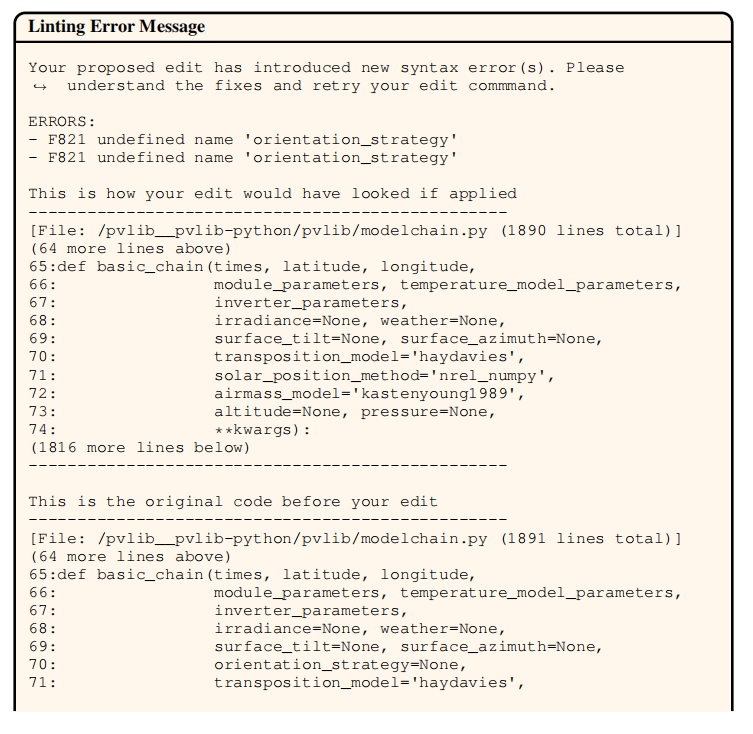
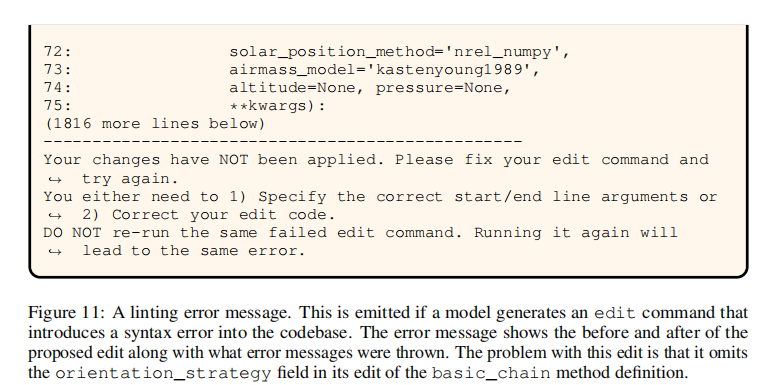
|
系统 |
模型 |
% Resolved |
$ Avg Cost |
|---|---|---|---|
|
RAG (非交互) |
GPT-4 Turbo |
1.31% |
$0.13 |
|
Shell-only |
GPT-4 Turbo |
11.00% |
$1.46 |
|
SWE-agent |
GPT-4 Turbo |
12.47% |
$1.59 |
|
SWE-agent |
Claude 3 Opus |
10.46% |
$2.59 |