在仓库级软件修复(Repository-level Software Repair)任务中,精准定位故障函数是自动修复成功的关键前提。然而,现实中的 GitHub Issue 通常未明确提及修改位置(仅 32.7% 含显式文件/函数名),且代码库规模庞大(如 Django 含 27,867 个函数),导致纯 LLM 方法常因语义模糊、上下文缺失、推理能力不足而失败。
来自燕山大学、南洋理工大学、墨尔本大学与阿尔托大学的研究团队在最新论文《Enhancing repository-level software repair via repository-aware knowledge graphs》中提出 KGCompass —— 一种仓库感知知识图谱(Repository-aware KG)驱动的修复框架。其实验表明:
- 修复成功率 58.3%(SWE-bench Lite),为所有开源单模型方法中最高;
- 函数级定位准确率 56.0%,显著优于纯 LLM;
- 成本仅 $0.2/bug,远低于 SWE-agent($1.6)与 ExpeRepair($2.1);
- 对 Claude-4 Sonnet、Claude-3.5 Sonnet、DeepSeek-V3、Qwen2.5 Max 等模型均提升显著(+30.2% ~ +156.4%);
- 89.7% 的成功定位依赖多跳图遍历,证明 KG 在桥接自然语言与代码结构中的核心价值。
动机:为何纯 LLM 难以胜任仓库级修复?
作者通过分析 SWE-bench Lite 指出两大核心挑战:
1. 故障定位不精确(Imprecise Fault Location)
- 仅 32.7% 的 Issue 显式提及目标文件/函数;
- LLM 易受词汇偏见影响(如 Issue 提到 “multiply”,就只查 multiply 相关函数);
- 现有方法(如 Agentless)仅提供 1 个候选位置,若错误则修复失败;
- 扩大候选集会引入噪声,增加 LLM 幻觉风险。

2. 缺乏可解释性(Lack of Interpretability)
- Agentic 方法(如 SWE-agent)决策过程为黑盒;
- Procedural 方法(如 Agentless)虽提供 Patch,但未解释为何选择该位置;
- 开发者难以信任或验证修复逻辑。
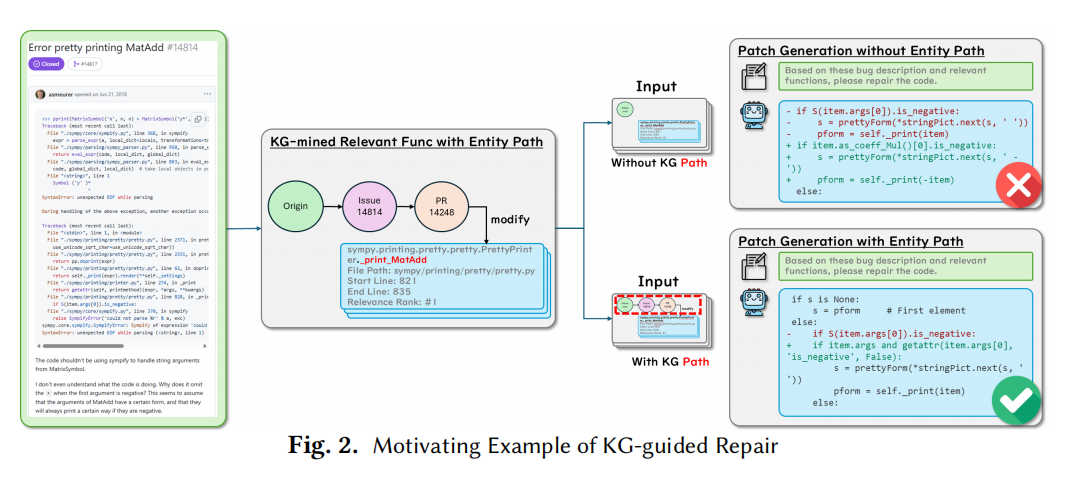
KGCompass 方法论:三阶段图驱动修复
KGCompass 包含三个阶段(见 Figure 3):
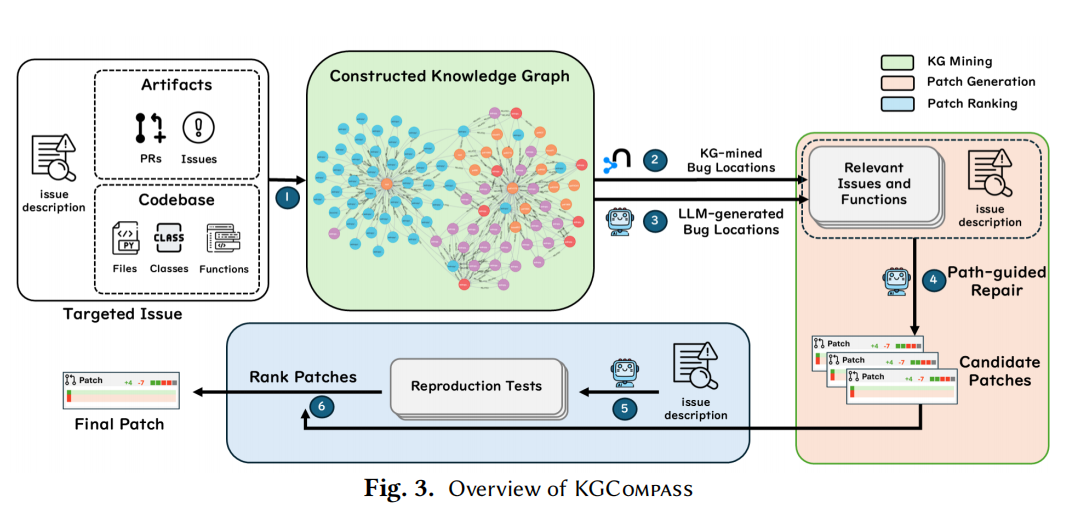
阶段 1:知识图谱构建与候选定位(Knowledge Graph Mining)
- 节点类型:仓库级(Issue、PR)、代码级(File、Class、Function);
- 边类型:
- 代码结构边:AST 分析得到的 containment(file→class→function)、call、import、attribute;
- 语义链接边:正则匹配 Issue/PR 文本中提到的文件/函数名,并仅保留时间早于 Issue 创建时刻的工件(防数据污染)。
- 候选生成:
- 用公式 S(f)=βl(f)⋅(α⋅cosnorm(ei,ef)+(1−α)⋅lev(ti,tf))S(f)=βl(f)⋅(α⋅cosnorm(ei,ef)+(1−α)⋅lev(ti,tf)) 评分函数相关性;
- 选取 KG Top-15 + LLM Top-5,共 20 个候选函数。
阶段 2:路径引导的补丁生成(Patch Generation)
- 为每个候选函数提供 实体路径(Entity Path):
issue → PR#14248 → _print_MatAdd
- Prompt 包含:(1) Issue 描述, (2) 20 个候选函数及路径, (3) 搜索-替换格式指令;
- 采用混合采样(T=0 确定性 + T>0 多样性),并用 自适应缩进修正(Algorithm 1)修复语法错误。

阶段 3:多层补丁排序(Patch Ranking)
- 生成 LLM 再现测试(平均 113 个/issue) + 回归测试;
- 四级排序策略:
- 通过回归测试数(仅限原代码已通过的);
- 通过再现测试数;
- 多数投票(最频繁补丁);
- 补丁尺寸(短优先)。
实验结果:全面超越 SOTA
主实验(RQ1)
在 SWE-bench Lite 上(Table 1):
|
系统
|
模型
|
Resolved%
|
成本
|
File Acc
|
Func Acc
|
|---|
|
ExpeRepair
|
Claude-4 + o4-mini
|
60.3%
|
~$2.1
|
84.7
|
52.6
|
|
Refact.ai Agent
|
Claude-3.7 + o4-mini
|
60.0%
|
N/A
|
80.6
|
47.0
|
|
KGCompass
|
Claude-4 Sonnet
|
58.3%
|
$0.2
|
83.6
|
56.0 ✅
|
|
SWE-agent
|
Claude-4
|
56.7%
|
~$1.6
|
80.9
|
53.9
|
|
KGCompass
|
Claude-3.5 Sonnet
|
46.0%
|
$0.2
|
76.7
|
49.4 ✅
|
- KGCompass 是单模型最佳(无需模型融合);
- 函数级定位准确率最高(56.0%);
- 成本最低($0.2)。
与纯 LLM 基线对比(Table 2):
- Claude-4: +50.8% → 58.3%
- Claude-3.5: +30.2% → 46.0%
- DeepSeek-V3: +115.7% → 36.7%
- Qwen2.5 Max: +156.4% → 33.3%
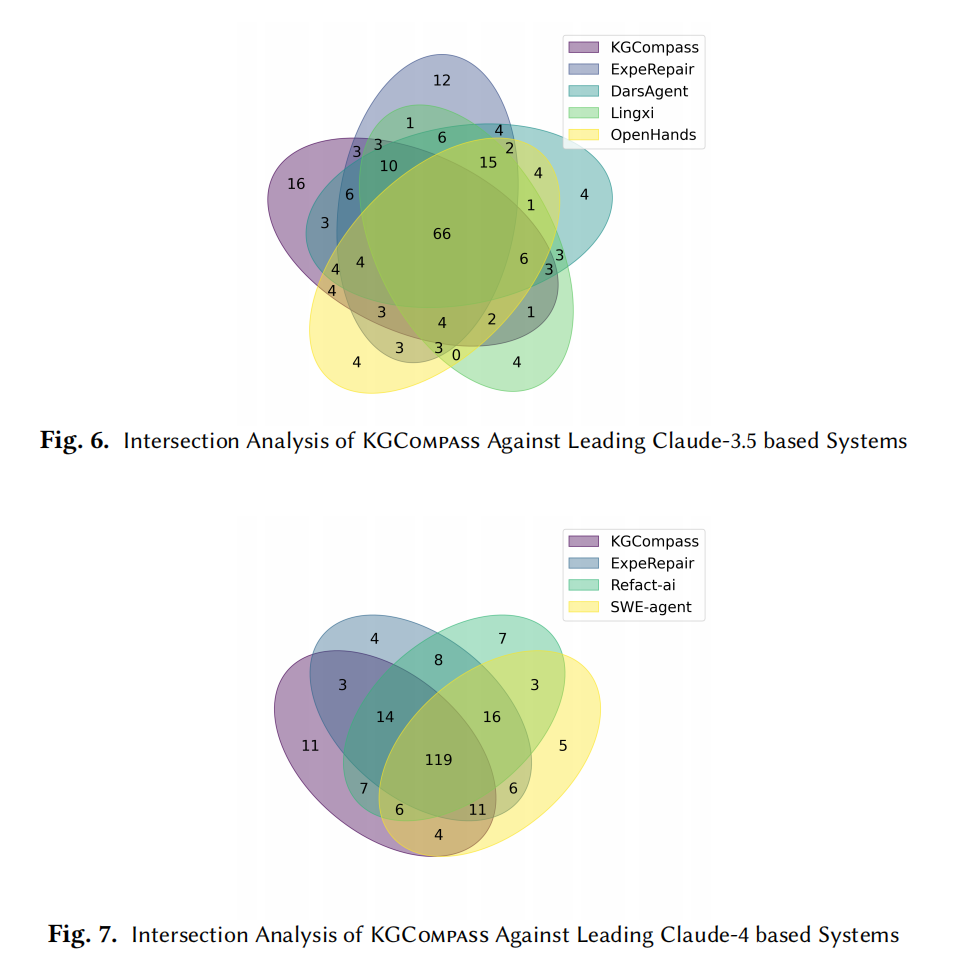
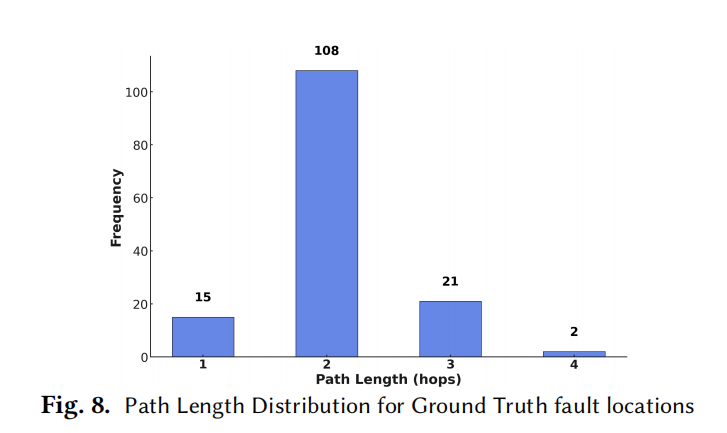
KG 贡献分析(RQ2)
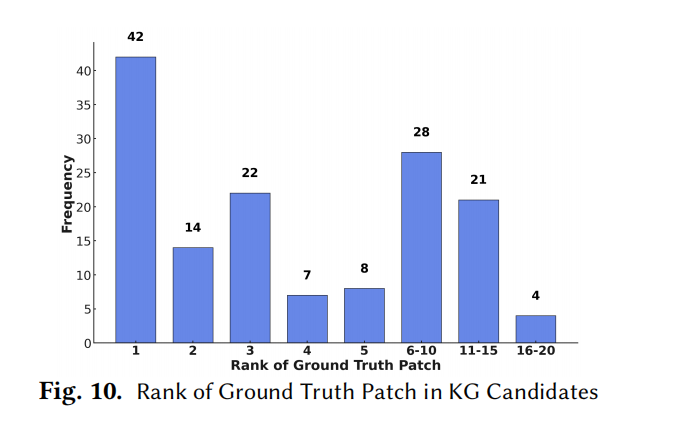
- 20 个 KG 候选函数覆盖 68.7% 文件 / 40.4% 函数级真值;
- 89.7% 的真值需 ≥2 跳路径);
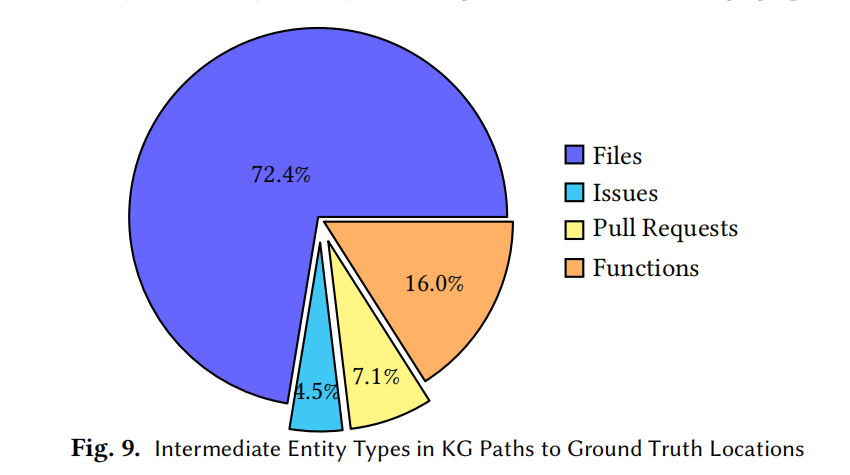
- 中间节点:72.4% 文件、16.0% 函数、7.1% PR、4.5% Issue;
消融实验(RQ3)
- 混合定位(KG+LLM)> LLM-only > KG-only;
- 加入实体路径:Claude-4 从 131 → 142 个修复(Table 6);
- 多层排序:从 139 → 175(Table 7);
- 6 个候选补丁:达到性能饱和(Table 8)。
启示与贡献
- 知识图谱是桥接自然语言与代码结构的有效媒介;
- 多跳路径对无显式提示的 Issue 至关重要(占 67.3%);
- 实体路径不仅提升定位,能引导 LLM 生成更健壮补丁;
- 低成本($0.2),适合工业落地。
开源地址:暂未公开(论文未提供),但方法细节完整。



 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
