


109
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享在 LLM 驱动的软件工程智能体(Software Engineering Agent)领域,当前主流方法(如 SWE-agent、Agentless、AutoCodeRover)普遍采用静态架构设计——即工具集、工作流、提示模板等在部署前固定,无法在任务执行过程中动态优化。这种“一次性设计、全局适用”的范式存在两大根本性局限:
针对这一瓶颈,UIUC 研究团队在最新论文 《LIVE-SWE-AGENT: Can Software Engineering Agents Self-Evolve on the Fly?》 中提出 首个运行时自进化软件工程智能体。其核心思想是:智能体本身也是软件,应能像人类程序员一样,在解决真实问题的过程中即时修改自身工具与逻辑。
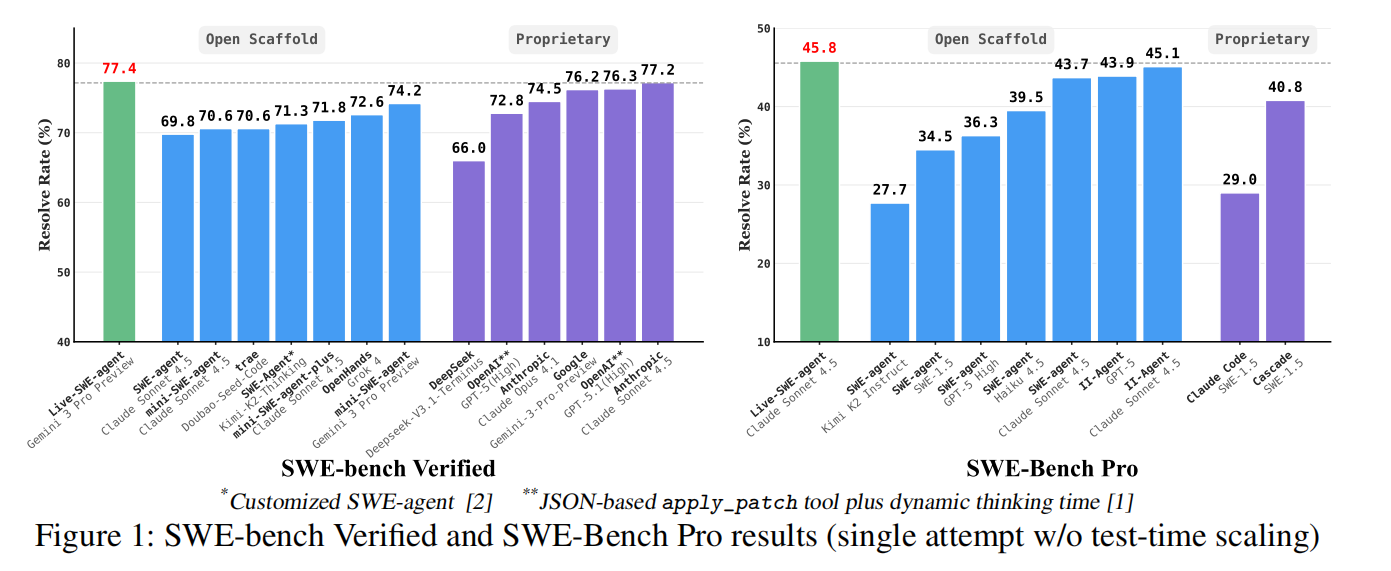
实验表明,LIVE-SWE-AGENT 在 SWE-bench Verified 上达到 77.4% 的单次修复成功率(pass@1),超越所有现有系统(包括最强商业方案);在更难的 SWE-Bench Pro 上达 45.8%,为当前 SOTA。更关键的是,它无需离线训练、无需预构建工具库,仅从一个极简的 bash-only 智能体(mini-SWE-agent)出发,在任务执行中自主创建、调试、复用定制化工具。
作者指出,当前自进化智能体(如 DGM、SICA)存在三大缺陷:
💡 核心洞见:与其在任务外“预训练”一个通用智能体,不如让智能体在任务内“即时创造”专用工具——这正是 LIVE-SWE-AGENT 的设计哲学。
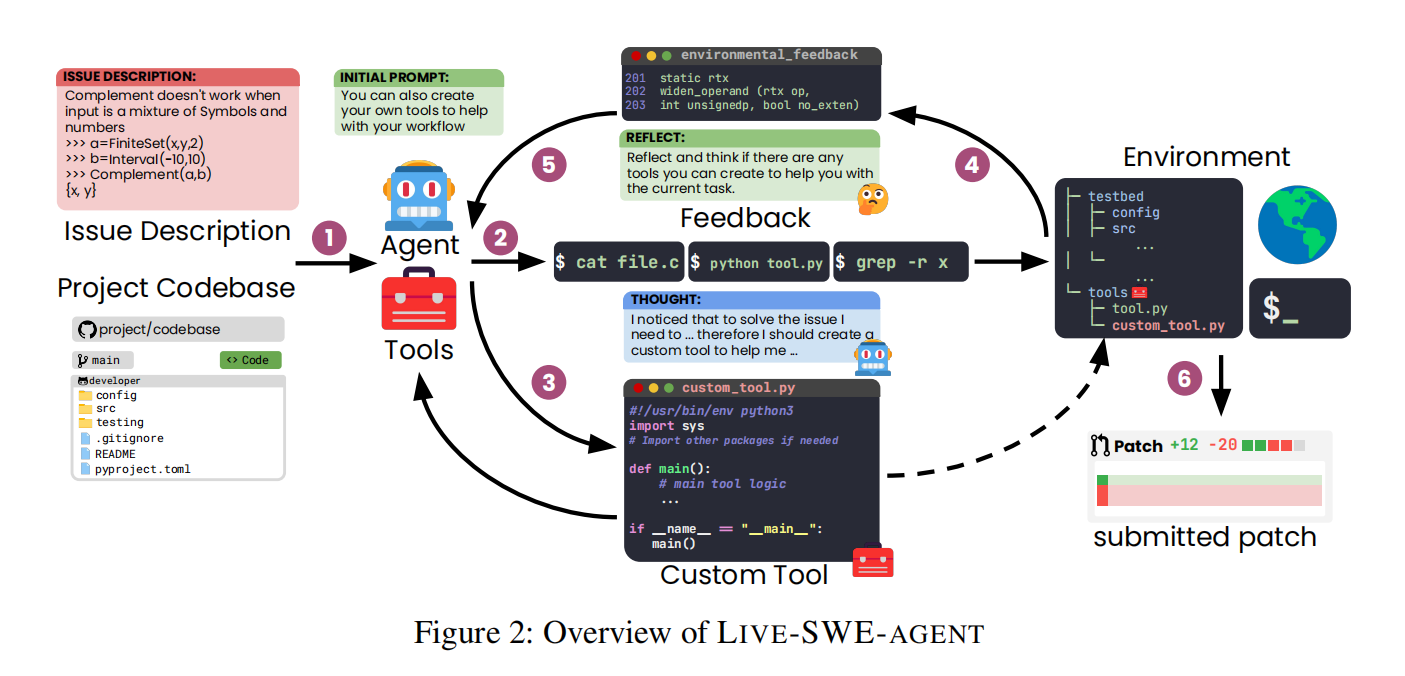
LIVE-SWE-AGENT 基于 mini-SWE-agent(仅支持 bash 命令)构建,通过三项关键机制实现自进化:
grep、cat、sed 等基础 bash 命令;python reproduce.py)cat << 'EOF' > tool.py 写入 Python 脚本)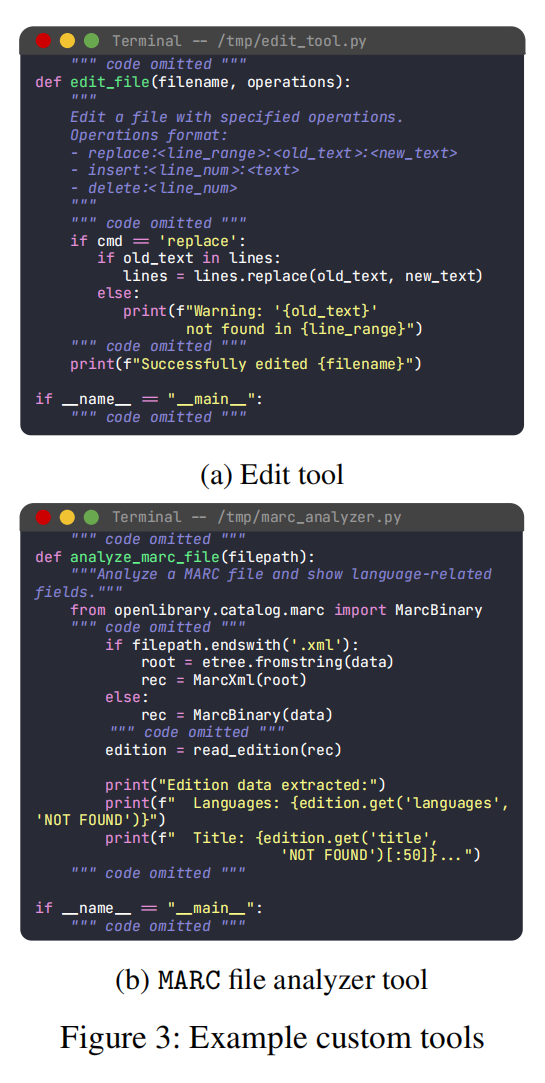
“Reflect on the previous trajectories and decide if there are any tools you can create to help you with the current task.”
|
系统 |
SWE-bench Verified |
SWE-Bench Pro |
|---|---|---|
|
LIVE-SWE-AGENT |
77.4% ✅ |
45.8% ✅ |
|
Proprietary SOTA |
≤74.2% |
≤43.9% |
|
SWE-agent |
56.7% |
43.6% |
|
Agentless |
27.4% |
— |
|
方法 |
修复率 |
离线成本 |
|---|---|---|
|
DGM |
53.3% |
1231 小时 |
|
HGM |
56.7% |
512 小时 |
|
LIVE-SWE-AGENT |
65.0% ✅ |
0 小时 ✅ |
search_code.py)。开源地址:https://github.com/OpenAutoCoder/live-swe-agent
排行榜:http://live-swe-agent.github.io

