




828
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享本文记录了一次真实的 AI 辅助开发过程:如何使用 Kiro AI IDE 从一个模糊的部署需求开始,通过人机协作,逐步设计出三层堆栈架构,并完成基于Amazon EMR Flink 智能监控系统的Amazon CDK 部署代码。
开发成果: – 开发时间:从 10 小时缩短到 1.5 小时(效率提升 6-7 倍) – 代码质量:自动应用亚马逊云科技最佳实践 – 架构演进:从单堆栈到三层堆栈的优化过程
项目地址:https://github.com/yangguangfu007/emr-flink-monitoring-agent
🔥 想利用生成式AI开发工具解放双手,却苦于应用效果不够完善、流程不够规范?
✨ 亚马逊云科技 Kiro 登场!采用“规范驱动”开发理念,结合 Agent Hooks 自动化系统,1小时让小白变身生产级游戏制作人!
🔛 速来云上探索实验室,体验 Kiro 开发独立游戏,从需求到部署全掌握!
👉点击这里,即刻开启 AI 开发之旅!
Amazon Cloud Development Kit (CDK) 是使用编程语言定义云基础设施的框架: – 使用 Python、TypeScript 等语言,而非 JSON/YAML – 代码复用和模块化 – IDE 支持(代码补全、类型检查) – 通过 Amazon CloudFormation 部署
Kiro 是亚马逊云科技推出的 AI 辅助开发工具: – 理解自然语言需求,生成 CDK 代码 – 基于 Spec 文档驱动开发 – 理解亚马逊云科技服务依赖关系 – 通过对话迭代优化架构设计
我只有一个简单的想法:
“我想把基于 Amazon EMR Flink 的监控系统部署到亚马逊云科技环境”
具体细节都不清楚: – 用什么服务部署后端?Amazon ECS?Amazon Lambda? – 前端怎么托管?Amazon S3?还是也用容器? – 网络架构怎么设计? – 安全组怎么配置?
我:我想把 Amazon EMR Flink 监控系统部署到亚马逊云科技,后端是 FastAPI,前端是 React。你有什么建议?
Kiro:
我理解你的需求。让我帮你分析一下:
后端部署选项:
Amazon Fargate – 推荐,无需管理服务器,按需付费
Amazon Lambda – 适合轻量级 API,但有 15 分钟超时限制
Amazon EC2 – 需要管理服务器,成本较高
前端部署选项:
Amazon S3 + Amazon CloudFront – 推荐,静态托管,全球 CDN
Amazon Amplify Hosting – 简单但灵活性较低
建议架构:
– 前端:Amazon CloudFront + Amazon S3
– 后端:Application Load Balancer (ALB) + Amazon Fargate
– 认证:Amazon Cognito User Pool
我可以帮你用 CDK 实现这个架构。要不要先创建一个 Spec 文档?
根据 Kiro 的建议,我创建了 Spec 文档来明确需求。
我:帮我创建 Spec 文档结构。
Kiro 帮我在 .kiro/specs/cloudfront-alb-ecs-deployment/ 创建了三个文档:
requirements.md – 部署需求
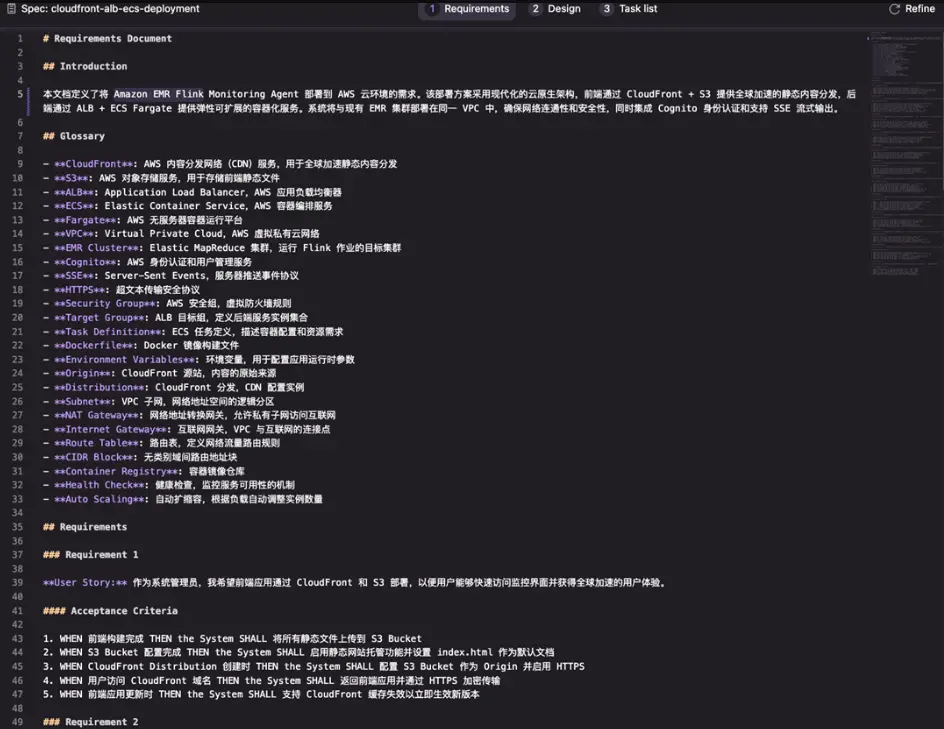
design.md – 架构设计

tasks.md – 任务分解

我:基于 Spec,帮我实现 CDK 部署代码。
Kiro:开始实现…
Kiro 生成了第一版代码,所有资源都在一个 Stack 中:
class FlinkMonitorStack(Stack):
def __init__(self, scope, id, **kwargs):
super().__init__(scope, id, **kwargs)
# VPC、子网、安全组
# Application Load Balancer (ALB)、Target Group
# Amazon ECS Cluster、AWS Fargate Service
# Amazon S3、Amazon CloudFront
# Amazon Cognito
# ... 所有资源都在这里
问题:代码超过 500 行,难以维护,部署时间长。
我:这个 Stack 太大了,有没有更好的组织方式?
Kiro:
你说得对。我建议采用多堆栈架构:
方案一:按资源类型分离
– NetworkStack:VPC、子网、安全组
– ComputeStack:Amazon ECS、Amazon Fargate
– StorageStack:Amazon S3、Amazon CloudFront
– AuthStack:Amazon Cognito
方案二:按部署频率分离(推荐)
– InfrastructureStack:基础设施(很少变更)
– BackendStack:后端应用(经常更新)
– FrontendStack:前端应用(经常更新)
方案二的优势:
更新前端不影响后端
更新后端不影响基础设施
部署更快(只部署变更的堆栈)
职责清晰
你觉得哪个方案更适合?
我:方案二看起来更合理。但是堆栈之间怎么共享资源?
Kiro:
通过 Amazon CloudFormation Outputs 和 Fn.importValue:
# InfrastructureStack 导出
CfnOutput(self, "VPCId",
value=vpc.vpc_id,
export_name="FlinkMonitor-VPC-Id"
)
# BackendStack 导入
vpc_id = Fn.import_value("FlinkMonitor-VPC-Id")
这样可以实现堆栈间的松耦合。
基于讨论,Kiro 重构了代码为三层堆栈。
我:请按照三层堆栈重构代码。
Kiro:正在重构…
Kiro 生成了基础设施堆栈代码:
class InfrastructureStack(Stack):
def __init__(self, scope, id, **kwargs):
super().__init__(scope, id, **kwargs)
# 网络资源
self._create_network_resources()
# 安全组
self._create_security_groups()
# 负载均衡
self._create_load_balancer()
# 前端基础设施
self._create_frontend_infrastructure()
# 认证服务
self._create_cognito()
关键对话:Amazon ECS 安全组应该在哪里创建?
我:Amazon ECS 安全组应该在 InfrastructureStack 还是 BackendStack?
Kiro:
建议在 InfrastructureStack 中创建,原因:
安全组是基础设施,不依赖 Amazon ECS 服务
可以在部署后端前就配置 Amazon EMR 安全组
避免循环依赖
符合 IaC 最佳实践
实现:
– InfrastructureStack 创建 Amazon ECS 安全组
– 导出安全组 ID
– BackendStack 导入并使用
Kiro 生成了后端堆栈代码:
class BackendStack(Stack):
def __init__(self, scope, id, **kwargs):
super().__init__(scope, id, **kwargs)
# 导入基础设施资源
vpc_id = Fn.import_value("FlinkMonitor-VPC-Id")
ecs_sg_id = Fn.import_value("FlinkMonitor-ECS-SecurityGroup")
# Amazon ECS Cluster
# Task Definition
# AWS Fargate Service
Kiro 生成了前端堆栈代码:
class FrontendStack(Stack):
def __init__(self, scope, id, **kwargs):
super().__init__(scope, id, **kwargs)
# 导入 Amazon S3 和 Amazon CloudFront
bucket_name = Fn.import_value("FlinkMonitor-Frontend-Bucket")
# 构建前端
# 部署到 Amazon S3
# 失效 Amazon CloudFront 缓存
在实际部署中遇到了一些问题,Kiro 帮助逐一解决。
我:部署失败,提示子网 CIDR 与 EMR 冲突。
Kiro:
我来帮你计算可用的 CIDR:
查询 Amazon EMR 集群的子网 CIDR
找到 Amazon VPC 中未使用的 CIDR 范围
更新 cdk.json 配置
已生成脚本:scripts/calculate_subnet_cidr.py
我:什么时候配置 Amazon EMR 安全组?
Kiro:
建议在 BackendStack 部署后、测试前配置:
步骤 4.5:配置 Amazon EMR 安全组
– Amazon ECS 安全组已在步骤 1 创建
– 不依赖 Amazon ECS 服务(只需要安全组 ID)
– 避免循环依赖
已生成脚本:scripts/configure_emr_security_group.sh
我:前端怎么获取 Amazon Cognito 和 API 地址?
Kiro:
通过脚本自动生成 .env 文件:
从 Amazon CloudFormation Outputs 读取值
生成 frontend/.env
前端构建时注入环境变量
已生成脚本:scripts/generate_frontend_env.sh
经过与 Kiro 的多轮对话和迭代,最终形成了清晰的三层堆栈架构。
完整部署架构图

三层堆栈架构图

职责分离:每个堆栈负责特定的资源类型
依赖清晰:后端和前端依赖基础设施
独立部署:可以单独更新某个堆栈
资源共享:通过 Amazon CloudFormation 输出共享资源
Amazon VPC 集成:自动发现 Amazon EMR 集群所在的 Amazon VPC
子网创建:
公有子网 × 2 (跨 2 个 AZ):Application Load Balancer (ALB) + Amazon NAT Gateway
私有子网 × 2 (跨 2 个 AZ):Amazon Fargate 任务
路由表:
公有路由表 → Amazon Internet Gateway
私有路由表 × 2 → Amazon NAT Gateway (每个 AZ 一个)
安全组:
Application Load Balancer (ALB) 安全组:允许 HTTP/HTTPS 入站
Amazon ECS 安全组:允许来自 Application Load Balancer (ALB) 的流量 (端口 8080)
Amazon IAM 角色:
Task Role:应用权限 (Amazon Bedrock、Amazon EMR、Amazon EC2)
Execution Role:Amazon ECS 基础操作权限
Application Load Balancer (ALB) :
公网访问 (internet-facing)
跨 2 个 AZ 部署
HTTP 监听器 (端口 80)
Target Group:
目标类型:IP (Amazon Fargate)
健康检查:/api/health 端点
Amazon S3 Bucket:
私有访问 (通过 Amazon CloudFront OAC)
阻止所有公共访问
Amazon CloudFront Distribution:
全球 CDN 加速
HTTPS 强制重定向
路由规则:
/* → Amazon S3 (前端静态文件)
/api/* → Application Load Balancer (ALB) (后端 API)
Amazon Cognito User Pool:
用户名 + 邮箱登录
密码策略 (8 位,大小写+数字)
Amazon Cognito User Pool Client:
OAuth 2.0 授权码流
回调 URL:Amazon CloudFront + localhost
Task Definition:
CPU:1024 (1 vCPU)
内存:2048 MB (2 GB)
架构:ARM64 (成本优化)
容器镜像:从 Amazon ECR 拉取
环境变量:AWS_DEFAULT_REGION、EMR_CLUSTER_ID
健康检查:curl /api/health
Amazon Fargate Service:
期望任务数:1 (可配置)
部署在私有子网
使用步骤 1 创建的 Amazon ECS 安全组
关联到 Application Load Balancer (ALB) Target Group
部署配置:
最大百分比:200%
最小健康百分比:100%
启用断路器和自动回滚
日志组:/ecs/flink-monitor
保留天数:7 天
日志流前缀:ecs
检查构建目录:frontend/dist
上传到 Amazon S3:使用 BucketDeployment
Amazon CloudFront 失效:自动失效缓存 (/*)
清理旧文件:prune=True
Amazon CloudFormation 堆栈

系统访问成功

监控仪表板

1. 模块化
每个堆栈职责清晰
易于理解和维护
代码复用性高
2. 独立部署
前端更新不影响后端
后端更新不影响基础设施
加快部署速度
3. 安全隔离
基础设施变更需要明确操作
降低误操作风险
便于权限管理
4. 成本优化
仅部署需要更新的堆栈
减少 Amazon CloudFormation API 调用
节省部署时间
1. Spec 驱动开发的价值
传统方式:直接写代码,边写边想架构 Kiro 方式:先写 Spec,明确需求和设计,再生成代码
优势: – 需求清晰,减少返工 – 设计文档自动生成 – 便于团队协作和 Code Review
2. 对话式架构演进
关键发现:最好的架构不是一次设计出来的,而是通过对话逐步优化的。
我的经验: – 第一版:单堆栈(简单但难维护) – 与 Kiro 讨论后:三层堆栈(模块化、可维护) – 遇到问题时:Kiro 提供多个方案,我选择最适合的
3. AI 辅助的最佳实践
Kiro 自动应用的最佳实践: – 安全组最小权限原则 – 跨 AZ 高可用部署 – 私有子网 + Amazon NAT Gateway – Amazon CloudFront OAC 而非 OAI – Amazon ECS 断路器和自动回滚
我的收获:不仅得到了代码,还学到了亚马逊云科技最佳实践。
4. 效率提升的关键
时间对比: – 传统开发:10 小时(查文档、写代码、调试) – Kiro 辅助:1.5 小时(对话、Review、微调)
效率提升的原因: – 减少查文档时间(Kiro 知道所有 API) – 减少调试时间(生成的代码质量高) – 减少重构时间(架构设计合理)
5. 人机协作的模式
最佳实践: – 人:提供需求、做决策、Review 代码 – AI:生成代码、提供方案、应用最佳实践
不要: – 完全依赖 AI(需要理解生成的核心代码和流程) – 完全不用 AI(错过效率提升机会)
6. 持续学习
意外收获: – 学会了三层堆栈架构模式 – 理解了 Amazon CloudFormation Outputs 的用法 – 掌握了 Amazon Fargate 的最佳实践 – 了解了 Amazon CloudFront 的高级配置
建议:把 Kiro 当作学习工具,不仅要用它生成代码,还要理解为什么这样设计。
通过 Kiro AI 辅助开发 Amazon CDK 部署架构,我获得了:
效率提升:开发时间从 10 小时缩短到5 小时
架构优化:从单堆栈演进到三层堆栈
代码质量:自动应用 亚马逊云科技最佳实践
知识积累:学习了云架构设计模式
核心体会: – Kiro 不是替代开发者,而是增强开发者 – 最好的架构来自人机协作 – Spec 驱动开发提高了代码质量 – AI 辅助让我们专注于架构设计,而非重复劳动
下一步计划:
– 使用 Kiro 开发 CI/CD 流水线
– 探索 Kiro 在多环境部署中的应用
参考资源
项目地址:https://github.com/yangguangfu007/emr-flink-monitoring-agent
Amazon CDK 文档:https://docs.aws.amazon.com/cdk/
Kiro AI 文档:https://kiro.dev/docs/
*前述特定亚马逊云科技生成式人工智能相关的服务目前在亚马逊云科技海外区域可用。亚马逊云科技中国区域相关云服务由西云数据和光环新网运营,具体信息以中国区域官网为准。
本篇作者

🔥 想利用生成式AI开发工具解放双手,却苦于应用效果不够完善、流程不够规范?
✨ 亚马逊云科技 Kiro 登场!采用“规范驱动”开发理念,结合 Agent Hooks 自动化系统,1小时让小白变身生产级游戏制作人!
🔛 速来云上探索实验室,体验 Kiro 开发独立游戏,从需求到部署全掌握!
👉 点击这里,即刻开启 AI 开发之旅!
